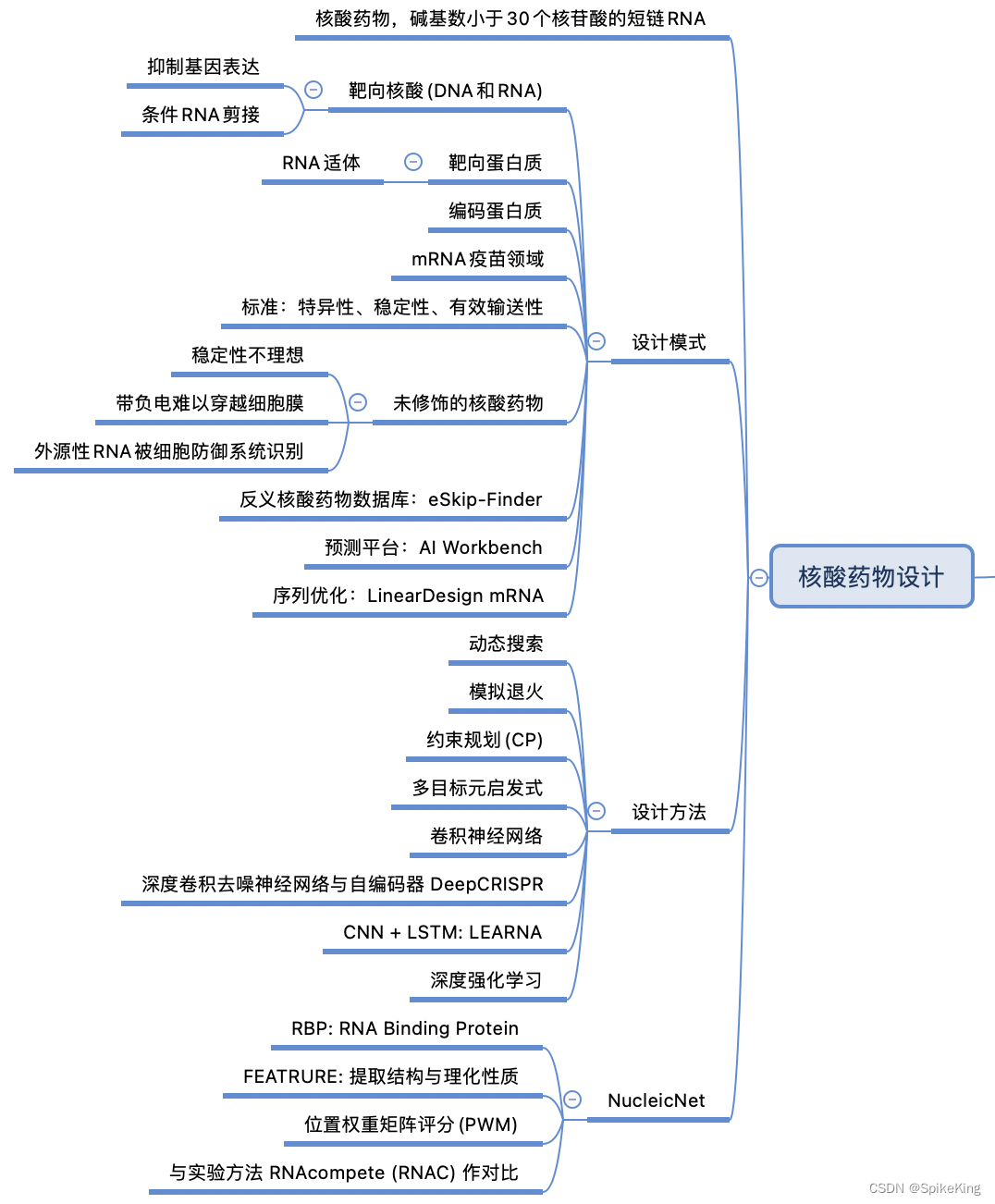
RocksDB大状态调优
RocksDB 是基于 LSM Tree 实现的(类似 HBase) ,写数据都是先缓存到内存中,
所以 RocksDB 的写请求效率比较高。 RocksDB 使用内存结合磁盘的方式来存储数据,每
次获取数据时,先从内存中 blockcache 中查找,如果内存中没有再去磁盘中查询。 使用
RocksDB 时,状态大小仅受可用磁盘空间量的限制, 性能瓶颈主要在于 RocksDB 对磁盘
的读请求, 每次读写操作都必须对数据进行反序列化或者序列化。 当处理性能不够时,仅需
要横向扩展并行度即可提高整个 Job 的吞吐量。
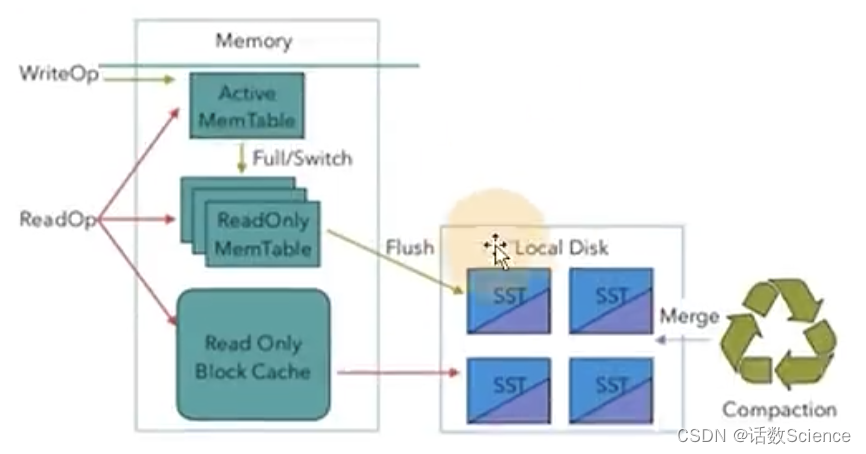
开启增量检查点和本地恢复
1)开启增量检查点
RocksDB 是目前唯一可用于支持有状态流处理应用程序增量检查点的状态后端,可以修改参数开启增量检查点:
state.backend.incremental: true #默认 false,改为 true。
或代码中指定
new EmbeddedRocksDBStateBackend(true)
调整预定义选项
Flink 针对不同的设置为 RocksDB 提供了一些预定义的选项集合,其中包含了后续提到
的一些参数,如果调整预定义选项后还达不到预期,再去调整后面的 block、 writebuffer
等参数。
当 前 支 持 的 预 定 义 选 项 有 DEFAULT 、 SPINNING_DISK_OPTIMIZED 、
SPINNING_DISK_OPTIMIZED_HIGH_MEM 或 FLASH_SSD_OPTIMIZED。有条件上 SSD
的, 可以指定为 FLASH_SSD_OPTIMIZED
state.backend.rocksdb.predefined-options: SPINNING_DISK_OPTIMIZED_HIGH_MEM
#设置为机械硬盘+内存模式