
随着机器学习模型规模的扩大和数据量的增加,单个设备的计算能力和内存容量逐渐成为瓶颈。这导致训练过程变得缓慢且耗时长,限制了模型的进一步发展和改进。为了解决这个问题,分布式训练应运而生。它利用多个计算资源并行地执行计算任务,将数据和计算负载分布到不同的节点上,大大加快训练速度从而使得更复杂的模型可以进行训练。目前,分布式训练已成为机器学习领域的重要技术,许多大型公司和研究机构都在采用分布式训练来加速模型训练,取得更好的性能和效果。现在主要的分布式训练有很多框架可以选择,例如 Horovod,Megatron-LM,DeepSpeed,Apache Spark,PyTorch DDP 等,在本篇文章中,我们会介绍使用 Horovod 和 Pytorch 利用 Amazon EC2 GPU 资源,进行多机多卡分布式训练。
本文主要分为 3 部分:
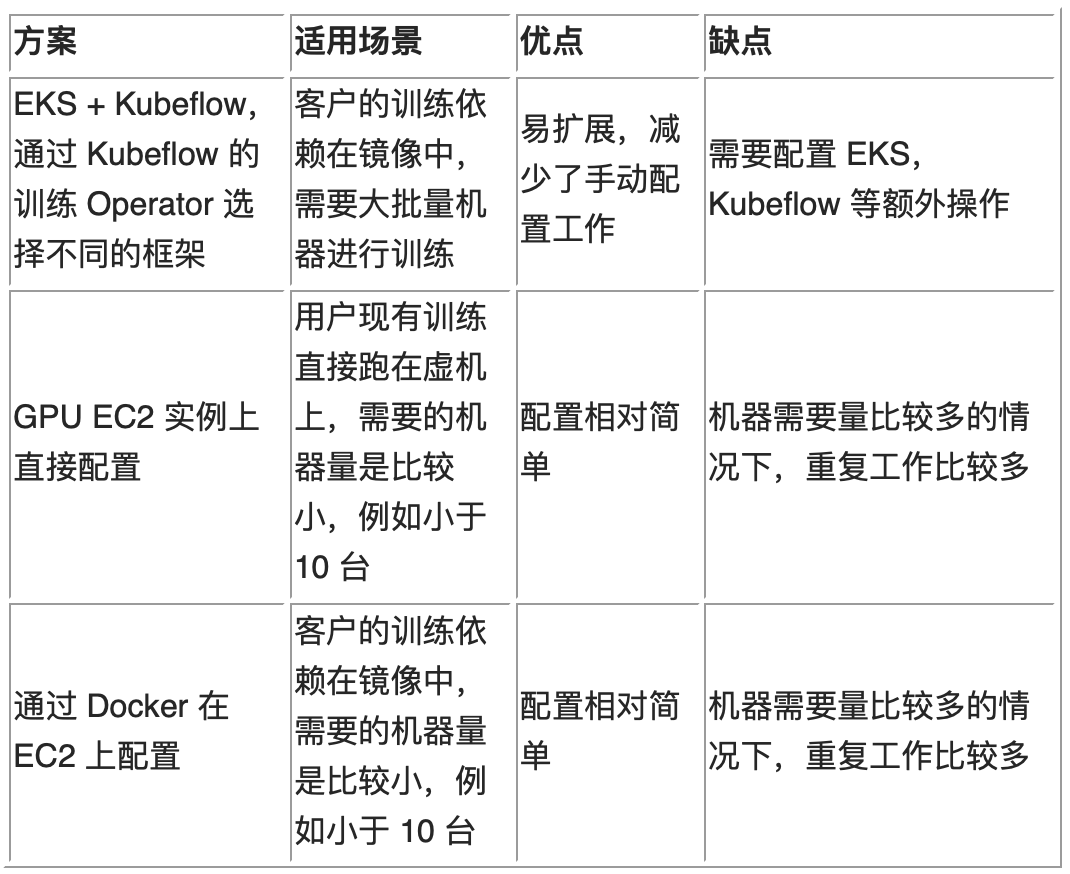
方案概述,包括 3 种我们根据不同的用户场景设计的方案;
配置细节;
实战中碰到的问题分享和最佳实践。
方案概述
本文中,我们基于观察到的 3 种用户的场景给出方案和具体的配置建议。
配置细节
本文提到的 3 种方案,我们都会进行详细地描述。请提前准备下面两个环境:
创建两台 g4dn.xlarge 实例
创建 Amazon Fsx for Lustre 存储,请参考官方文档:
https://docs.aws.amazon.com/fsx/latest/LustreGuide/getting-started-step1.html
Amazon EKS 和 Kubeflow 的方案
进行分布式训练
Kubeflow 是 Kubernetes 的机器学习工具包,目标是利用 Kubernetes 的优点,尽可能简单地扩展机器学习(ML)模型并将它们部署到生产环境。它提供了很多个不同的训练 Operator 支持训练,包括 TensorFlow,MPIJob,Pytorch 等。Kubeflow 训练的 Operator 是一个 Kubernetes 自定义资源,用于在 Kubernetes 上运行 PyTorch,Tensorflow 等培训任务。同时,每一个训练任务都是配置文件,我们需要在配置文件里指定训练需要的资源,依赖的镜像,训练代码等。我们会在今天的配置中使用 MPIJob 去做 Tensorflow 的分布式训练,PytorchJob 去做 Pytorch 的训练,如果您是其他的训练方式,请参考 Kubeflow Training Operators:
https://www.kubeflow.org/docs/components/training/
Kubeflow 的环境建立,这里我不再赘述,在亚马逊云科技海外区请参考 Kubeflow on EKS:
