文章目录
- GPU架构
- GPU渲染
- 内存架构
- Streaming Multiprocessor(SM)
- CUDA Core
- Tensor Core
- RT Core
- CPU-GPU异构系统
- GPU资源管理模型
- GPU架构演进
- G80 架构
- Fermi 架构
- Maxwell架构
- Tesla架构
- Pascal架构
- Volta 架构
- Turing架构
- Ampere 架构
- Hopper架构
- 参考文献
GPU架构
主要组成包括:
- CUDA 核心:GPU 架构中的主要计算单元,能够处理各种数学和逻辑运算。
- 内存系统:包括 L1、L2 高速缓存和共享内存等,用于存储数据和指令,以减少 GPU 访问主存的延迟。
- 高速缓存和缓存行:用于提高 GPU 的内存访问效率。
- TPC/SM:CUDA 核心的分组结构,一个 TPC 包含两个 SM,每个 SM 都有自己的 CUDA 核心和内存。
- Tensor Core( 2017 年 Volta 架构引入):Tensor张量核心,用于执行张量计算,支持并行执行FP32与INT32运算。
- RT Core(2018 年 Turing 架构引入 ):光线追踪核心,负责处理光线追踪加速。
- NVIDIA GPU 架构还包括内存控制器、高速缓存控制器、CUDA 编译器和驱动程序等其他组件,这些组件与SM 和其他核心组件协同工作,可以实现高效的并行计算和内存访问,提高 GPU 的性能和能效。
GPU渲染

从Fermi开始NVIDIA使用类似的原理架构,使用一个Giga Thread Engine来管理所有正在进行的工作,GPU被划分成多个GPCs(Graphics Processing Cluster),每个GPC拥有多个SM(SMX、SMM)和一个光栅化引擎(Raster Engine),它们其中有很多的连接,最显著的是Crossbar,它可以连接GPCs和其它功能性模块(例如ROP或其他子系统)。
程序员编写的shader是在SM上完成的。每个SM包含许多为线程执行数学运算的Core(核心)。例如,一个线程可以是顶点或像素着色器调用。这些Core和其它单元由Warp Scheduler驱动,Warp Scheduler管理一组32个线程作为Warp(线程束)并将要执行的指令移交给Dispatch Units。
GPU中实际有多少这些单元(每个GPC有多少个SM,多少个GPC …)取决于芯片配置本身。例如,GM204有4个GPC,每个GPC有4个SM,但Tegra X1有1个GPC和2个SM,它们均采用Maxwell设计。SM设计本身(内核数量,指令单位,调度程序…)也随着时间的推移而发生变化,并帮助使芯片变得如此高效,可以从高端台式机扩展到笔记本电脑移动。
内存架构
部分架构的GPU与CPU类似,也有多级缓存结构:寄存器、L1缓存、L2缓存、GPU显存、系统显存。但是GPU-style的内存架构ALU定夺,GPU上下文(Context)多,吞吐量高,依赖高带宽与系统内存交换数据。
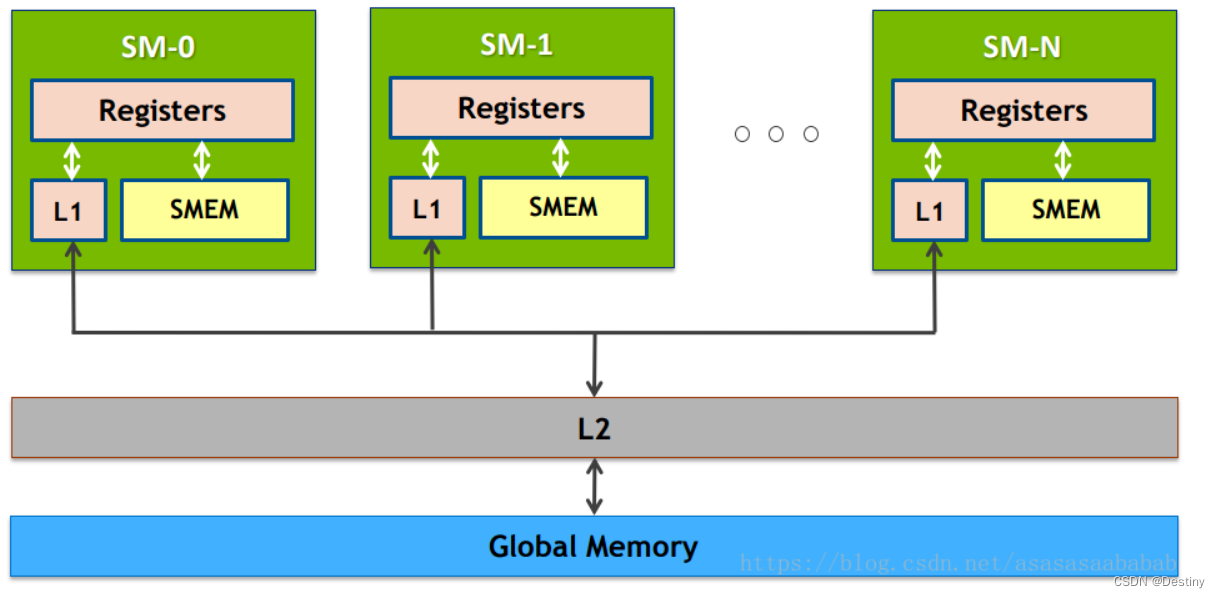
内存(Memory)是显卡用于存储数据和代码的部分,它可以快速访问大量数据,大大提高了显卡的运算速度。当前英伟达显卡的内存主要分为两种:GDDR5和GDDR6。GDDR5内存具有高带宽、低延迟和低功耗等特点,通常用于较低端的显卡;而GDDR6内存则具有更高的带宽、更低的延迟和更高的功耗,适用于高端游戏等需要更高性能的应用。
