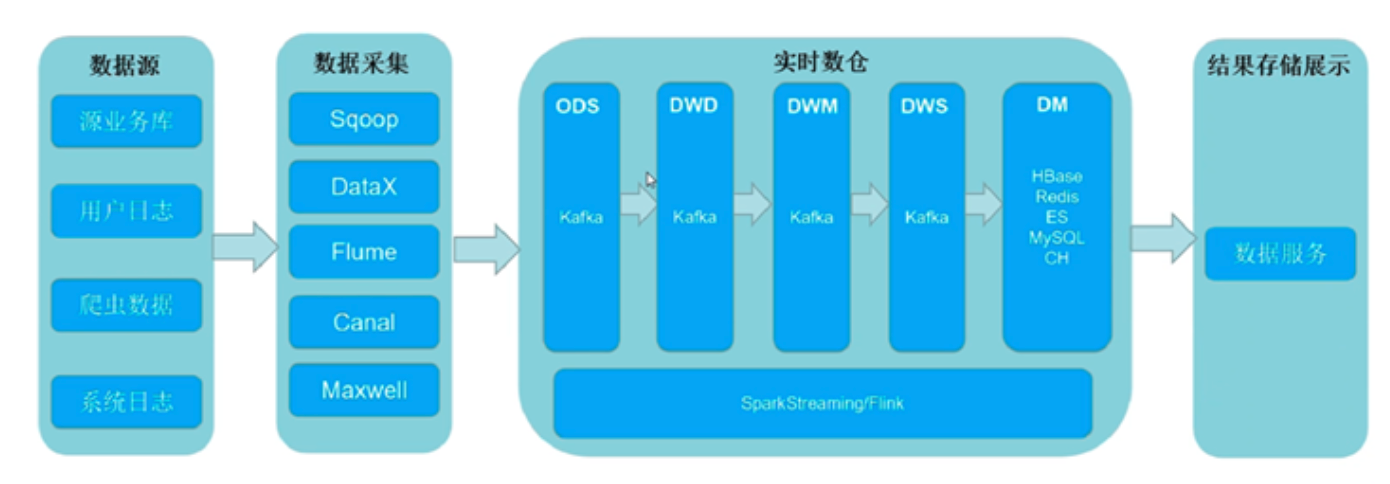
消失的日子在实习,今天最后一天了来看看自己的学习日志,有没有可以和小伙伴交流的部分吧!
目录
一、产品one
①简介
②底层原理
③知识点一
作用一:日志采集
作用二:实时监测
作用三:规则匹配
作用四:安全识别
作用五:检测攻击
④知识点二
⑤知识点三
⑥知识点四
二、产品two
①简介
②知识点一
③知识点二
④知识点三
一、产品one
①简介
被叫做高级持续性威胁预警系统,可以支持对多种协议进行还原和威胁检测,我们的测试过程就是通过对协议相关的pcap包进行回放,在产品层面展示的信息是否和pcap包内部信息一致,这里面需要学习的东西主要是wireshark的使用以及对产品的了解。以一个pcap包为出发点,编写整个测试过程的自动化测试脚本。
②底层原理
旁路接入交换机镜像流量后开始工作
系统通过旁路部署或者离线pcap包上传的方式通过业界广泛使用的dpdk驱动进行网络流量的采集和还原 从而对流量协议还原和后续的安全检测。
③知识点一
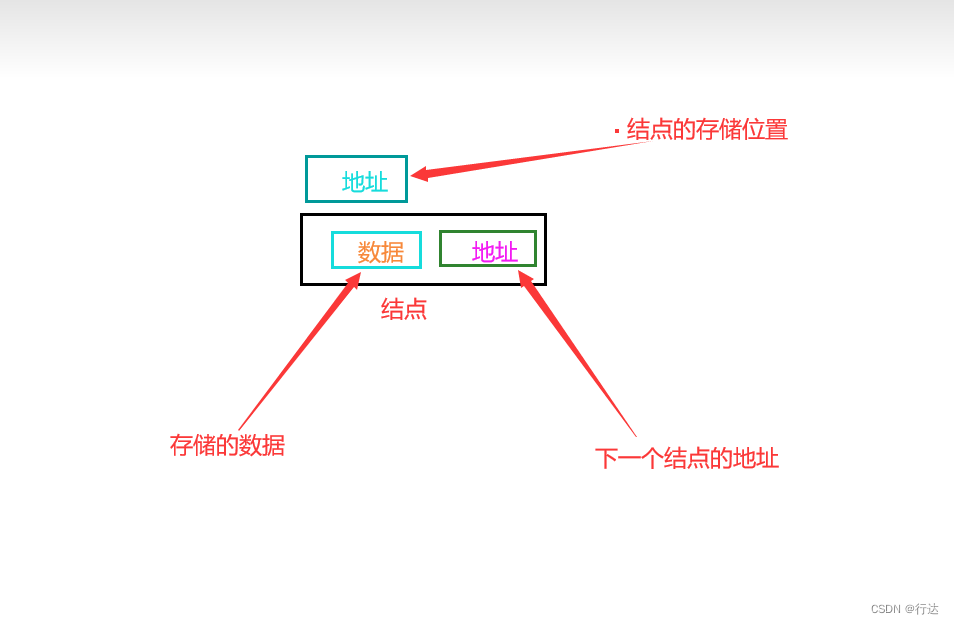
流量探针是一种对网络流量进行采集、分析的网络流量处理工具,也是我工作中接触最多的,清楚流量探针的用途是至关重要的。
作用一:日志采集
流量探针可以把网络流量转变为流量日志,比如我们在回放pcap包时可以将协议的元数据记录下来在探针上就能够看到相关的元数据、源目的IP和端口等
作用二:实时监测
有些网络行为跟网络负载有关无法基于日志进行分析,比如DDOS攻击、异常协议检测、隐蔽信道检测。
作用三:规则匹配
基于流量匹配规则,给出了匹配结果和预定的收集程序,保存特定流量的 Pcap文件以供保存。
作用四:安全识别
识别网络中的恶意软件、病毒和蠕虫,监测和阻止非法访问、未经授权的数据传输等。流量探针还可以对网络流量进行分类和标记,根据不同类型的流量进行不同的处理和管理,提高网络的安全性和性能。
作用五:检测攻击