https://awslabs.github.io/kubeflow-manifests/docs/
中国区请参考三剑客 EKS + Kubeflow + Karpenter 助力构建弹性机器学习平台:
https://aws.amazon.com/cn/blogs/china/three-swordsmen-eks-kubeflow-karpenter-help-build-an-elastic-machine-learning-platform/
MPIJob
1. 创建 MPIJob CRD,请不要按照 Kubeflow 的官网提示创建,会报错,建议指定 MPIJob 的 release 版本去添加。成功后我们可以看到“mpijobs.kubeflow.org”。
kubectl apply -f https://raw.githubusercontent.com/kubeflow/mpi-operator/v0.4.0/deploy/v2beta1/mpi-operator.yaml
kubectl get crd
2. 我们还是会使用 Horovod 0.28.1 和 Tensorflow 的代码,但是请注意,我们需要基于 horovod/horovod:0.28.1 去打包一个新的镜像,请参考下面的 Dockerfile 创建新的 Docker 镜像。
mpi-operator 通过 Secret 将 .ssh 文件夹挂载进来。为了使其正常工作,我们需要禁用 UserKnownHostsFile,以避免写入权限的问题,同时禁用 StrictModes 可以避免目录和文件的读取权限检查。
我加了测试的代码,简单起见,我直接克隆了 Horovod 的官方代码。
FROM horovod/horovod:0.28.1
RUN echo " UserKnownHostsFile /dev/null" >> /etc/ssh/ssh_config && \sed -i 's/#\(StrictModes \).*/\1no/g' /etc/ssh/sshd_config
RUN mkdir /tensorflow
WORKDIR "/tensorflow"
RUN git clone https://github.com/horovod/horovod
WORKDIR "/tensorflow/"3. 编辑自己的训练任务,代码如下,替换<YOUR_IMAGE_REPO>为您自己的镜像连接。
apiVersion: kubeflow.org/v2beta1
kind: MPIJob
metadata:name: tf-test
