High-Resolution Image Synthesis with Latent Diffusion Models
论文链接
代码链接
What’s the problem addressed in the paper?(这篇文章究竟讲了什么问题?比方说一个算法,它的 input 和 output 是什么?问题的条件是什么)
- 这篇文章提出了一种合成高分辨率图片的潜在空间扩散模型(LDM),解决了在像素空间中优化Diffusion Models时面临的高计算开销问题。
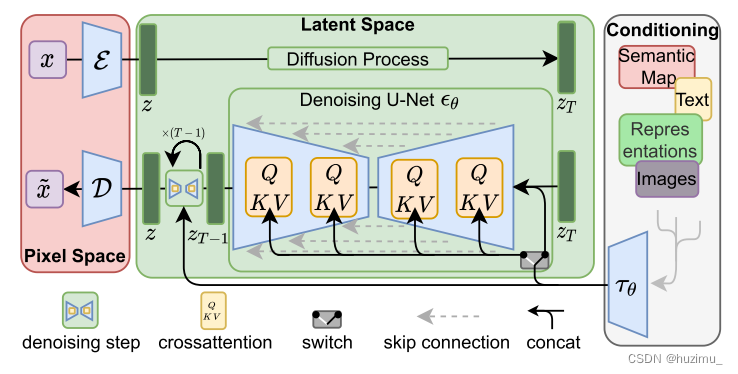
- 下图是LDM的结构流程图,从左到右的三个模块分别是:感知图片压缩(Perceptual Image Compression),潜在扩散模型(Latent Diffusion Model),和条件机制模块(Condition mechanism)。首先,原始图片 x x x在像素空间中被感知压缩模型压缩为潜在空间特征 z z z,然后,Unet通过扩散过程(向 z z z中添加噪声和去除噪声)重构了潜在空间特征 z t z_t zt,其被解码为输出图片 x ~ \tilde{x} x~。在这个过程中,条件机制将输入的条件(例如,文本,图片等)编码为文本嵌入。然后,利用cross-attention机制将条件输入注入到Unet结构中。
Is it a new problem? If it is a new problem, why does it matters? 新问题的话有意义吗?重要吗? If it is not an entirely new problem, why does it still matter? 为什么要研究这个问题/为什么这个问题是重要的
- 不是新问题,但是仍然很重要
- 因为在高分辨率图片数据上进行训练时梯度的计算量很大,而现有的采样和层级化策略无法解决这个问题。
What is the scientific hypothesis that the paper is trying to verify? 这篇文章觉得自己发现了什么新的知识?
- 在一个压缩的潜在空间(compressed latent space)上优化的一个潜在扩散模型,可以高效和低开销地合成高分辨率的图片,在和cross-attention机制结合后,LDM可以有效应用于条件生成任务,包括文本生成图片等任务。
What are the key related works and what are the key people working in this topic?