显存(Video Memory)是显卡专门用来存储图形数据的部分,它比普通内存更快速,可以更好地支持图形运算。英伟达显卡的显存一般分为两种:GDDR5和GDDR6。GDDR5显存通常用于中低端显卡,而GDDR6显存则主要适用于高端的游戏和图形应用。
Streaming Multiprocessor(SM)
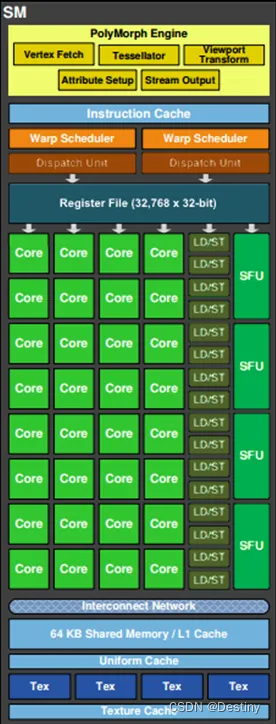
上图为一个SM的构成图,从上到下依次是:
- PolyMorph Engine:多边形引擎负责属性装配(attribute Setup)、顶点拉取(VertexFetch)、曲面细分、栅格化(这个模块可以理解专门处理顶点相关的东西)。
- 指令缓存(Instruction Cache)
- 2个Warp Schedulers:这个模块负责warp调度,一个warp由32个线程组成,warp调度器的指令通过Dispatch Units送到Core执行。
- 指令调度单元(Dispatch Units) 负责将Warp Schedulers的指令送往Core执行
- 128KB Register File(寄存器)
- 16个LD/ST(load/store)用来加载和存储数据
- Core (Core,也叫流处理器Stream Processor)
- 4个SFU(Special function units 特殊运算单元)执行特殊数学运算(sin、cos、log等)
- 内部链接网络(Interconnect Network)
- 64KB 共享缓存
- 全局内存缓存(Uniform Cache)
- 纹理读取单元(Tex)
CUDA Core
CUDA 全称为统一计算设备架构 (Compute Unified Device Architecture) ,是一个并行计算平台,同时也是一个应用程序编程接口 (API)。目的在于让软件开发人员能够更好地控制他们可以使用的物理资源。使用 C 或 C++ 编码的计算机程序员对资源分配有很大的控制权。CUDA 系统极大地促进了 OpenACC 和 OpenCL 等框架的普及和使用。CUDA 核心也是并行处理器,允许不同处理器同时处理数据。这与双核或四核 CPU 类似,只不过 GPU 有数千个 CUDA 核心。
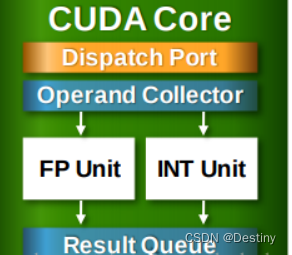
包括控制单元Dispatch Port、Operand Collector,以及浮点计算单元FP Unit、整数计算单元Int Unit,另外还包括计算结果队列。当然还有Compare、Logic、Branch等。相当于微型CPU。
英伟达显卡的多模态构成主要由CUDA、OpenGL及OpenCL等技术构成。
1.CUDA
CUDA(Compute Unified Device Architecture)平台是英伟达推出的一种并行计算技术,主要用于加速GPU的计算能力。通过CUDA平台,英伟达显卡可以高效地处理复杂的计算任务,提高计算性能。
2.OpenGL
OpenGL是一种开放的图形编程接口,可以在不同的操作系统和硬件平台上运行。英伟达显卡支持OpenGL技术,并可以通过OpenGL实现硬件加速的图形渲染。
3.OpenCL
OpenCL是一种开放的并行计算框架,可以同时利用多个处理器来进行运算。英伟达显卡支持OpenCL技术,可以通过OpenCL实现硬件加速的数据处理和计算。
并行计算
