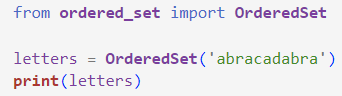
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
先决条件
OpenAI 使用政策
基本 OpenAI 概念
Models
Prompts
Tokens
OpenAI API 中可用的模型
在 Playground 上试用 GPT 模型
入门:OpenAI Python 库的第一步
OpenAI 访问和 API 密钥
使用 OpenAI 的 Hello World
使用 ChatGPT 和 GPT-4
聊天完成端点的输入选项
主要输入参数
对话和tokens的长度
额外的可选参数
聊天完成端点的输出结果格式:
使用其他文本完成模型
文本完成端点的输入选项
主要输入参数
提示和标记的长度
额外的可选参数
文本完成端点的输出结果格式:
使用 GPT 精通文本编辑
审核模型
注意事项
定价和代币限制
安全和隐私:警告!
其他 OpenAI API 和功能:
使用 DALL-E 生成图像
嵌入
Whisper
摘要和备忘单
在本章中,我们将全面探索 GPT-4 和 ChatGPT API 并了解它们的内部组织。我们的目标是让您深入了解 OpenAI API,以便您可以有效地将它们集成到您的 Python 应用程序中。到本章结束时,您将能够自信地进入 API 领域,并在您的开发项目中有效地利用这些 API 的强大功能。
我们将通过介绍 OpenAI playground 开始本章,这将使您能够在实际编写任何代码之前更好地理解模型。接下来,我们将介绍 OpenAI Python 库的第一步,包括访问详细信息和一个简单的 Hello World 示例。然后,我们将逐步完成创建请求并将请求发送到 API 的过程。我们还将研究如何管理 API 响应,以确保我们知道如何解释这些 API 返回的数据。此外,本章还将涵盖安全最佳实践和成本管理等注意事项。随着我们的进步,您将获得实用知识,这些知识将对您作为使用 GPT-4 和 ChatGPT 的 Python 开发人员的旅程非常有用。
先决条件
OpenAI 使用政策
在继续之前,请查看OpenAI 使用政策,如果您还没有,请在OpenAI 主页上创建一个帐户。您还可以查看条款和政策页面上的其他法律文件。
基本 OpenAI 概念
第 1 章中介绍的概念对于使用 OpenAI API 和库也是必不可少的。
Models
OpenAI 提供了几种不同的模型,专为各种任务而设计:这些模型中的每一种都具有不同的功能。此外,这些模型中的每一个都有自己的定价。您将在以下页面找到可用型号的详细比较以及有关如何做出选择的提示。
请注意,有些模型是为文本完成而设计的,而其他模型是为聊天或编辑而设计的,这会影响 API 的使用。例如,ChatGPT 和 GPT-4 背后的模型是基于聊天的。
Prompts
提示的概念在第 1 章中介绍过。提示不是 OpenAI API 的特殊性,而是 LLM 的常见概念。简而言之,提示是您发送给模型的输入文本。提示允许您定义您希望模型执行的任务。对于 ChatGPT 和 GPT-4 模型,提示具有带有消息列表的聊天格式。我们将在本书中回顾这种特定提示格式的细节。
Tokens
与提示一样,标记的概念在第 1 章中进行了描述。标记是单词或单词的一部分。粗略估计,对于英文文本,100 个标记大约等于 75 个单词。处理到 API 的令牌数量会影响 API 调用的总体价格,该数量取决于输入文本和输出文本的长度。您将在详细介绍 OpenAI API 用法的部分中找到有关管理和控制输入和输出令牌数量的更多详细信息。
OpenAI API 中可用的模型
OpenAI API使您可以访问由 OpenAI 开发的多个模型。这些模型作为服务通过 API(通过直接 HTTP 调用或提供的库)提供,这意味着模型由 OpenAI 在远程服务器上运行,开发人员可以简单地向这些模型发送查询。
每个型号都有一组不同的功能和定价。本节简要概述了每个模型,而功能和使用的详细信息将在下一章中介绍。请务必注意,虽然您无法直接访问和修改这些模型的代码以满足您的需要,但可以根据您的特定数据对某些模型进行微调。这允许您基于 OpenAI 可用模型创建自己的模型。
由于 OpenAI 提供的许多模型都在不断更新,因此很难给出它们的完整列表。因此,我们将在这里关注最重要的:
InstructGPT
