Python数据可视化
一、JSON数据格式
1、定义
2、python数据和JSON数据转换
二、pyecharts
三、折线图
四、地图
五、动态柱状图
一、JSON数据格式
1、定义
- JSON是一种轻量级的数据交互格式。可以按照JSON指定的格式去组织和封装数据
- JSON本质上是一个带有特定格式的字符串
- JSON就是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互

2、python数据和JSON数据转换
如果有中文可以带上:ensure_ascii=False参数来确保中文正常转换

二、pyecharts
- 安装pyecharts
pip install pyecharts
- 打开官方画廊:
https://gallery.pyecharts.org/#/README
三、折线图
- 导入模块:from pyecharts.charts import Line
- 构建图表:line = Line( )
- 生成图表:line.render( )
- 全局配置:line.set_global_opts( )
折线图相关配置项
.add_yaxis相关配置选项
.set_global_opts全局配置选项



案例
需求:美日印三国确诊人数对比折线图
代码示例
# 导入包 import json from pyecharts.charts import Line from pyecharts.options import TitleOpts, LabelOpts# 处理数据 f_us = open("F:/学习资料/Python/黑马/资料/可视化案例数据/折线图数据/美国.txt", "r", encoding="utf-8") us_data = f_us.read() # 美国的全部内容f_jp = open("F:/学习资料/Python/黑马/资料/可视化案例数据/折线图数据/日本.txt", "r", encoding="utf-8") jp_data = f_jp.read() # 日本的全部内容f_in = open("F:/学习资料/Python/黑马/资料/可视化案例数据/折线图数据/印度.txt", "r", encoding="utf-8") in_data = f_in.read() # 印度的全部内容 # 去掉不合json规范的开头 us_data = us_data.replace("jsonp_1629344292311_69436(", "") jp_data = jp_data.replace("jsonp_1629350871167_29498(", "") in_data = in_data.replace("jsonp_1629350745930_63180(", "") # 去掉不合json规范的结尾 us_data = us_data[:-2] jp_data = jp_data[:-2] in_data = in_data[:-2] # json转python字典 us_dict = json.loads(us_data) jp_dict = json.loads(jp_data) in_dict = json.loads(in_data) # 获取trend key us_trend_data = us_dict['data'][0]['trend'] jp_trend_data = jp_dict['data'][0]['trend'] in_trend_data = in_dict['data'][0]['trend'] # 获取日期数据,用于x轴,取2020年(公用) us_x_data = us_trend_data['updateDate'][:314] # 到12.31号 # jp_x_data = jp_trend_data['updateDate'][:314] # 到12.31号 # in_x_data = in_trend_data['updateDate'][:314] # 到12.31号 # 获取确诊数据,用于y轴,取2020年 us_y_data = us_trend_data['list'][0]['data'][:314] jp_y_data = jp_trend_data['list'][0]['data'][:314] in_y_data = in_trend_data['list'][0]['data'][:314] # 生成图表 line = Line() # 构建折线图对象 # 添加x轴数据 line.add_xaxis(us_x_data) # x轴是公用的 # 添加y轴数据 line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False))# 设置全局选项 line.set_global_opts(# 标题设置title_opts=TitleOpts(title="2020美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%") ) # 调用render方法生成图表 line.render("美日印三国确诊人数对比折线图.html") # 关闭文件对象 f_us.close() f_jp.close() f_in.close()运行结果
生成一个 美日印三国确诊人数对比折线图.html 文件


四、地图
- 导入模块:from pyecharts.charts import Map
- 构建图表:map = Map( )
- 生成图表:map.render( )
- 全局配置:map.set_global_opts( )
案例
需求:全国疫情地图
代码示例
# 导入模块 import json from pyecharts.charts import Map from pyecharts.options import *# 读取数据文件 f = open("F:/学习资料/Python/黑马/资料/可视化案例数据/地图数据/疫情.txt", "r", encoding="utf-8") data = f.read() # 关闭文件 f.close() # 取到各省数据 # 将字符串json,转换为字典 data_dict = json.loads(data) # 从字典中取各省份数据 province_data_list = data_dict["areaTree"][0]["children"] # 组装每个省份和确诊人数为元组,并各个省的数据都封装入列表内 data_list = [] # 绘图所需要的数据列表 for province_data in province_data_list:province_name = province_data["name"] # 省份名称province_confirm = province_data["total"]["confirm"] # 确诊人数data_list.append((province_name, province_confirm)) # 创建地图对象 map = Map() # 添加数据 map.add("各省份确诊人数", data_list, "china") # 设置全局配置,定制分段的视觉映射 map.set_global_opts(title_opts=TitleOpts(title="全国疫情地图"),visualmap_opts=VisualMapOpts(is_show=True, # 是否显示is_piecewise=True, # 是否分段pieces=[{"min": 1, "max": 99, "label": "1-99人", "color": "#CCFFFF"},{"min": 100, "max": 990, "label": "100-999人", "color": "#FFFF99"},{"min": 1000, "max": 4999, "label": "1000-4999人", "color": "#FF9966"},{"min": 5000, "max": 9999, "label": "5000-9999人", "color": "#FF6666"},{"min": 10000, "max": 99999, "label": "10000-99999人", "color": "#CC3333"},{"min": 100000, "label": "100000人以上", "color": "#990033"}]) ) # 绘图 map.render("全国疫情地图.html")运行结果
生成一个 全国疫情地图.html 文件