CUDA 的巨大优势是任务并行化,这些并行化任务可以使用各种高级语言来执行,例如 C 语言、C++以及 Python,CUDA 是目前最常用的任务加速平台。
应用范围
CUDA 应用范围包括加密哈希、物理引擎、游戏开发等相关项目,在科学行业,在测量、测绘、天气预报和其他等相关项目得到了很大改善和简化。
CUDA 还可以对有风险的金融操作进行预测,将效率加快至少十八倍或更多。其他例子包括 Tesla GPU 在云计算和其他需要强大工作能力的计算系统中广受好评。CUDA 还允许自动驾驶车辆简单高效地运行,能够进行其他系统无法完成的实时计算。
Tensor Core
CUDA 核心足以满足计算工作负载,但 Tensor Core 的速度明显更快。CUDA 核心每个时间周期只能执行一项操作,但 Tensor 核心可以处理多项操作,从而带来令人难以置信的性能提升。从根本意义上来说,Tensor Core 所做的就是提高矩阵乘法的速度。
计算速度的提升确实是以准确性为代价的,从这点上来说 CUDA 核心的准确度要高得多。但是在训练机器学习模型时,Tensor Core 在计算速度和总体成本方面要有效得多。
CUDA Core 专门处理图形工作负载,Tensor Core 更擅长处理数字工作负载。
RT Core
2018 年 NVIDIA 发布了新一代的旗舰显卡 RTX 2080,搭载了全新的 Turing(图灵)架构。全新的架构也同时添加了名为 RT Core 的计算单元。该计算单元的目的是为了让 GPU 拥有实时光线追踪的能力,一种可以让画面更换新的渲染演算法。
光线追踪(Ray Tracing)的原理是从用户端为起点,寻找光线反射和折射的路径并算出用户会看到的物体颜色及亮度。
CPU-GPU异构系统
根据CPU和GPU是否共享内存,可分为两种类型的CPU-GPU架构:
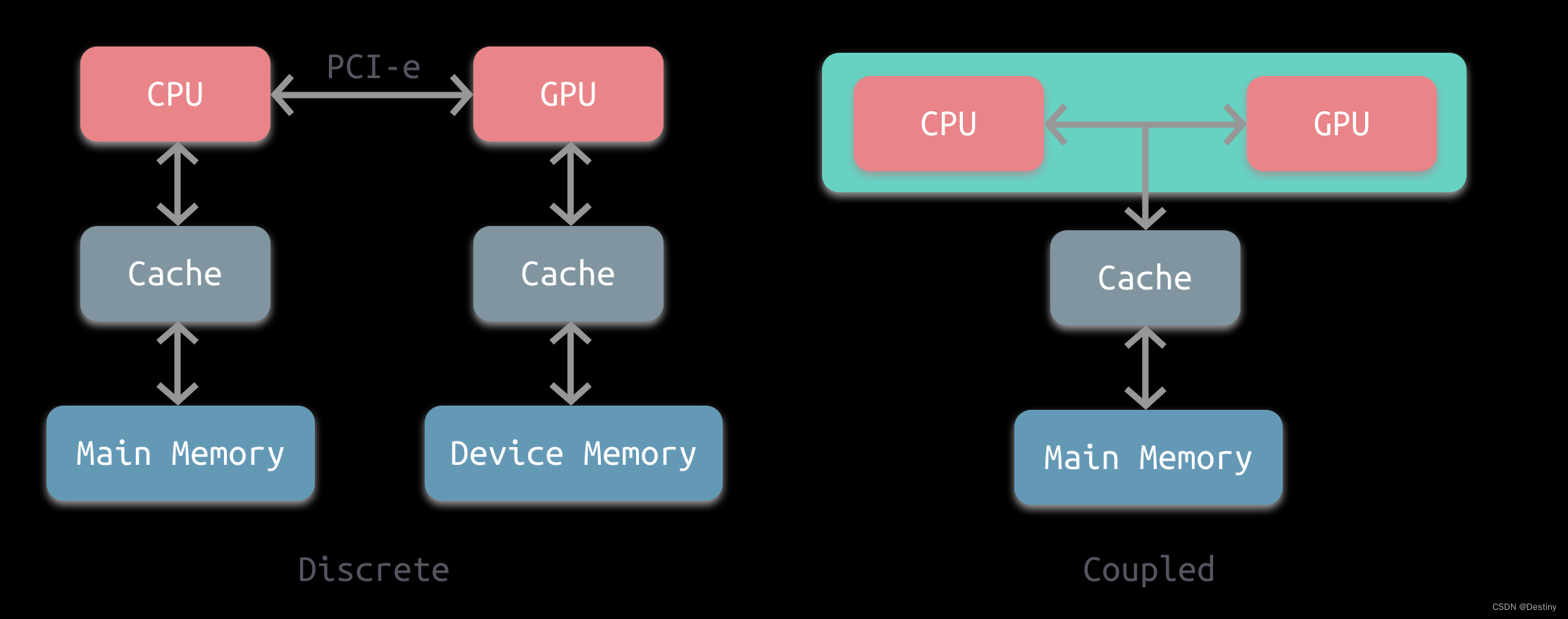
上图左是分离式架构,CPU和GPU各自有独立的缓存和内存,它们通过PCI-e等总线通讯。这种结构的缺点在于 PCI-e 相对于两者具有低带宽和高延迟,数据的传输成了其中的性能瓶颈。目前使用非常广泛,如PC、智能手机等。
上图右是耦合式架构,CPU 和 GPU 共享内存和缓存。AMD 的 APU 采用的就是这种结构,目前主要使用在游戏主机中,如 PS4。
在存储管理方面,分离式结构中 CPU 和 GPU 各自拥有独立的内存,两者共享一套虚拟地址空间,必要时会进行内存拷贝。对于耦合式结构,GPU 没有独立的内存,与 GPU 共享系统内存,由 MMU 进行存储管理。
GPU资源管理模型
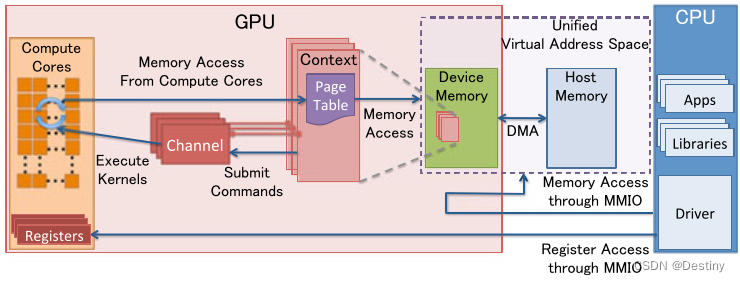
下图是分离式架构的资源管理模型:
-
MMIO(Memory Mapped IO)
- CPU与GPU的交流就是通过MMIO进行的。CPU 通过 MMIO 访问 GPU 的寄存器状态。
- DMA传输大量的数据就是通过MMIO进行命令控制的。
- I/O端口可用于间接访问MMIO区域,像Nouveau等开源软件从来不访问它。
-
GPU Context
- GPU Context代表了GPU计算的状态。
- 在GPU中拥有自己的虚拟地址。
- GPU 中可以并存多个活跃态下的Context。
-
GPU Channel
- 任何命令都是由CPU发出。
- 命令流(command stream)被提交到硬件单元,也就是GPU Channel。
- 每个GPU Channel关联一个context,而一个GPU Context可以有多个GPU channel。