该系列模型可以理解并生成大量自然语言任务。它包括几个模型:text-ada-001、text-babbage-001、text-curie-001和text-DaVinci-003。Ada只能完成简单的任务,但也是 GPT-3 系列中速度最快、成本最低的机型。和 都babbage 更curie 强大但也更昂贵。DaVinci 能够以优异的品质完成所有的完成任务,但它也是GPT-3车型家族中最昂贵的车型。
ChatGPT
ChatGPT 背后的模型是gpt-3.5-turbo. 这是一个聊天模型;因此,它可以将一系列消息作为输入并返回适当生成的消息作为输出。虽然 的聊天格式gpt-3.5-turbo旨在促进多回合对话,但也可以将其用于没有对话的单回合任务。在单轮任务中,性能gpt-3.5-turbo相当text-DaVinci-003,并且gpt-3.5-turbo价格是其十分之一,具有或多或少相当的性能,建议默认情况下也将其用于单轮任务。
GPT-4
Gpt-4是OpenAI提出的最大的模型。它还在最大的文本和图像多模式语料库上进行了训练。因此,它在许多领域拥有广泛的知识和专业知识。GPT-4 可以遵循复杂的自然语言指令,准确解决难题。它可以用于聊天和单回合任务,精度更高。OpenAI 生产了两个版本的 GPT-4,具有 8k 和 32k 上下文窗口。8k 代币的版本称为gpt-432k 代币的版本gpt-4-32k。
GPT-3.5-turbo 和 GPT-4 都在不断更新。当我们提到模型时gpt-3.5-turbo,gpt-4,我们gpt-4-32k 指的是这些模型的最新版本。还提供静态模型版本,开发人员可以在引入模型后至少使用三个月。在撰写本书时,最新的静态版本是 gpt-3.5-turbo-0301、 gpt-4-0314 和 gpt-4-32k-0314。
正如上一章所讨论的,OpenAI 建议使用 instructGPT 系列而不是原始的 GPT-3 模型。但这些原始模型在 API 中仍然可变,名称为:DaVinci、curie和。使用它们时要小心,因为我们在第 1 章中已经看到它们可以给出奇怪的答案。稍后在讨论微调方法时,我们将重用这些模型。babbageada
请注意,在监督微调阶段之后获得的 SFT 模型(未经过 RLHF 阶段)也可以在名称为 的 API 中使用DaVinci-instruct-beta。
在 Playground 上试用 GPT 模型
无需编码即可直接测试 OpenAI 提供的不同语言模型的一种绝佳方法是使用 OpenAI Playground。它是一个基于 Web 的平台,可让您在特定任务上快速测试 OpenAI 提供的各种大型语言模型。Playground 将使您能够编写提示、选择模型并轻松查看生成的输出。
要访问游乐场:
-
导航到OpenAI 主页,单击“开发人员”,然后单击“概述”。
-
如果您已有帐户但尚未登录,请单击屏幕右上角的“登录”。否则,如果您没有 OpenAI 帐户,则需要创建一个帐户才能使用 Playground 和大多数 OpenAI 功能。单击屏幕右上角的“注册”即可轻松创建帐户。请注意,由于游乐场和 API 使用需要付费,因此您需要提供付款方式。
-
登录后,加入 Playground 的链接将位于网页的左上角。
当你到达比赛场地时,你会看到图2-1。

图 2-1 OpenAI Playground界面 - 文本完成模式
为了便于使用,中央的主屏幕是您输入消息的输入屏幕。写好消息后,按底部的绿色“提交”按钮。这将要求语言模型完成以生成您的消息的以下内容。在图 2-1的示例中,我们写了“正如笛卡尔所说,我认为因此”,在单击“提交”按钮后,模型以“我是”完成了我们的输入。
警告
从现在开始请小心,它并没有那么贵,但每次点击“提交”时,您都会使用您的信用额度。
屏幕的顶部、右侧和底部有许多选项。让我们从屏幕底部开始。提交按钮右侧的第一个按钮是一个简单的撤消操作,用于删除最后生成的文本。在我们的例子中,它将删除“我是”。撤消的右侧是重新生成按钮。这与您直接执行撤消然后提交一样。屏幕底部最后一个有用的按钮是历史记录,其中包含您过去 30 天的所有请求。请注意,一旦进入历史菜单,出于隐私原因,如有必要,很容易将其删除。
右侧部分包含您使用的界面和模型的不同选项。我们只会在这里解释其中的一些选项。其中一些将在本书后面描述。右侧的第一个下拉列表是“模式”。最初,我们默认处于“完成”模式。其他可用模式是“聊天”、“插入”和“编辑”。
正如您已经看到的,在 playground 的默认模式下,语言模型会尝试完成用户在主屏幕上输入的提示内容。
