目录
- 一、推荐文章视频
- 一、ddddocr环境配置
- 二、字符集验证码训练
- 三、ocr_api_server服务搭建
一、推荐文章视频
- 文章原文来自这里:训练验证码-4、ddddocr训练字符验证码 ,
原文文章末尾有视频介绍 - 更多内容见训练验证码合集
一、ddddocr环境配置
1.打开ddddocr项目 https://github.com/sml2h3/dddd_trainer 进行下载压缩包并解压,文章末尾是视频介绍,如果文字有些不清楚,可以看视频操作
图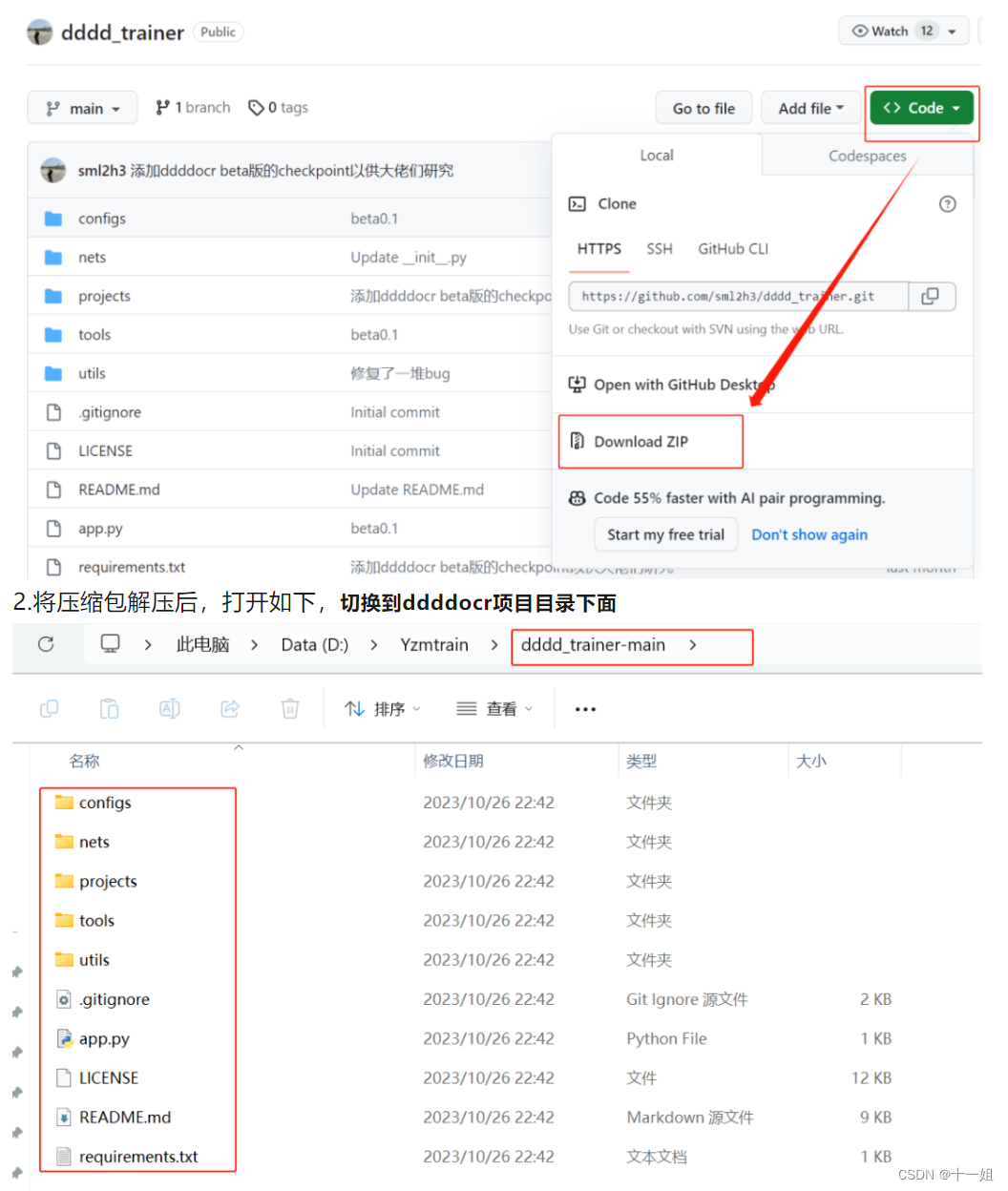
fire
loguru
pyyaml
tqdm
numpy
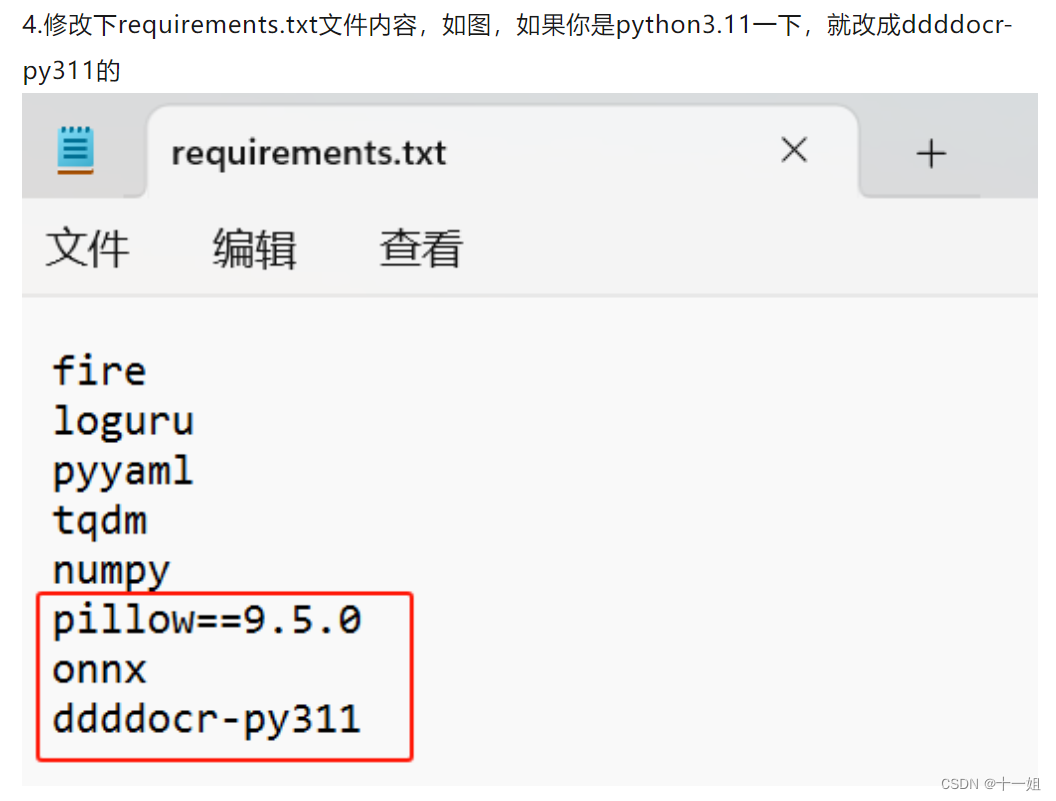
pillow==9.5.0
onnx
ddddocr-py311
