关联式container
STL中一些常见的容器:
-
序列式容器(Sequence Containers):
- vector(动态数组): 动态数组,支持随机访问和在尾部快速插入/删除。
- list(链表): 双向链表,支持在任意位置快速插入/删除。
- deque(双端队列): 双端队列,支持在两端快速插入/删除。
容器适配器(Container Adapters):
- stack(栈): 后进先出(LIFO)的数据结构。
- queue(队列): 先进先出(FIFO)的数据结构。
- priority_queue(优先队列): 具有优先级的队列。
-
关联式容器(Associative Containers):
- set(集合): 有序集合,不允许重复元素。
- multiset(多重集合): 有序集合,允许重复元素。
- map(映射): 键-值对的集合,按键有序存储,不允许重复键。
- multimap(多重映射): 键-值对的集合,按键有序存储,允许重复键。
无序关联容器(Unordered Associative Containers):
- unordered_set: 无序集合,不允许重复元素。
- unordered_multiset: 无序集合,允许重复元素。
- unordered_map: 无序映射,按键无序存储,不允许重复键。
- unordered_multimap: 无序映射,按键无序存储,允许重复键。
关联式容器
关联式容器是指数据是键值对的格式。容器内部结构(可能是RB-tree或者hash-table)便依照其键值大小,以某种特定规则将这个元素放置于合适的位置,关联式容器没有所谓头尾(只有最大元素和最小元素);所以不会有所谓push_back()、push_front()等行为的操作。
1.set
set中所有元素都会根据元素的键值自动被排序。std::set 使用红黑树(一种自平衡的二叉搜索树)作为底层数据结构。
set的元素不像map那样可以同时拥有key和value,set的键值就是实值。并且set不允许两个元素拥有相同的值。
迭代器
std::set 的迭代器性质:
- 递增顺序:
std::set中的元素是有序排列的,迭代器按照递增(升序)的顺序遍历元素。这是由底层平衡二叉搜索树的特性决定的。 - 双向迭代器:
std::set提供双向迭代器,支持向前(++)和向后(-)遍历。 - 随机访问特性的缺失: 与支持随机访问的容器(如
std::vector)不同,std::set的迭代器不支持+n或n这样的随机跳跃,因为底层结构并不是一个连续的存储区域。 - 不能通过迭代器修改set键值,因为set的元素值关系到set元素的排列,随意改变值,会导致排列顺序崩溃,所以不不能通过迭代器修改set值。
因此插入和删除操作并不会使set迭代器失效。当然,被删除的哪个迭代器除外。
set的核心在于使用的红黑树的insert_unique插入数据。

2.map
map所有元素都会根据元素的键值自动被排序。std::map 也是使用红黑树(一种自平衡的二叉搜索树)作为底层数据结构。
map的所有元素都是pair,同时拥有实值(value)和键值(key)。pair的第一元素被视为键值,第二元素被视为实值。map不允许两个元素拥有相同的键值。
pair的定义:
template<class T1,class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair():first(T1()),second(T2()){}pair(const T1& a,const T2& b):first(a),second(b){}
};
map和set一样的核心在于使用的红黑树的insert_unique插入数据。

迭代器
map和set的迭代器性质一样。
- 递增顺序
- 双向迭代器
- 随机访问特性缺少
- 不能通过迭代器修改map键值。但是可以通过迭代器修改键值对应的实值。
int main() {std::map<int, std::string> myMap;// 插入元素myMap[1] = "One";myMap[2] = "Two";myMap[3] = "Three";// 使用迭代器遍历并修改值for (auto it = myMap.begin(); it != myMap.end(); ++it) {std::cout << "Key: " << it->first << ", Value: " << it->second << std::endl;//it->first = 4; //报错// 修改值it->second = "Modified";}for (auto it = myMap.begin(); it != myMap.end(); ++it) {std::cout << "Key: " << it->first << ", Value: " << it->second << std::endl;}return 0;
}
关联式容器的find方法

3.multiset
multiset的特性以及用法和set完全相同,唯一的差别在于它允许键值重复。
它的底层机制是使用RB-tree的insert_equal()而非insert_unique();

4.multimap
与map的用法完全相同,唯一的差别在于,它允许键值重复。
它的底层机制是使用RB-tree的insert_equal()而非insert_unique();