流量探针通过对网络侦察的不断监控与分析,能够识别出各类攻击,如“零日”恶意软件、“内部威胁”、“高级持久性威胁”、“分布式拒绝服务”等。例如,锐捷网络研制的一款RG-BDS-TSP G千兆流量探针硬件,它通过AI智能检测模型,结合特征匹配、机器学习等技术对流量进行深度解析,TSP探针实现了对DGA(域名生成算法)的精准识别,恶意域名检出率超95%,是目前制衡僵尸网络的关键武器。
综上所述,对于流量产品来说,流量探针也是一个不可忽视的基础。
④知识点二
补充完自动化测试脚本后,我还参与到了性能测试中去,这个在实习之前从来没有接触过,导师简单讲解后可以操作但是并不知道原理,就又去了解了一下。
企业中使用的是avalanche测试仪,也就是思博伦测试仪。测试仪可以模拟n个IP地址,同时执行action中的命令(比如发送HTTP中的get请求),从而产生对被测设备的访问压力。
它的功能有:
①模拟客户端访问被测的服务器
②模拟产生流量,既做客户端又做服务器
③高性能④构造流量
⑤抓包
⑥支持多种协议包括隧道vlan 在流量安全设备上的性能测试上广泛应用
测试仪的一对口用来模拟客户端与服务端,经过交换机发送流量
交换机将与测试仪相连的其中一个接口的收发包流量镜像到与流量探针相连的接口上,这样我们就可以看到流量的相关数据了。
仪器本身吞吐可以产生80gbps流量 新建可以发出40万请求 40cps
性能指标:依公司指标而定
通过测试的标准:没有丢包 cpu利用率不超过80% 攻击检测的数量一致。
⑤知识点三
参与了一次升级包回归测试,逻辑还没有参透就去了解其他产品了。
细节性的东西就不说了,业务流程主要是先创建证书进入到平台,查看此次升级包的版本,查看需要做回归测试的是哪些部分,接下来进入linux系统输入vim /opt/work/******,将里面的升级包规则库版本改小(据说这一步不做,导入新的升级包就不会成功,现在也还是不太明白),后面的步骤就常规了,升级新包之后我们要在linux上看是否导入成功准备就绪(tail -f ********),服务器起来后我们就可以根据条目进行回归测试了。
⑥知识点四
除此之外,我常听组内的人说集管中心,所以我有自己去查了查。
