前言
2023 年,Ultralytics 推出了最新版本的 YOLO 模型。注意力机制是提高模型性能最热门的方法之一。
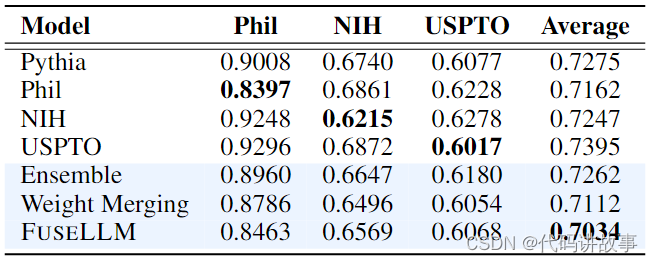
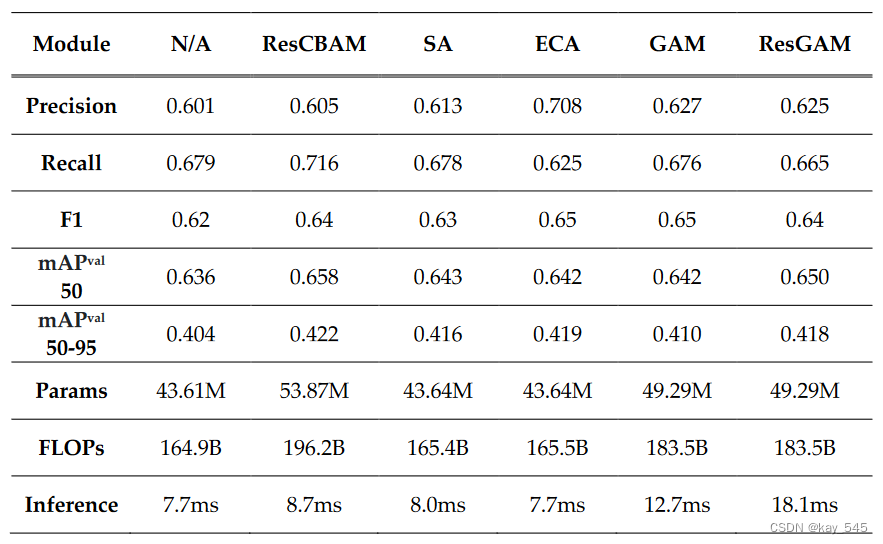
本次介绍的是YOLOv8-AM,它将注意力机制融入到原始的YOLOv8架构中。具体来说,我们分别采用四个注意力模块:卷积块注意力模块(CBAM)、全局注意力机制(GAM)、高效通道注意力(ECA)和随机注意力(SA)来设计改进模型并在数据集上进行测试。实验结果表明,基于ResBlock + CBAM(ResCBAM)的YOLOv8-AM模型在IoU 50(mAP 50)下的平均精度提到了2.2%,达到了state-of-the-art(SOTA)表现。相反,结合GAM的YOLOv8-AM模型获得了的mAP @50并不是一个令人满意的增强。因此,我们将ResBlock和GAM结合起来,引入ResGAM设计另一个新的YOLOv8-AM模型,获得一个较为满意的结果。
目录
前言
注意力机制:
Convolutional Block Attention Module
Efficient Channel Attention
Shuffle Attention
Global Attention Mechanism
实验结果(供参考)
可论文指导--------->v jiabei-545
改进代码(失效+ v 👆)
注意力机制:

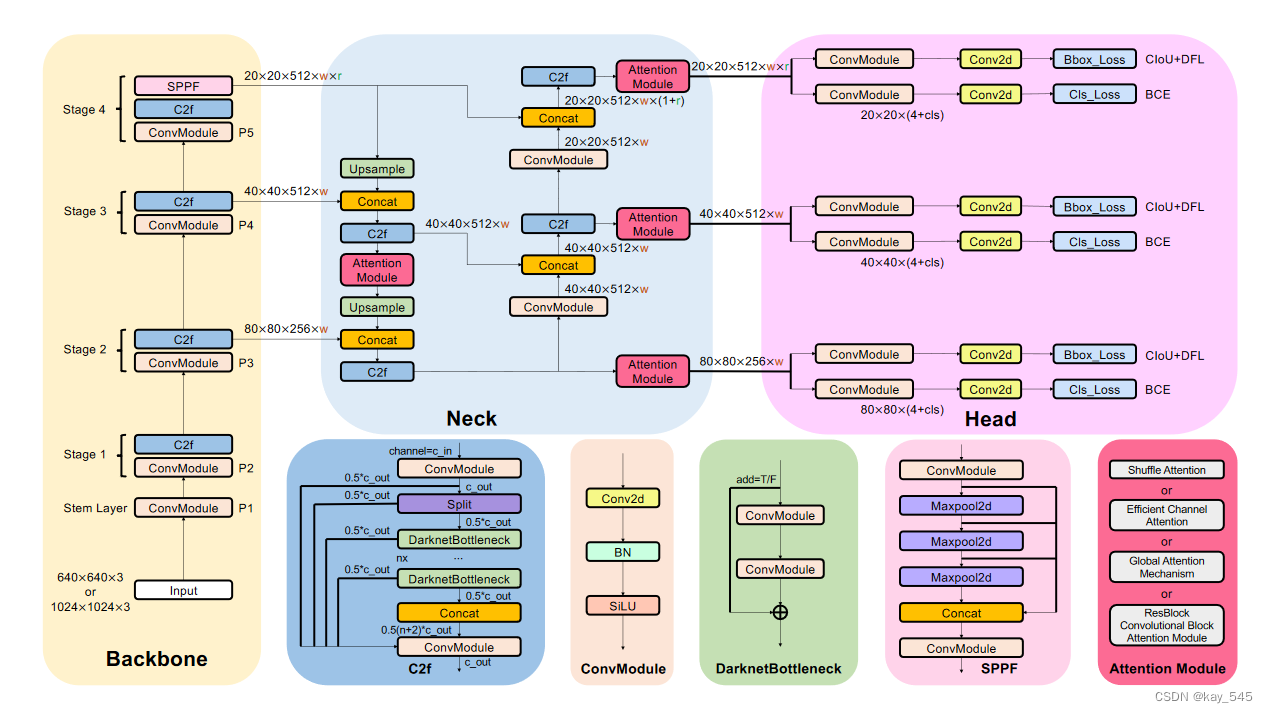
YOLOv8 架构由四个关键组件组成:Backbone、Neck、Head 和 Loss Function。 Backbone 融合了 Cross Stage Partial (CSP) 概念,具有减少计算负载、同时增强 CNN 学习能力的优势。如图所示,YOLOv8与采用C3模块的YOLOv5不同,采用C2f模块,该模块集成了C3模块和YOLOv7中的扩展ELAN(E-ELAN)概念。
Convolutional Block Attention Module

CBAM 包括通道注意力(C-Attention)和空间注意力(S-Attention),如图所示。给定一个中间特征图,CBAM 通过等式依次推断出 1D 通道注意力图 和 2D 空间注意力图 。

原理和resnet一样
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 9 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, ResBlock_CBAM, [512]]- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, ResBlock_CBAM, [256]]- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 20 (P4/16-medium)- [-1, 1, ResBlock_CBAM, [512]]- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 24 (P5/32-large)- [-1, 1, ResBlock_CBAM, [1024]]- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)Efficient Channel Attention

