经历了2023年的秋招,现在也已经入职半年了,空闲时间将面试中可能遇到的机器学习问题整理了一下,可能答案也会有错误的,希望大家能指出!另外,不论是实习,还是校招,都祝福大家能够拿到满意的Offer!
机器学习面经系列的其他部分如下所示:
机器学习-面经(part2)-交叉验证、超参数优化、评价指标等内容
机器学习-面经(part3)-正则化、特征工程面试问题与解答合集
机器学习-面经(part4)-决策树共5000字的面试问题与解答
机器学习-面经(part5)-KNN以及SVM等共二十多个问题及解答
机器学习-面经(part6)-集成学习(万字解答)
机器学习-面经(part7、无监督学习)
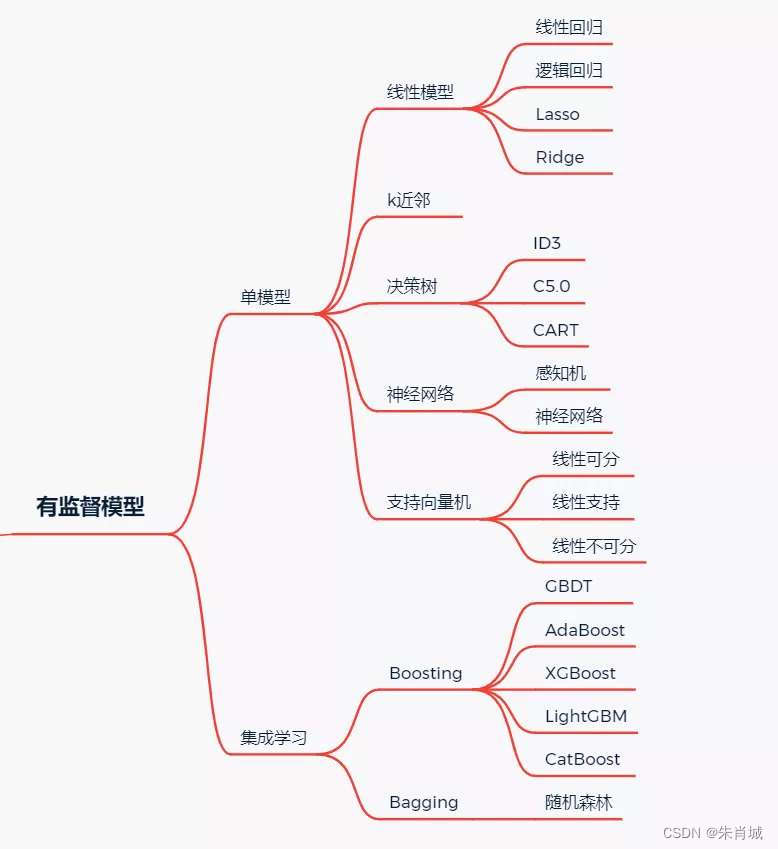
1、机器学习模型
1.1 有监督学习模型
1.2 无监督学习模型

1.3 概率模型

1.4、什么是监督学习?什么是非监督学习?
所有的回归算法和分类算法都属于监督学习。并且明确的给给出初始值,在训练集中有特征和标签,并且通过训练获得一个模型,在面对只有特征而没有标签的数据时,能进行预测。
监督学习:通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如 分类。
非监督学习:直接对输入数据集进行建模,例如强化学习、K-means 聚类、自编码、受限波尔兹曼机。
半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。
目前最广泛被使用的分类器有人工神经网络、支持向量机、最近邻居法、高斯混合模型、朴素贝叶斯方法、决策树和径向基函数分类。
无监督学习里典型的例子就是聚类了。聚类的目的在于把相似的东西聚在一起,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。
1.5、回归、分类、聚类的区别与联系