spec:slotsPerWorker: 1runPolicy:cleanPodPolicy: RunningmpiReplicaSpecs:Launcher:replicas: 1template:spec:containers:- image:<YOUR_IMAGE_REPO>name: tf-testcommand:- mpirun- --allow-run-as-root- -np- "2"- -bind-to- none- -map-by- slot- -x- NCCL_DEBUG=INFO- -x- LD_LIBRARY_PATH- -x- PATH- -mca- pml- ob1- -mca- btl- ^openib- python- /horovod/examples/tensorflow2/tensorflow2_mnist.pyWorker:replicas: 2template:spec:nodeSelector: computetype: gpucontainers:- image: <YOUR_IMAGE_REPO>name: tf-testresources:limits:nvidia.com/gpu: 14. 通过 kubectl apply -f tf-test.yaml 提交您的训练任务。
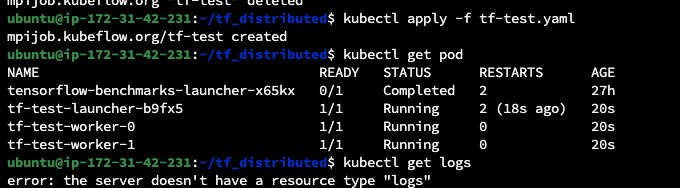
5. 提交后可以看到两台 EKS GPU 节点的用量,提交后也可以通过 kubectl logs -f tf-test-launcher-b9fx5 查看训练日志。
PytorchJob 去执行 Pytorch 的训练任务
1. Kubeflow 在安装成功后,默认会有 pytorchjobs.kubeflow.org ,您可以通过 kubectl get crd 查看。额外,请通过 kubectl get pods -n kubeflow 查看 TrainingOperator 是否正常运行。
training-operator-7589458f95-kjmh2 1/1 Running 0 2d2. 准备本次 PytorchJob 的训练镜像,请参考下面我做实验的 Dockerfile,其分布式训练代码 mnist.py 可以在 Training Operator Github 上下载:
https://github.com/kubeflow/training-operator/blob/master/examples/pytorch/mnist/mnist.py
通过以下 Dockerfile 创建镜像后,上传至您的仓库。
FROM pytorch/pytorch:2.1.2-cuda11.8-cudnn8-develRUN pip install tensorboardXRUN mkdir -p /opt/mnistWORKDIR /opt/mnist/src
ADD mnist.py /opt/mnist/src/mnist.pyRUN chgrp -R 0 /opt/mnist \
