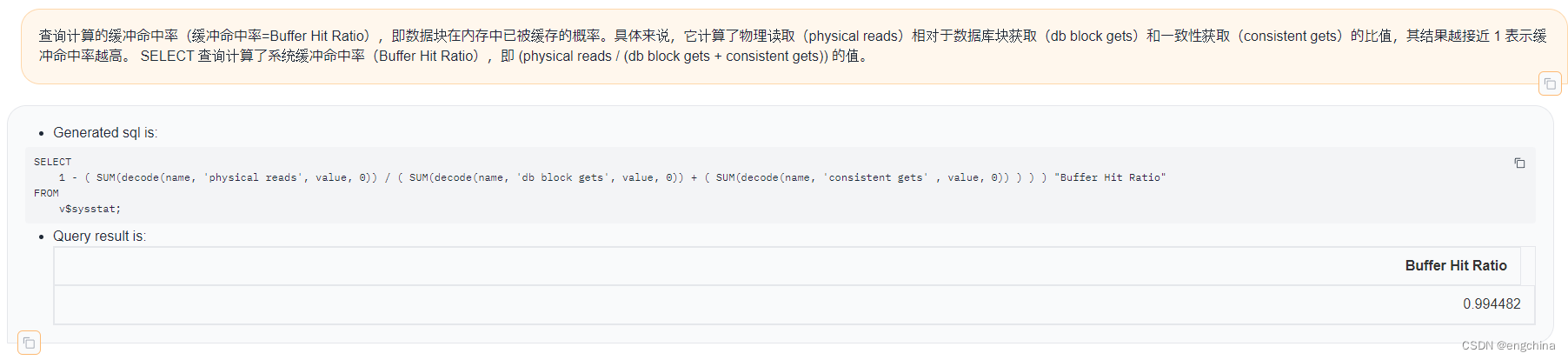
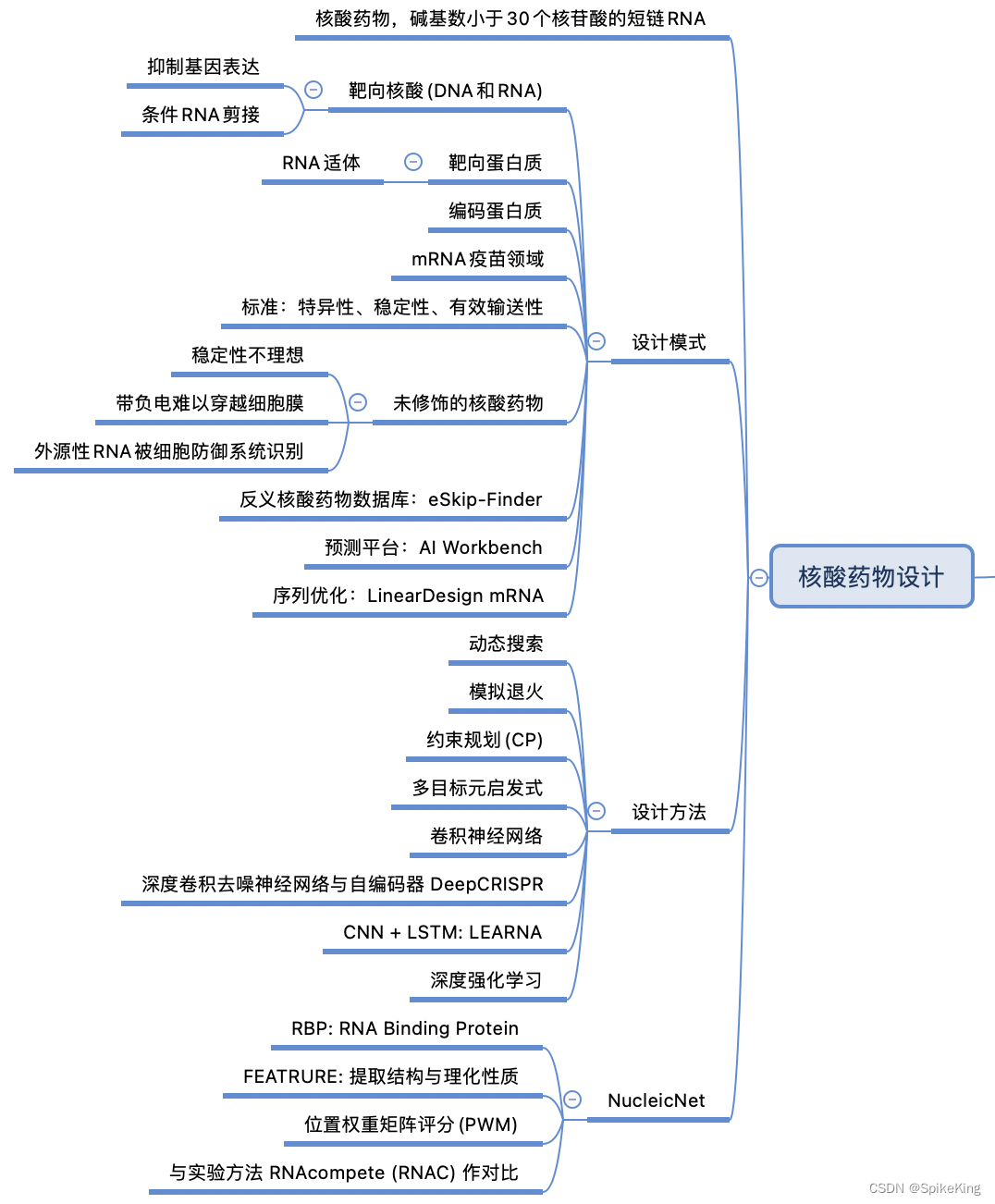
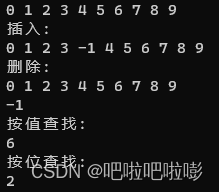
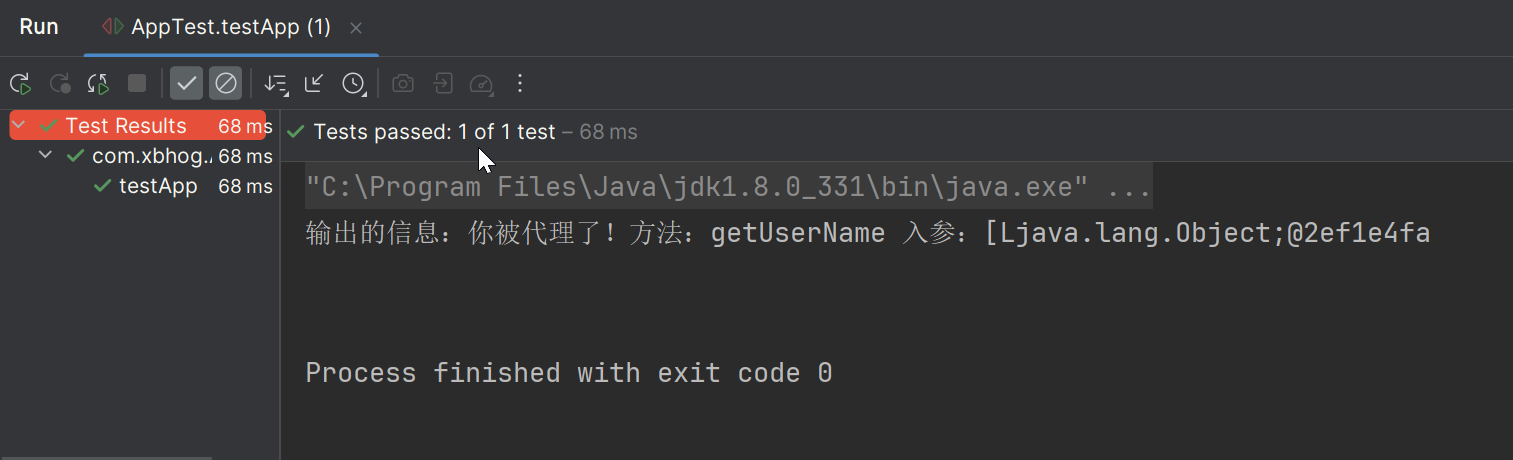
1. 跨代引用概述
在Java堆内存中,年轻代和老年代之间存在的对象相互引用,假设现在要进行一次新生代的YGC,但新生代中的对象可能被老年代所引用的,为了找到新生代中的存活对象,不得不遍历整个老年代。这样明显效率很低下,那么如何快速识别并回收这种引用对象呢?

