1.环境搭建:
(a)开发环境:pycharm
(b)虚拟环境(可有可无,优点:使用虚拟环境可以把使用的包自动生成一个文件,其他人需要使用时可以直接选择导入包,不需要额外的环境搭建。缺点:占一丢丢储存)
(c)Django下载,下载到pycharm根目录。打开项目目录,在资源管理器中的项目目录中打开终端,然后直接pip。或者在官网中下载。
(d)创建Django项目:左上角新建Django项目,展开更多设置,可以选择创建html模版,和初始app(填写名字才会创建)。创建项目之后会自动创建很多个py文件

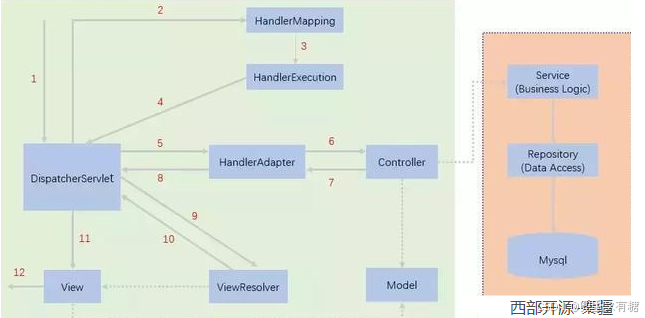
2.HTTP通信过程:
当我们访问地址时

这里访问本地地址,其中8000为端口号,index为路由。
我们指定当我们访问路由为index,我们可以在urls.py中找到路由所对应的视图函数,那么就会自动运行我们的视图函数。例如这里写了路由index对应的函数为index,所以他会去找index函数,这个函数我们写在user.views里,所以我们这里要先进行import导入。

user是我们创建app时写的app名字,后续也可以添加在djangoproject目录里的setting.py文件中:

如果一开始在创建项目的时候写了app名,那么这里就不用写了,否则会报错。
在user这个app里我们创建一个templates文件夹用来储存html模版。

在views.py文件中我们写了视图函数index,并且在我们urls.py中import导入了这个函数库,于是我们会执行这个函数并在这里返回一个html文件。
3.运行项目:
在pycharm中打开终端:在经过上述步骤之后,可以直接输入
python manage.py runserver这会执行我们的整个项目并给予一个地址可以让我们观察项目返回内容。

ctrl+c可以中断这个程序,否则他会一直运行。
4.数据库迁移:
在models.py中写入数据库数据后,在终端中运行
python manage.py makemigrationsmigrations文件夹会多出一个文件。
导入数据后再:
python manage.py migrate迁移数据,这时 在data文件中就可以可视化查询数据库内容并修改。
我们可以在视图文件中导入models函数,models里面我们写的函数就可以拿出来用,这里用到Usermodel函数,加上后缀名objects.all可以返回数据库所有的内容。再利用render,命名一个users(左)来储存users(右)的所有数据并导入html中。

在html中我们就可以利用for循环遍历数据库所有的内容。
html如下:

结果如下:

5.后台管理:
我们在admin.py中导入models的类,再在后台管理系统中运行。

在终端中创建超级用户(管理员):
python manage.py createsuperuser输入账号密码(密码不可视),就能创建成功。路由选择admin打开网址就能打开后台管理系统

里面存储的数据和数据表里的内容一致,可以实时修改。
6.路由传参的页面跳转(反向解析):

首先在urls中的路由里写入传参的形式。
<int:id>这个的意思就是传入的数据是整数,跟在路由后面。比如传入为1,那么网址就是..../detail/1/
传入数据可以直接网址上面传入,也可以在函数中传入例如:
在视图函数中添加:
def detail(request,id):c=Usermodel.objects.get(pk=id)return render(request,'detail.html',{'users':c}这里的c相当于在model中获取了数据,虽然model只写了数据库结构,但是model.objects可以直接导入数据库内容(别管怎么来的,这就是django),再用get方法只获取id的内容。这里获取哪一个呢?根据我们传入的id决定。
id由哪里来?我们写一个html交互数据库,利用循环展示每一个数据的内容。我们点击某一个超链接对应的数据库内容,那么就会获得这个超链接对应的数据库内容的id,把它反向解析到url中。detail是我们提前在urls.py里写好的url的名字。

1.html(name=‘index’):
<!DOCTYPE html> <html lang="en"> <head><meta charset="UTF-8"><title>Title</title> </head> <body> <h1> Hello world </h1> <ul>{% for a in users %}<a href="{% url 'detail' a.id %}" >{{ a.name }},{{ a.age }}</a>{% endfor %} </ul> </body> </html>
detail.html:
<!DOCTYPE html> <html lang="en"> <head><meta charset="UTF-8"><title>Title</title> </head> <body> <h1>{{ users.id }}{{ users.sex }}</h1> </body> </html>
这样我们就可以根据id不同,在同一个页面显示不同的内容。
result:
Rec 0001
再利用反向解析写个返回键:

为什么href不直接跳转到1.html反而要给一个name为index的url地址呢?
直接跳转到html没办法传入数据,但是跳转到路由会先执行视图函数,在视图函数中我们可以先获取数据再返回渲染的html,这样在第二次通过html获取数据的时候才不会报错。不然html不知道在哪里获取数据。