&& chmod -R g+rwX /opt/mnistENTRYPOINT ["python", "/opt/mnist/src/mnist.py"]3. 和 MPIJob 一样,提交 Pytorch 任务也是通过定义配置文件的方式,请替换您的仓库地址。使用 kubectl apply -f kubeflow_pytorchjob.yaml 提交作业。
kind: "PyTorchJob"
metadata:name: "pytorch-dist-mnist-gloo"
spec:pytorchReplicaSpecs:Master:replicas: 1restartPolicy: OnFailuretemplate:metadata:annotations:sidecar.istio.io/inject: "false"spec:containers:- name: pytorchimage:<YOUR_IMAGE_REPO>args: ["--backend", "gloo"]#resources: # limits:# nvidia.com/gpu: 1Worker:replicas: 2restartPolicy: OnFailuretemplate:metadata:annotations:sidecar.istio.io/inject: "false"spec:nodeSelector: computetype: gpucontainers: - name: pytorchimage: <YOUR_IMAGE_REPO>args: ["--backend", "gloo"]resources: limits:nvidia.com/gpu: 14. 我们在作业提交后,可以通过 kubectl get pod 去查看 Pod 的情况,以及训练的日志。

GPU EC2 上直接配置
在 EC2 上直接配置时,我们包含了两个框架, Tensorflow 配合 Horovod 和 Pytorch DDP。EC2 上的配置环境,我们使用的是 CUDA 11.8, 一般 EC2 上面默认的很有可能不是 11.8,那请通过下面的命令进行修改或指定您需要的 CUDA 版本。
sudo rm /usr/local/cuda
sudo ln -s /usr/local/cuda-11.8 /usr/local/cuda修改软连接后,把下面的命令写入到 ~/.bashrc 中,并执行 source ~/.bashrc。
export PATH="/usr/local/cuda-11.8/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH"Horovod TensorFlow 分布式
我们建议安装在虚拟环境中安装需要的依赖,以避免需求版本与其他环境发生冲突。通过以下命令创建虚拟环境并使用,可以把虚拟环境创建在 /fsx 下,方便共享使用。