图2-2 给出了在聊天模式下使用 playground 的示例。在左侧的这种模式下,我们有一个名为“系统”的新部分。在这部分中,您可以描述聊天系统的行为方式。例如,在图2-2中,我们要求做一个爱猫的好帮手。我们还要求系统总是谈论这些猫并给出简短的回答。然后就可以在中央屏幕上与我们的聊天机器人聊天,正如您所看到的,我们的聊天机器人喜欢猫!如果您希望继续与系统对话,只需单击“添加消息”,输入您的消息,然后单击“提交”。右边也可以定义文本补全使用的模型,这里我们使用GPT-4。并非所有型号都适用于所有模式;例如,在“聊天”模式下,只有 GPT-4 和 GPT-3.5-turbo 可用。
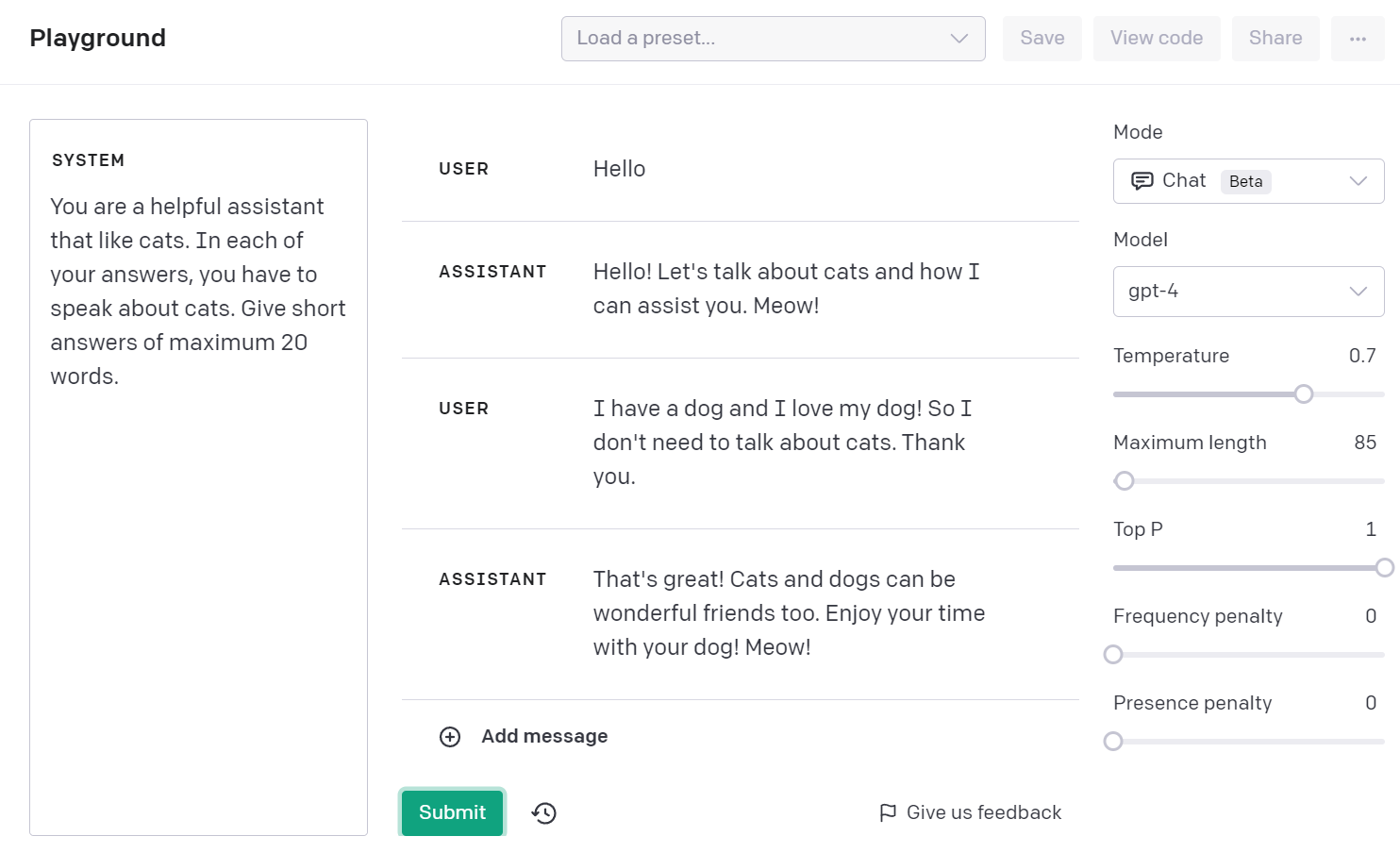
图 2-2 OpenAI playground 界面——聊天模式
Playground 中可用的第三种模式是“插入”模式,如图2-3 所示。您可以在此模式下将内容插入现有文本,而不是仅仅从提示中完成现有文本。如下例所示,在此模式下,您可以在文本中使用标记[insert]来指示您希望语言模型在何处插入新文本。文本显示在右侧,您可以在其中看到生成的绿色文本。在编写长文本、段落之间的过渡或将模型引到结尾时,自然会需要这种插入模式。您只能使用一个 [insert] 来指示应在何处插入文本。添加后 [插入]在正文中,可以分为两部分。[insert] 左边的部分称为“提示”,[insert] 之后的文本称为“后缀”。

图 2-3 OpenAI playground界面 - 插入模式
操场上最后一个可用的模式是“编辑”。在这种模式下,如图2-4 所示,您提供一些文本和说明,模型将尝试对其进行相应的修改。在下面的示例中,描述了一个正在旅行的年轻人的文本。该模型被指示为一位年长的女性改编文本,您可以看到结果符合说明。

图 2-4 OpenAI playground界面 - 编辑模式
在Playground界面的右侧,'Mode'下拉列表下方是'Model'下拉列表。正如您已经看到的,这是您选择大型语言模型的地方。下拉列表中的可用模型列表取决于所选模式。如果您查看“模型”下拉列表下方,您将看到定义模型行为的参数,例如“温度”。我们不会在这些部分中详细介绍这些参数。当我们仔细检查这些不同模型的工作原理时,将描述其中的大多数。
屏幕顶部包含一个下拉列表“加载预设...”和四个按钮。
在上面的示例中,我们使用 LLM 来完成句子“正如笛卡尔所说,我认为因此”,但是可以通过使用适当的提示让模型执行特定的任务。由于有时很难知道使用哪个提示来执行特定作业,图 2-5中的下拉列表提供了模型可以执行的常见任务列表,并与预设示例相关联。

图 2-5 示例下拉列表
应该注意的是,建议的预设示例不仅定义了提示,还定义了屏幕右侧的一些选项。例如,点击“Grammatical Standard English”,主窗口会出现如图2-6 所示提示。
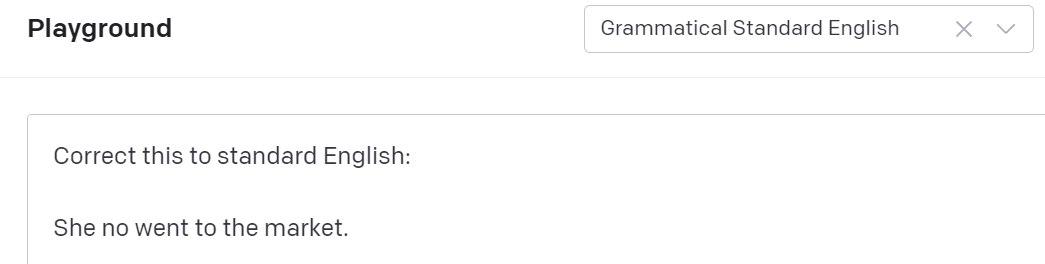
图 2-6 “语法标准英语”的示例提示
如果您执行“提交”,您将获得以下响应:“她没有去市场。” 您可以使用下拉列表中建议的这些提示作为起点,但您始终必须修改它们以适应您的问题。
OpenAI 还提供了针对不同任务的完整示例列表。
下拉列表“加载预设...”旁边是“保存”按钮。想象一下,您已经为您的任务定义了一个带有模型及其参数的有价值的提示,并且您希望稍后在 Playground 中轻松地重用它。此“保存”按钮会将 Playground 的当前状态保存为预设。您可以为您的预设命名和描述,保存后,您的预设将出现在下拉列表“加载预设...”中
界面顶部倒数第二个按钮称为“查看代码”。它提供了在 Playground 中直接将测试运行到脚本中的代码。您可以在 Python、node.js 或直接在 curl 中请求代码,以直接与 Linux 终端中的 OpenAI 远程服务器交互。如果询问以“如笛卡尔所说,我认为因此”开头的示例的 Python 代码,我们将得到以下内容:
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Completion.create( model="text-DaVinci-003", prompt="As Descartes said, I think therefore", temperature=0.7, max_tokens= 3, top_p=1, frequency_penalty=0, presence_penalty=0