- Diffusion Models(DMs) & UNet:
Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. CoRR, abs/1503.03585, 2015. - cross attentions
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, pages 5998–6008, 2017 - UNet:
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, pages 5998–6008, 2017 - image compression
Patrick Esser, Robin Rombach, and Bj¨orn Ommer. Taming transformers for high-resolution image synthesis. CoRR,abs/2012.09841, 2020
What’s the key of the proposed solution in the paper? 所提解决方案的关键
- 将在像素空间上优化扩散模型转变为在一个低维潜在空间上优化模型
How are experiment designed?
-
1、分析不同downsampling factors f 对LDMs性能的影响,包括FID,IS等指标(On Perceptual Compression Tradeoffs)
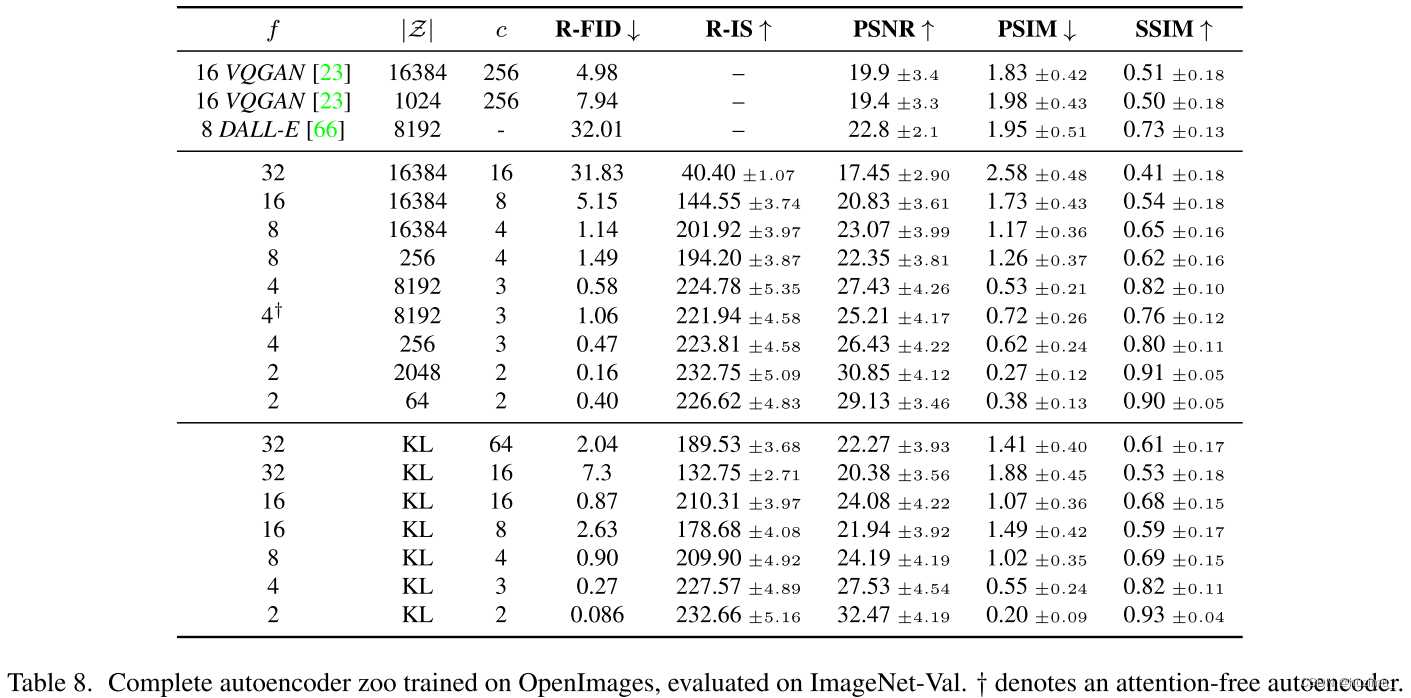
-
2、无条件图片合成评估:在不同数据集上,像素空间上训练的DMs和LDM在图片质量(FID)和有效性(Precision和Recall)上进行比较 (Image Generation with Latent Diffusion)
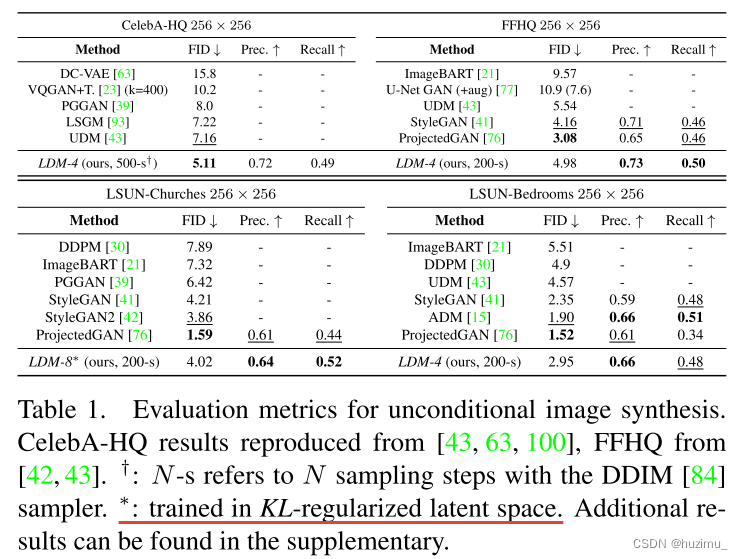
-
3、条件图片合成评估(text-to-image, class-to-image, layout-to-image, image-to-image)(Conditional Latent Diffusion)
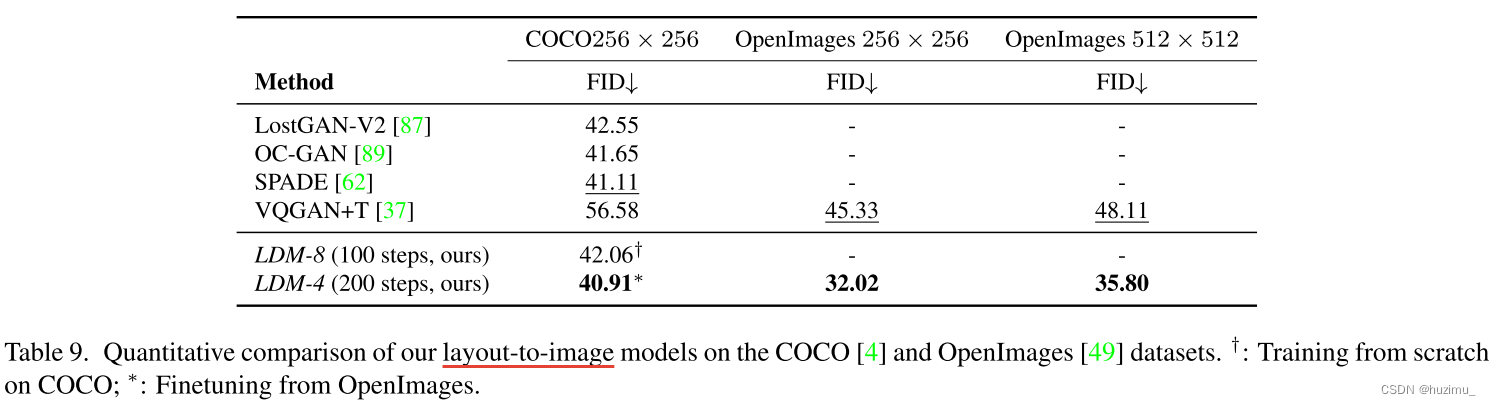
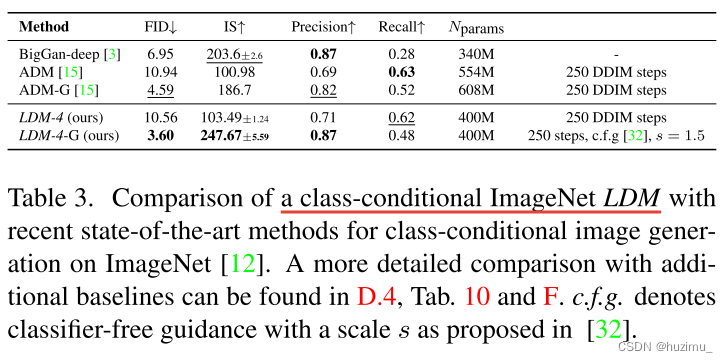
