起
在学习了卷积神经网络的理论基础和阅读了VGG的论文之后,对卷积有了大致的了解,但这都只是停留在理论上,动手实践更为重要,于是便开始了0基础学习pytorch、图像处理,搭建模型。
pytorch学习视频 https://www.bilibili.com/video/BV1hE411t7RN
代码参考https://blog.csdn.net/aa330233789/article/details/106411301
数据集来源https://www.cnblogs.com/xiximayou/p/12372969.html
悟
- 收获最大的是对于pycharm的了解更进一步,利用help 和 ?? 在python console 中查看帮助文档,是一个很实用的技巧,并且这也是离线操作,不会就查,函数的参数、参数的含义、数学原理等等一应俱全,配上Makedown的编辑器,绝了。
- 惊讶于pytorch的封装能力,就从一个BP函数来说,简单的几个参数,包含了 L 2 L^2 L2正则化(权重衰减)、动态学习率调整,对于一个萌新来说,大概连原理也不要明白,只需要知道参数的作用便可以搭建网络。
- 实际上这个实战还有很多地方没有完善,比如数据增强部分,数据可视化,模型的训练(没算力啥也不是),还有很多地方值得进一步挖掘。
- 整体搭建一个类似的项目,虽然伤眼睛、废手,收获确实很大,对于Pytorch的理解比上一个星期的视频可要来得深刻,当然如果想要深入学习pytorch那又是另一个问题。
话不多说,细节全在注释中。
show the code
read_data.py
from torch.utils.data import Dataset
import cv2
import os
import numpy as np
import torch
from torchvision import transforms
class Mydata(Dataset):def __init__(self,img_path):# 用于设置类中的变量self.img_path=img_pathself.img_list=os.listdir(img_path)print(self.img_list[0])def __getitem__(self, idx):img_name = self.img_list[idx]img_item_path = os.path.join(self.img_path,img_name)img = cv2.imread(img_item_path)img = cv2.resize(img,(224,224),interpolation=cv2.INTER_LINEAR)# 这里需要注意opencv独特图像存储方式trans = transforms.ToTensor()img = trans(img)#img = torch.from_numpy(img)#print(img.shape)label = 0if img_name[0]=='c':label=1return img,labeldef __len__(self):return len(self.img_list)
model
from torch import nnclass VGG16Net(nn.Module):# 继承父类nn.Moduledef __init__(self):super(VGG16Net,self).__init__()'''如果不用super,每次调用父类的方法是需要使用父类的名字使用super就避免这个麻烦super()实际上的含义远比这个要复杂。有兴趣可以通过这篇博客学习:https://blog.csdn.net/zhangjg_blog/article/details/83033210''''''A sequential container.Modules will be added to it in the order they are passed in theconstructor. Alternatively, an ``OrderedDict`` of modules can bepassed in. The ``forward()`` method of ``Sequential`` accepts anyinput and forwards it to the first module it contains. It then"chains" outputs to inputs sequentially for each subsequent module,专业术语:一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数这是一个有序模型容器,输入会按照顺序逐层通过每一模型,最终会返回最后一个模型的输出。实现原理:利用for循环 将所有的参数(即子模块)加入到self._module,然后在__call__中调用forward(),而forward()函数则会将self.module中的子模块推理一遍,返回值也就是最终结果。参考博客:https://blog.csdn.net/dss_dssssd/article/details/82980222 '''# 第一层,2个卷积层和一个最大池化层self.layer1 = nn.Sequential(# 输入3通道,输出64通道。卷积核大小3,填充1,步长默认为1(输入224*224*3的样本图片,输出为224*224*64)nn.Conv2d(3,64,3,padding=1),# 对数据做归一化,这是由于经过训练后的数据分布改变,需要将其拉回到N(1,0)的正态分布,防止梯度消失,读入的参数是通道数。nn.BatchNorm2d(64),# 激活函数。