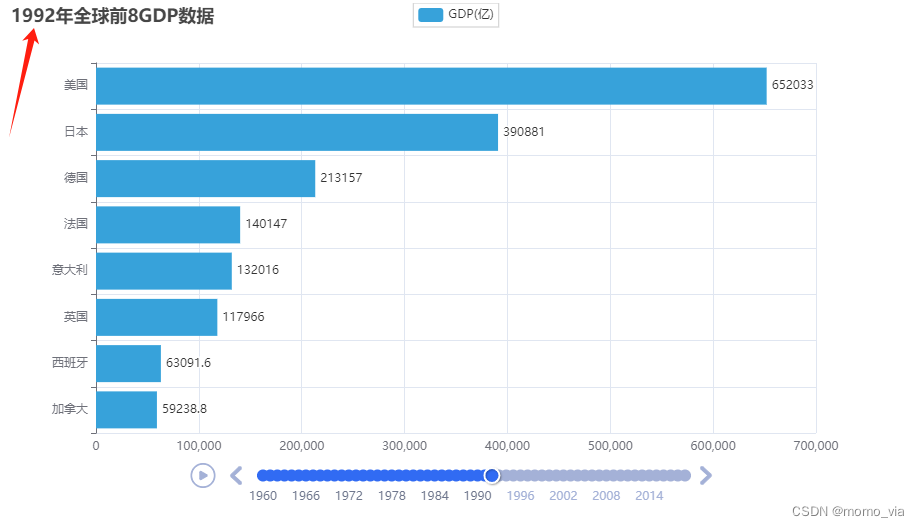
五、动态柱状图
- 导入模块:from pyecharts.charts import Bar,Timeline
- 构建图表:bar= Bar( )
- 创建时间线:timeline = Timeline( )
- 生成图表:bar.render( )
- 标签在右侧:label_opts=LabelOpts(position="right")
- 反转x轴:bar.reversal_axis( )
案例
需求:动态GDP柱状图
代码示例
# 导入模块 from pyecharts.charts import Bar, Timeline from pyecharts.options import * from pyecharts.globals import *# 读取数据 f = open("F:/学习资料/Python/黑马/资料/可视化案例数据/动态柱状图数据/1960-2019全球GDP数据.csv", "r", encoding="GB2312") data_lines = f.readlines() # 关闭文件 f.close() # 删除第一条数据 data_lines.pop(0) # 将数据转换为字典存储,格式为: # 定义一个字典对象 data_dict = {} for line in data_lines:year = int(line.split(",")[0]) # 年份country = line.split(",")[1] # 国家gdp = float(line.split(",")[2]) # gdp数据# 如何判断字典里有没有指定的key?try:data_dict[year].append([country, gdp])except KeyError:data_dict[year] = []data_dict[year].append([country, gdp]) # 创建时间线对象 timeline = Timeline({"theme": ThemeType.LIGHT}) # 排序年份 sorted_year_list = sorted(data_dict.keys()) for year in sorted_year_list:data_dict[year].sort(key=lambda element: element[1], reverse=True)# 取出本年前8名的国家year_data = data_dict[year][0:8]x_data = []y_data = []for country_gdp in year_data:x_data.append(country_gdp[0]) # x轴添加国家y_data.append(country_gdp[1] / 10000000) # y轴添加gdp数据# 构建柱状图bar = Bar()x_data.reverse()y_data.reverse()bar.add_xaxis(x_data)bar.add_yaxis("GDP(亿)", y_data, label_opts=LabelOpts(position="right"))bar.reversal_axis()# 设置每一年标题bar.set_global_opts(title_opts=TitleOpts(title=f"{year}年全球前8GDP数据"))timeline.add(bar, str(year))# 设置时间线自动播放 timeline.add_schema(play_interval=1000,is_timeline_show=True,is_auto_play=True,is_loop_play=False ) # 绘图 timeline.render("1960-2019全球GDP前8国家.html")运行结果
生成一个 1960-2019全球GDP前8国家.html 文件

想要案例资料可以私信我~