目录
一. pyspark交互式编程示例(学生选课成绩统计)
该系总共有多少学生;
该系DataBase课程共有多少人选修;
各门课程的平均分是多少;
使用累加器计算共有多少人选了DataBase这门课。
二.编写独立应用程序实现数据去重示例
该系共开设了多少门课程?
Tom同学的总成绩平均分是多少?
求每名同学的选修的课程门数?
编写独立应用程序实现求平均值问题
一. pyspark交互式编程示例(学生选课成绩统计)
请下载chapter4-data1.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
请根据给定的实验数据,在pyspark中通过编程来计算以下内容:
【参考答案】
-
该系总共有多少学生;
>>> lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")>>> res = lines.map(lambda x:x.split(",")).map(lambda x: x[0]) //获取每行数据的第1列 >>> distinct_res = res.distinct() //去重操作>>> distinct_res.count()//取元素总个数//265答案为:265人
-
该系DataBase课程共有多少人选修;
>>> lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")>>> res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")>>> res.count()//126答案为126人
-
各门课程的平均分是多少;
>>> lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")>>> res = lines.map(lambda x:x.split(",")).map(lambda x:(x[1],(int(x[2]),1))) //为每门课程的分数后面新增一列1,表示1个学生选择了该课程。格式如('ComputerNetwork', (44, 1))>>> temp = res.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])) //按课程名聚合课程总分和选课人数。格式如('ComputerNetwork', (7370, 142))>>> avg = temp.map(lambda x:(x[0], round(x[1][0]/x[1][1],2)))//课程总分/选课人数 = 平均分,并利用round(x,2)保留两位小数>>> avg.foreach(print)答案为:
('ComputerNetwork', 51.9)('Software', 50.91)('DataBase', 50.54)('Algorithm', 48.83)('OperatingSystem', 54.94)('Python', 57.82)('DataStructure', 47.57)('CLanguage', 50.61)
使用累加器计算共有多少人选了DataBase这门课。
>>> lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")>>> res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")//筛选出选了DataBase课程的数据>>> accum = sc.accumulator(0) //定义一个从0开始的累加器accum>>> res.foreach(lambda x:accum.add(1))//遍历res,每扫描一条数据,累加器加1>>> accum.value //输出累加器的最终值//126答案:共有126人
二.编写独立应用程序实现数据去重示例
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
(1)假设当前目录为/usr/local/spark/mycode/remdup,在当前目录下新建一个remdup.py文件,复制下面代码;
|
(2)最后在目录/usr/local/spark/mycode/remdup下执行下面命令执行程序(注意执行程序时请先退出pyspark shell,否则会出现“地址已在使用”的警告);
| $ python3 remdup.py |
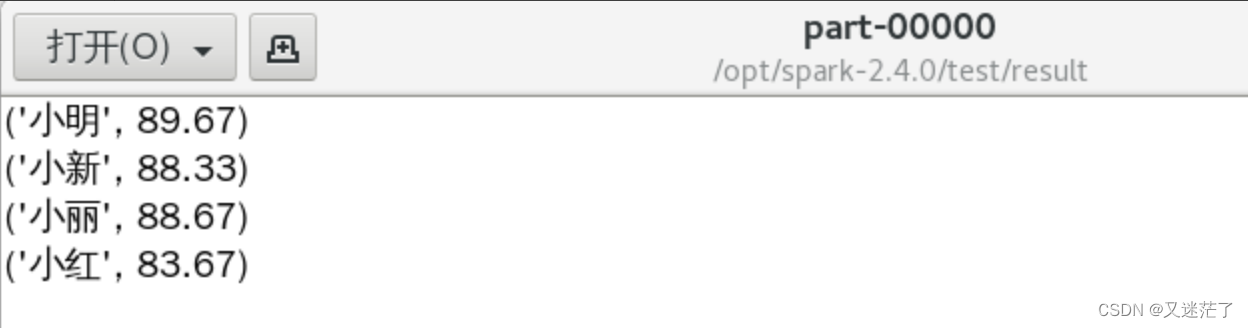
(3)在目录/usr/local/spark/mycode/remdup/result下即可得到结果文件part-00000。
拓展
-
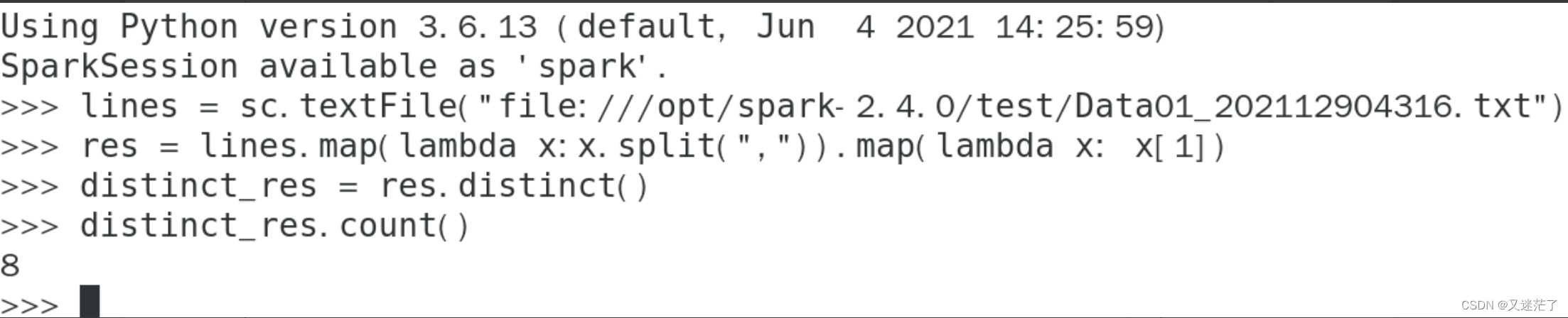
该系共开设了多少门课程?
-
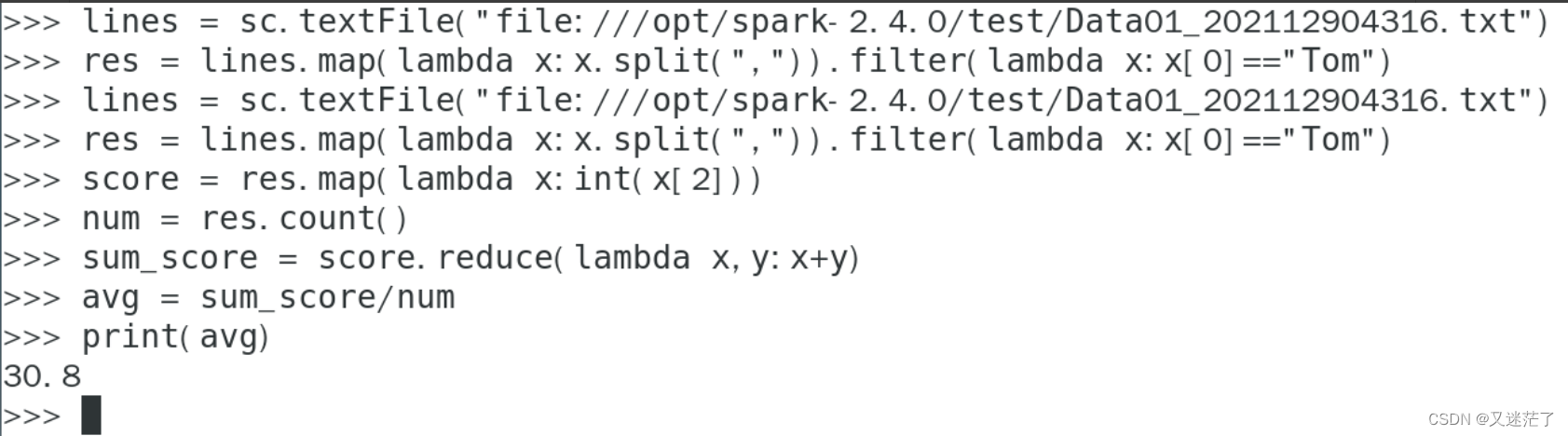
Tom同学的总成绩平均分是多少?
