成功者总是善于发现 “可学之处”,执着精进;失败者总是善于发现 “不可学之处”,怨天尤人。
郑重说明:本文适合对游戏开发感兴趣的小白初学者,本人力图将事物用简单的语言表达清楚,但水平有限,能力一般,文章如有错漏之处,还望批评指正。
最近,人工智能应用chatGPT火遍全球。今天,我想开一个小专题,谈一谈游戏AI。但此AI非彼AI,形式和机制差别巨大,相同的是,两者都创造了价值。
AI,全称为 Artificial Intelligence,是任何可以让机器模拟人类行为的能力。那么,在游戏开发中,是怎么让机器模拟人类的行为的?
一、游戏AI的应用
在游戏领域,AI的应用范围大致应用在以下一些方面:

NPC决策。我们在玩游戏的过程中,经常会与大量的NPC打交道,真实生动的NPC带来的体验让人心情愉悦。NPC在与游戏玩家交互的过程中,如何模拟人类的反应来做决策至关重要。
移动与导航。地图游戏中,移动成为必须。有大量的算法来研究如何智能地模拟人类的移动行为。
博弈AI。棋牌或者即时对战类游戏中,存在大量的博弈。近些年知名的AlphaGo就是其中的典型代表。
游戏内容生成。在引入工业化生产的现代社会,游戏内容也是一类快速消耗的产品。如何快速有效地生产丰富多彩的游戏内容,也引起了开发商的关注。游戏AI也能辅助开发者生产,如地图生成等。
数值平衡性。一些游戏的战斗中,往往涉及大量的技能、效果,互相作用带来了无穷的结果。因此用AI来辅助我们做数值平衡性的跑测,力求公平,避免产生致命的问题也很重要。
二、NPC决策:sense-think-act 模型
2.1 决策模型
设想一下,你设计的一款游戏里有一个NPC怪物,我们叫他小木吧:

在游戏开始后,小木应该怎么做决策,来决定接下来做什么呢?
对游戏有过了解的同学应该清楚,游戏内状态的更新和变化都是通过一个叫做循环的东西来控制的。小木身处这样一个循环的世界,要做的也就是自身不停的循环。
在每一次的循环中,小木需要经历三个阶段,我们称为 sense-think-act 循环模型:
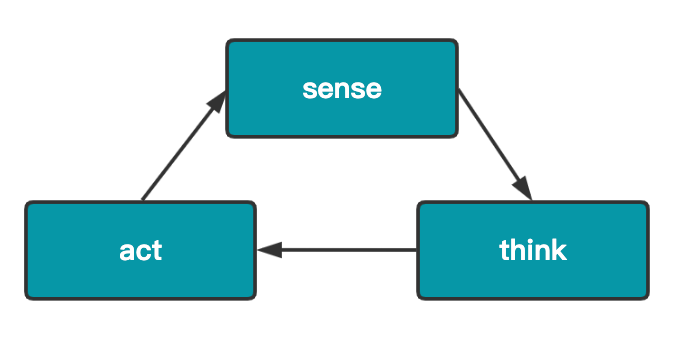
Sense: 在这个阶段,小木需要探测周围世界中的信息,或者被告知周围世界中发生了什么事情。这些信息或者事情会影响它的行为。例如,有危险正在靠近,地上有物品可以拾取,或者受到了攻击。
Think: 小木需要做出决策,对上述的Sense做出适当的反应,比如应该战斗还是逃跑,亦或是拾取物品。
Act: 小木需要以上述决策作为目标,来具体实施。比如移动到某个低点,释放技能,或者做出拾取的动作。
每一次的循环中,都依次执行这个 sense-think-act模型,如此无限往复。
2.2 与通用AI决策的区别
需要注意的是,游戏内的AI 并不一定要做 “最优” 的决策,而是要有趣或者富有挑战性,要表现的很逼真,拟人,最优解并不一定是设计者需要的。所以类似 AlphaGo 这种超级智能的AI 并不符合游戏中实际的需要。
另外,最优解往往需要大量的训练或者计算,并不能满足游戏中大量AI 对实时性和性能的要求。所以 GameAI 和 实际机器学习中的 AI 还不太一样。
2.3 有关 Sense
很多游戏引擎中,会集成主动sense模块。如 UE4 中的感知(perception):
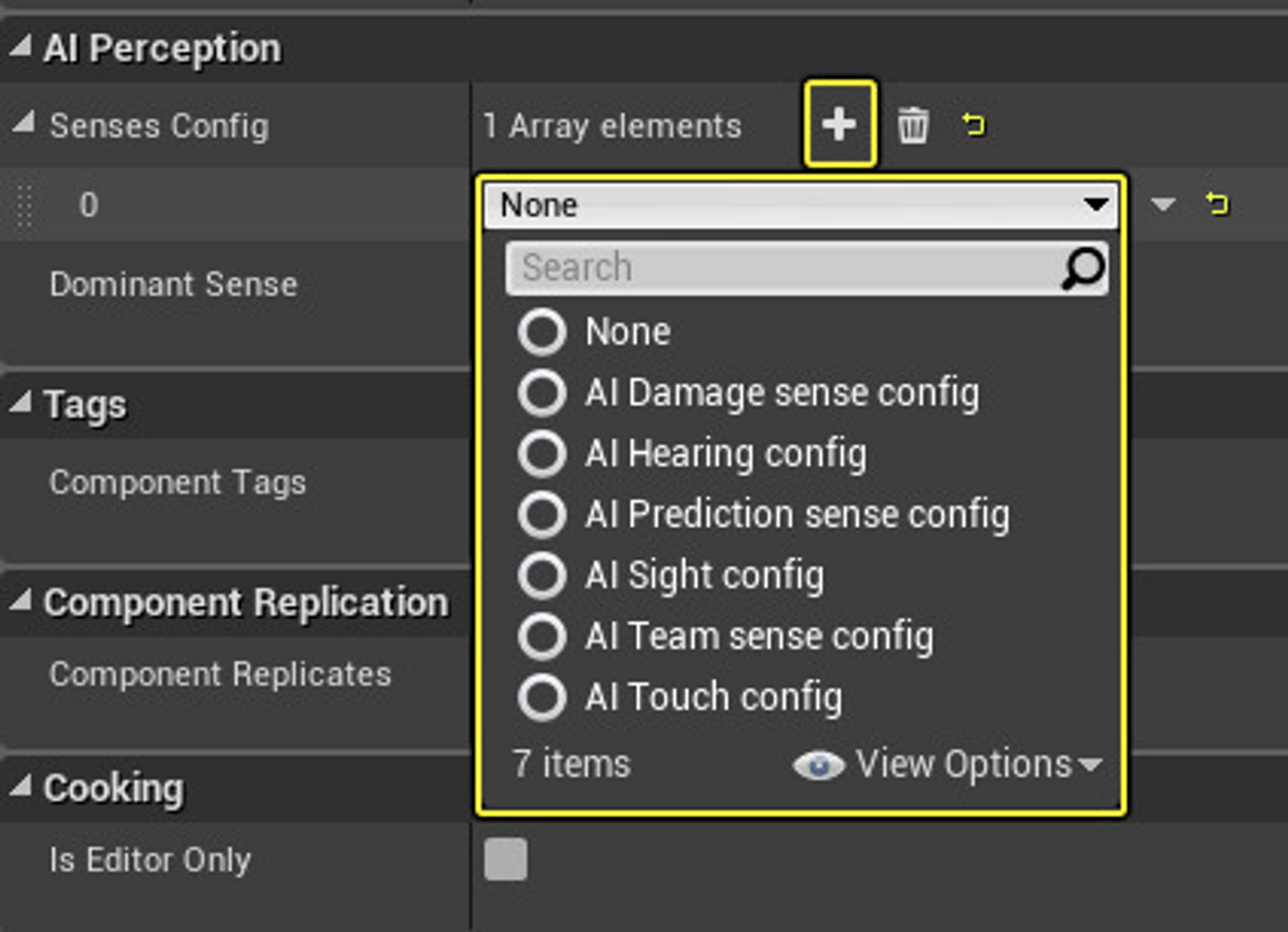
从图中,我们可以看到很多具体的感知:
听觉
视觉
触觉
团队感知
...
在游戏中除了每一次思考时主动感知(sense)之外,往往还有另外一类感知:
对事件做出反应(responding to events)
在每一次的循环中,可以主动感知,每一次的感知间隔(循环间隔)可以是一帧,或者一次思考间隔的时间,如0.5秒。
正是因为有感知间隔,NPC决策往往不够实时。因此,还需要有对被动感知的处理。例如,NPC收到队友的呼救信息,受到攻击等等。通过对事件做出实时反应,NPC的决策才会更真实。
三、AI决策模型的实现
3.1 发展历程
对于决策模型 sense-think-act,其实现方式经历了一系列的演变。大致有以下一些方式:

3.2 基础决策
hardcode
如 hardcode 在代码中一个例子:球拍击球的小游戏AI:
every frame/update while the game is running:if the ball is to the left of the paddle:move the paddle leftelse if the ball is to the right of the paddle:move the paddle right每一帧的循环中,对照 sense-think-act 模型:
sense 就是两个 if 条件。AI 在 if 中主动从 game 中拉取需要的数据:球是在球拍的左边还是右边。
think 也体现这两个 if 条件中,体现了决策分支,只不过是 hardcode 的方式,这几个分支是互斥的关系。
act 就是 move 的操作,会涉及具体的 move 实现,如设置方向和速度等。
配置表
hardcode的方式过于死板了,调整起来非常不方便。游戏中成千上万的AI如果都使用hardcode的方式来实现,基本是无法维护的。
如果使用数据驱动的方式,如配置表驱动,则要更方便,参数可以灵活调整,但是具体的决策项还是要提前通过代码实现好。
Script 脚本
配置的方式毕竟还是有不少限制。此时,我们可以使用脚本语言如 Lua,其可以实现更为强大的功能。很重要的一点是,它和配置表一样也可以热更新。这对开发调试,以及在线修复或调整AI的逻辑错误等比较重要。
3.3 高级决策
在基础决策实现的基础上,又发展出了一些更高级的决策方式,如状态机、行为树、Utility权重决策等,这一部分我们后面再继续阐述。
三、移动与导航
在前面的文章中,我们说明的是AI应用中比较典型的NPC决策模型。
而这里我们要讨论的另一大类,移动与导航,其实是上述决策模型中的 act,因为它非常常用,所以可以作为典型单独讨论。
移动会涉及到速度(velocity)的设置以及方向。在 think 环节,我们可以设置这个 velocity 或者设置其目的地或者追击的 target 等,然后在 act 环节做具体的 move。
导航在游戏中更为常见,涉及到一些经典的寻路算法如:
A* 算法
JPS 算法
NavMesh算法
这些算法如果要应用到地图导航中,还需要涉及地图如何表达的问题。这些我们也会在之后的系列文章中讨论。
关于AI在博弈对战、游戏内容的生成以及数值平衡性的使用,本人经验也不多,以后有研究成果了再单独分享。
有关游戏AI的综述我们就说到这里。
【参考资料】
The Total Beginner's Guide to Game AI
AI分享站