参数inplace =false 是默认返回对象,需要重开地址,这里True返回地址,为了节省开销nn.ReLU(inplace=True),# 输入为224*224*64,输出为224*224*64nn.Conv2d(64,64,3,padding=1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),# 进行卷积核2*2,步长为2的最大池化,输入224*224*64,输出112*112*64nn.MaxPool2d(kernel_size=2,stride=2))# 第二层,2个卷积层和一个最大池化层self.layer2 = nn.Sequential(# 输入为112*112*64,输出为112*112*128nn.Conv2d(64,128,3,padding=1),nn.BatchNorm2d(128),nn.ReLU(inplace=True),# 输入为112*112*128,输出为112*112*128nn.Conv2d(128,128,3,padding=1),nn.BatchNorm2d(128),nn.ReLU(inplace=True),# 112*112*128 --> 56*56*128nn.MaxPool2d(kernel_size=2,stride=2))#第三层,3个卷积层和一个最大池化self.layer3 = nn.Sequential(# 56*56*128 --> 56*56*256nn.Conv2d(128,256,3,padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),# 56*56*256 --> 56*56*256nn.Conv2d(256, 256, 3, padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),# 56*56*256 --> 56*56*256nn.Conv2d(256, 256, 3, padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),# 56*56*256 --> 28*28*256nn.MaxPool2d(kernel_size=2,stride=2))#第四层,3个卷积层和一个最大池化self.layer4=nn.Sequential(# 28*28*256 --> 28*28*512nn.Conv2d(256,512,3,padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),# 28*28*512 --> 28*28*512nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),# 28*28*512 --> 28*28*512nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),# 28*28*512 --> 14*14*512nn.MaxPool2d(kernel_size=2,stride=2))#第五层,3个卷积层和一个最大池化self.layer5=nn.Sequential(# 14*14*512 --> 14*14*512nn.Conv2d(512,512,3,padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),# 14*14*512 --> 14*14*512nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),# 14*14*512 --> 14*14*512nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),# 14*14*512 --> 7*7*512nn.MaxPool2d(kernel_size=2,stride=2))# 将卷积层打包self.conv_layer = nn.Sequential(self.layer1,self.layer2,self.layer3,self.layer4,self.layer5)# 全连接层self.fc = nn.Sequential(# 1*1*25088 --> 1*1*4096nn.Linear(25088,4096),nn.ReLU(inplace=1),nn.Dropout(),# 1*1*4096 --> 1*1*4096nn.Linear(4096,4096),nn.ReLU(inplace=1),nn.Dropout(),# 1*1*4096 --> 1*1*1000nn.Linear(4096,1000))def forward(self,x):x = self.conv_layer(x)# 7*7*512 --> 1*1*25088x=x.view(-1,25088)x=self.fc(x)return x
train.py
import torch
from read_data import Mydata
from torch.utils.data import DataLoader
from torch import nn
from torch import optim
from model import VGG16Net
import time#超参数设置
batch_size = 8 # 每次训练的数据量
learn_rate = 0.01 # 学习率
step_size = 10 # 控制学习率变化
epuch_num = 1 # 总的训练次数
num_print = 10 # 每n个batch打印一次mydata = Mydata(r"D:\machine learning\deep learning\VGG16\data\train")# 利用dataloader加载数据集
train_loader = torch.utils.data.DataLoader(mydata,batch_size=batch_size,shuffle=True,drop_last=True)# 生成驱动器