)本节介绍了 OpenAI Playground,它是一个方便、用户友好的平台,无需编码即可测试 OpenAI 语言模型。探索了 Playground 中的不同模式和选项,突出了它在处理不同任务和生成所需输出方面的多功能性。本节还讨论了如何保存自定义预设、查看集成代码示例以及将预设示例用于特定任务。
入门:OpenAI Python 库的第一步
本节将讨论如何获取和管理 OpenAI 服务的 API 密钥。通过展示如何在小型 Python 脚本中使用这些密钥进行简单的 API 使用,本节还将允许我们使用此 OpenAI API 进行首次测试
GPT-4 和 ChatGPT 由 OpenAI 作为服务提供。这意味着用户无法直接访问模型的代码,也无法在自己的服务器上运行模型。然而,OpenAI 管理着他们模型的部署和运行,用户可以调用这些模型,前提是他们有一个账户和密钥。
对于接下来的步骤,请确保您已登录 OpenAI 网页。
OpenAI 访问和 API 密钥
OpenAI 要求您拥有 API 密钥才能使用其服务。此密钥有两个用途:首先,它授予调用 API 方法的权利,其次,它将您的 API 调用链接到您的帐户以用于计费目的。只有使用此密钥才能从您的应用程序调用 OpenAI 服务。
要获取 OpenAI API 密钥,请导航至OpenAI 平台页面。在右上角,单击您的帐户名末尾,然后单击“查看 API 密钥”,如图2-7所示。

图 2-7。OpenAI 菜单选择“查看 API 密钥”
当您在“ API keys ”页面上时,单击“ Create new secret key ”并复制您的密钥。这个密钥是以'sk-'开头的一长串字符。
警告
请妥善保管此密钥,因为它直接链接到您的帐户,被盗的密钥可能会导致不必要的费用。
获得密钥后,最佳做法是将其导出为环境变量。这将允许您的应用程序访问 API 密钥,而无需直接在您的代码中写入它。
在 Linux 环境下:
// set environment variable OPENAI_API_KEY for current sessionexport OPENAI_API_KEY=sk-(...)
// check that environment variable was set
echo $OPENAI_API_KEY在 Windows 环境中:
// set environment variable OPENAI_API_KEY for current sessionset OPENAI_API_KEY=sk-(...)
// check that environment variable was set
echo %OPENAI_API_KEY%此代码片段将设置一个环境变量,并使您的密钥可用于从同一 shell 会话启动的其他进程。对于 Linux 系统,也可以将此行直接添加到您的 .batchrc 文件中。这将允许在所有 shell 会话中访问您的环境变量。
要在 Windows 11 中永久添加/更改环境变量,请同时按“Windows+R”。它将打开“运行程序或文件”窗口。在此窗口中,键入“sysdm.cpl”直接转到“系统属性”面板,然后单击“高级”选项卡,然后单击“环境变量”按钮。在那里,您可以使用您的 OpenAI 密钥添加一个新的环境变量。
现在您已经有了密钥,是时候使用 OpenAI API 编写您的第一个 Hello World 了。
使用 OpenAI 的 Hello World
本节将展示 OpenAI Python 库的第一行代码。我们将从一个经典的 Hello World 示例开始,以了解 OpenAI 如何提供其服务。
可以使用 pip 轻松安装此 Python 库:
pip install openai接下来,可以在 Python 中直接访问 OpenAI API:
import openai
# call the openai ChatCompletion endpoint
response = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=[{"role": "user", "content": "Hello World!"}]
)
# extract the response
print(response['choices'][0]['message']['content'])输出结果:
Hello there! How may I assist you today?