- 每个GPU Context 包含相关channel的 GPU Channel Descriptors , 每个 Descriptor 都是 GPU 内存中的一个对象。
- 每个 GPU Channel Descriptor 存储了 Channel 的设置,其中就包括 Page Table 。
- 每个 GPU Channel 在GPU内存中分配了唯一的命令缓存,这通过MMIO对CPU可见。
- GPU Context Switching 和命令执行都在GPU硬件内部调度。
-
GPU Page Table
- GPU Context在虚拟基地空间由Page Table隔离其它的Context 。
- GPU Page Table隔离CPU Page Table,位于GPU内存中。
- GPU Page Table的物理地址位于 GPU Channel Descriptor中。
- GPU Page Table不仅仅将 GPU虚拟地址转换成GPU内存的物理地址,也可以转换成CPU的物理地址。因此,GPU Page Table可以将GPU虚拟地址和CPU内存地址统一到GPU统一虚拟地址空间来。
-
PCI-e BAR
- GPU 设备通过PCI-e总线接入到主机上。 Base Address Registers(BARs) 是 MMIO的窗口,在GPU启动时候配置。
- GPU的控制寄存器和内存都映射到了BARs中。
- GPU设备内存通过映射的MMIO窗口去配置GPU和访问GPU内存。
-
PFIFO Engine
- PFIFO是GPU命令提交通过的一个特殊的部件。
- PFIFO维护了一些独立命令队列,也就是Channel。
- 此命令队列是Ring Buffer,有PUT和GET的指针。
- 所有访问Channel控制区域的执行指令都被PFIFO 拦截下来。
- GPU驱动使用Channel Descriptor来存储相关的Channel设定。
- PFIFO将读取的命令转交给PGRAPH Engine。
-
BO
-
Buffer Object (BO),内存的一块(Block),能够用于存储纹理(Texture)、渲染目标(Render Target)、着色代码(shader code)等等。
-
Nouveau和Gdev经常使用BO。
Nouveau是一个自由及开放源代码显卡驱动程序,是为NVidia的显卡所编写。
Gdev是一套丰富的开源软件,用于NVIDIA的GPGPU技术,包括设备驱动程序。
-
更多详细可以阅读论文:Data Transfer Matters for GPU Computing。
GPU架构演进
G80 架构
英伟达第一个 GPU 架构,采用了 MIMD(多指令流多数据流)标量架构,拥有 128 个 SP(流处理器),核心频率范围从 250MHz 到 600MHz,搭配 DDR3 显存。该架构是当时最强大的 GPU 之一,但是功耗较高。
Fermi 架构
Fermi架构白皮书
Fermi 是 Nvidia 在 2010 年发布的架构,引入了很多今天也仍然不过时的概念。英伟达第一个采用 GPU-Direct 技术的 GPU 架构,它拥有 32 个 SM(流多处理器)和 16 个 PolyMorph Engine 阵列。该架构采用了 4 颗芯片的模块化设计,拥有 32 个光栅化处理单元和 16 个纹理单元,搭配 GDDR5 显存。
