一、说明
随着最近开发的库,执行深度学习分析变得更加容易。其中一个库是拥抱脸。Hugging Face 是一个平台,可为 NLP 任务(如文本分类、情感分析等)提供预先训练的语言模型。
本博客将引导您了解如何使用拥抱面部管道执行 NLP 任务。以下是我们将在此博客中讨论的主题。
- 什么是自然语言处理?
- 什么是变形金刚?
- 使用变形金刚执行各种 NLP 任务。
我们将介绍的 NLP 任务是文本分类、命名实体识别、问答和文本生成。
让我们潜入!
二、什么是自然语言处理?
NLP是人工智能的一个子领域,允许计算机解释,操纵和理解人类语言。NLP 任务的目标是分析文本和语音数据,如电子邮件、社交媒体新闻源、视频、音频等。使用 NLP 技术,您可以处理各种任务,例如文本分类、生成文本内容、从文本中提取答案等。
NLP不仅仅处理书面文本。它还克服了语音识别和计算机视觉中的复杂挑战,例如创建声音样本的成绩单或图像的描述。
很酷,我们在本节中了解了 NLP 是什么。让我们继续看看变形金刚库是什么。
三、什么是transformer库?
Transformers 是一个库,提供 API 和工具,可轻松下载和训练最先进的预训练模型。
你可能会问什么是预训练模型。让我解释一下。预训练模型实际上是一个保存的预训练网络,该网络以前在大型数据集上训练过。使用预先训练的模型,可以节省从头开始训练模型所需的时间和资源。
很好,我们看了变形金刚库是什么。让我们执行一些任务来展示如何使用这个库。
3.1 transformer应用
变压器具有处理各种NLP任务的强大功能。处理 NLP 任务的最简单方法是使用该函数。它将模型与其必要的预处理和后处理步骤连接起来。这允许您直接输入任何文本并获得答案。pipeline
要使用变压器,您需要使用以下命令安装它:
pip install -q transformers
为了展示如何使用该功能,让我们从转换器导入它。pipeline
from transformers import pipeline很酷,我们现在可以使用这个对象执行 NLP 任务。让我们从情绪分析开始。
3.2 情绪分析
情绪分析是最常用的NLP任务之一。它是检测文本中积极或消极情绪的过程。为了演示如何执行此任务,让我们创建一个文本。
text = "This movie is beautiful. I would like to watch this movie again."太棒了,我们现在有一条短信。让我们找出这段文字的情绪。为此,首先,我们通过调用管道函数来实例化管道。接下来,我们给出我们感兴趣的任务的名称。
classifier = pipeline("sentiment-analysis")很好,我们已经准备好使用此对象分析我们的文本。
classifier(text)# Output:
[{'label': 'POSITIVE', 'score': 0.9998679161071777}]如您所见,我们的管道预测了标签并显示了分数。标签为正,得分为 0.99。事实证明,模型非常有信心文本具有积极的情绪。太好了,我们已经完成了情绪分析。这很简单,对吧?
让我们退后一步,想想发生了什么。此管道首先选择了一个预训练模型,该模型已针对情绪分析进行了微调。接下来,在创建分类器对象时,下载模型。请注意,将某些文本传递到管道时,会将文本预处理为模型可以理解的格式。
在此分析中,我们使用管道进行情绪分析。您还可以将其用于其他任务。最近开发的一些管道是情绪分析;我们刚刚学会了如何执行这个管道、摘要、命名实体识别、问答、文本生成、翻译、特征提取、零镜头分类等。让我们来看看其中的一些。我们现在要讨论的管道是零命中分类。
3.3 零镜头分类
假设您要对未标记的文本进行分类。这就是零镜头分类管道的用武之地。它可以帮助您标记文本。因此,您不必依赖预训练模型的标签。让我们看一下如何使用这个管道。首先,我们将通过调用管道函数进行实例化。
classifier = pipeline("zero-shot-classification")现在让我们创建一个要分类的文本。
text = "This is a tutorial about Hugging Face."让我们定义候选标签。
candidate_labels = ["tech", "education", "business"]很酷,我们创建了文本和标签。现在,让我们预测一下这句话的标签。为此,我们将使用分类器对象。
classifier(text, candidate_labels)# Output:
{'sequence': 'This is a tutorial about Hugging Face','labels': ['education', 'tech', 'business'],'scores': [0.8693577647209167, 0.11372026801109314, 0.016921941190958023]}如您所见,文本是关于教育的。在这里,我们没有根据数据微调模型。我们的管道直接返回概率分数。这就是为什么这个管道被称为零镜头。让我们继续看一下文本生成任务。