恭喜!您刚刚使用 OpenAI Python 库编写了您的第一个程序。
我们将在接下来的段落中详细介绍使用该库的细节。
您会注意到此代码段中未引用 OpenAI API 密钥。
实际上,OpenAI 库默认会查找“OPENAI_API_KEY”环境变量。另一种选择是直接使用以下代码片段进行设置:
# 加载你的 API 密钥
openai.api_key = os.getenv("OPENAI_API_KEY")OpenAI Python 库还提供了一个命令行实用程序。以下代码在终端中运行,相当于使用前面的 Hello World 示例:
openai api chat_completions.create -m gpt-3.5-turbo -g user "Hello world"笔记
还可以通过 HTTP 请求或官方 Node.js 库以及其他社区维护的库与 OpenAI API 进行交互。
使用 ChatGPT 和 GPT-4
本节将详细介绍如何将在 ChatGPT 和 GPT-4 模型后面运行的模型与 OpenAI Python 库一起使用。
GPT 3.5 Turbo 模型是目前最便宜和最通用的。因此,它也是大多数用例的最佳选择。下面是它的使用示例。
import openai# For GPT 3.5 Turbo, the endpoint is ChatCompletionopenai.ChatCompletion.create(# For GPT 3.5 Turbo, the model is “gpt-3.5-turbo”model="gpt-3.5-turbo",# Conversation as a list of messages. messages=[{"role": "system", "content": "You are a helpful teacher."},{"role": "user", "content": "Is there other measures than time complexity for an algorithm?"},{"role": "assistant", "content": "Yes, there are other measures besides time complexity for an algorithm, such as space complexity."},{"role": "user", "content": "What is it?"}])在此示例中,您使用最少数量的参数,即用于进行预测的 LLM 和输入消息。正如我们在此示例中所见,输入消息中的对话格式允许将多个交换发送到模型。请注意,不会存储发送到模型 API 调用的消息。问题“What is it?"指的是以前的答案,只有在模型知道这个答案的情况下才有意义。每次都必须发送整个对话以模拟聊天会话。我们将在下一节中详细介绍输入选项。
GPT 3.5 Turbo 和 GPT-4 模型针对聊天会话进行了优化,但这不是强制性的。它们也适用于传统的完成任务。两种模型均可用于多轮对话和单轮任务。要使用它来完成,你只需要在内容部分有提示的消息中放置一个角色。通过这种方式,它将自动表现得像一个经典的完成模型。之前经典的Hello World例子就是使用ChatGPT补全的例子。
ChatGPT 和 GPT-4 模型都使用相同的端点openai.ChatCompletion。更改模型 ID 将允许开发人员在 GPT-3.5 Turbo 和 GPT4 之间切换,而无需更改任何其他代码。
聊天完成端点的输入选项
我们现在将更详细地介绍如何使用openai.ChatCompletion端点及其create 方法。
笔记
该
create方法允许用户调用 OpenAI 模型。其他方法可用,但对与模型交互没有帮助。要查看,您可以访问 OpenAI 的 Github Python 库存储库上的 Python 库代码。
主要输入参数
model string
要使用的模型的 ID。目前,可用的模型有:
gpt-4、gpt-4-0314、gpt-4-32k、gpt-4-32k-0314、gpt-3.5-turbo、gpt-3.5-turbo-0301
可以访问可用模型列表;model_lst = openai.Model.list().
请注意,并非所有可用模型都与 ChatCompletion 端点兼容。
messages array
这是表示对话的消息对象数组。消息对象有两个属性:角色(可能的值为“系统”、“用户”和“助手”)和内容(包含对话消息的字符串)。
对话以可选的系统消息开始,然后是交替的用户和助理消息。消息如下:
-
系统消息有助于设置助手的行为。
-
用户消息相当于用户在 ChatGPT 网络界面中键入问题或句子。它们可以由应用程序的用户生成或设置为指令。
-
助手消息有两个作用:要么存储先前的响应以继续对话,要么可以设置为指令以提供所需行为的示例。模型对过去的请求没有任何记忆,因此必须存储先前的消息才能为对话提供上下文并提供所有相关信息。
对话和tokens的长度
有必要仔细管理对话的长度。如前所述,对话的总长度将与令牌总数相关。这将对以下方面产生影响:
花费 : 定价是通过tokens,
时机 :tokens越多,响应就越需要一些时间,
最后,模型是否有效
令牌总数必须低于模型的最大限制。您可以在注意事项部分找到令牌限制示例。
OpenAI 提供了一个名为tiktoken的库,它允许开发人员计算文本字符串中有多少个标记。我们强烈建议在调用端点之前使用此库来估算成本。
您可以通过管理消息的长度并通过参数控制输出令牌的数量来控制输入令牌的数量,max_token 如下一段所述。
额外的可选参数
OpenAI 提供了其他几个选项来调整您与库的交互方式。我们不会在这里详细介绍所有参数,但我们建议您查看以下列表:
temperature number (default: 1, accepted values between 0 and 2)
LLM 通过一次预测一系列标记来生成答案。根据输入上下文,他们为每个潜在标记分配概率。在大多数情况下,只有少数标记有意义,而其余标记的概率接近于零。当 temperature 参数设置为 0 时,LLM 将始终选择概率最高的 token。随着温度的升高,模型不再那么关注概率最高的标记。它允许更多样和创造性的输出。温度为 0 意味着响应是确定性的,对模型的调用将始终为给定输入返回相同的完成。值越高,完成的随机性就越高。
n integer (default: 1)
使用此参数,可以为给定的输入消息生成多个聊天完成。但是,请注意,不能保证所有选择都会不同。例如,输入参数中的温度为 0,您将得到多个响应,但它们都是相同的。
stream boolean (default: false)
顾名思义,此参数将允许答案采用流格式。这意味着将发送部分消息增量,就像在 ChatGPT 界面中一样。有关示例,请参见第 3 章。
max_tokens integer
这是在聊天完成时生成的最大令牌数。此参数是可选的,但我们强烈建议将其设置为一种良好做法,以控制您的成本。请注意,如果此参数太高,则可能会被忽略或不遵守:输入和生成的令牌的总长度受模型令牌限制的限制。
您可以在官方文档页面上找到更多详细信息和其他参数。
聊天完成端点的输出结果格式:
现在您已经掌握了查询基于聊天的模型的所有信息,让我们看看如何使用这些结果。
Hello World 示例的完整响应是以下 Python 对象:
{"choices": [{"finish_reason": "stop","index": 0,"message": {"content": "Hello there! How may I assist you today?","role": "assistant"}}],"created": 1681134595,"id": "chatcmpl-73mC3tbOlMNHGci3gyy9nAxIP2vsU","model": "gpt-3.5-turbo","object": "chat.completion","usage": {"completion_tokens": 10,"prompt_tokens": 11,"total_tokens": 21}我们将检查所有生成的输出。
choices array of “choice” object
这是响应的基本部分:此数组包含模型的实际响应。默认情况下,这个数组只有一个元素,可以用参数n改变(见上一段)。这个元素包含
finish_reason string
模型回答结束的原因。在我们的“Hello World”示例中,我们可以看到finish_reason isstop 这意味着我们收到了来自模型的完整响应。如果在输出生成过程中出现错误,它将出现在该字段中。
index integer
选择数组中选择对象的索引。
message object
消息对象包含两个属性:角色和内容。角色永远是助理,内容包括模型生成的文本。通常我们要获取的是这个字符串:response['choices'][0]['message']['content']
created timestamp
生成时时间戳格式的日期。在我们的“Hello World”示例中,此时间戳转换为 2023 年 4 月 10 日星期一下午 1:49:55。
id string
OpenAI 内部使用的技术标识符。
model string
使用的模型。这与模型设置为输入相同
object string
应该始终chat.completion用于 GPT-4 和 GPT3.5 模型,因为我们正在使用 chat.completion 端点。
usage string
usage 对象很重要:它提供有关此查询中使用的令牌数量的信息,因此为您提供定价信息。表示prompt_tokens 输入中使用的标记数, 是completion_tokens 输出中的标记数,您可能已经猜到了, total_tokens = prompt_tokens + completion_tokens
如果您希望有多个选择并使用n 大于一个的参数,您会注意到该prompt_tokens 值不会改变,但该completion_tokens 值将大致乘以n。
使用其他文本完成模型
如前所述,OpenAI 提供了 GPT-3 和 GPT-3.5 系列中的多个其他模型。这些模型使用与 ChatGPT 和 GPT-4 模型不同的端点。尽管 GPT 3.5 Turbo 通常是价格和性能方面的最佳选择,但了解如何使用完成模型也很有帮助。这对于某些用例来说可能是正确的,例如微调,其中 GPT-3 补全模型是唯一的选择。
文本补全和聊天补全之间存在本质区别:正如您可能猜到的那样,两者都生成文本,但聊天补全针对对话进行了优化。
正如您将在以下代码片段中看到的,与openai.ChatCompletion 端点的主要区别在于提示格式。基于聊天的模型必须是对话格式;对于完成,它是一个单一的提示。
import openai
# call the openai Completion endpoint
response = openai.Completion.create(model="text-DaVinci-003",prompt="Hello World!"
)
# extract the response
print(response['choices'][0]['message']['content'])此代码片段将输出一个完成,例如:
"\n\nIt's a pleasure to meet you. I'm new to the world"但是,您仍然可以以对话方式与文本完成模型进行交互。
如果使用第一章的提示示例:
Explain what is meant by time complexity.您可能不会得到问题的答案,而是像这样完成:
Explain what is meant by space complexity. Explain what is meant by the big-O notation.但是,提示:
Question: Explain what is meant by time complexity.
Answer:会给你满意的答复:
Time complexity is a measure of how long it takes an algorithm to run in terms of the amount of time required to execute each step.这些是提示工程技术,将在第 4 节中介绍.
我们将在下一节中详细介绍此端点的输入选项。
文本完成端点的输入选项
的输入选项集openai.Completion.create 与我们之前在聊天端点中看到的非常相似。同样,我们将通过主要输入参数,考虑提示长度的影响
主要输入参数
model string Required要使用的模型的 ID,完全像openai.ChatCompletion 这是唯一必需的选项。
prompt string or array (default: <|endoftext|>)生成补全的提示。openai.ChatCompletion 这是与端点的主要区别.它应该被编码为字符串、字符串数组、标记数组或标记数组数组。如果没有向模型提供提示,它将像从新文档的开头一样生成。
max_tokens integer这是在聊天完成时生成的最大令牌数。此参数的默认值为 16,对于某些用例而言可能太低,应根据您的需要进行调整。
suffix string (default: null)完成后出现的文本。此参数允许添加将在完成后的后缀文本。它允许进行插入,因为我们已经在图2-3的Playground 中有了一个示例。
提示和标记的长度
与聊天模型完全一样,定价将直接取决于我们发送的输入和接收的输出。对于输入消息,我们必须仔细管理提示参数的长度,以及后缀(如果使用的话)。对于我们收到的输出,使用max_tokens。它可以让你避免不愉快的惊喜。
额外的可选参数
就像openai.ChatCompletion,可以使用额外的可选参数来进一步调整模型的行为一样。这些参数与我们在段落中经历的相同openai.ChatCompletion,我们将不再详细介绍。
文本完成端点的输出结果格式:
现在您已拥有查询基于文本的模型所需的所有信息,您会发现结果与 Chat Endpoint 结果非常相似。
以下是我们使用达芬奇模型的 Hello World 示例的示例输出:
{"choices": [{"finish_reason": "stop","index": 0,"logprobs": null,"text": "<br />\n\nHi there! It's great to see you."}],"created": 1681883111,"id": "cmpl-76uutuZiSxOyzaFboxBnaatGINMLT","model": "text-DaVinci-003","object": "text_completion","usage": {"completion_tokens": 15,"prompt_tokens": 3,"total_tokens": 18}
}您会注意到此输出与我们在聊天模型中的输出非常相似。唯一的区别在于选择对象:我们没有包含内容和角色属性的消息,而是包含text 模型生成的完成的简单消息。
使用 GPT 精通文本编辑
我们之前看到的 API 中的两个模型都添加了文本,但我没有修改输入中给出的文本。您将在下文中看到,模型也可能从输入提示和指令返回提示的编辑版本。