集管中心就是主要管理探针的平台,而不同集管的底层架构也是不同的,单单是消息队列就有很多种,比如rabbitmq、kafka。
rabbitmq是实现了高级消息队列协议amqp的面向消息的中间件,可以实现异步消息处理,程序中的端口号为5672,它可以将一些无需即时返回并且耗时的操作提取出来进行异步处理,这样可以节省服务器的请求响应时间从而提高系统的吞吐量
工作机制:生产者 消费者 代理
生产者:消息的创建者 主要创建消息和推送消息给消息服务器
消费者:消息的接收方 主要接收数据和确认消息
代理:rabbitmq本身 只是承担的”快递“的角色
两者的区别:
rabbitmq:要求消息可靠性高 在客户端消费消息时有确认消息的机制 吞吐量小 不能支持批量存储 当消息到达队列后会将消息推送到消费者手中 被消费者确认的消息会被磁盘删除掉。
kafka:大数据量并且活跃 在客户端消费消息时没有消息确认的机制 吞吐量高 可以支持批量存储 当消息到达队列后消费者需要手动拉取消息 确认的消息仍然会保存在磁盘中。
二、产品two
①简介
平台提供演习管理、组织管理、安全接入资源管理和演习全周期的管理功能,对演习项目的增删改、初始化配置、资源分配、多演习并发、数据清理等。
接口测试平台 可以对操作进行录制 直接导入到测试平台 接口管理 多协议支持 场景自动化
接口定义:定义一个接口 登录或者注销 查看 删除等等
场景自动化:一个场景可能包含一个或多个接口
关系:一个接口对应多个场景 一个场景包含多个接口
②知识点一
了解完这个产品之后,我主要做的工作是接口自动化。使用的平台是MeterSphere,这个平台非常容易上手,因为编写接口时只需要借助他的扩展工具,开始录制结束录制就能够将所需要的接口导入到测试平台了。
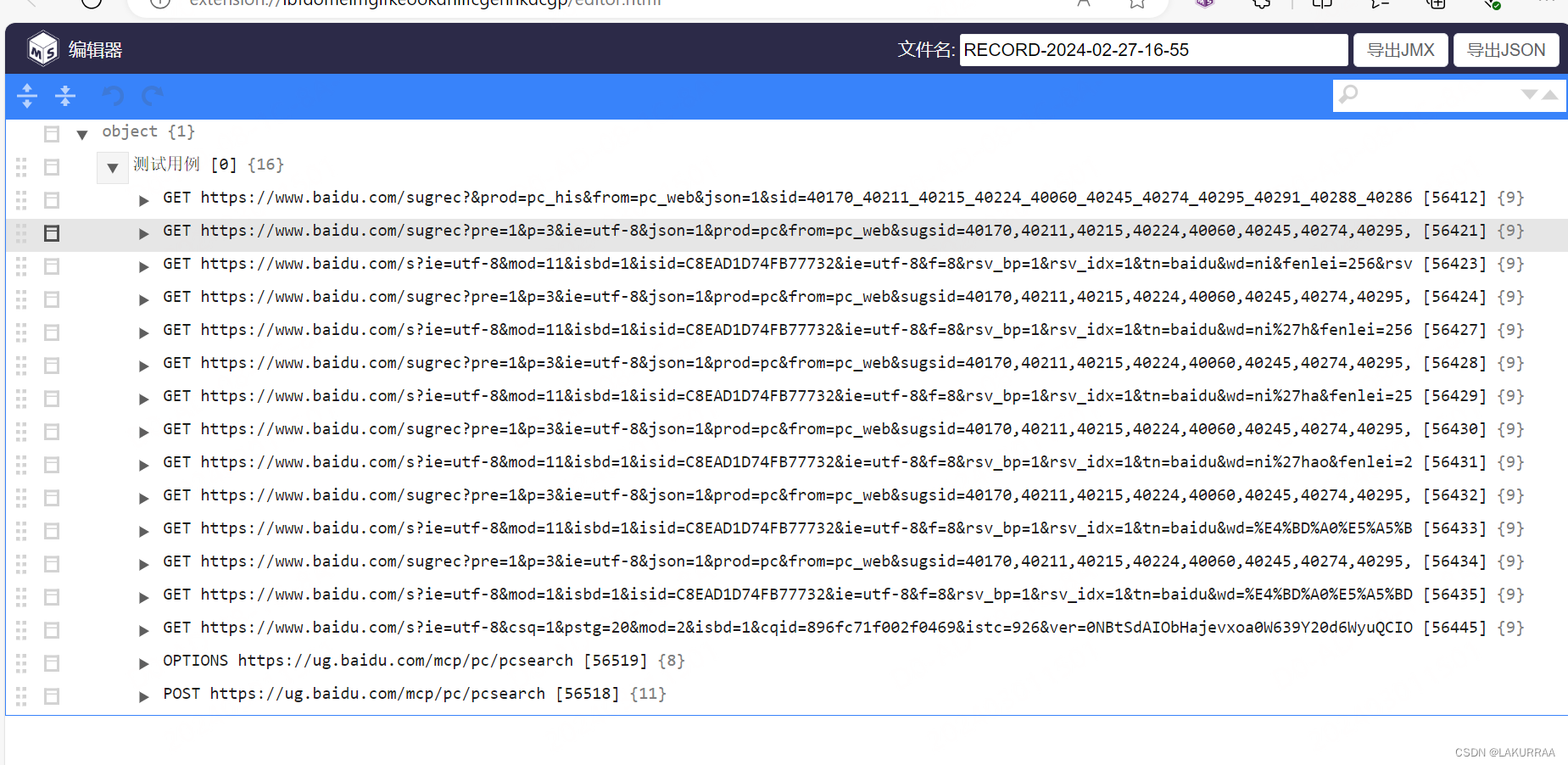 写接口定义部分需要特别有耐心,几乎产品所涉及的全部的功能都要注意到,最终我们完成的接口定义部分可能有成百上千条。
写接口定义部分需要特别有耐心,几乎产品所涉及的全部的功能都要注意到,最终我们完成的接口定义部分可能有成百上千条。