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 利用驱动器驱动模型
model = VGG16Net().to(device=device)# 损失函数
get_loss = nn.CrossEntropyLoss()# SGD优化器 第一个参数是输入需要优化的参数,第二个是学习率,第三个是动量,大致就是借助上一次导数结果,加快收敛速度。
'''
这一行代码里面实际上包含了多种优化:
一个是动量优化,增加了一个关于上一次迭代得到的系数的偏置,借助上一次的指导,减小梯度震荡,加快收敛速度
一个是权重衰减,通过对权重增加一个(正则项),该正则项会使得迭代公式中的权重按照比例缩减,这么做的原因是,过拟合的表现一般为参数浮动大,使用小参数可以防止过拟合
'''
optimizer = optim.SGD(model.parameters(),lr=learn_rate,momentum=0.8,weight_decay=0.001)# 动态调整学习率 StepLR 是等间隔调整学习率,每step_size 令lr=lr*gamma
# 学习率衰减,随着训练的加深,目前的权重也越来越接近最优权重,原本的学习率会使得,loss上下震荡,逐步减小学习率能加快收敛速度。
scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=step_size,gamma=0.5,last_epoch=-1)loss_list=[]
start=time.time()for epoch in range(epuch_num):running_loss = 0.0# enumerate()是python自带的函数,用于迭代字典。参数1,是需要迭代的对象,第二参数是迭代的起始位置for i,(inputs,labels) in enumerate(train_loader,0):inputs,labels = inputs.to(device), labels.to(device)optimizer.zero_grad()# 将梯度初始化为0outputs = model(inputs)# 前向传播求出预测的值loss = get_loss(outputs,labels).to(device)# 求loss,对应loss +=loss.backward() # 反向传播求梯度optimizer.step() # 更新所有参数running_loss += loss.item()# loss是张量,访问值时需要使用item()loss_list.append(loss.item())if i % num_print == num_print - 1:print('[%d epoch, %d] loss: %.6f' % (epoch + 1, i + 1, running_loss / num_print))running_loss = 0.0lr = optimizer.param_groups[0]['lr']# 查看目前的学习率print('learn_rate : %.15f'% lr)scheduler.step()# 根据迭代epoch更新学习率end = time.time()
print('time:{}'.format(end-start))torch.save(model,'./model.pth')
test.py
import torch
from read_data import Mydata
from torch.utils.data import DataLoader
from torch import nn
from torch import optim
from model import VGG16Nettestdata = Mydata(r'D:\machine learning\deep learning\VGG16\data\test\test')
test_loader = torch.utils.data.DataLoader(testdata,batch_size=1,shuffle=False)device = torch.device('cpu')
model = torch.load('./model.pth')model.eval()
correct = 0.0
total = 0
with torch.no_grad():for input, label in test_loader:inputs = input.to(device)outputs = model(inputs)pred = outputs.argmax(dim=1 )# 返回每一行中最大元素索引total += inputs.size(0)correct += torch.eq(pred,label).sum().item()# 比较实际结果和标签
print('Accuracy of the network on the 10000 test images:%.2f%%'%(100.0*correct/total))
print(total)ps:其实还有很多问题比如作者在训练是采用贪心式的预训练,如何借助pytorch框架完成,在test.py代码中也存在一些问题。
VGG网络简单、有效,不知道resnet的残差又是怎样的风景。
续:为了验证该网络的有效性,我从kaggle中拿到了猫狗的数据集进行尝试
数据集来源Kaggle : Using a Convolutional Neural Network for classifying Cats vs Dogs

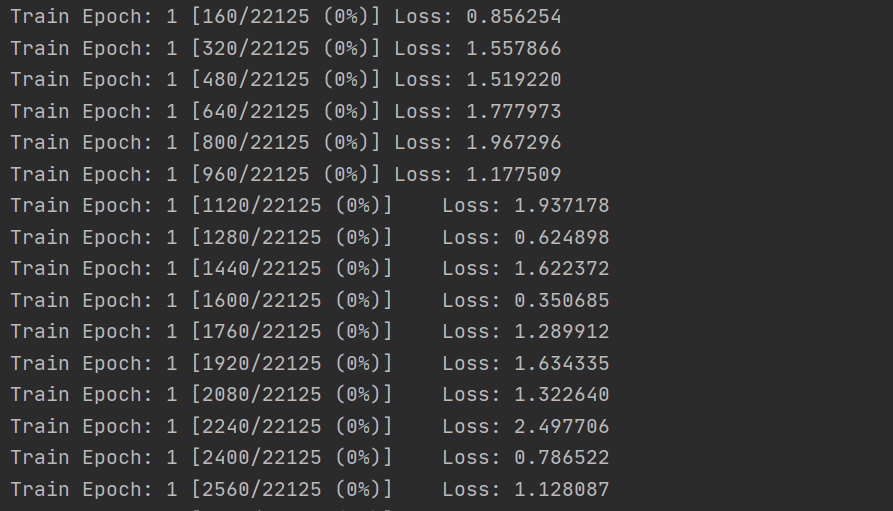
可以看出训练在有效进行,但可能是学习率等超参数的问题呢,训练loss的跳动过大。