1.6、生成模式 vs 判别模式
生成模型: 由数据学得联合概率分布函数 P(X,Y),求出条件概率分布P(Y|X)的预测模型。 朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机。 判别式模型: 由数据直接学习决策函数 Y = f(X),或由条件分布概率 P(Y|X)作为预测模型。 K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场。
2、线性模型
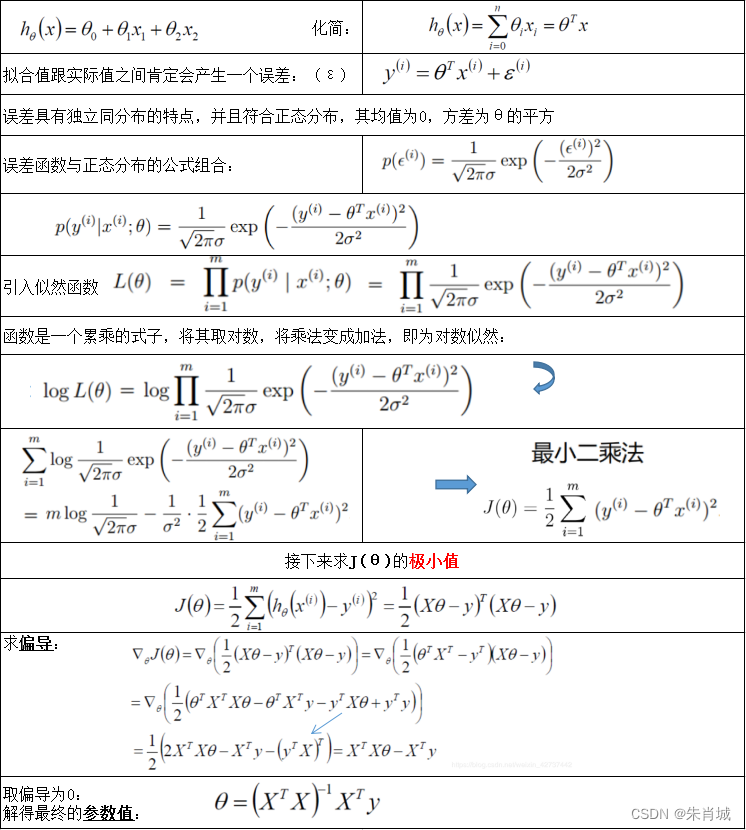
2.1 线性回归
原理: 用线性函数拟合数据,用 MSE 计算损失,然后用梯度下降法(GD)找到一组使 MSE 最小的权重。
线性回归的推导如下所示:
2.1.1 什么是回归?哪些模型可用于解决回归问题?
- 指分析因变量和自变量之间关系.
- 线性回归: 对异常值非常敏感
- 多项式回归: 如果指数选择不当,容易过拟合。
- 岭回归
- Lasso回归
- 弹性网络回归
2.1.2 线性回归的损失函数为什么是均方差?

2.1.3 什么是线性回归?什么时候使用它?
利用最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析.
- 自变量与因变量呈直线关系;
- 因变量符合正态分布;
- 因变量数值之间独立;
- 方差是否齐性。
2.1.4 什么是梯度下降?SGD的推导?
BGD: 遍历全部数据集计算一次loss函数,然后算函数对各个参数的梯度,更新梯度。

BGD、SGD、MBGD之间的区别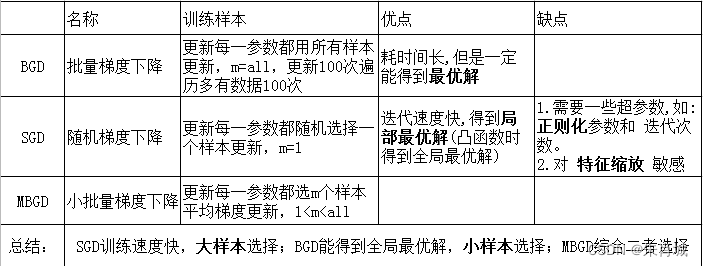

2.1.5 什么是最小二乘法(最小平方法)?
它通过最小化误差的平方和寻找数据的最佳函数匹配。
2.1.6 常见的损失函数有哪些?
- 0-1损失
- 均方差损失(MSE)
- 平均绝对误差(MAE)
- 分位数损失(Quantile Loss)
- 分位数回归可以通过给定不同的分位点,拟合目标值的不同分位数; 实现了分别用不同的系数控制高估和低估的损失,进而实现分位数回归
- 交叉熵损失
- 合页损失 一种二分类损失函数,SVM的损失函数本质: Hinge Loss + L2 正则化 合页损失的公式如下:
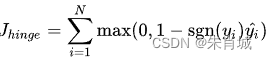
2.1.7 有哪些评估回归模型的指标?
衡量线性回归法最好的指标: R-Squared