③知识点二
其实最难的是我们在创建场景时,不同接口之间的关联。用过postman的人都知道,接口的关联与登录操作息息相关,为了保证一个场景的成功建立,cookie成了关键。
Meterphere平台也为大家提供了便捷的方式——提取参数
在登陆接口执行后,我们只需要在响应头中提取我们想要的参数设置为一个变量,在之后的操作中只需要将该变量写入请求头中就可以了。
除此之外一个场景中也不必这么麻烦,只要勾选了这个就可以了。

④知识点三
编写完后,在调试之前我们还要对调试的结果进行规定,比如常见的响应码200就表示测试通过,如果不是200且不考虑重定向的情况下就是测试不通过,那就需要断言。

断言:对一些基本的预期结果和执行结果的对比,用来判断测试执行是否通过
断言类型
主要对三个部分做判断:response code状态码 response header响应头 response data响应体
①文本 eg: 选取response code 等于 200
②正则
+代表前面的字符至少出现一次 *代表前面的字符可以出现0次1次多次 ?代表前面的字符最多出现一次
[]匹配字符串中所有包含[]内的字符
[^]匹配字符串中所有不包含[]内的字符
[A-Z]匹配A到Z所有的大写字母
.匹配除换行符之外的任何字符 相当于[^\n\r]
[\s\S]匹配所有的空白符和非空白符 \s表示空白符 \S表示非空白符不包括换行
\w匹配字母数字下划线
\d匹配任意一个阿拉伯数字
\n匹配一个换行符
\r匹配一个回车符
\t匹配一个制表符
\v匹配一个垂直制表符
\f匹配一个换页符
③JSONPath 主要针对返回值为json字符串的请求,可以对响应体的内容进行判断 eg:$.user.email
④XPath 适用于返回值为xpath格式的请求
⑤脚本 对于复杂的断言 使用脚本来完成
⑥响应时间 在规定时间内完成则断言成功
![[C语言]——分支和循环(2)](https://img-blog.csdnimg.cn/direct/86075e4722814ae686d58de83f22f674.png)