一、简介
使用PyTorch实现的生成对抗网络(GAN)模型,包括编码器(Encoder)、解码器(Decoder)、生成器(ResnetGenerator)和判别器(Discriminator)。其中,编码器和解码器用于将输入图像进行编码和解码,生成器用于生成新的图像,判别器用于判断输入图像是真实的还是生成的。在训练过程中,生成器和判别器分别使用不同的损失函数进行优化。
二、相关技术
2.1数据准备
image_paths = sorted([str(p) for p in glob('../input/celebahq-resized-256x256/celeba_hq_256' + '/*.jpg')])# 定义数据预处理的transforms
image_size = 128# 数据预处理的transforms,将图像大小调整为image_size,并进行标准化
transforms = T.Compose([T.Resize((image_size, image_size), Image.BICUBIC),T.ToTensor(),T.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)) # to scale [-1,1] with tanh activation
])inverse_transforms = T.Compose([T.Normalize(-1, 2),T.ToPILImage()
])# 划分训练集、验证集和测试集
train, valid = train_test_split(image_paths, test_size=5000, shuffle=True, random_state=seed)
valid, test = train_test_split(valid, test_size=1000, shuffle=True, random_state=seed)
# 输出数据集长度
print(f'Train size: {len(train)}, validation size: {len(valid)}, test size: {len(test)}.')
2.2超参数的设置
配置了批次、学习率、迭代、遮盖图像的大小、指定GPU等等
epochs = 30
batch_size = 16
lr = 8e-5
mask_size = 64
path = r'painting_model.pth'
b1 = 0.5
b2 = 0.999
patch_h, patch_w = int(mask_size / 2 ** 3), int(mask_size / 2 ** 3)
patch = (1, patch_h, patch_w)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
2.3创建数据集
#创建数据集
其中apply_center_mask: 将掩码应用于图像的中心部分,遮挡中心部分。该方法接受一个图像作为输入,并返回应用了掩码的图像和掩码区域的索引。
apply_random_mask(self, image): 将掩码随机应用于图像的某个区域。该方法接受一个图像作为输入,并返回应用了掩码的图像和被遮挡的部分。
class CelebaDataset(Dataset):def __init__(self, images_paths, transforms=transforms, train=True):self.images_paths = images_pathsself.transforms = transformsself.train = traindef __len__(self):return len(self.images_paths)def apply_center_mask(self, image):# 将mask应用于图像的中心部分//遮挡中心部分idx = (image_size - mask_size) // 2masked_image = image.clone()masked_image[:, idx:idx+mask_size, idx:idx+mask_size] = 1masked_part = image[:, idx:idx+mask_size, idx:idx+mask_size]return masked_image, idxdef apply_random_mask(self, image):# 将mask随机应用于图像的某个区域y1, x1 = np.random.randint(0, image_size-mask_size, 2)y2, x2 = y1 + mask_size, x1 + mask_sizemasked_part = image[:, y1:y2, x1:x2]masked_image = image.clone()masked_image[:, y1:y2, x1:x2] = 1return masked_image, masked_partdef __getitem__(self, ix):path = self.images_paths[ix]image = Image.open(path)image = self.transforms(image)if self.train:masked_image, masked_part = self.apply_random_mask(image)else:masked_image, masked_part = self.apply_center_mask(image)return image, masked_image, masked_partdef collate_fn(self, batch):images, masked_images, masked_parts = list(zip(*batch))images, masked_images, masked_parts = [[tensor[None].to(device) for tensor in ims] for ims in [images, masked_images, masked_parts]]images, masked_images, masked_parts = [torch.cat(ims) for ims in [images, masked_images, masked_parts]]return images, masked_images, masked_parts# 创建数据集和数据加载器