2.1.8 什么是正规方程?
正规方程组是根据最小二乘法原理得到的关于参数估计值的线性方程组。正规方程是通过求解![]() 来找出使得代价函数最小的参数解出:
来找出使得代价函数最小的参数解出: ![]()
2.1.9 梯度下降法找到的一定是下降最快的方向吗?
不一定,它只是目标函数在当前的点的切平面上下降最快的方向。 在实际执行期中,牛顿方向(考虑海森矩阵)才一般被认为是下降最快的方向,可以达到超线性的收敛速度。梯度下降类的算法的收敛速度一般是线性甚至次线性的(在某些带复杂约束的问题)。
2.1.10 MBGD需要注意什么? 如何选择m?
一般m取2的幂次方能充分利用矩阵运算操作。 一般会在每次遍历训练数据之前,先对所有的数据进行随机排序,然后在每次迭代时按照顺序挑选m个训练集数据直至遍历完所有的数据。
2.2 LR
也称为"对数几率回归"。
知识点提炼
- 1.分类,经典的二分类算法!
- 2.LR的过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证这个求解的模型的好坏。
- 3.Logistic 回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别)
- 4.回归模型中,y 是一个定性变量,比如 y = 0 或 1,logistic 方法主要应用于研究某些事件发生的概率。
- 5.LR的本质:极大似然估计
- 6.LR的激活函数:Sigmoid
- 7.LR的代价函数:交叉熵
优点:
- 1.速度快,适合二分类问题
- 2.简单易于理解,直接看到各个特征的权重
- 3.能容易地更新模型吸收新的数据
缺点:
- 对数据和场景的适应能力有局限性,不如决策树算法适应性那么强。LR中最核心的概念是 Sigmoid 函数,Sigmoid函数可以看成LR的激活函数。
- Regression 常规步骤:
- 寻找h函数(即预测函数)
- 构造J函数(损失函数)
- 想办法(迭代)使得J函数最小并求得回归参数(θ)
LR伪代码:
- 初始化线性函数参数为1
- 构造sigmoid函数
- 重复循环I次
- 计算数据集梯度
- 更新线性函数参数
- 确定最终的sigmoid函数
- 输入训练(测试)数据集
- 运用最终sigmoid函数求解分类

2.2.1 为什么 LR 要使用 sigmoid 函数?
1.广义模型推导所得 2.满足统计的最大熵模型 3.性质优秀,方便使用(Sigmoid函数是平滑的,而且任意阶可导,一阶二阶导数可以直接由函数值得到不用进行求导,这在实现中很实用)
2.2.2 为什么常常要做特征组合(特征交叉)?
- LR模型属于线性模型,线性模型不能很好处理非线性特征,特征组合可以引入非线性特征,提升模型的表达能力。
- 另外,基本特征可以认为是全局建模,组合特征更加精细,是个性化建模,但对全局建模会对部分样本有偏,
- 对每一个样本建模又会导致数据爆炸,过拟合,所以基本特征+特征组合兼顾了全局和个性化。
2.2.3 为什么LR比线性回归要好?
- LR和线性回归首先都是广义的线性回归;其次经典线性模型的优化目标函数是最小二乘,而LR则是似然函数;另外线性回归在整个实数域范围内进行预测,敏感度一致,而分类范围,需要在[0,1]。LR就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型,因而对于这类问题来说,LR的鲁棒性比线性回归的要好
2.2.4 LR参数求解的优化方法?(机器学习中常用的最优化方法)
梯度下降法,随机梯度下降法,牛顿法,拟牛顿法(LBFGS,BFGS,OWLQN)
目的都是求解某个函数的极小值。
2.2.5 工程上,怎么实现LR的并行化?有哪些并行化的工具?
- LR的并行化最主要的就是对目标函数梯度计算的并行化。
- 无损的并行化:算法天然可以并行,并行只是提高了计算的速度和解决问题的规模,但和正常执行的结果是一样的。
- 有损的并行化:算法本身不是天然并行的,需要对算法做一些近似来实现并行化,这样并行化之后的双方和正常执行的结果并不一致,但是相似的。
- 基于Batch的算法都是可以进行无损的并行化的。而基于SGD的算法都只能进行有损的并行化。
2.2.6 LR如何解决低维不可分问题?
通过特征变换的方式把低维空间转换到高维空间,而在低维空间不可分的数据,到高维空间中线性可分的几率会高一些。
具体方法:核函数,如:高斯核,多项式核等等
2.2.7 LR与最大熵模型MaxEnt的关系?
没有本质区别。LR是最大熵对应类别为二类时的特殊情况,也就是当LR类别扩展到多类别时,就是最大熵模型。
2.2.8 为什么 LR 用交叉熵损失而不是平方损失(MSE)?
![]()
如果使用均方差作为损失函数,求得的梯度受到sigmoid函数导数的影响;
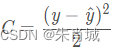 求导:
求导:![]()
如果使用交叉熵作为损失函数,没有受到sigmoid函数导数的影响,且真实值与预测值差别越大,梯度越大,更新的速度也就越快。
![]() 求导:
求导:![]()
记忆:mse的导数里面有sigmoid函数的导数,而交叉熵导数里面没有sigmoid函数的导数,sigmoid的导数的最大值为0.25,更新数据时太慢了。
2.2.9 LR能否解决非线性分类问题?
可以,只要使用kernel trick(核技巧)。不过,通常使用的kernel都是隐式的,也就是找不到显式地把数据从低维映射到高维的函数,而只能计算高维空间中数据点的内积。
2.2.10 用什么来评估LR模型?
- 1.由于LR是用来预测概率的,可以用AUC-ROC曲线以及混淆矩阵来确定其性能。
- 2.LR中类似于校正R2 的指标是AIC。AIC是对模型系数数量惩罚模型的拟合度量。因此,更偏爱有最小的AIC的模型。
2.2.11 LR如何解决多分类问题?(OvR vs OvO)

