参考:CLIP改进工作串讲(上)、CLIP改进工作串讲(下)、李沐精读系列、CLIP 改进工作串讲(上)笔记
由于是论文串讲,所以每个链接放在每一个小节里。
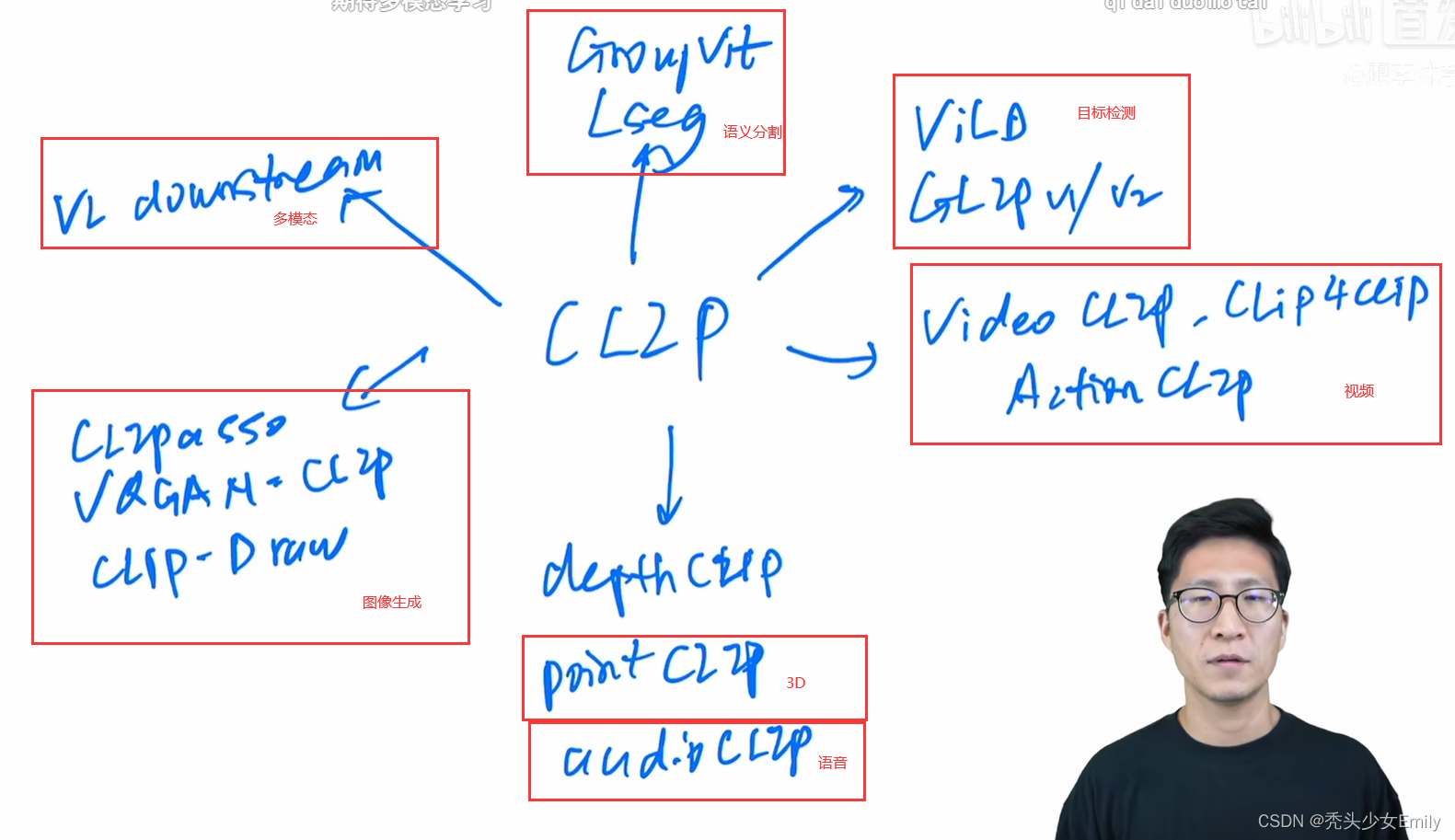
CLIP的应用如下:
回顾:
- CLIP:CLIP就是用对比学习的方式去训练一个视觉语言的多模态模型。
- 训练方式:给定一个图像文本对,图像通过图像编码器,文本通过文本编码器后得到一系列图像文本的特征。如下图,对角线蓝色部分为正样本,其他为负样本。利用简单的对比学习目标函数,在经过4亿的图像文本对上训练后,CLIP就获得了强大的性能。
- 推理:最大相似度的标签。

一、语义分割
1.1 LSeg
论文: Language-driven Semantic Segmentation
语义分割可以看做是像素级的分类。LSeg与 CLIP 实现 zero-shot 的方式类似,它通过类别 prompt 作为文本输入,然后计算相似度,也实现了zero-shot 语义分割。
LSeg的意义在于将文本的分支加入到传统的有监督分割的pipeline模型中,通过矩阵相乘将文本和图像结合起来了。训练时可以学到language aware(语言文本意识)的视觉特征,从而在最后推理的时候能使用文本prompt得到任意你想要的分割结果。
1.1.1 模型框架

从总的框架图来看,整体看来与CLIP模型非常相似,只是将单个的图像文本特征换成语义分割中逐像素的密集特征。
另外除了上方的文本编码器提取的文本特征,要与密集图像特征相乘来计算像素级的图文相似度之外,整个网络与传统的有监督网络完全一致。
现在来解释图中所出现的符号。
- 文本编码器提取
的文本特征,图像编码器提取
的密集图像特征,二者相乘得到
的特征,再经过Spatial Regularization Blocks上采样回原图尺寸。最后计算模型的输出与ground truth监督信号的交叉熵损失进行训练。
分别是类别 个数(可变)、通道数和特征图的高宽,C一般取512或者768。
- Text Encoder:直接用的是CLIP 文本编码器的模型和权重,并且训练、推理全程中都是冻结的。因为分割任务的数据集都比较小(10-20万),训练的话结果会不好。
- Images Encoder:DPT结构(使用了ViT进行有监督训练的语义分割模型,结构就是ViT+decoder),backbone可以是ResNet或者ViT。如果使用后者,其参数用的是Vit/DEit的预训练权重,直接使用CLIP的预训练权重效果不太好。