train_dataset = CelebaDataset(train)
valid_dataset = CelebaDataset(valid, train=True)train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=train_dataset.collate_fn, drop_last=True)
valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False, collate_fn=valid_dataset.collate_fn, drop_last=True)
2.4 构建神经网络
2.4.1定义初始化函数
定义了初始化函数init_weights,用于初始化卷积层、反卷积层和批归一化层的权重。同时,还定义梯度更新函数set_params,用于设置模型参数是否需要梯度更新。
def init_weights(m):if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):nn.init.normal_(m.weight, 0, 0.02)if m.bias is not None:nn.init.zeros_(m.bias)if isinstance(m, nn.BatchNorm2d):nn.init.normal_(m.weight, 1, 0.02)nn.init.zeros_(m.bias)def set_params(model, unfreeze):for param in model.parameters():param.requires_grad = unfreeze
2.4.2 #定义生成器网络
ResDown模块用于下采样操作,它包含三个卷积层和一个激活函数。输入x经过卷积和批归一化操作得到特征图x,然后通过上采样得到特征图skip。最后将特征图x与特征图skip相加,并经过激活函数得到输出特征图。
ResUp模块用于上采样操作,它也包含三个卷积层和一个激活函数。输入x经过上采样得到特征图x,然后通过卷积和批归一化操作得到特征图x。接着,输入x经过上采样和卷积和批归一化操作得到特征图skip。最后将特征图x与特征图skip相加,并经过激活函数得到输出特征图。
这两个模块可以用于构建生成对抗网络(GAN)中的生成器部分,用于生成图像或进行图像转换任务。
class ResDown(nn.Module):def __init__(self, channel_in, channel_out, scale=2):super(ResDown, self).__init__()self.conv1 = nn.Conv2d(channel_in, channel_out//2, 3, 1, 1)self.batch_norm1 = nn.BatchNorm2d(channel_out//2, 0.8)self.conv2 = nn.Conv2d(channel_out//2, channel_out, 3, scale, 1)self.batch_norm2 = nn.BatchNorm2d(channel_out, 0.8)self.conv3 = nn.Conv2d(channel_in, channel_out, 3, scale, 1)self.activation = nn.LeakyReLU(0.2) #激活层def forward(self, x):skip = self.conv3(x)x = self.conv1(x)x = self.batch_norm1(x)x = self.activation(x)x = self.conv2(x)x = self.batch_norm2(x)x = self.activation(x + skip)return xclass ResUp(nn.Module):def __init__(self, channel_in, channel_out, scale=2):super(ResUp, self).__init__()self.conv1 = nn.Conv2d(channel_in, channel_out//2, 3, 1, 1)self.batch_norm1 = nn.BatchNorm2d(channel_out//2, 0.8)self.conv2 = nn.Conv2d(channel_out//2, channel_out, 3, 1, 1)self.batch_norm2 = nn.BatchNorm2d(channel_out, 0.8)self.upscale = nn.Upsample(scale_factor=scale, mode="nearest") #上采样层self.conv3 = nn.Conv2d(channel_in, channel_out, 3, 1, 1)self.activation = nn.LeakyReLU(0.2)def forward(self, x):skip = self.conv3(self.upscale(x))x = self.conv1(x)x = self.batch_norm1(x)x = self.activation(x)x = self.conv2(self.upscale(x))x = self.batch_norm2(x)x = self.activation(x + skip)return x2.4.3定义编码器和解码器