3.4 文本生成
像 ChatGPT 这样的工具非常适合生成文本,但有时您可能希望生成有关主题的文本。文本生成的目标是生成有意义的句子。我们的模型会收到提示并自动完成它。让我们看看如何执行管道。首先,我们使用文本生成来实例化管道。
generator = pipeline("text-generation")让我们继续创建一个提示。
prompt= "This tutorial will walk you through how to"现在,让我们将此提示传递给我们的对象。
generator(prompt)# Output:
[{'generated_text': 'This tutorial will walk you through how to setup a Python script to automatically find your favourite website using Python and JavaScript so you can build a web site that'}]如您所见,根据我们的句子生成了一个文本。请注意,此文本是随机生成的。因此,如果您没有获得与此处相同的结果,这是正常的。
在此示例中,我们使用了默认模型。您还可以从中心选择特定型号。要为您的任务找到合适的模型,请转到模型中心并单击左侧的相应标签。
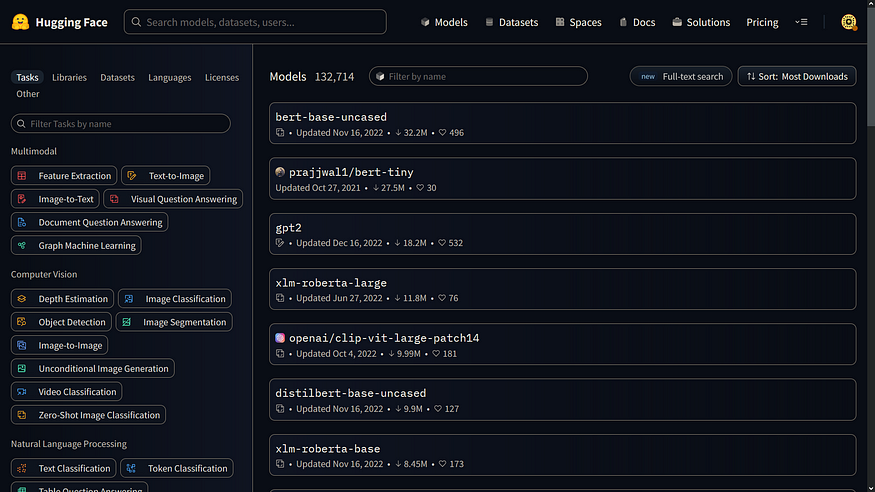
模特在拥抱脸
在这里,您可以看到任务支持的模型。很酷,让我们尝试一个模型。首先,我们将创建一个管道。让我们将任务和模型名称传递给它。
generator = pipeline("text-generation", model="distilgpt2")很酷,我们实例化了一个对象。让我们使用前面的提示创建一个最大长度为 30 的文本。
generator(prompt, max_length = 30)如您所见,使用我们确定的模型创建了一个文本。让我们继续看一下命名实体识别任务。
3.5 命名实体识别 (NER)
NER是最受欢迎的数据预处理任务之一。在 NLP 中,产品、地点和人员等现实世界的对象称为命名实体,从文本中提取它们称为命名实体识别。让我们通过一个示例来展示此任务是如何完成的。首先,让我们从管道创建一个对象。
ner = pipeline("ner", grouped_entities=True)在这里,我们通过了将句子的各个部分重新组合在一起。例如,我们希望将“Google”和“Cloud”分组为一个组织。现在让我们创建一个例句。grouped_entities=True
"text = My name is Tirendaz and I love working with Hugging Face for my NLP task."现在,让我们将此文本传递给我们的对象。
ner(text)# Output:
[{'entity_group': 'PER','score': 0.99843466,'word': 'Tirendaz','start': 11,'end': 19},{'entity_group': 'ORG','score': 0.870751,'word': 'Google Cloud','start': 31,'end': 43},{'entity_group': 'LOC','score': 0.99855834,'word': 'Berlin','start': 47,'end': 53}]如您所见,我们的模型正确识别了文本中的实体。很好,让我们继续问答任务。
3.6 生成问答系统
在问答中,我们给模型一段称为上下文的文本和一个问题。模型根据文本回答问题。让我们用一个例子来说明这一点。首先,让我们从问答管道创建一个对象。
question_answerer = pipeline("question-answering")现在让我们使用这个对象。
question_answerer(question="Where do I live?",context="My name is Tirendaz and I live in Berlin",)# Output:
{'score': 0.7006925940513611, 'start': 31, 'end': 43, 'answer': 'Google Cloud'}如您所见,我们的管道从上下文中提取了信息。很酷,我们学会了如何使用管道执行各种 NLP 任务。您还可以将管道用于其他任务,例如摘要和翻译。
你可以在这里找到我在这个博客中使用的笔记本。
四、总结
变形金刚是拥抱脸中的一个库,提供API和工具。您可以使用此库执行 NLP 任务。最简单的方法是使用拥抱面孔管道。管道提供了一个易于使用的 API,可将模型与其必要的预处理和后处理步骤连接起来。因此,您可以使用管道对象轻松执行各种 NLP 任务。
参考资源
- 拥抱脸