5.创建ddddocr训练专属的虚拟环境,注意这里我安装的pytorch版本对应,请看上面文章找自己cuda对应的torch版本安装(该篇文章 深度学习环境安装 目录三),依次执行如下命令
- conda create -n dd python=3.11
- conda activate dd
- pip install -r requirements.txt
- N卡gpu训练:conda install pytorch2.0.1 torchvision0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c nvidia
- 只cpu训练:conda install pytorch2.0.1 torchvision0.15.2 torchaudio==2.0.2 cpuonly
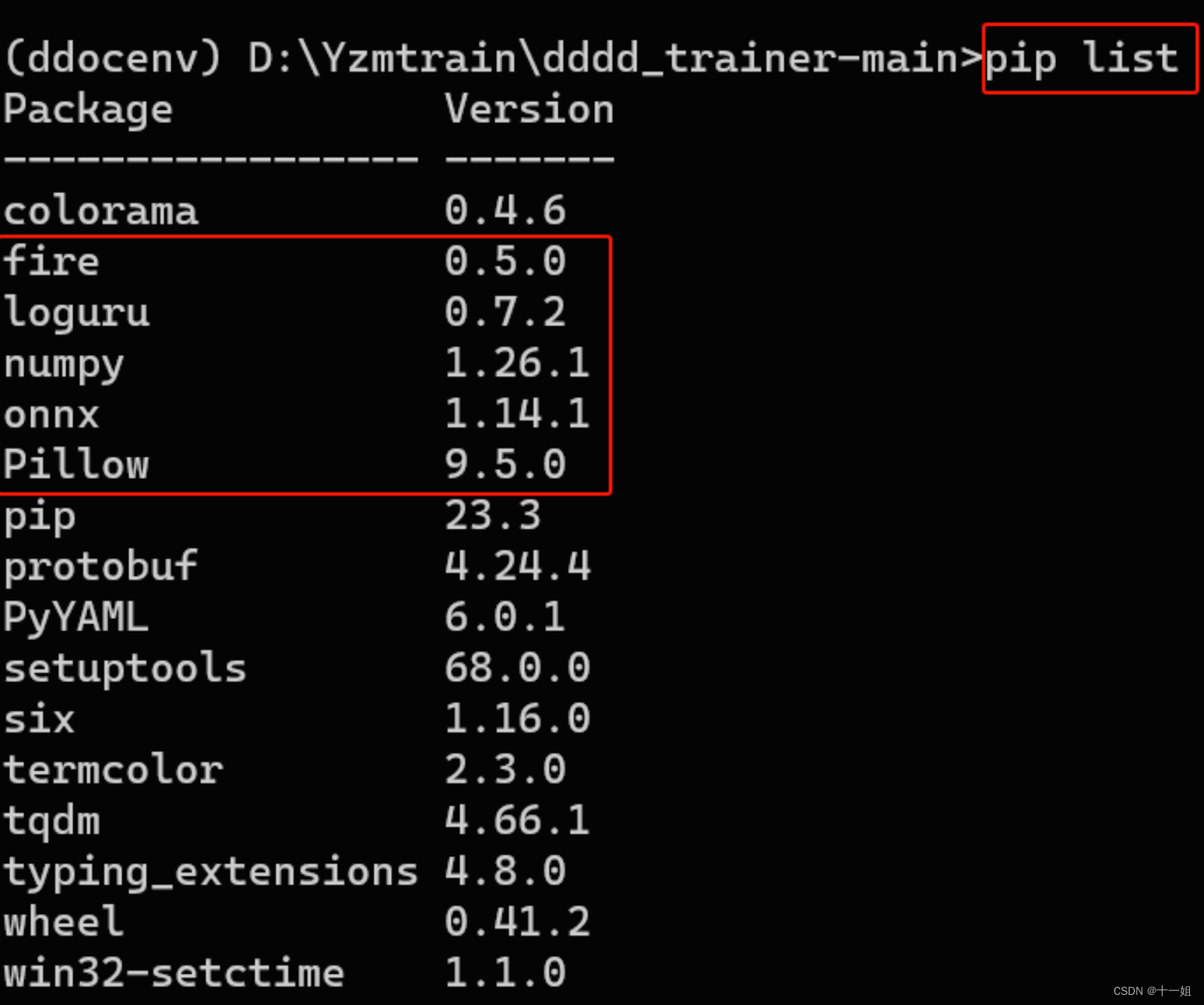