这就不得不提到Card Table(卡表)和 Remember Set(记忆集,简称RSet)了。
2. 跨代引用的处理方式
2.1 卡表(Card Table)
卡表是一种用于跟踪年轻代对象被老年代对象引用的数据结构。它将堆内存划分为一系列固定大小的区域(卡片),每个卡片记录了年轻代对象被老年代对象引用的情况。在老年代垃圾回收时,垃圾收集器会扫描卡表,以确定哪些年轻代对象是存活的,即被老年代对象引用。
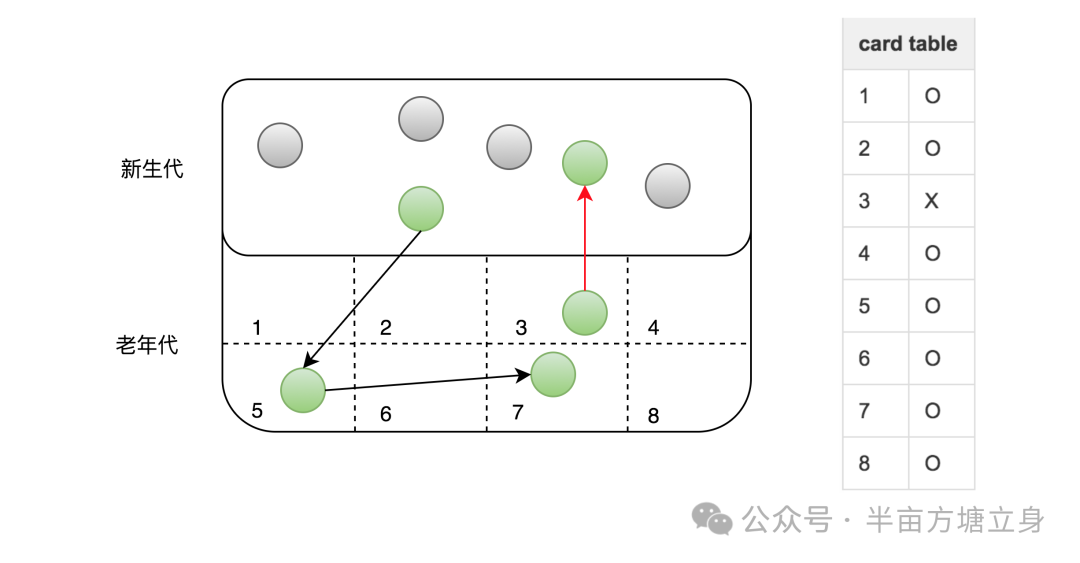
在 JVM 中,一个 card 的大小(通常是)512字节。在多线程并行收集时,每个线程可以批量扫描多个 card,一批 card 被称为一个 stride。默认一个 stride 含有 256个 card,即每个线程要每次扫描 512 * 256 = 128 K 的内存区域。stride数量太多就会导致线程在stride之间切换的开销增加,进而导致 GC Pause 增长, strides 太少恐怕也会导致单次扫描的时间增长,进而影响整个 GC Pause 。
2.2 记忆集(Remembered Sets)
伴随 G1 垃圾收集器的诞生,传统的老年代和新生代都从物理上的连续空间,变成了一个个物理上不连续的空间 region。
JVM 针对这些Region 提供了一个数据结构,也就是 CSet(Collection Set),存储任意年代的region。
物理上不连续的 region 造成了新生代和老年的引用破碎化,新生代引用老年代,所以产生了 old->young和young->old的跨代对象引用,这时候 JVM 只要扫描 CSet 中的 R Set 即可。
逻辑上说每个Region都有一个RSet,RSet记录了其他Region中的对象引用本Region中对象的关系。
每个Region会在自身的Remembered Set中纪录下来自其他Region的指向自身的Card位置。这个Remembered Set是一个Hash Table,Key是别的Region的起始地址,Value是一个集合,里面的元素是Card Table的Index。
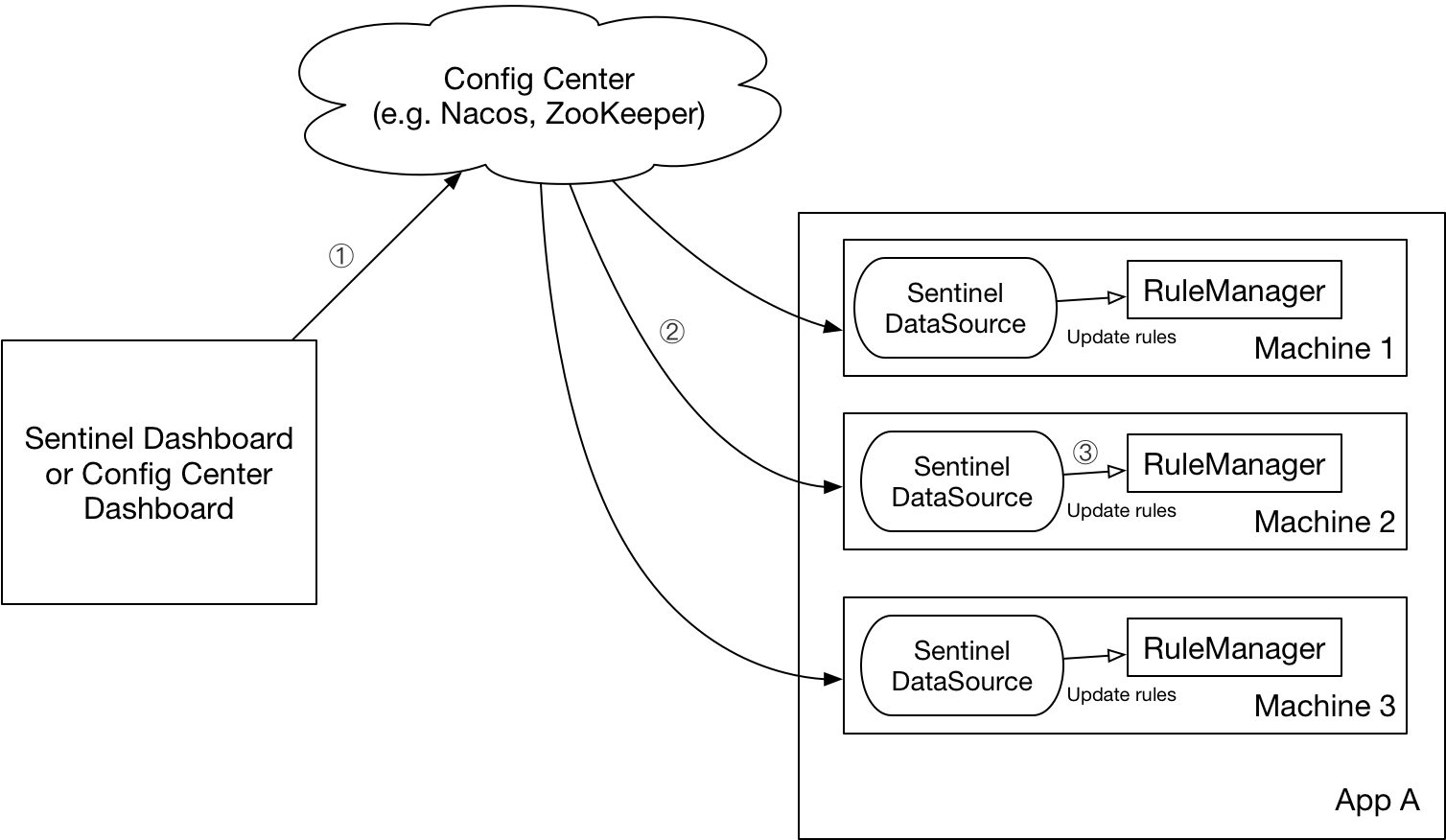