2.2.12 在训练的过程当中,如果有很多的特征高度相关或者说有一个特征重复了100遍,会造成怎样的影响?
如果在损失函数最终收敛的情况下,其实就算有很多特征高度相关也不会影响分类器的效果。但是对特征本身来说的话,假设只有一个特征,在不考虑采样的情况下,你现在将它重复100遍。训练以后完以后,数据还是这么多,但是这个特征本身重复了100遍,实质上将原来的特征分成了100份,每一个特征都是原来特征权重值的百分之一。如果在随机采样的情况下,其实训练收敛完以后,还是可以认为这100个特征和原来那一个特征扮演的效果一样,只是可能中间很多特征的值正负相消了。
2.2.13 为什么在训练的过程当中将高度相关的特征去掉?
- 去掉高度相关的特征会让模型的可解释性更好。
- 可以大大提高训练的速度。如果模型当中有很多特征高度相关的话,就算损失函数本身收敛了,但实际上参数是没有收敛的,这样会拉低训练的速度。
- 其次是特征多了,本身就会增大训练的时间。
2.3 Lasso
定义:所有参数绝对值之和,即L1范数,对应的回归方法。
Lasso(alpha=0.1) # 设置学习率
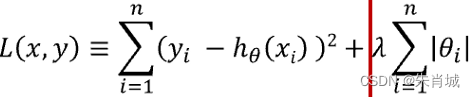
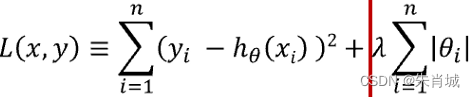
2.4 Ridge
- 定义:所有参数平方和,即L2范数,对应的回归方法。
- 通过对系数的大小施加惩罚来解决 普通最小二乘法 的一些问题。
- Ridge(alpha=0.1) # 设置惩罚项系数
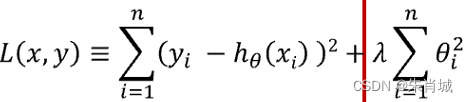
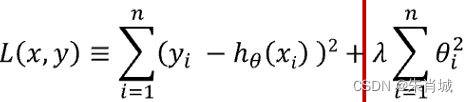
2.5 Lasso vs Ridge

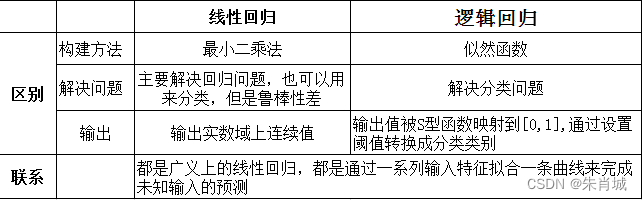
2.6 线性回归 vs LR













![[数据结构初阶]队列](https://img-blog.csdnimg.cn/direct/db1d4c5bb9fe4e9996831e6a95854ac6.jpeg)