编码器:捕捉了输入数据的核心特征和结构。
解码器接收编码器的输出作为输入,并通过一系列操作将其转换回原始数据的形式,或者转换成另一种形式的数据。
class Encoder(nn.Module): #编码器def __init__(self, channels, ch=64, z=512):super(Encoder, self).__init__()self.conv1 = ResDown(channels, ch) self.conv2 = ResDown(ch, 2*ch) self.conv3 = ResDown(2*ch, 4*ch) self.conv4 = ResDown(4*ch, 8*ch) self.conv5 = ResDown(8*ch, 8*ch) self.conv_mu = nn.Conv2d(8*ch, z, 2, 2) #卷积层self.conv_log_var = nn.Conv2d(8*ch, z, 2, 2) def sample(self, mu, log_var):std = torch.exp(0.5*log_var)eps = torch.randn_like(std)return mu + eps*stddef forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = self.conv4(x)x = self.conv5(x)mu = self.conv_mu(x)log_var = self.conv_log_var(x)x = self.sample(mu, log_var)return x, mu, log_varclass Decoder(nn.Module): #解码器def __init__(self, channels, ch=64, z=512):super(Decoder, self).__init__()self.conv1 = ResUp(z, ch*8)self.conv2 = ResUp(ch*8, ch*4)self.conv3 = ResUp(ch*4, ch*2)self.conv4 = ResUp(ch*2, ch)self.conv5 = ResUp(ch, ch//2)self.conv6 = nn.Conv2d(ch//2, channels, 3, 1, 1) #卷积池self.activation = nn.Tanh()def forward(self, x): #传播的是解码器解码后的特征图x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = self.conv4(x)x = self.conv5(x)x = self.conv6(x)return self.activation(x)
2.4.4定义生成器模型
#生成器模型
class ResnetGenerator(nn.Module):def __init__(self, channel_in=3, ch=64, z=512):super(ResnetGenerator, self).__init__()self.encoder = Encoder(channel_in, ch=ch, z=z)self.decoder = Decoder(channel_in, ch=ch, z=z)def forward(self, x):#传播编码器编码后的特征向量encoding, mu, log_var = self.encoder(x)recon = self.decoder(encoding)return recon, mu, log_var
2.4.5定义判别器模型
判别器模型用于图像生成任务中的判别器部分,用于区分真实图像和生成图像。
#判别器模型
class Discriminator(nn.Module):def __init__(self, channels=3):super(Discriminator, self).__init__()def discriminator_block(in_filters, out_filters, stride, normalize, dropout, spectral):if spectral: #封装稳定训练layers = [nn.utils.spectral_norm(nn.Conv2d(in_filters, out_filters, 3, stride, 1), n_power_iterations=2)]else:layers = [nn.Conv2d(in_filters, out_filters, 3, stride, 1)]if normalize: #归一化layers.append(nn.InstanceNorm2d(out_filters))layers.append(nn.LeakyReLU(0.2, inplace=True))if dropout: #防止过拟合layers.append(nn.Dropout(p=0.5))return layerslayers = []in_filters = channelsfor out_filters, stride, normalize, dropout, spectral in [(64, 2, False, 0, 0), (128, 2, True, 0, 0), (256, 2, True, 0, 0), (512, 1, True, 0, 0)]:layers.extend(discriminator_block(in_filters, out_filters, stride, normalize, dropout, spectral))in_filters = out_filterslayers.append(nn.Conv2d(out_filters, 1, 3, 1, 1))self.model = nn.Sequential(*layers)def forward(self, img): return self.model(img)