GPU 通过 Host Interface 读取 CPU 指令,GigaThread Engine 将特定的数据从 Host Memory 中拷贝到内部的 Framebuffer 中。随后 GigaThread Engine 创建并分发多个 Thread Blocks 到多个 SM 上。多个 SM 彼此独立,并独立调度各自的多个 Thread Wraps 到 SM 内的 CUDA Cores 和其他执行单元上执行。
上面这句话有几个概念解释一下:
SM: 对应于上图中的 SM 硬件实体,内部有很多的 CUDA Cores;
Thread Block: 一个 Thread Block 包含多个线程(比如几百个),多个 Blocks 之间的执行完全独立,硬件可以任意调度多个 Block 间的执行顺序,而 Block 内部的多个线程执行规则由程序员决定,程同时程序员可以决定一共有多少个 Blocks;
Thread Warp: 32 个线程为一个 Thread Warp,Warp 的调度有特殊规则
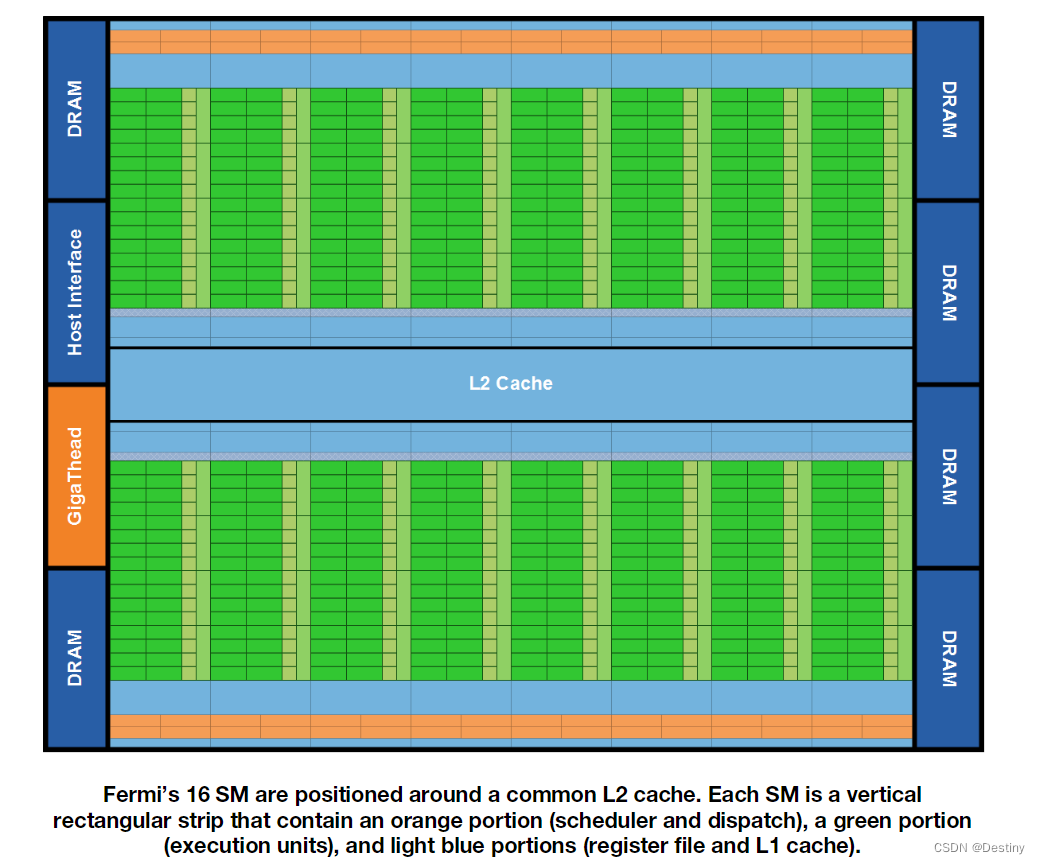
SM 内有 32 个 CUDA Cores,每个 CUDA Core 含有一个 Integer arithmetic logic unit (ALU)和一个 Floating point unit(FPU). 并且提供了对于单精度和双精度浮点数的 FMA 指令。
SM 内还有 16 个 LD/ST 单元,也就是 Load/Store 单元,支持 16 个线程一起从 Cache/DRAM 存取数据。
4 个 SFU,是指 Special Function Unit,用于计算 sin/cos 这类特殊指令。每个 SFU 每个时钟周期只能一个线程执行一条指令。而一个 Warp(32 线程)就需要执行 8 个时钟周期。SFU 的流水线是从 Dispatch Unit 解耦的,所以当 SFU 被占用时,Dispatch Unit 会去使用其他的执行单元。
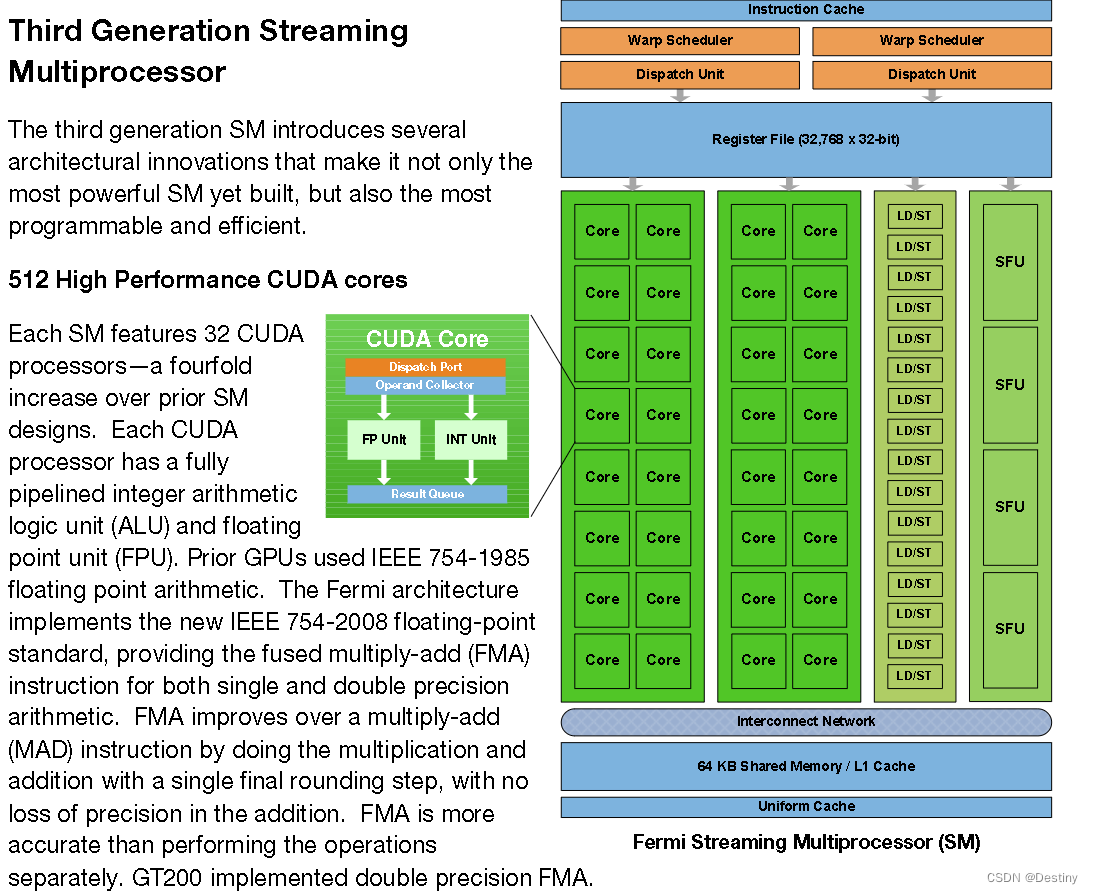
之前一直提到 Warp,但之前只说明了是 32 个线程,我们在这里终于开始详细说明,首先来看 Dual Warp Scheduler 的概览。
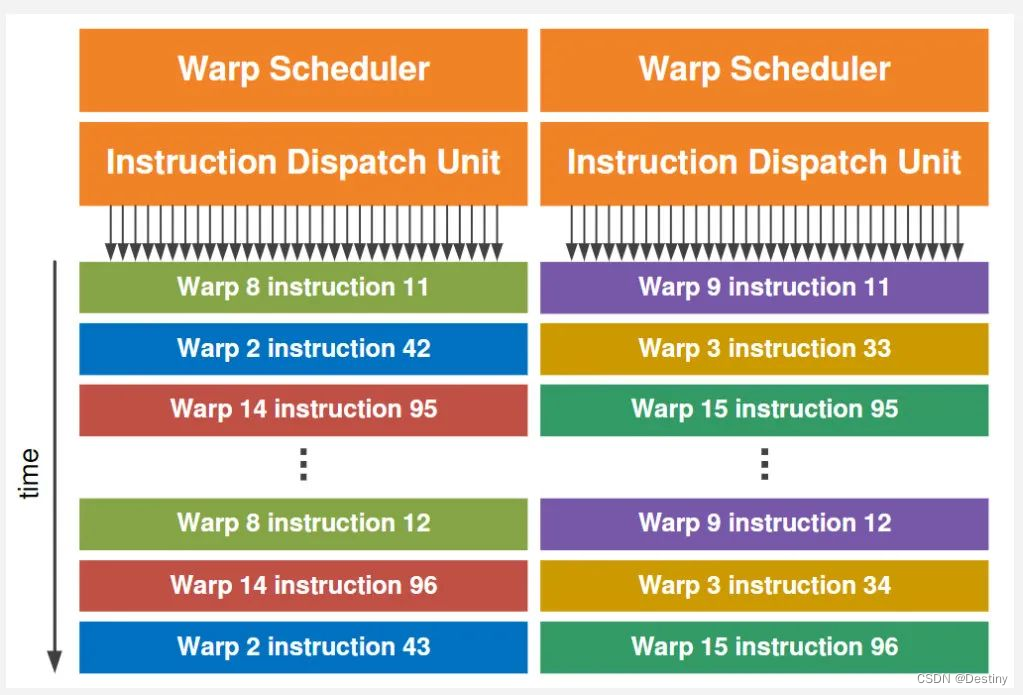
在之前的 SM 概览图以及上图里,可以注意到 SM 内有两个 Warp Scheduler 和两个 Dispatch Unit. 这意味着,同一时刻,会并发运行两个 warp,每个 warp 会被分发到一个 Cuda Core Group(16 个 CUDA Core), 或者 16 个 load/store 单元,或者 4 个 SFU 上去真正执行,且每次分发只执行 一条 指令,而 Warp Scheduler 维护了多个(比如几十个)的 Warp 状态。
这里引入了一个核心的约束,任意时刻,一个 Warp 里的 Thread 都在执行同样的指令,对于程序员来说,观测不到一个 warp 里不同 thread 的不同执行情况。
但是众所周知,不同线程可能会进入不同的分支,这时如何执行一样的指令?
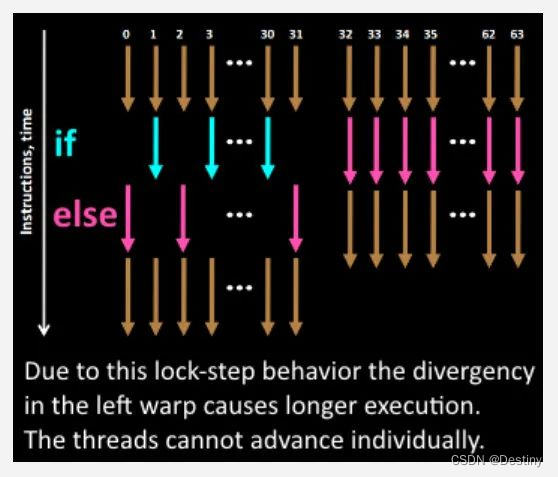
可以看上图,当发生分支时,只会执行进入该分支的线程,如果进入该分支的线程少,则会发生资源浪费。