python3 -m virtualenv /fsx/horovod_gpu_ve
source horovod_gpu_ve/bin/activate
1. 下载您的依赖,我这里使用的 Tensorflow 2.4.0 和 Horovod 0.28.1 版本,CUDA,Python, Tensorflow 的版本兼容性问题,可以查看 Tensorflow 的官网:https://www.tensorflow.org/install/source#tested_build_configurations
pip install tensorflow==2.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
HOROVOD_WITH_MPI=1 HOROVOD_WITH_TENSORFLOW=1 pip install --no-cache-dir horovod -i https://pypi.tuna.tsinghua.edu.cn/simple
3. 配置两台机器的免密登录,在 node0 和 node1 上分别执行 ssh-keygen ,复制生成的 id_rsa.pub 文件中密钥,复制到对方的 ~/.ssh/authorized_keys 中,复制之后通过 ssh 登录验证是否成功。
4. Horovod 可以通过下面两种命令开启分布式训练, horovodrun 和 mpirun 。 np 为指定的总 GPU 节点数目, -H node0:1,node1:1 指定每节点上的 GPU 数目。 tensorflow2_mnist.py 为训练代码:
https://github.com/horovod/horovod/blob/master/examples/tensorflow2/tensorflow2_mnist.py
horovodrun -np 2 -H node0:1,node1:1 python code-horovod-gpu/tensorflow2_mnist.py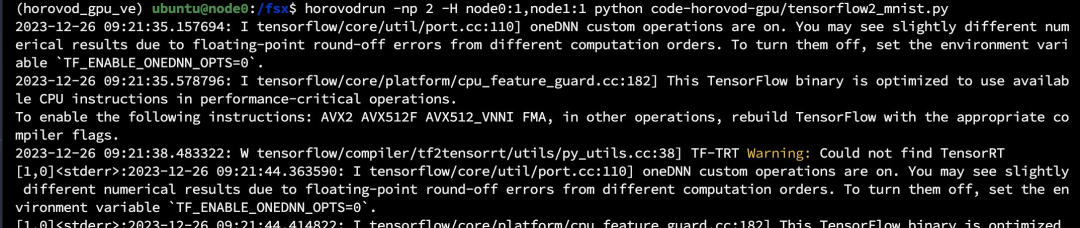

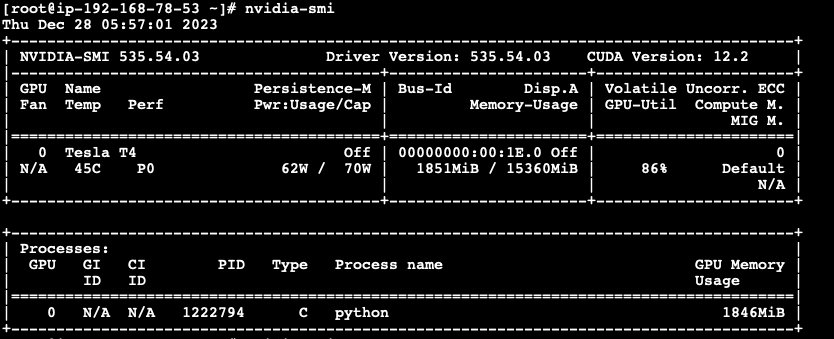
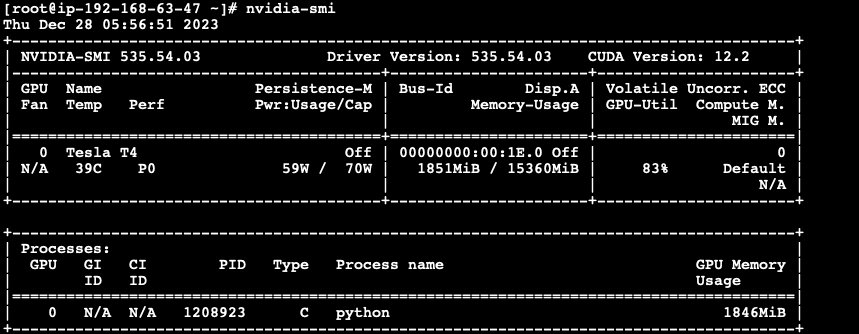
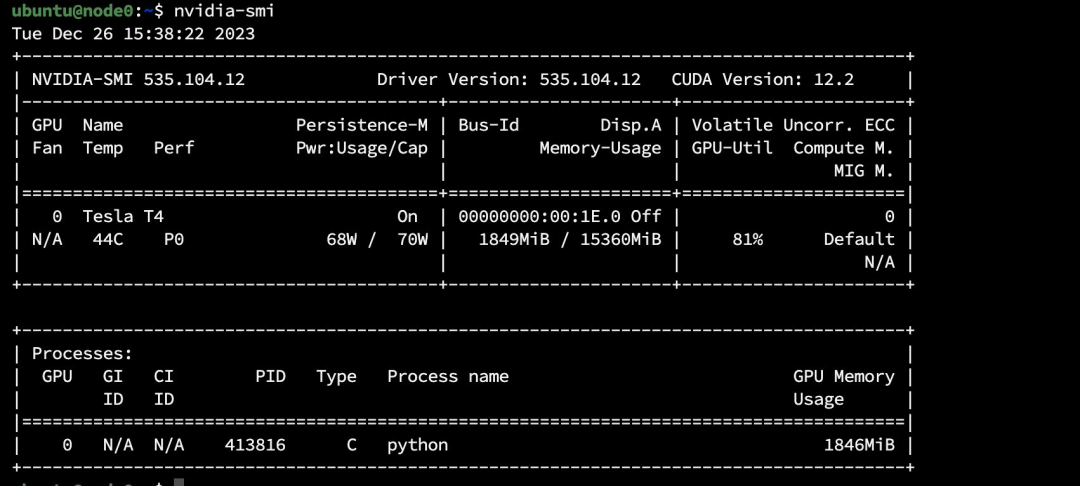
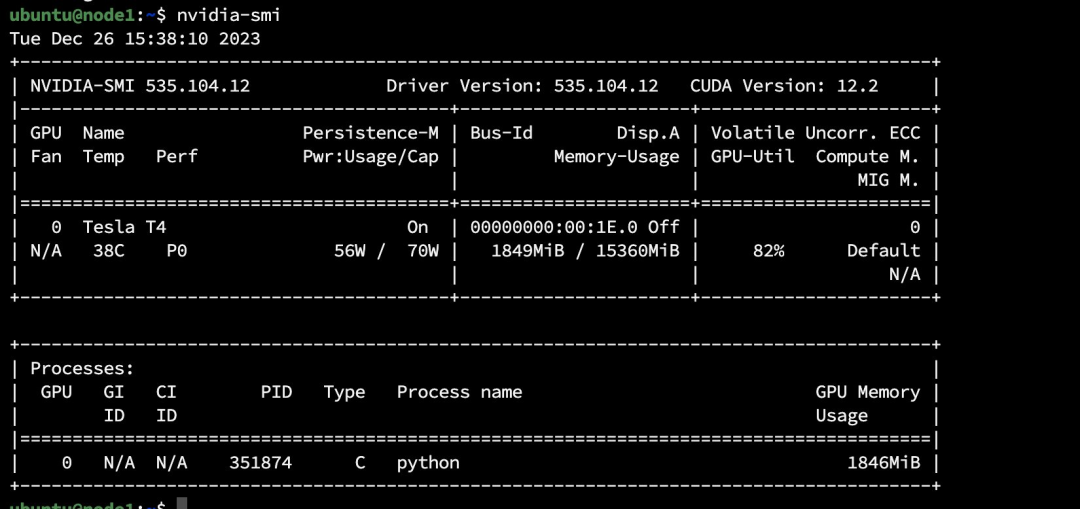
训练已经开始,我们可以通过 nvidia-smi 查看到两个节点都已经开始训练任务。
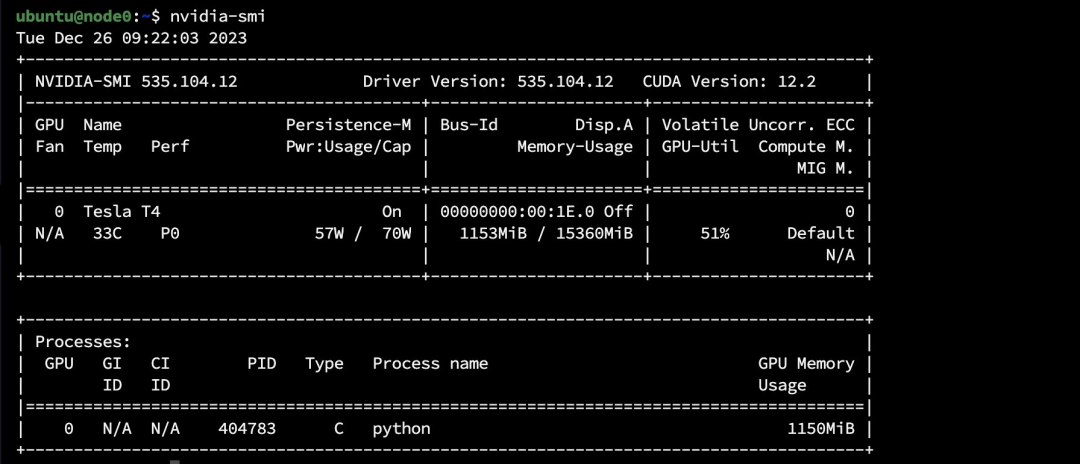
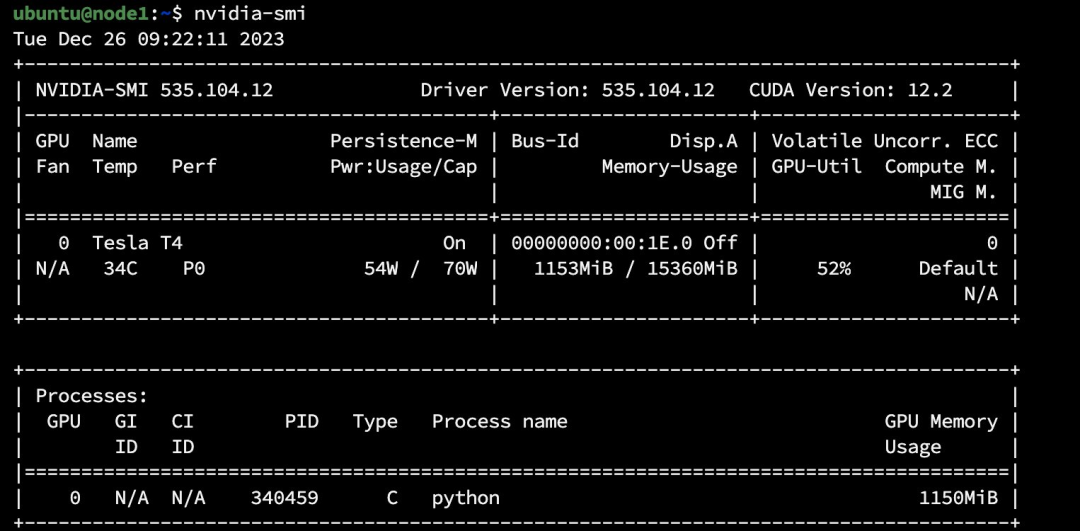