ECA 主要包含跨通道交互和具有自适应卷积核的一维卷积,如图 所示。跨通道交互代表了一种组合特征的新方法,增强了特定语义的特征表达。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 9 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, ECAAttention, [512]]- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, ECAAttention, [256]]- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 20 (P4/16-medium)- [-1, 1, ECAAttention, [512]]- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 24 (P5/32-large)- [-1, 1, ECAAttention, [1024]]- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)Shuffle Attention
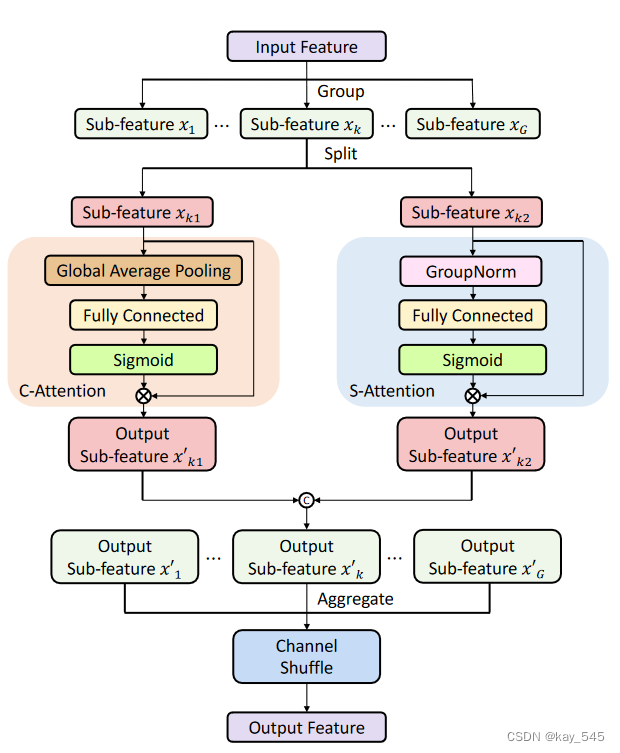
SA将输入特征图分为不同的组,利用Shuffle Unit将通道注意力和空间注意力整合到每个组的一个块中,如图所示。随后,子特征被聚合,并且“ ShuffleNetV2 中使用的“Channel Shuffle”算子用于促进各种子特征之间的信息通信。对于通道注意力,SA 采用 GAP 来捕获和嵌入子特征。此外,使用带有 sigmoid 函数的简单门控机制来创建紧凑的函数,以促进精确和自适应的选择。
# SA.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 9 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, ShuffleAttention, [512]]- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, ShuffleAttention, [256]]- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 20 (P4/16-medium)- [-1, 1, ShuffleAttention, [512]]- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 24 (P5/32-large)- [-1, 1, ShuffleAttention, [1024]]- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)Global Attention Mechanism