在 SM 概览图里,我们可以看到 SM 内 64KB 的 On-Chip Memory,其中 48KB 作为 shared memory, 16KB 作为 L1 Cache. 对于 L1 Cache 以及非 On-Chip 的 L2 Cache,其作用与 CPU 多级缓存结构中的 L1/L2 Cache 非常接近,而 Shared Memory,则是相比 CPU 的一个大区别。无论是 CPU 还是 GPU 中的 L1/L2 Cache,一般意义上都是无法被程序员调度的,而 Shared Memory 设计出来就是让渡给程序员进行调度的片上高速缓存。
Maxwell架构
2014 Maxwell架构白皮书
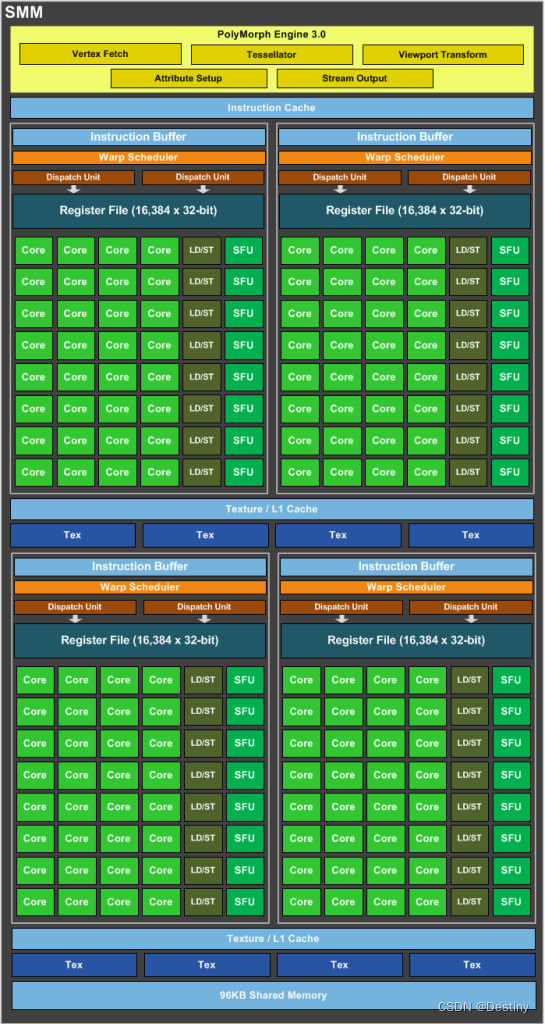
Maxwell的 SM 开始做减法了,每个 SM(SMM)中包含:
- 4 个 Warp Scheduler,8 个 Dispatch Unit
- 128 个 CUDA Core(4 * 32)
- 32 个 SFU 和 LD/ST Unit(4 * 8)
这些硬件单元的流水线分布也不再是像 Kepler 那样大锅炖了,而是有点像是把 4 个差不多像是 Fermi 的 SM 拼在一起组成一个 SM:
每个 Process Block 中包含的内容也更加的多,每个Process Block里面包含了:
- 1 个 Warp Scheduler 和 2 个 Dispatch Unit
- 32 个 CUDA Core
- 8 个 SFU 和 LD/ST Unit
Tesla架构
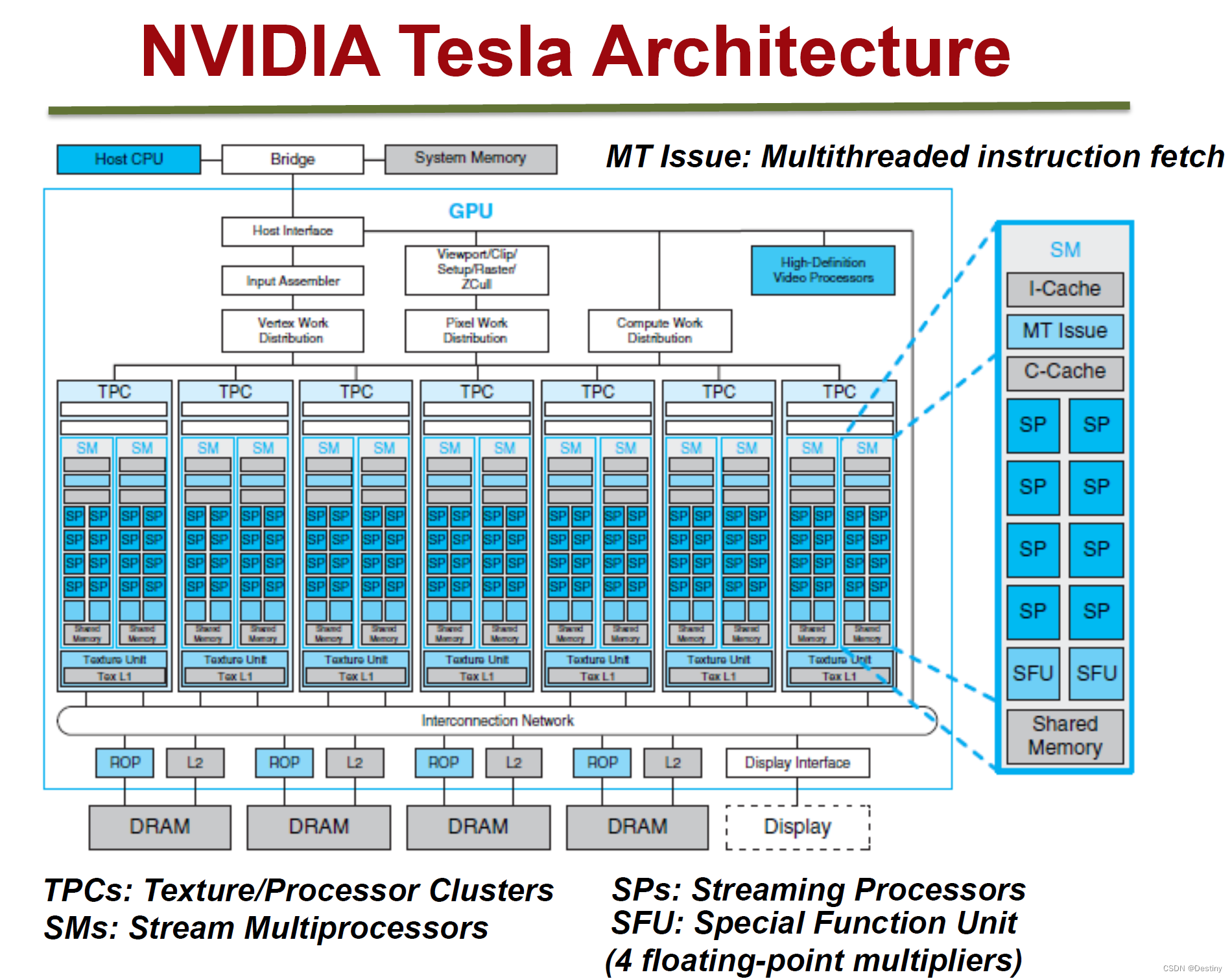
Tesla微观架构总览图如上。下面将阐述它的特性和概念:
- 拥有7组TPC(Texture/Processor Cluster,纹理处理簇)
- 每个TPC有两组SM(Stream Multiprocessor,流多处理器)
每个SM包含:
- 6个SP(Streaming Processor,流处理器)
- 2个SFU(Special Function Unit,特殊函数单元)
- L1缓存、MT Issue(多线程指令获取)、C-Cache(常量缓存)、共享内存
除了TPC核心单元,还有与显存、CPU、系统内存交互的各种部件。
Pascal架构
2016年。SM 内部作了进一步的精简,整体思路是 SM 内部包含的东西越来越少,但是总体的片上 SM 数量每一代都在不断增加,每个 SM 中包含:
- 2 个 Warp Scheduler,4 个 Dispatch Unit
- 64 个 CUDA Core(2 * 32)
- 32 个双精浮点单元(2 * 16,双精回来了)
- 16 个 SFU 和 LD/ST Unit(2 * 8)
一个 SM 里面包含的 Process Block 数量减少到了 2 个,每个 Process Block 内部的结构倒是 Maxwell 差不多:
- 1 个 Warp Scheduler 和 2 个 Dispatch Unit
- 32 个 CUDA Core
- 多了 16 个 DP Unit
- 8 个 SFU 和 LD/ST Unit
此外还有一些其它的升级变化:
- 面向 Deep Learning 做了一些专门的定制(CuDNN 等等库)。
- 除了 PCIE 以外,P100 还有 NVLink 版,单机卡间通信带宽逆天了,多机之间也能通过 Infiniband 进一步扩展 NVLink(GPUDirect)。
- P100 上把 GDDR5 换成了 HBM2,Global Memory 的带宽涨了一个数量级。
- 16nm FinFET 工艺,性能提升一大截,功耗还能控制住不怎么增加。