下面是 mpirun 的命令行,通过 -x 指定环境变量, —mca btl_tcp_if_include 指定网卡。
mpirun -np 2 -H node0:1,node1:1 -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH —mca btl_tcp_if_include ens5 python code-horovod-gpu/tensorflow2_mnist.py训练开始后,我们可以通过 nvidia-smi 查看到两个节点的 GPU 使用量。
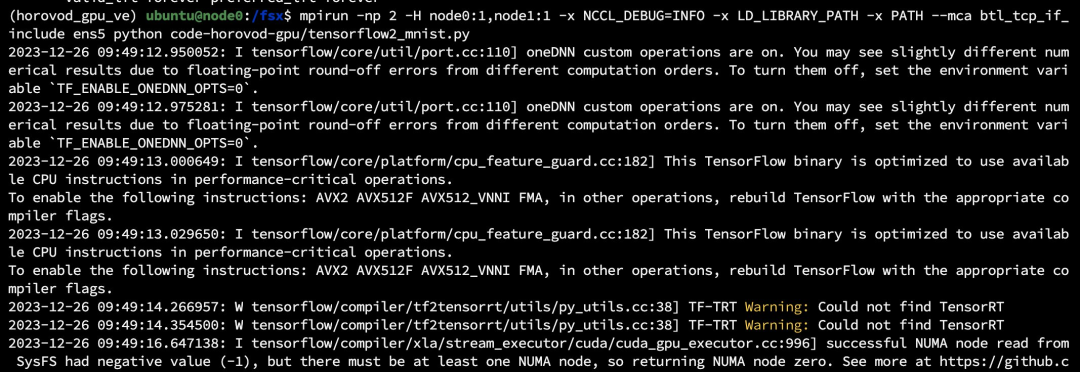
Pytorch 分布式
Pytorch 的分布式多机多卡训练相对比较简单,但下面的命令需要在两个机器上分别运行,训练代码连接为 Pytorch 的官方代码:
https://github.com/pytorch/examples/blob/main/distributed/ddp-tutorial-series/multinode.py
nproc_per_node:每个节点的 GPU 数量
nnodes:节点数量
node_rank: 当前节点的 rank
master_addr:主节点 ip
master_port:10086
torchrun —nproc_per_node=1 —nnodes=2 —node_rank=0 —master_addr='172.31.17.254' —master_port='10086' /fsx/multinode.py —total_epochs=2000 —save_every=1
torchrun —nproc_per_node=1 —nnodes=2 —node_rank=1 —master_addr='172.31.17.254' —master_port='10086' /fsx/multinode.py —total_epochs=2000 —save_every=1
通过 Docker 在 EC2 上配置
我们通过利用 Docker host 网络的方式,让两个节点互相通信。首先按照 EC2 上的配置方法,配置 /etc/hosts 中的两个节点。
两节点免密登录,请首先 sudo su 后,执行 EC2 上的免密配置方法
在两个节点上启动 Docker 容器,我这里使用的也同样是 horovod/horovod:0.28.1 版本的镜像,训练脚本依旧是 tensorflow2_mnist.py ,这里需要映射环境变量和 ssh 的配置
nvidia-docker run -it —ipc=host —network=host -v /fsx/code-horovod-gpu/:/vol/ -v /root/.ssh/:/root/.ssh/ -e LD_LIBRARY_PATH=/usr/local/lib horovod/horovod:0.28.1