GAM采用了CBAM提出的由通道注意力和空间注意力组成的主要架构,并重新设计了子模块,如图所示。此外,我在GAM内的各层之间添加了快捷连接,这使得输入能够更快地向前传播。
# GAM.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 9 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, GAM_Attention, [512,512]]- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, GAM_Attention, [256,256]]- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 20 (P4/16-medium)- [-1, 1, GAM_Attention, [512,512]]- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 24 (P5/32-large)- [-1, 1, GAM_Attention, [1024,1024]]- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
原理和resnet一样
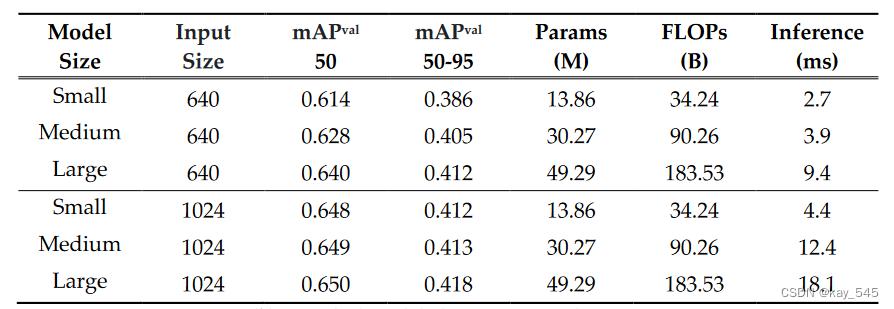
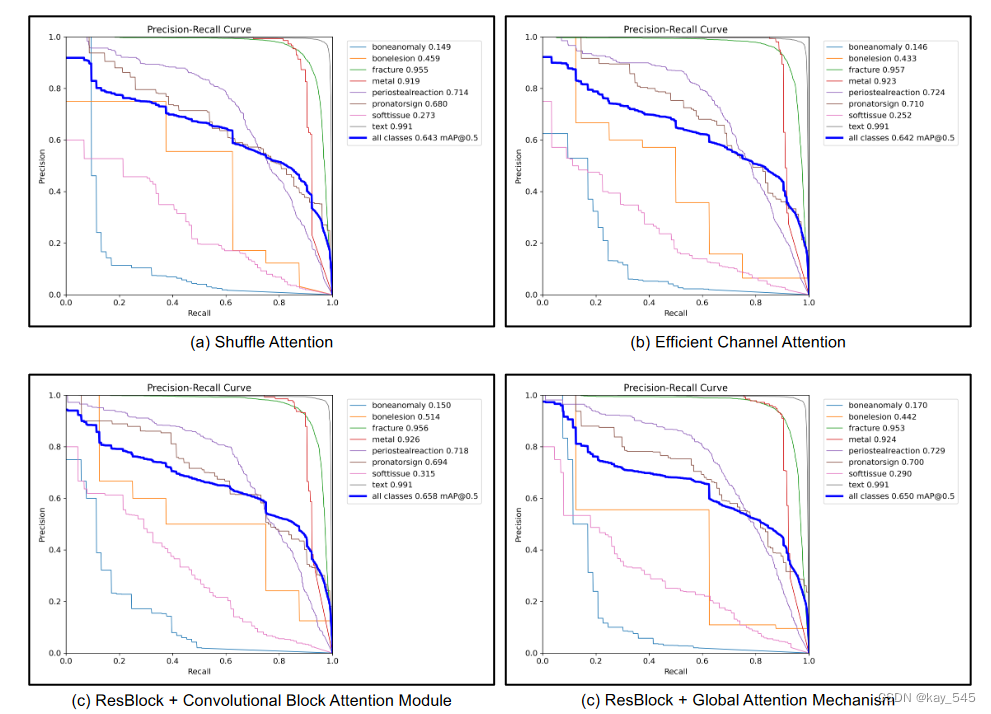
实验结果(供参考)
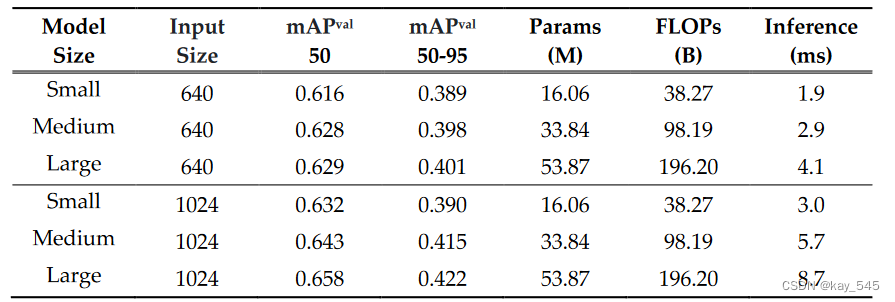

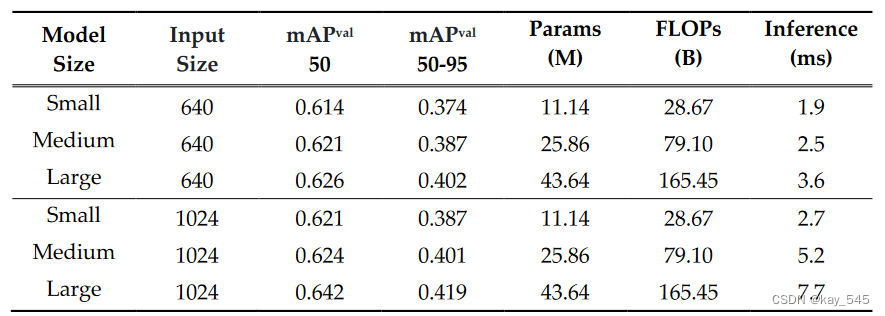

可论文指导--------->v jiabei-545
改进代码(失效+ v 👆)
链接: https://pan.baidu.com/s/1Fi7ghwJ6XiXrDDnoCvlvrQ?pwd=zk88 提取码: zk88
欢迎大家在评论区进行讨论