-
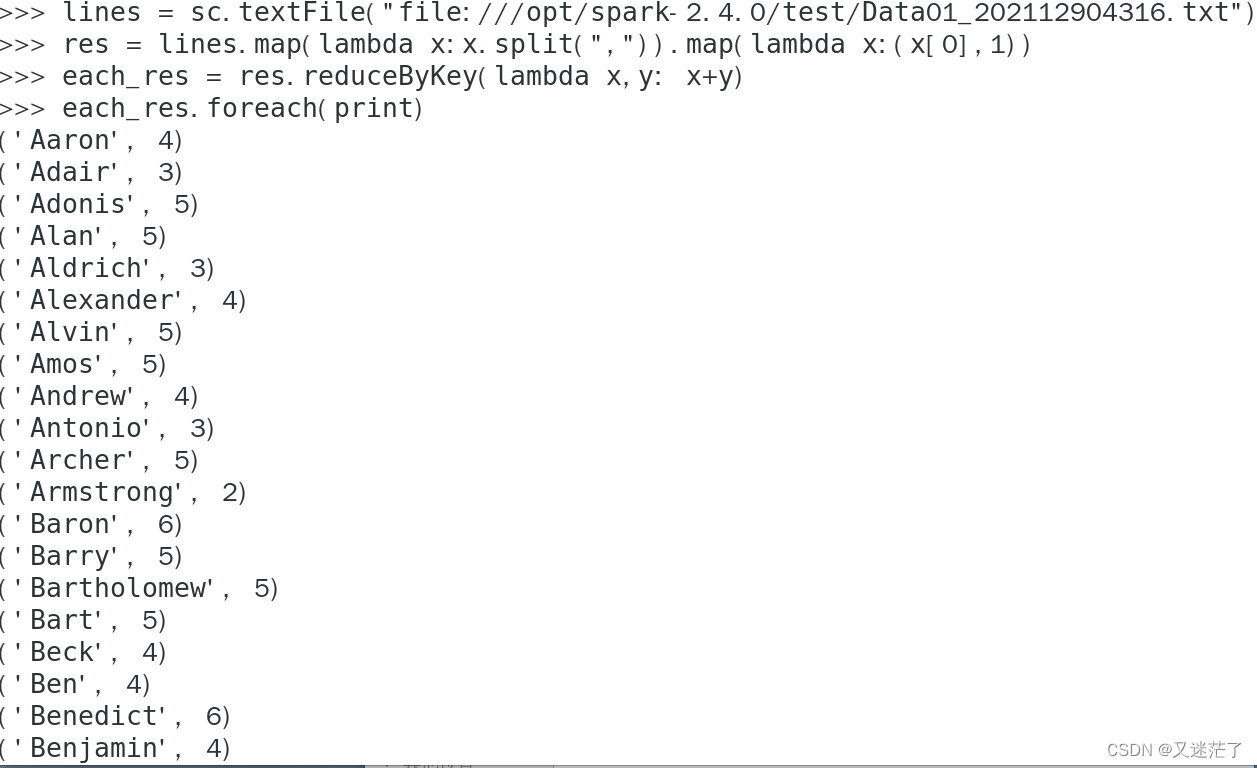
求每名同学的选修的课程门数?
-
编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,
Algorithm成绩(文件名 Algorithm_.txt):
小明 92
小红 87
小新 82
小丽 90
Database成绩(文件名 Database_.txt):
小明 95
小红 81
小新 89
小丽 85
Python成绩(文件名 Python_.txt):
小明 82
小红 83
小新 94
小丽 91
平均成绩格式如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)