3. 在两个 Docker 镜像中, 重新设置 ssh 端口为 2022,这个是为了避免宿主机的 22 端口冲突。配置后可以通过 ssh -p 2022 node0 去测试两个 Docker 镜像是否可以 ssh 登录成功
echo "Port 2022" >> /etc/ssh/sshd_config
/usr/sbin/sshd -D&
4. 配置成功后,我们可以选择下面的两个命令去执行分布式训练
horovodrun -np 2 -H node0:1,node1:1 -p 2022 python /vol/tensorflow2_mnist.pympirun —allow-run-as-root -np 2 -H node0:1,node1:1 -x NCCL_DEBUG=INFO —mca plm_rsh_args "-p 2022" -x LD_LIBRARY_PATH -x PATH —mca btl_tcp_if_include ens5 python /vol/tensorflow2_mnist.py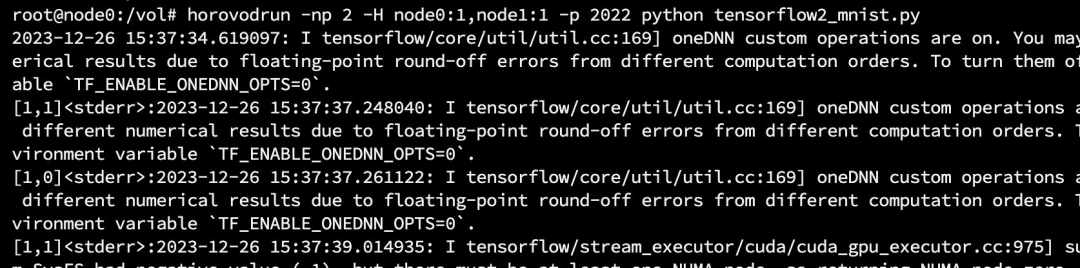
实战中碰到的问题分享
和最佳实践
在实际操作的时候,因为训练环境的依赖和训练代码等版本的问题,肯定会碰到各种各样的问题。我们把碰到的问题总结了下,您可以作为参考。
1. 在使用 mpirun 的时候, 我们经常碰到的问题。提示没有对应的可执行程序,例如 cannot find /usr/bin/orted,这时候您可以通过两个方面进行筛查:
如果您是通过 docker 的方式运行的,可以查看是否是两个 docker 容器在互相访问,因为有一种情况是 docker 容器 ssh 直接登录到的是另一个节点。如果是这种情况,我们建议避免掉 22 端口复用,例如您可以修改 docker 容器的 ssh 端口为 2022,并且 mpirun 命令 —mca plm_rsh_args "-p 2022" ,我们发现可能和 mpirun 的版本有关系,有的时候 mpirun 不指定 2022 端口可以正常训练,但有的版本会出错。
还有一种情况是,mpirun 需要通过 -x 设置环境变量,所以我们在测试过程中通过 -x LD_LIBRARY_PATH -x PATH 把两端的环境变量设置好。我们建议把您需要的环境变量放在一个文件中,在第一台机器上 source 后,通过-x 进行设置。
2. 使用 mpirun 的时候,最初没有加—mca btl_tcp_if_include ens5 , 会提示下面的错误,一直不进行训练。
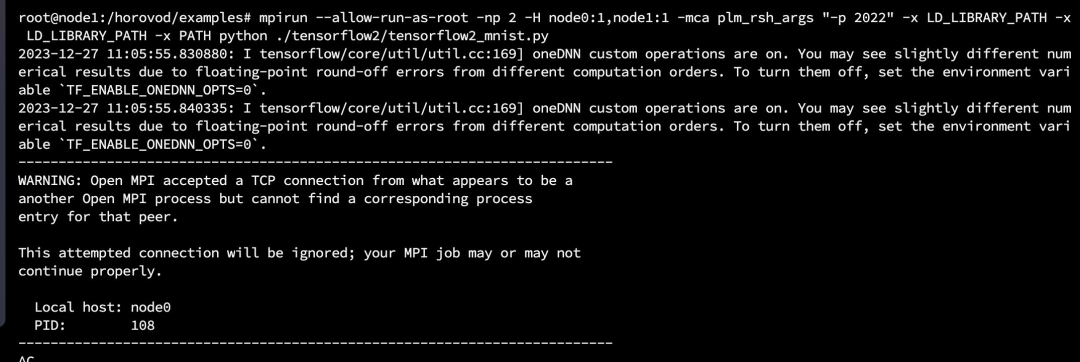