- Spatial Regularization Blocks :是本文提出的一个模块,如下图。在计算完像素级图文相似度后继续学习一些参数,可以进一步学习文本图像融合后的特征。模块由一些卷积和DW卷积组成(当加了两个模块时效果提升,加了四个模块后效果崩溃,作者未解释)

模型在 7 个分割数据集上进行训练,这些数据集都是由有标注的分割图组成,所以模型是以有监督的方式进行训练的(损失函数是交叉熵损失而非无监督的对比学习目标函数)。推理时,可以指定任意个数、任意内容的类别 prompt 来进行 zero-shot 的语义分割。
1.1.2 失败案例
下图,标签给定是toy,grass在嵌入空间中(embedding space),狗的视觉特征明显更接近“玩具”而不是“草”,并且没有其他标签可以解释视觉特征,所以狗被检测为toy。如果标签是face,grass,狗会被检测为face。

失败原因:用了CLIP,本质都是计算图像和文本特征之间的相似性,并不是真正在做分类,而是选择最接近的那个。
LSeg的特点:虽然画的框架图很像CLIP,也用了CLIP的Text Encoder。但是它的目标函数不是对比学习,也不是无监督的框架。LSeg其实并没有把文本当作监督信号来使用,还是依赖手工标注的segametation mask。
1.2 GroupViT
论文:GroupViT: Semantic Segmentation Emerges from Text Supervision
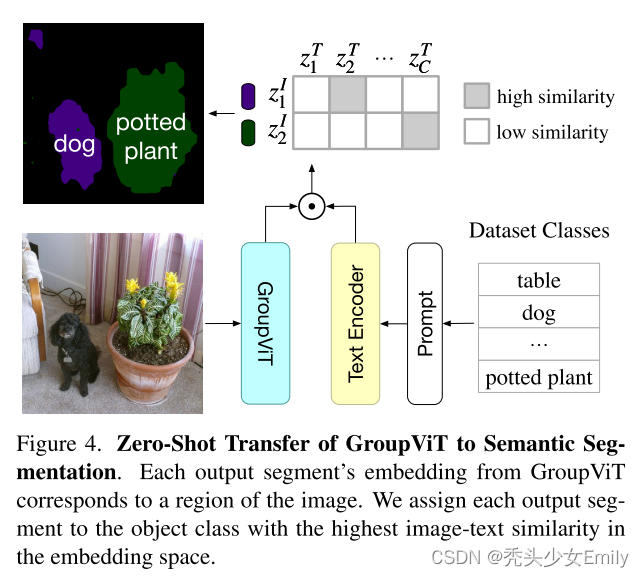
对比上一小节的LSeg,它就是利用文本当作监督信号。与CLIP类似,利用图像文本对进行无监督的训练,从而让模型进行简单的分割任务。
1.2.1 模型框架
GroupViT 的核心思想,是利用了之前视觉的无监督分割工作中的 grouping。简单说如果有一些聚类的中心点,从这些中心点开始发散,把周围相似的点逐渐扩散成一个group,最后这个group即相当于一个Segmentation mask(感觉类似DBSCAN),是一种自下而上的方式。
Group ViT的贡献就是在现有的ViT模型框架中加入计算单元Grouping Block,同时加入了可学习的Group Tokens。这样模型在初期学习的时候就能慢慢一点点的将相邻相近的元素group起来,最后变成一个个segmentation mask。


- Image Encoder:
- 它结构就是Vision Transformer,一共是12层 Transformer Layers,其输入除了原始图像的Pacth embeddings,还有可学习的 group token 。
- 假设输入图像尺寸是224,×224,选择的Image Encoder是ViT-Small/16,则输出Pacth embeddings尺寸是196×384,也就是图中的token
。对应的group token
尺寸是64×384。
- 这里的 group tokens 就相当于分类任务中的 cls token。然后通过Transformer Layer的自注意力来学习到底哪些patch属于哪些group token。
- 训练过程:
- 经过六层 Transformer Layers 的之后,学的差不多了。加入一个Grouping Block 来完成 grouping ,将图像块 token 分配到各个 group token 上,合并成为更大的、更具有高层语义信息的 group,即Segment Token(维度64×384,相当于一次聚类的分配)。
- Grouping Block结构如上图右侧所示,其grouping做法与自注意力机制类似。计算 grouping token (64×384)与图像块 token (196×384)的相似度矩阵(64×196),将token分配到相似度最大的grouping token上面(聚类中心的分配)。这里为了克服 argmax 的不可导性,使用了 可导的gumbel softmax。合并完成后得到
(64×384) 。
- 重复上述过程:添加新的 Group tokens
,经过 3 层 Transformer Layers 的学习之后,再次经过grouping block 分配,得到
(8×384) 。
- 为了和文本特征进行对比学习,将最后一层Transformer Layers输出的序列特征(8×384)进行全局平均池化Avg Pooling,得到1×384的图片特征。再经过一个MLP层变成
维的图片特征。最后与文本特征
计算对比损失。
- 推理过程:
- 文本和图像分别经过各自的编码器得到文本特征和图像特征,然后计算相似度,得到最匹配的图像文本对,就可以知道每个group embedding对应什么class。局限性在于最后的聚类中心(Group Tokens)只有8类,所以一张图像中最多分割出八个目标。
-
1.2.2 背景类
问:Group ViT在推理过程中怎么考虑背景类的呢?