RSet、Card和Region的关系
下图表示了RSet、Card和Region的关系:
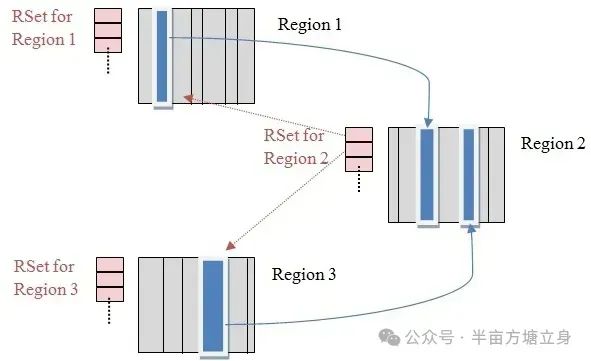
图中是相互引用的三个region。R1 和 R3 的被细分到了card table 级别。R2 被 R1 和 R3的某些区域引用,所以 R2 的 RSet 会记录到 R1 和 R2 的区域索引,即产生某些循环引用的作用。
一个 Region 的 RSet 如果有值,至少可以证明这个区域是有引用的;一个区域如果无值,则可以认为这个区域不可达,可以不扫描这个区域(Card Table 可以减少 Minor GC 扫描 old 区来理解 young 区的时间,RSet 则可以减少扫描生成 CSet 选取候选 region 的时间)。
在做YGC的时候,只需要选定young generation region的RSet作为根集,这些RSet记录了old->young的跨代引用,避免了扫描整个old generation。而mixed gc的时候,old generation中记录了old->old的 RSet,young->old的引用由扫描全部young generation region(的 card table)得到,这样也不用扫描全部old generation region。所以RSet的引入大大减少了GC的工作量。
2.3 处理器屏障(Processor Barriers)
处理器屏障是一种硬件支持的机制,用于跟踪对象之间的引用关系。当发生引用修改时,处理器屏障可以监测到对内存的访问,并通知垃圾收集器。垃圾收集器可以根据这些信息来更新引用关系,确保跨代引用被正确处理。
3. 总结
卡表只解决 youngGC 扫老年代的问题,而 RSet 则解决了(G1 对)所有 Region 的扫描问题。卡表通过对外引用提示我们应该扫描什么区域,这样我们可以避开不用扫描的区域;RSet通过对内引用提示我们应该扫描什么区域,这样我们可以避开不用扫描的区域。
跨代引用的垃圾回收是Java虚拟机中一个复杂而重要的问题。通过合理设计和优化记忆集、卡表等数据结构,并结合并发标记-清除算法、处理器屏障等技术,可以有效地处理跨代引用,保证垃圾回收的效率和稳定性,从而提高Java应用程序的性能和可靠性。