编辑的端点是openai.Edit.create. 您必须指定用作编辑起点的输入文本、告诉模型如何编辑提示的命令以及模型的名称。您只能为此端点使用两个模型:text-DaVinci-edit-001和code-DaVinci-edit-001。其他参数也可用于控制输出(例如, or temperature )n,但因为我们之前已经见过它们,所以我们不会重新解释它们。
以下是如何使用此功能的示例。我们在 Playground 中重用了与之前相同的示例,其中我们将一个主要角色是男性的句子作为输入,并要求将这个主要角色替换为一位年长的女性。
# Call the openai Edit endpoint, with the text-DaVinci-edit-001 modelresponse = openai.Edit.create(model="text-DaVinci-edit-001",input="A young man is going on a trip. Before leaving, he said goodbye to his friend and parcked his suitcase.",instruction="Change the main character to an old woman")# extract the responseprint(response['choices'][0]['text']) 文本编辑端点的输出结果格式与我们之前看到的类似;因此,这里没有必要对其进行详细描述。
审核模型
如上所述,在使用 OpenAI 模型时,您必须遵守OpenAI 使用政策中描述的规则。为了帮助您遵守这些规则,OpenAI 提供了一个模型来检查内容是否符合这些使用政策。如果您构建一个将用户输入用作提示的应用程序,这将很有用:您可以根据审核端点结果过滤查询。该模型提供分类功能,允许您搜索以下类别的内容:
恨
煽动基于种族、性别、民族、宗教、国籍、性取向、残疾或种姓的群体的仇恨。
仇恨/威胁
涉及对目标群体的暴力或严重伤害的仇恨内容。
自我伤害
宣传或描述自残行为(包括自杀、割伤和饮食失调)的内容。
性的
旨在描述性活动或宣传性服务(教育和健康除外)的内容。
与未成年人发生性关系
涉及 18 岁以下人群的露骨色情内容。
暴力
美化暴力或颂扬他人的痛苦或屈辱的内容。
暴力/图形
以生动的细节描绘死亡、暴力或严重身体伤害的暴力内容。
警告
对英语以外的语言的支持是有限的。
审核模型的端点只有openai.Moderation.create,两个参数可用:模型和输入文本。有两种内容审核模型。默认模型是text-moderation-latest随时间自动更新的模型,以确保您始终使用最准确的模型。另一个模型是text-moderation-stable. OpenAI 会在更新此模型之前通知您。
警告
的准确度
text-moderation-stable可能略低于text-moderation-latest。
以下是如何使用此审核模型的示例。
response = openai.Moderation.create(model='text-moderation-latest',input="I want to kill my neighbor.",)我们来看看审核端点的输出结果:
{"id": "modr-7AftIJg7L8jqGIsbc7NumObH4j0Ig","model": "text-moderation-004","results": [{"categories": {"hate": false,"hate/threatening": false,"self-harm": false,"sexual": false,"sexual/minors": false,"violence": true,"violence/graphic": false},"category_scores": {"hate": 0.0400671623647213,"hate/threatening": 3.671687863970874e-06,"self-harm": 1.3143378509994363e-06,"sexual": 5.508050548996835e-07,"sexual/minors": 1.1862029225540027e-07,"violence": 0.9461417198181152,"violence/graphic": 1.463699845771771e-06},"flagged": true}]}审核端点的输出结果提供以下信息:
model string用于预测的模型。
在我们上面的例子中调用方法的时候,我们指定了使用的模型text-moderation-latest,在输出结果中,使用的模型是text-moderation-004。如果我们用 调用该方法text-moderation-stable,它就会被text-moderation-001使用。
flagged boolean如果模型将内容识别为违反 OpenAI 的使用政策,则将其设置为 true;否则,将其设置为 false。
categories dict 包括带有用于策略违规类别的二进制标志的字典。对于每个类别,如果模型识别出违规,则该值为 true,否则为 false。
字典可以通过访问print(type(response['results'][0]['categories']))
category_scores dict 该模型提供了一个字典,其中包含特定类别的分数,显示输入违反该类别的 OpenAI 政策的置信度。分数范围从 0 到 1,分数越高表示越有信心。这些分数不应被视为概率。
字典可以通过访问print(type(response['results'][0]['category_scores']))
警告
OpenAI 会定期改进审核系统。因此,基于类别分数的自定义规则可能需要随着时间的推移进行调整。
注意事项
定价和代币限制
如果不更仔细地研究使用 OpenAI 模型所产生的成本,我们就不能再进一步了。
OpenAI 将其模型的定价列在其定价页面上。
请注意,OpenAI 不一定会维持此定价,并且成本可能会随时间变化。
在撰写本书时,最常用的 OpenAI 模型的定价如下:
| 家庭 | 模型 | 使用定价 | 最大代币 |
| 聊天 | gpt-4 | 提示: $0.03/1K 代币 完成: $0.06/1K 代币 | 8,192 |
| 聊天 | gpt-4-32k | 提示: $0.06/1K 代币 完成: $0.012/1K 代币 | 32,768 |
| 聊天 | gpt-3.5-turbo | $0.002/1K 代币 | 4,096 |
| 文本补全 | gpt-3.5-turbo | $0.0200 / 1K 代币 | 4,097 |
从中有几点需要注意:
-
DaVinci 模型的成本是 GPT-3.5 Turbo 的 10 倍。我们建议仅在您希望进行一些微调时才使用达芬奇(目前只有达芬奇可以进行微调)。我们将在第四章中看到更多关于微调的内容。
-
GPT-3.5 Turbo 也比 GPT-4 型号便宜。GPT-4 和 GPT-3.5 模型之间的差异与许多基本任务无关。然而,在复杂的推理情况下,GPT-4 的表现远远优于之前的任何模型。
-
GPT-4 模型具有与 GPT-3.5 Turbo 和DaVinci 模型不同的定价系统:它们区分输入(提示)和输出(完成)
-
GPT-4 允许上下文的长度是原来的两倍,甚至可以达到 32k 个标记,相当于超过 25,000 个文本单词。GPT-4 支持使用案例,例如长篇内容创建、高级对话以及文档搜索和分析……需要付费。
安全和隐私:警告!