2.5可视化生成器和判别器模型
2.5.1可视化生成器模型
generator = ResnetGenerator().apply(init_weights).to(device)
summary(generator, (3, 128, 128))
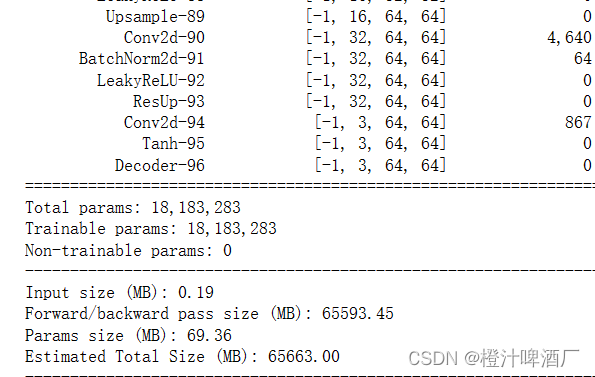
2.5.2可视化判别器模型
discriminator = Discriminator().apply(init_weights).to(device)
summary(discriminator, (3, 64, 64))
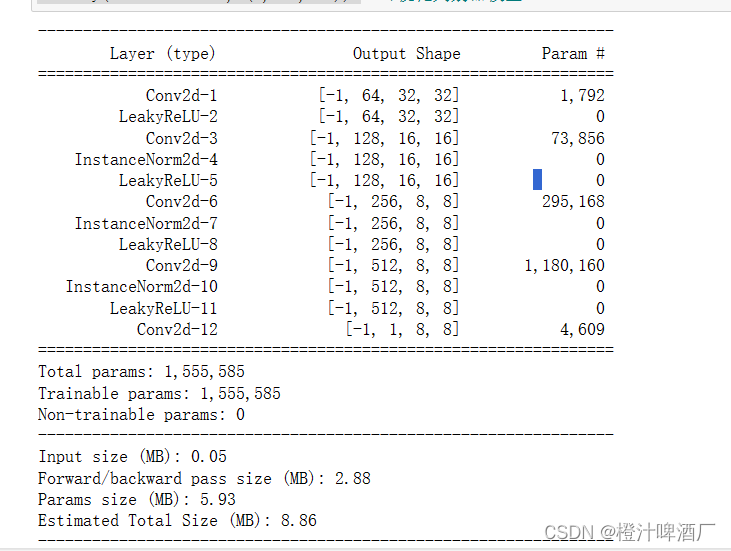
2.6定义对抗损失函数和优化器
class KLDLoss(nn.Module):def forward(self, mu, logvar, beta=1.0):kld = -0.5 * torch.sum(1 + logvar - torch.pow(mu, 2) - torch.exp(logvar))return beta * kldreconstruction_loss = nn.functional.mse_loss
kld_loss = KLDLoss()
kld_criterion = lambda x, y, mu, logvar: reconstruction_loss(y, x, reduction="sum") + kld_loss(mu, logvar, beta=0.1)
adversarial_loss = nn.MSELoss() # 对抗损失,使用均方误差损失代替二进制交叉熵损失# 优化器
optimizer_G = torch.optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2)) # 生成器优化器
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2)) # 判别器优化器
2.7定义训练模型
def train_one_batch(batch, generator, discriminator, criterion_adv, criterion_pix, optimizer_G, optimizer_D):generator.train()discriminator.train()images, masked_images, masked_parts = batchreal = torch.FloatTensor(batch_size, *patch).fill_(1.0).requires_grad_(False).to(device) # 真实样本标签fake = torch.FloatTensor(batch_size, *patch).fill_(0.0).requires_grad_(False).to(device) # 生成样本标签set_params(discriminator, False) optimizer_G.zero_grad() gen_parts, mu, logvar = generator(masked_images) gan_loss = criterion_adv(discriminator(gen_parts), real) pix_loss = criterion_pix(masked_parts, gen_parts, mu, logvar) loss_g = 0.001 * gan_loss + 0.999 * pix_loss loss_g.backward() optimizer_G.step() set_params(discriminator, True) optimizer_D.zero_grad() real_loss = criterion_adv(discriminator(masked_parts), real) # 真实样本损失fake_loss = criterion_adv(discriminator(gen_parts.detach()), fake) # 生成样本损失loss_d = (real_loss + fake_loss) / 2 loss_d.backward()optimizer_D.step() return loss_g.item(), loss_d.item()
2.8 定义验证模型
def validate_one_batch(batch, generator, discriminator, criterion_adv, criterion_pix):generator.eval()discriminator.eval()images, masked_images, masked_parts = batchreal = torch.FloatTensor(batch_size, *patch).fill_(1.0).requires_grad_(False).to(device) # 真实样本标签fake = torch.FloatTensor(batch_size, *patch).fill_(0.0).requires_grad_(False).to(device) # 生成样本标签gen_parts, mu, logvar = generator(masked_images)gan_loss = criterion_adv(discriminator(gen_parts), real)pix_loss = criterion_pix(masked_parts, gen_parts, mu, logvar) loss_g = 0.001 * gan_loss + 0.999 * pix_lossreal_loss = criterion_adv(discriminator(masked_parts), real)fake_loss = criterion_adv(discriminator(gen_parts.detach()), fake)loss_d = (real_loss + fake_loss) / 2 ``## 2.9测试模型```powershell