6.可以训练字母/数字/汉字/定长/不定长/大小写/乘号加减号等,报错解决推荐文章 https://blog.csdn.net/weixin_68123638/article/details/131463026
二、字符集验证码训练
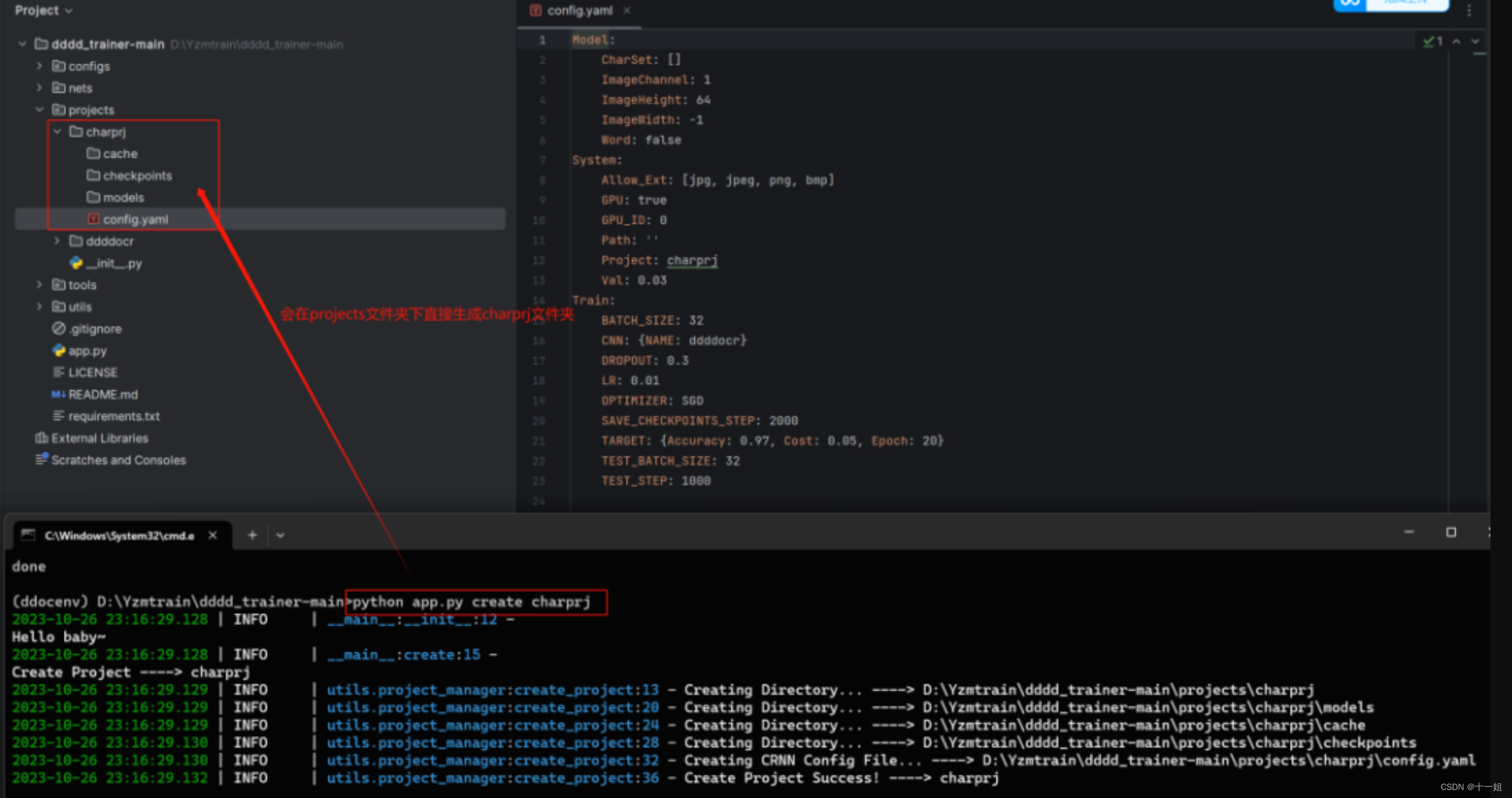
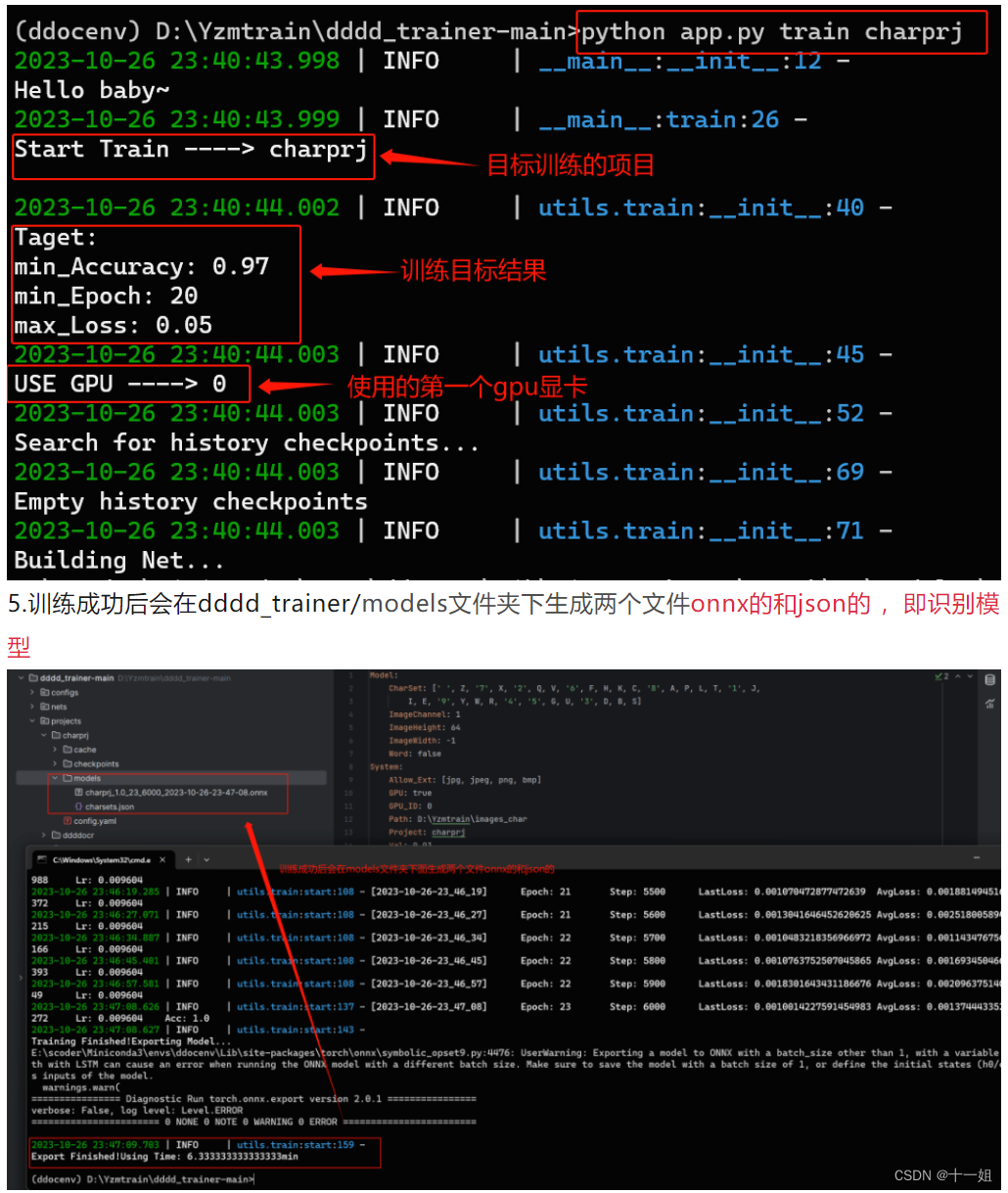
1.创建训练项目:python app.py create charprj , 如图这时候在dddd_trainer/projects下会自动生成一个charprj的文件夹,并且包含三个空文件夹cache、checkpoints、models 和一个config.yaml配置文件
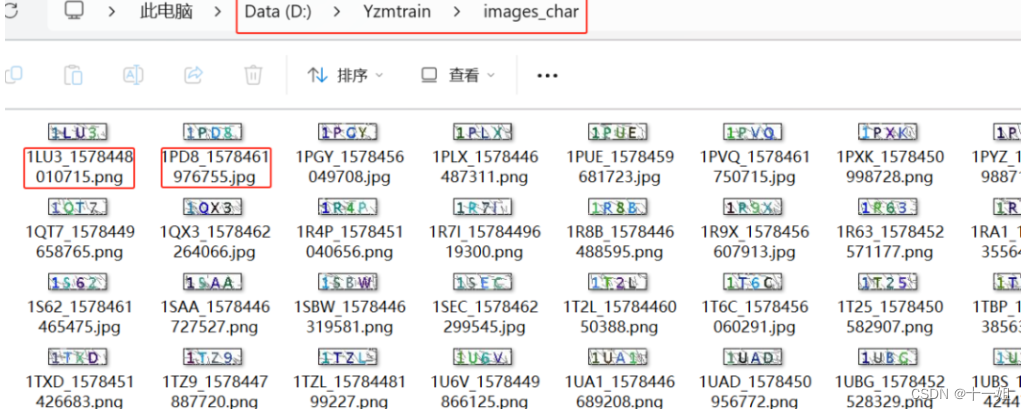
2.准备数据集:听说至少需要1200张图片(不确定), 如图我在D:\Yzmtrain\images_char 目录下面放了一些数据集,这些数据集的命名,名称_随机hash值