- Unified Memory,支持把 GPU 的显存和 CPU 的内存统一到一个相同的地址空间,驱动层自己会做好 DtoH 和 HtoD 的内存拷贝,编程模型上更加友好了。
- CUDA Core 也有了升级,现在硬件上直接支持 FP16 的半精计算了,半精性能是单精的 2 倍。
Volta 架构
Volta白皮书
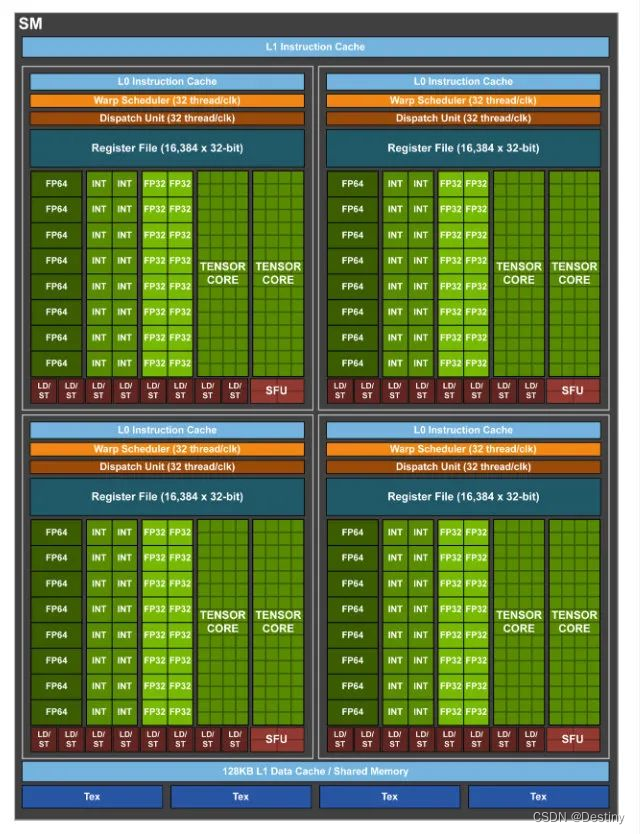
2017年。采用了全新的设计理念和技术,拥有 256 个 SM 和 32 个 PolyMorph Engine 阵列,每个 SM 都拥有 64 个 CUDA 核心。该架构采用了全新的 Tensor 张量核心、ResNet 和 InceptionV3 加速模块等技术,搭配 GDDR6X 显存。这个架构可以说是完全以 Deep Learning 为核心了,相比 Pascal 也是一个大版本。
和 Pascal 的改变类似,到了 Volta,直接拆了 4 个区块,每个区块多配了一个 L0 指令缓存,而 Shared Memory/Register File 这都没有变少,也就和 Pascal 的改变一样,单个线程可使用的资源更多了。单个区块还多个两个名为 Tensor Core 的单元,这就是这个版本的核心了。可以吐槽一下,这个版本又把 L1 和 Shared Memory 合并了。
我们首先看 CUDA Core, 可以看到,原本的 CUDA Core 被拆成了 FP32 Cuda Core 和 INT32 Cuda Core,这意味着可以同时执行 FP32 和 INT32 的操作。
Turing架构
2018Turing架构白皮书
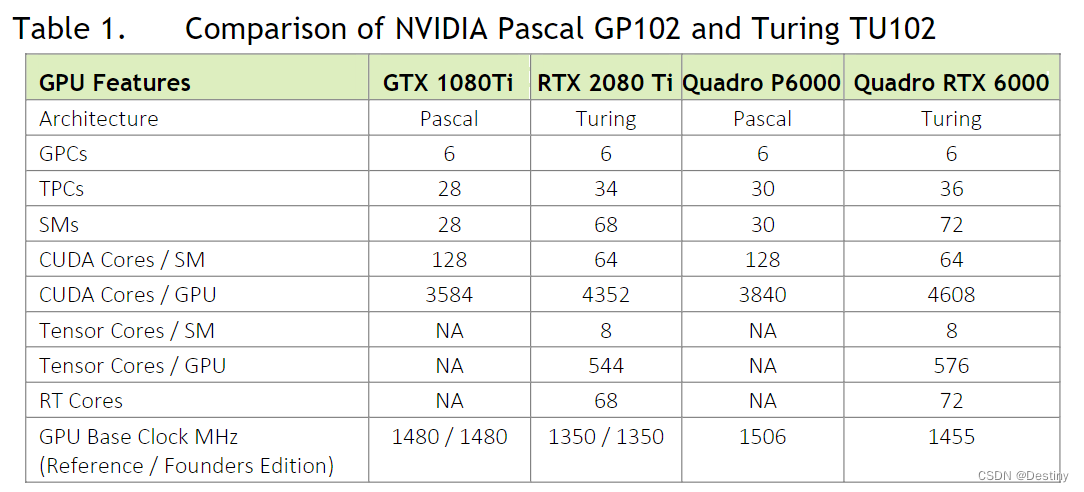
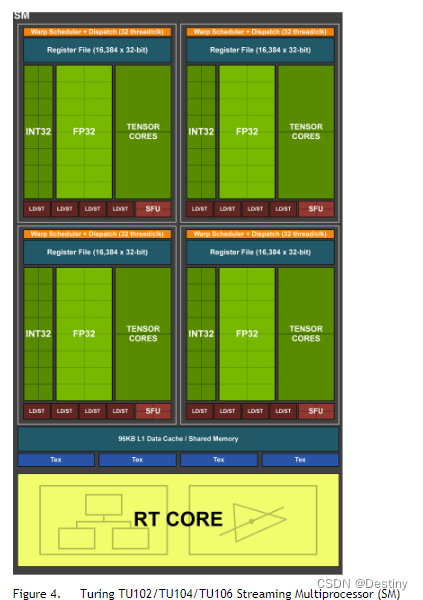
每个GPC均包含一个专用的光栅化引擎和6个TPC,且每个TPC均包含两个SM。每个SM包含:
- 64个CUDA核心
- 8个Tensor核心
- 1个256KB寄存器堆
- 4个纹理单元以及96KB的L1或共享内存
- 可根据计算或图形工作负载将这些内存设置为不同容量。每个SM中的全新RT核心处理引擎负责执行光线追踪加速。
Turing架构采用全新SM设计,每个TPC均包含两个SM,每个SM共有64个FP32核心和64个INT32核心。Turing SM支持并行执行FP32与INT32运算,每个Turing SM还拥有8个混合精度Turing Tensor核心和1个RT核心。
Ampere 架构
Ampere架构白皮书
代表产品为 GeForce RTX 30 系列。该架构继续优化并行计算能力,并引入了更先进的 GDDR6X 内存技术,大幅提高了内存带宽和性能。相比 Turing 架构,Ampere 架构中的 SM 在 Turing 基础上增加了一倍的 FP32 运算单元,这使得每个 SM 的 FP32 运算单元数量提高了一倍,同时吞吐量也就变为了一倍。此外,安培架构还改进了着色器性能和张量核(Tensor Cores),进一步加速深度学习和人工智能任务的处理速度。
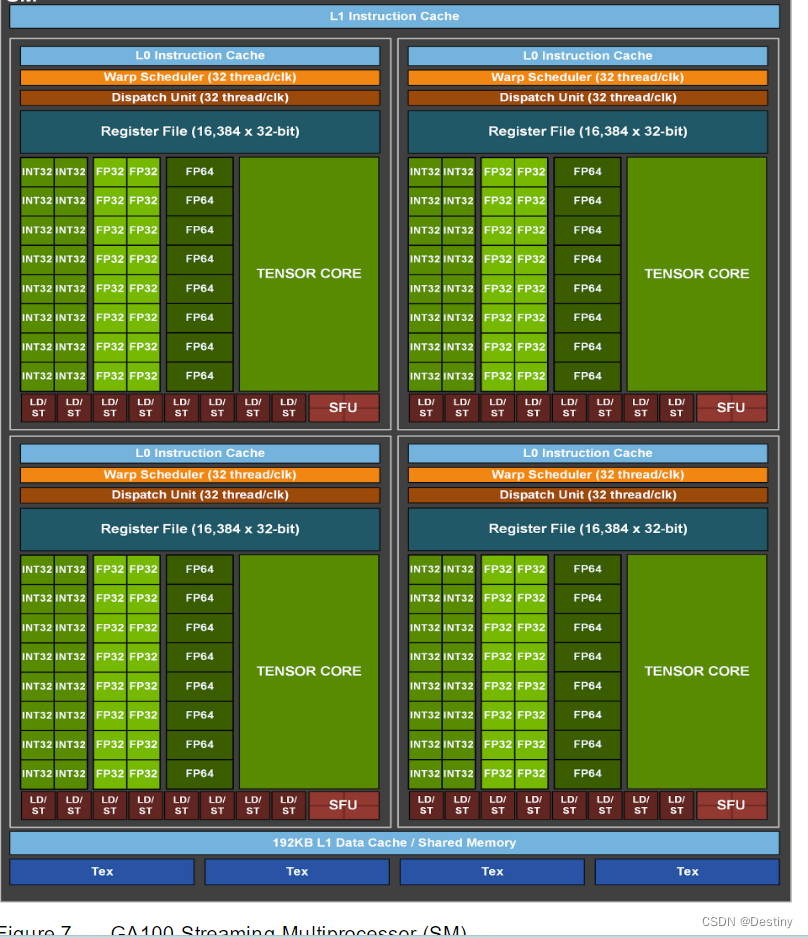
NVIDIA Ampere GA100 GPU架构满配如下:
- 8 GPCs,
- 8 TPCs/GPC, 2 SMs/TPC, 16 SMs/GPC, 128 SMs per full GPU