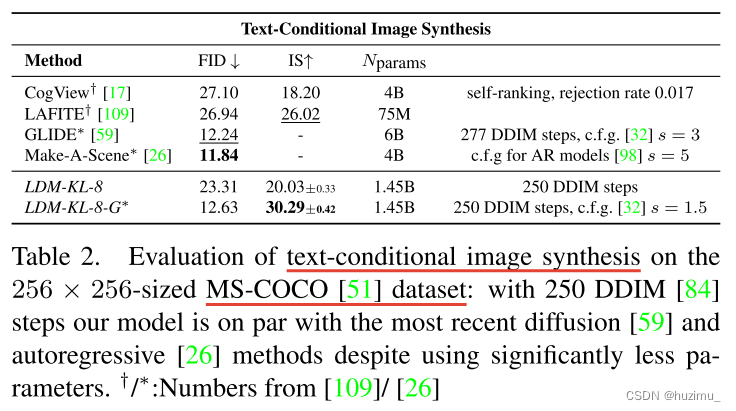
-
4、超分辨率图片合成(在低分辨率数据集上训练的模型可以生成高分辨率图片)(Super-Resolution with Latent Diffusion)
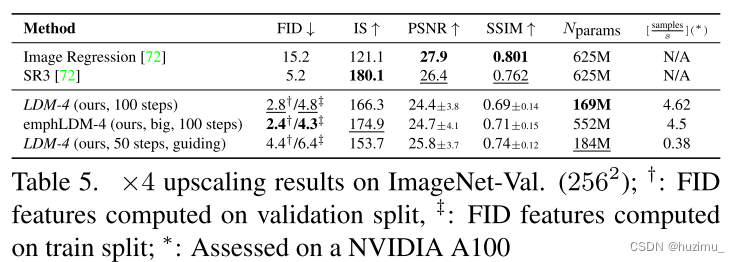
-
5、图片修复任务(Inpainting with Latent Diffusion)
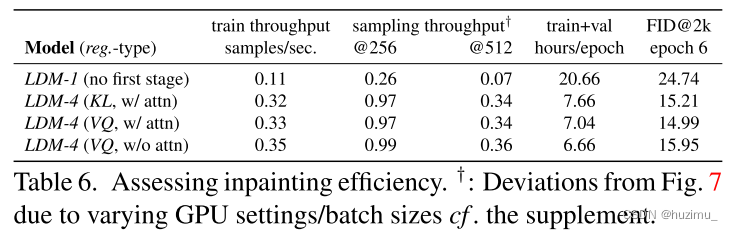

What datasets are used for quantatitiave evaluation? Is the code open sourced?
- 数据集:unconditional:CelebA-HQ [39], FFHQ [41], LSUN-Churches and Bedrooms [102],and ImageNet [12];conditional:LAION-400M [78]
- 评估标准:FID、IS、Precision-and-Recall等
- 代码:https://github.com/CompVis/latent-diffusion
- 基准方法
Is the scientific hypothesis well supported by evidence in the experiments?
- 是。LDM相较于像素空间训练的DMs,大大降低了计算开销,并且在无条件和条件图片合成任务中表现得更好。
What are the contributions of this paper? (try to summarize in your own words)
- 压缩的低维度潜在空间相较于像素空间,在高分辨率图片合成时更能减少计算和时空开销,同时保证图片质量
- 潜在扩散模型(LDM)能够在多种图片合成任务上取得优异的变现(包括无条件和条件生成)
- 开源可复用的代码
What should do next? 这篇文章局限性在哪里,接着它还能怎么做?
- 尽管LDM比基于像素空间的DMs减少了很多计算开销,但是它的序列采样过程仍然比GAN慢
- LDM在像素空间上需要高细粒度精度的任务,LDM仍然存在不足


![[ai笔记12] chatGPT技术体系梳理+本质探寻](https://img-blog.csdnimg.cn/img_convert/cbf42387b2df0c76b16b4f7ac2416fa0.png)