5.hashtable
上述提到的以红黑树做为底层结构的set、map,其查找的时间复杂度为对数,但是依赖于元素值是要有足够的随机性。例如输入数据完全有序或完全逆序,红黑树可能会退化成链表,导致性能下降至O(n)。
HashTable 是一种通过哈希函数将关键字映射到存储桶的数据结构。STL中的HashTable通常是一个数组,每个数组元素是一个链表或其他形式的容器。当有多个关键字哈希到同一个存储桶时,它们被放入同一个链表中。
使用哈希函数会遇到一个问题,可能有不同的元素被映射到相同的位置,这就是所谓的hash碰撞问题。解决hash碰撞问题有很多,包括线性探测、二次探测、开链法等。
线性探测
线性探测的基本操作:
-
插入操作:
- 根据散列函数计算键的散列值。
- 如果该位置为空,则将键值对插入该位置。
- 如果该位置已被占用,就向后线性探测,查找下一个空闲位置,直到找到一个空闲位置为止,然后插入键值对。
-
查找操作:
- 根据散列函数计算键的散列值。
- 如果该位置为空,表示键不存在。
- 如果该位置不为空,检查键是否匹配,如果匹配则找到了键,返回对应的值;否则,向后线性探测,查找下一个位置,直到找到匹配的键或者遇到空位置为止。
-
删除操作:
- 查找要删除的键。
- 如果找到,将该位置标记为空,表示删除该键。注意:在某些实现中,可以使用特殊的标记表示已删除的位置,而不是直接将位置设置为空。被叫做惰性删除,实际的删除操作等到整理表的时候再删。
具体的探测序列可以表示为:
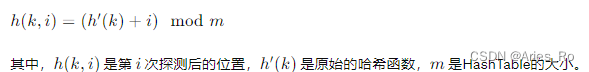
二次探测
二次探测是解决散列表冲突的一种方法,类似于线性探测,但是在寻找下一个可用位置时,不是简单地线性向后移动,而是使用一个二次方程来计算下一个位置。这样可以更灵活地处理冲突,减少聚集的可能性。

二次探测的优点是相对于线性探测,能够更好地分散冲突,减少聚集问题。然而,如果HashTable的大小选择不当,仍然可能发生聚集问题。
开链法
开链法的做法是为每一个表格元素维护一个list。通过哈希函数定位到某一个list,然后在那一个list上执行插入、搜寻、删除操作。
使用开链法,哈希表的负载系数将大于1。上述的线性探测和二次探测的负载系数都是小于1的。
开链法由一个bukets vector和一个bucket list组成。
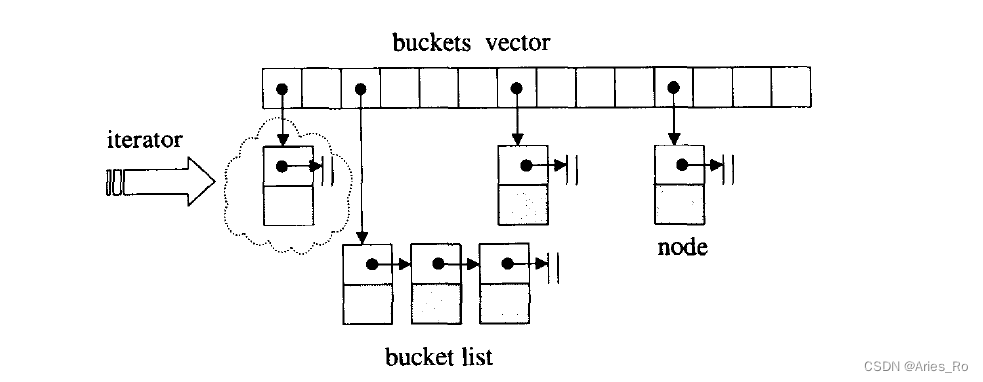

迭代器

hash_set、hash_map、hash_multiset、hash_multimap
hash_set以hashtable为底层机制。由于hash_set所供应的操作接口。 注意:hash_table中没有自动排序功能。
hash_map、hash_multiset、hash_multimap基本都与对应的类型相同,只是底层机制由hash_table来进行实现。