- 64 FP32 CUDA Cores/SM, 8192 FP32 CUDA Cores per full GPU
- 4第三代Tensor Cores/SM, 512第三代Tensor Cores per full GPU
- 6 HBM2 stacks, 12 512bit 内存控制器
NVIDIA A100在AI训练(半/单精度操作,FP16/32)和推理(8位整数操作,INT8)方面,GPU比Volta GPU强大20倍。在高性能计算(双精度运算,FP64)方面,NVIDIA表示GPU的速度将提高2.5倍。
五大突破:
- NVIDIA Ampere架构 — A100的核心是NVIDIA Ampere GPU架构,其中包含超过540亿个晶体管,使其成为世界上最大的7纳米处理器。
- 基于TF32的第三代张量核(Tensor Core): Tensor核心的应用使得GPU更加灵活,更快,更易于使用。TF32包括针对AI的扩展,无需进行任何代码更改即可使FP32精度的AI性能提高20倍。此外, TensorCore 现在支持FP64,相比上一代,HPC应用程序可提供多达2.5倍的计算量。
- 多实例(Multi-Instance)GPU — MIG是一项新技术功能,可将单个A100GPU划分为多达七个独立的GPU,因此它可以为不同大小的作业提供不同程度的计算,从而提供最佳利用率。
- 第三代NVIDIA NVLink —使GPU之间的高速连接速度加倍,可在服务器中提供有效的性能扩展。
- 结构稀疏性—这项新的效率技术利用了AI数学固有的稀疏特性来使性能提高一倍。
NVIDIA A100基于7nm Ampere GA100 GPU,具有6912 CUDA内核和432 Tensor Core,540亿个晶体管数,108个流式多处理器。采用第三代NVLINK,GPU和服务器双向带宽为4.8 TB/s,GPU间的互连速度为600 GB/s。另外,Tesla A100在5120条内存总线上的HBM2内存可达40GB。
Hopper架构
Hopper架构白皮书

作为面向专业计算的GPU,H100采用HBM3高带宽显存,NVIDIA将六颗HBM3高带宽显存堆栈在核心两侧。核心内建5120-bit的HBM3显存位宽,英伟达可配置最高80GB显存,SXM5版(HBM3显存)带宽更是达到3TB/s,PCIe版本(HBM2e)则是2TB/s。
H100的主机接口同样迎来升级,SXM外形的PCB板配备新一代NVLink,拥有900GB/s的带宽。面对AIC插卡版本采用PCIe 5.0 x16(拥有128GB/s)接口,两者均引入了资源池(resource-pooling)功能,加速GPU之间的数据交换。
虽然H100拥有144组单元,但SXM版也只启用其中的132组单元。PCIe版本更是只有114组,两者的最高频率均为1.8GHz。不仅如此,H100核心的功率高达700W,PCIe版本也达到350W,上一代的A100仅为400W;在提升性能的同时,H100的功耗也在大幅上升。
参考文献
[1] https://segmentfault.com/a/1190000044379561
[2] https://blog.csdn.net/daijingxin/article/details/115042353
[3] https://www.cnblogs.com/timlly/p/11471507.html
[4] https://cloud.tencent.com/developer/article/1891497