3.如果是单个汉字的话,python app.py create charprj --single , 如果想要创建一个CNN的项目,则可以加上–single参数,CNN项目识别比如图片类是什么分类的情况,比如图片上只有一个字,识别这张图是什么字(图上有多个字的不要用CNN模式),又比如分辨图片里是狮子还是兔子用CNN模式比较合适,大多数OCR需求请不要使用–single

3.缓存数据配置:python app.py cache charprj D:\Yzmtrain\images_char ,dddd_trainer/cache文件夹下会生成两个文件cache.train.tmp和cache.val.tmp,里面记录的就是images文件夹下面的图片信息
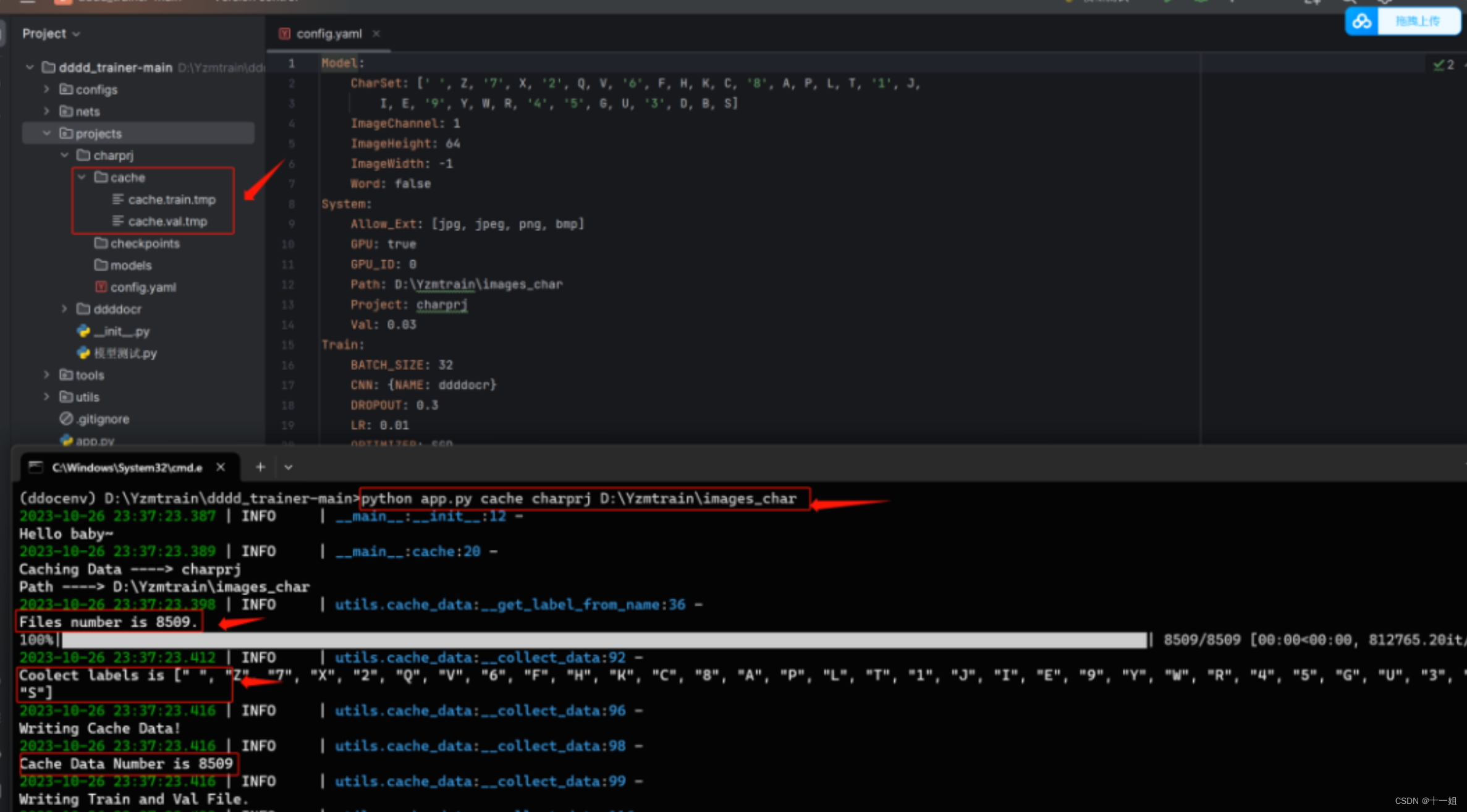