在撰写本书时,OpenAI 声称作为输入发送到模型的数据不会用于再训练,除非您决定选择加入。但是,出于监控和使用合规性检查目的,您的输入会保留 30 天。这意味着 OpenAI 员工以及专业的第三方承包商可以访问您的 API 数据。
警告
切勿通过 OpenAI 端点发送敏感数据,例如个人信息或密码
我们建议您查看OpenAI 的数据使用政策以获取最新信息,因为这可能会发生变化。
如果您是国际用户,请注意您的个人信息和您作为输入发送的数据可能会从您所在的位置传输到美国的 OpenAI 设施和服务器。这可能会对您的应用程序创建产生一些法律影响。
其他 OpenAI API 和功能:
您的 OpenAI 帐户允许您访问文本完成之外的功能。我们选择了其中的几个功能来在本节中进行探索。但是,如果您想深入了解所有 API 的可能性,请查看OpenAI 的 API 参考页面。
使用 DALL-E 生成图像
2021 年 1 月,OpenAI 推出了 DALL-E,这是一种能够根据自然语言描述创建逼真的图像和艺术品的人工智能系统。DALL-E 2 以更高的分辨率、更好的输入文本理解能力和新功能使技术更进一步。DALL-E 的两个版本都是通过在图像及其文本描述上训练一个转换器模型创建的。您可以通过 API 和实验室界面试用 DALL-E 2 。
嵌入
由于模型依赖于数学函数,因此它需要数值输入来处理信息。但是,许多元素(例如单词或标记)并不是天生的数字。为了克服这个问题,嵌入将这些概念转换为数值向量。嵌入允许计算机通过用数字表示它们来更有效地理解这些概念之间的关系。在某些情况下,访问嵌入可能很有用,OpenAI 提供了一个模型,可以将文本转换为数字向量。嵌入端点允许开发人员获得输入文本的矢量表示。然后可以将该向量表示用作其他 ML 模型和 NLP 算法的输入。
嵌入的原理是向量化两个文本字符串并衡量它们的相关性。
有了这个想法,您可以有各种用例:
搜索 : 按与查询字符串的相关性对结果进行排序
建议 :推荐包含与查询字符串相关的文本字符串的文章
聚类 :按相似性对字符串进行分组
异常检测 :查找与其他文本字符串无关的文本字符串
完整的文档可以在OpenAI 的参考文档中找到。
Whisper
它是一种用于语音识别的通用模型。它是在大型音频数据集上训练的,也是一个多任务模型,可以执行例如多语言语音识别、语音翻译和语言识别。OpenAI 的Whisper 项目的 GitHub 页面上提供了一个开源版本。
摘要和备忘单
设置 OpenAI 帐户后,我们建议您从两件事开始:
-
检查OpenAI 使用策略
-
使用提供的游乐场:这是一种理想的方式,让您无需编码即可熟悉不同的模型。
OpenAI 提供多种模型作为服务,特别是 ChatGPT 背后的模型,称为 GPT-3.5 Turbo 和最新的 GPT-4。这些模型可通过聊天完成端点获得。其他模型也可用,例如 DaVinci,也可通过文本完成端点获得。
提示
GPT-3.5 Turbo 是大多数用例的最佳选择:比旧型号更强大,而且最便宜。
我们创建了一个备忘单,供快速参考以将输入发送到 GPT-3.5 Turbo:
-
安装 openai 依赖
pip install openai -
设置您的 API 密钥可用
export OPENAI_API_KEY=sk-(...) -
在 Python 中,导入 openai
import openai -
调用 openai ChatCompletion 端点
response = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=[{"role": "user", "content": "Your Input Here"}]) -
得到答案
print(response['choices'][0]['message']['content'])警告
切勿通过 OpenAI 端点发送敏感数据,例如个人信息或密码
OpenAI 还提供了其他几种模型和工具。如果您计划构建将用户输入发送到 OpenAI 模型的应用程序,我们建议查看审核端点。嵌入端点允许您找到两个字符串之间的相似性,如果您希望在应用程序中包含 NLP 功能,这也可能很有用。
提示
不要忘记查看定价页面,并使用tiktoken来估算使用成本。
现在您已了解如何使用 OpenAI 服务,让我们深入探讨为什么要使用它们:在下一章中,您将看到各种示例和用例的概述,并且您将能够OpenAI ChatGPT 和 GPT-4 模型中的大部分。










![[论文速览] Sparks of Artificial General Intelligence: Early experiments with GPT-4](https://img-blog.csdnimg.cn/e7a12c37a257461989e266da30a93bc6.png)