3. 使用 mpirun 的情况, 提示错误 BLAS: Program is Terminated. Because you tried to allocate too many memory regions . 这个可以通过 OPENBLAS_NUM_THREADS,GOTO_NUM_THREADS , OMP_NUM_THREADS 这几个值设置为 1 解决,但一定注意要通过 mpirun -x 在多台机器上配置,我们在这个上面浪费了一段时间。
4. 我们在执行的时候碰到了这个错误提示, "One or more tensors were submitted to be reduced, which will cause deadlock" ,训练任务一直 Pending,后来通过换了镜像版本解决了这个问题,建议大家一定要根据 Tensorflow 官方建议的兼容版本进行使用。
5. 观察训练性能时,我们最开始是通过每步 Step 花费的时间去统计,但后来发现 Horovod 的 Step 是根据每个 GPU 去统计的,我们的代码里只输出了第一个 GPU 的 Step 值,所以造成对亚马逊云科技的 GPU 性能有了误解,在转变成观察收敛速度后,确实是会快的。
总结
在本文中,我们详细总结了用户在日常工作中可能会遇到的多机多卡分布式训练的 3 种方式,并提供了几种不同的方案配置细节,正在考虑在亚马逊云科技上开始分布式训练的用户可以根据这些方案涵盖的技术栈和适用场景,并对它们的优缺点进行了全面评估,选择合适自己的方案。
近年来,亚马逊云科技也发布了一系列服务帮助用户构建分布式训练环境,比如 Amazon ParallelCluster 和 Amazon SageMaker HyperPod,感兴趣的读者也可以联系作者,共同探讨相关的技术话题。
本篇作者

冯秋爽
亚马逊云科技解决方案架构师,负责跨国企业级客户基于亚马逊云科技的技术架构设计、咨询和设计优化工作。在加入亚马逊云科技之前曾就职于 IBM、甲骨文等 IT 企业,积累了丰富的程序开发和数据库的实践经验。

张铮
亚马逊云科技机器学习产品技术专家,负责基于亚马逊云科技加速计算和 GPU 实例的咨询和设计工作。专注于机器学习大规模模型训练和推理加速等领域,参与实施了国内多个机器学习项目的咨询与设计工作。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!


![[项目设计] 从零实现的高并发内存池(四)](https://img-blog.csdnimg.cn/c446ebae288e480d84f5d14d494c88bb.gif)




![[云原生] K8s之pod控制器详解](https://img-blog.csdnimg.cn/direct/140b5e8f5ada48bd844a0f7d1ed95e0c.png)