Model:CharSet: [] # 字符集,不要动,会自动生成ImageChannel: 1 # 图片通道数,如果你想以灰度图进行训练,则设置为1,彩图,则设置为3。如果设置为1,数据集是彩图,项目会在训练的过程中自动在内存中将读取到的彩图转为灰度图,并不需要提前自己修改并且该设置不会修改本地图片ImageHeight: 64 # 图片自动缩放后的高度,单位为px,高度必须为16的倍数,会自动缩放图像ImageWidth: -1 # 图片自动缩放后的宽度,单位为px,本项若设置为-1,将自动根据情况调整Word: false # 是否为CNN模型,这里在创建项目的时候通过参数控制,不要自己修改
System:Allow_Ext: [jpg, jpeg, png, bmp] # 支持的图片后缀,不满足的图片将会被自动忽略GPU: true # 是否启用GPU去训练,使用GPU训练需要参考步骤一安装好环境GPU_ID: 0 # GPU设备号,0为第一张显卡Path: '' # 数据集根目录,在缓存图片步骤会自动生成,不需要自己改,除非数据集地址改了Project: test # 项目名称 也就是{project_name}Val: 0.03 # 验证集的数据量比例,0.03就是3%,在缓存数据时,会自动选则3%的图片用作训练过程中的数据验证,修改本值之后需要重新缓存数据
Train:BATCH_SIZE: 32 # 训练时每一个batch_size的大小,主要取决于你的显存或内存大小,可以根据自己的情况,多测试,一般为16的倍数,如16,32,64,128CNN: {NAME: ddddocr} # 特征提取的模型,目前支持的值为ddddocr,effnetv2_l,effnetv2_m,effnetv2_xl,effnetv2_s,mobilenetv2,mobilenetv3_s,mobilenetv3_lDROPOUT: 