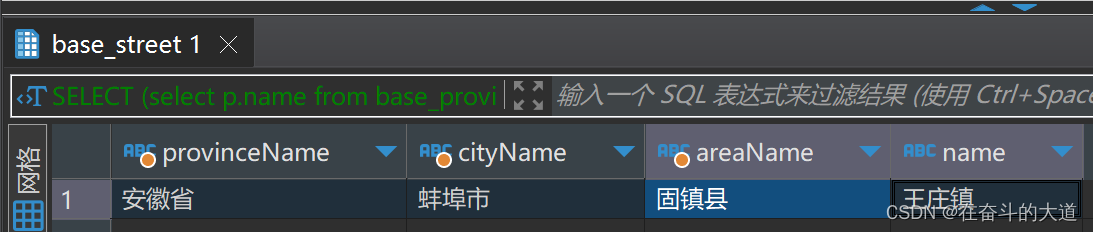
一、背景
近期操作退役EC集群的节点。在退役的过程中,遇到了一些问题。特此总结一下。
本文描述的问题现象是:
每一批次退役10个节点,完全退役成功后开始操作下一批。
但是,中间有一批次有2台节点的Under Replicated Blocks一直是1,不往下降。
处于Decommissioning状态卡住了很久。如果不人为干预的话,会一直卡住,无法退役成功。

二、问题排查、源码分析
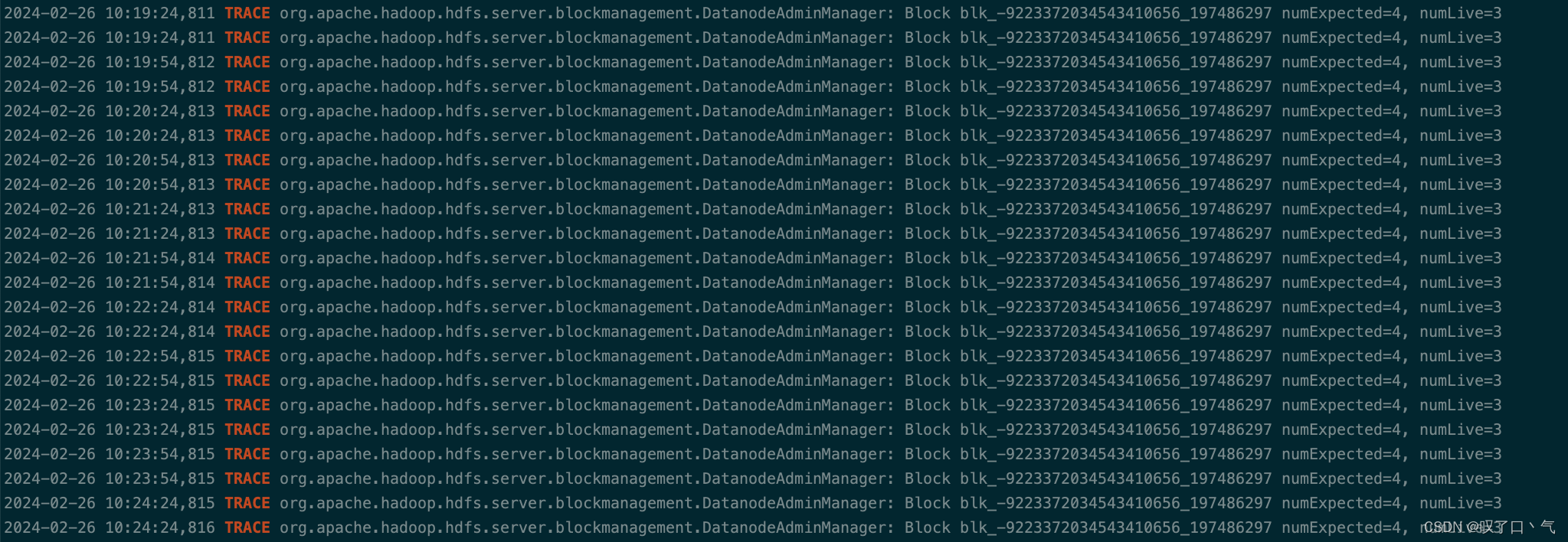
1、首先确定卡在了哪个块的复制上。
将 org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminManager这个LOG的级别修改为TRACE级别。
这样在DatanodeAdminManager#isSufficient方法里就会有TRACE日志打印出来,告诉我们哪个块有问题。
如下图所示,我们知道卡在了blk_-9223372034543410656_197486297这个块上。
2、 使用fsck -blockId 看看这个块属于哪个文件?
如下图所示。另外我们注意到,此块有一个internal block已经是DECOMMISSIONED状态了(0390节点上那个,这个细节很重要。)