@torch.no_grad()
def test_plot(test, generator, scale=1):idx = np.random.randint(len(test))random_path = test[idx]image = Image.open(random_path)image = transforms(image)masked_image, idx = train_dataset.apply_center_mask(image)generator.eval()gen_part = generator(masked_image.unsqueeze(0).to(device))[0].squeeze(0).cpu().detach()gen_image = masked_image.clone()gen_image[:, idx:idx+mask_size, idx:idx+mask_size] = gen_part# scale [-1,1] or [0,1]if scale:run_transforms = inverse_transformselse:run_transforms = T.ToPILImage()image = run_transforms(image)masked_image = run_transforms(masked_image)gen_image = run_transforms(gen_image)#生成对比图片plt.figure(figsize=(10, 5))plt.subplot(131)plt.title('Original Image')plt.imshow(image)plt.subplot(132)plt.title('Masked Image')plt.imshow(masked_image)plt.subplot(133)plt.title('Inpainted Image')plt.imshow(gen_image)plt.tight_layout()plt.show()plt.pause(0.01)
2.10 训练
#初始化损失
train_d_losses, valid_d_losses = [], []
train_g_losses, valid_g_losses = [], []
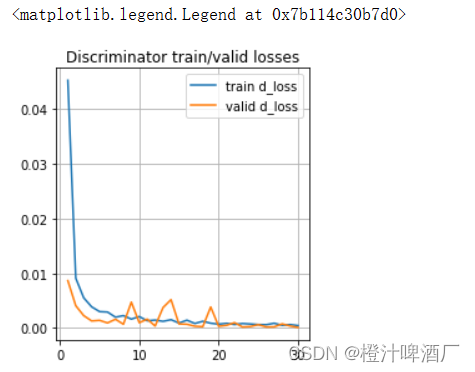
for epoch in range(epochs):print(f'Epoch {epoch+1}/{epochs}')# 训练集迭代tq_bar = tqdm(train_dataloader, total=len(train_dataloader), desc=f'Train step {epoch+1}')epoch_d_losses, epoch_g_losses = [], []for _, batch in enumerate(tq_bar):g_loss, d_loss = train_one_batch(batch, generator, discriminator, adversarial_loss, kld_criterion, optimizer_G, optimizer_D)epoch_g_losses.append(g_loss)epoch_d_losses.append(d_loss)tq_bar.set_postfix(g_loss=np.mean(epoch_g_losses), d_loss=np.mean(epoch_d_losses))train_d_losses.append(np.mean(epoch_d_losses))train_g_losses.append(np.mean(epoch_g_losses))# 验证集迭代tq_bar = tqdm(valid_dataloader, total=len(valid_dataloader), desc=f'Validation step {epoch+1}')epoch_d_losses, epoch_g_losses = [], []for _, batch in enumerate(tq_bar):g_loss, d_loss = validate_one_batch(batch, generator, discriminator, adversarial_loss, kld_criterion)epoch_d_losses.append(d_loss)epoch_g_losses.append(g_loss)tq_bar.set_postfix(g_loss=np.mean(epoch_g_losses), d_loss=np.mean(epoch_d_losses))valid_d_losses.append(np.mean(epoch_d_losses))valid_g_losses.append(np.mean(epoch_g_losses))if (epoch+1) % 2 == 0 or (epoch+1) == epochs:test_plot(test, generator)checkpoint = {'discriminator': discriminator,'generator': generator,}torch.save(checkpoint, path)效果图:训练的次数还是不够,有感兴趣的小伙伴可以跑一下