0.3 # 非专业人员不要动LR: 0.01 # 初始学习率OPTIMIZER: SGD # 优化器,不要动SAVE_CHECKPOINTS_STEP: 2000 # 每多少step保存一次模型TARGET: {Accuracy: 0.97, Cost: 0.05, Epoch: 20} # 训练结束的目标,同时满足时自动结束训练并保存onnx模型,Accuracy为需要满足的最小准确率,Cost为需要满足的最小损失,Epoch为需要满足的最小训练轮数TEST_BATCH_SIZE: 32 # 测试时每一个batch_size的大小,主要取决于你的显存或内存大小,可以根据自己的情况,多测试,一般为16的倍数,如16,32,64,128TEST_STEP: 1000 # 每多少step进行一次测试
4.训练或者恢复训练:python app.py train charprj
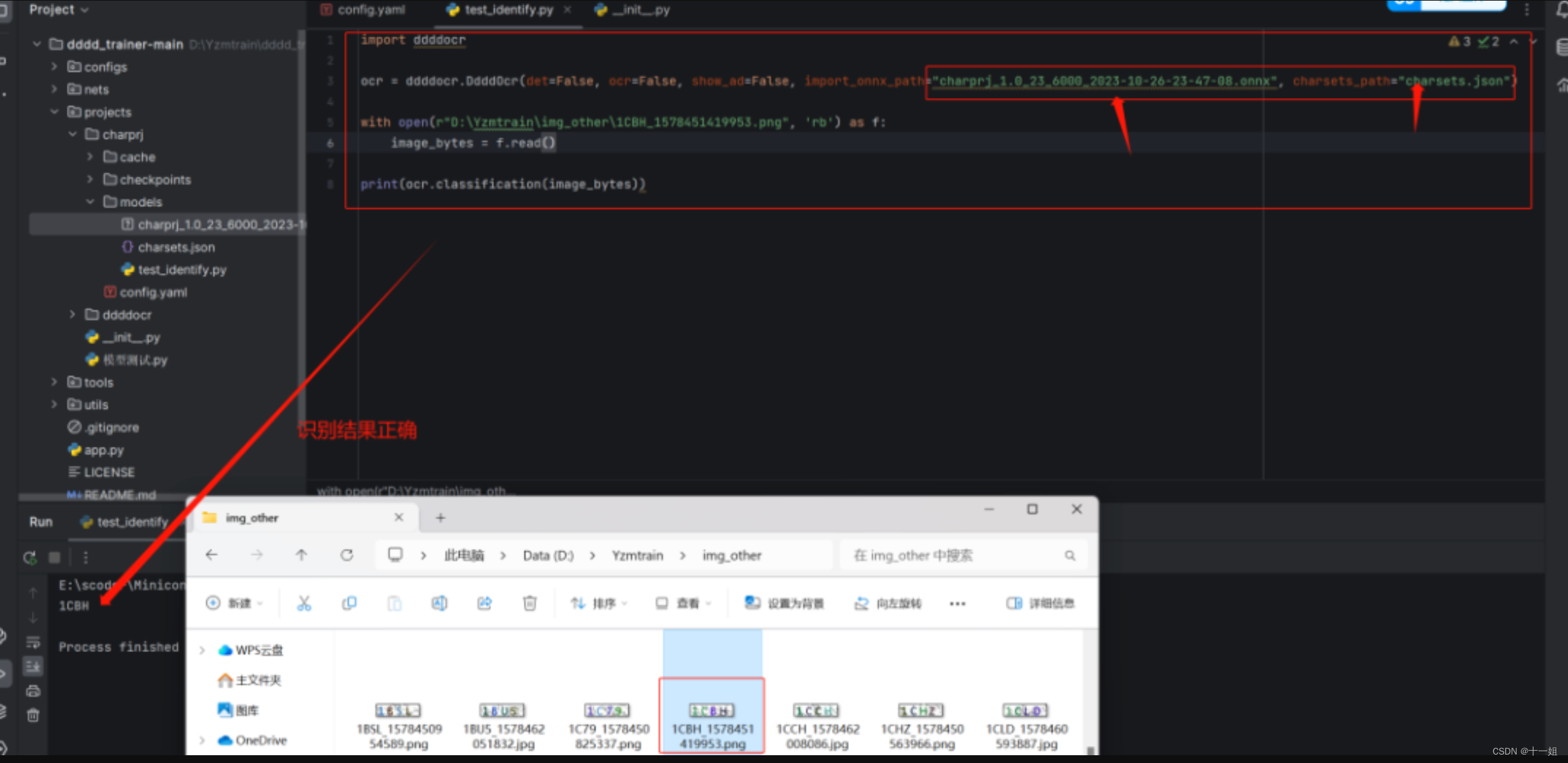
import ddddocrocr = ddddocr.DdddOcr(det=False, ocr=False, show_ad=False, import_onnx_path="charprj_1.0_23_6000_2023-10-26-23-47-08.onnx", charsets_path="charsets.json")with open(r"D:\Yzmtrain\img_other\1CBH_1578451419953.png", 'rb') as f:image_bytes = f.read()print(ocr.classification(image_bytes))
三、ocr_api_server服务搭建
1.服务搭建详细内容看这个吧,本文不介绍https://github.com/sml2h3/ocr_api_server
2、更多内容见训练验证码合集