在后台读取一个文件里的JSON数据,转换成字符串返回给前端,前端使用JSON.parse转换JSON报错。在将JSON校验和压缩后发现前端还是转换失败。在返回结果的时候可以看见一个小红点

最后排查,不带BOM的识别是Java遗留的一个bug。
解决方案:
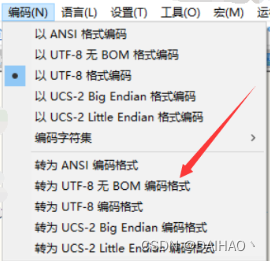
1、JSON文件修改为以UTF-8无BOM编码格式
2、使用Apache commons io提供的BOMInputStream
<dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.11.0</version></dependency>
import org.apache.commons.io.input.BOMInputStream;
import java.io.*;public class ReadFileWithApacheCommonsIO {public static void main(String[] args) {File file = new File("path/to/your/file.txt");try (BOMInputStream bomInputStream = new BOMInputStream(new FileInputStream(file), false);Reader reader = new InputStreamReader(bomInputStream, "UTF-8");BufferedReader bufferedReader = new BufferedReader(reader)) {String line;while ((line = bufferedReader.readLine()) != null) {System.out.println(line);}} catch (IOException e) {e.printStackTrace();}}
}
3、对于BOM,我们需要手动处理,通过InputStreamReader指定字符编码,并且利用BufferedReader逐行读取
import java.io.*;public class ReadFileWithoutBOM {public static void main(String[] args) {File file = new File("path/to/your/file.txt");try (InputStream inputStream = new FileInputStream(file);Reader reader = new InputStreamReader(inputStream, "UTF-8");BufferedReader bufferedReader = new BufferedReader(reader)) {// 检查并跳过BOMbufferedReader.mark(1);int charRead = bufferedReader.read();if (charRead != 0xFEFF) { // 0xFEFF 是UTF-8 BOMbufferedReader.reset(); // 如果不是BOM,回到开头}String line;while ((line = bufferedReader.readLine()) != null) {System.out.println(line);}} catch (IOException e) {e.printStackTrace();}}
}