在做zero-shot推理时,不光时选择最大的那个相似度(有时,最大的相似度也比较小),作者为了尽可能提高前景类的分割性能,设置了一个相似度阈值。比如设置group embedding和文本的特征相似度必须超过0.9且是取最大的那个,才会将符合条件的group embedding归为这一类。如果group embedding与所有的文本相似度都没有超过所设定的阈值,那么就会将它归为背景类。
Group ViT的局限:
- 是图像编码器的结构,没有很好地利用dense prediction的特性。
- 背景类:图片分割做的很好,分类差了。因为CLIP学不到很模糊的概念如背景group embedding和文本的相似度必须超过阈值,再取最大的。若group embedding和文本的相似度都没有超过阈值,groupvit就认为该group embedding是背景。当在COCO等类别非常多的数据集上时,置信度都比较低,阈值的设置就比较麻烦。(加一个约束把背景类融到里面。阈值可学习)
Group ViT的特点:
- GroupViT 没有在ViT基础上加很复杂的模块,目标函数也和CLIP保护一致,所以其scale性能很好。即更大模型更多数据,其性能会更好。
- GroupViT 图片分割做得好(segmentation mask生成的好),但是语义分割做的不够好,这是由于CLIP这种对比学习的训练方式,对于明确语义物体信息能学的很好;但是对于背景这种语义比较模糊类别很难识别,因为背景可以代表很多类。后续改进可以是每个类设置不同阈值,或者使用可学习的阈值,或者是更改 Zero-Shot 推理过程、训练时加入约束,融入背景类概念等。
二、目标检测
2.1 ViLD
论文:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
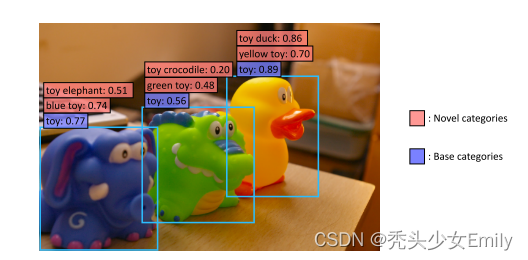
把CLIP模型当作teacher取蒸馏作者设计的网络,从而达到利用zero-shot去做目标检测的目的。简单来说,ViLD 想要做到的事情是:在训练时只需要训练基础类,然后通过知识蒸馏从 CLIP 模型中学习,从而在推理时能够检测到任意的新的物体类别(Open-vocabulary Object)。
从论文的引言给出的一张图和简单描述就能洞悉出整篇论文所要研究的内容。如下图所示,如果用传统的目标检测算法的话,模型只会判断这些物体都是玩具,也就是图中蓝色的基础类,而无法检测到更细致的类别。使用CLIP之后,在现有检测框上,不需要额外标注,就可以检测出新的类(图中红色标识类)。
2.1.1 模型框架

ViLD 方法的研究重点在两阶段目标检测方法的第二阶段,即得到提议框(proposal)之后。其思想还是最简单的分别抽取文本和图片特征,然后通过点积计算相似度。
上图的(a)Vanilla detector 和(b)ViLD-text的大致过程如下:
- (a) Vanilla detector:Mask R-CNN框架。一阶段得到的候选框proposals经过检测头得到 region embeddings,然后经过分类头得到预测的bounding box以及对应的类别。损失分为定位损失(回归损失)和分类损失。
- (b) ViLD-text分支:
- N个proposals经过一些处理得到类似图a中的N个 region embeddings(图片特征)。
- 将物体类别(基础类)处理为prompt 句子就得到了文本,然后将这些文本扔给文本编码器得到Text Embeddings(文本特征)。和Lseg类似,这些Text Embeddings也是冻住权重的,不参与训练。
- 上面物体类别就是 Base categories(也叫CB,Class Base),和Mask R-CNN有监督训练的基础类一样,所以ViLD-text 做的还是有监督训练。
- 因为是有监督训练,所以需要额外添加一个背景类进行训练,即可学习的Background embedding(基础类之外的类别全部归为背景类)。
- Text Embeddings加上分别和可学习的背景 embedding以及 region embeddings进行点积来计算图文相似度得到logics,然后计算logics和GT的交叉熵损失来进行训练。
- 在 ViLD-text 模型中,只是将文本特征和图像特征做了关联(感觉到这里只是类似Lseg),模型可以做文本查询的 zero-shot 检测。但是由于模型还不了解基础类CB之外的其他语义内容(X新类别CN),因此直接做 zero-shot 的效果不会很好。
- 根据下列ViLD-text的点积计算公式来理解训练过程。
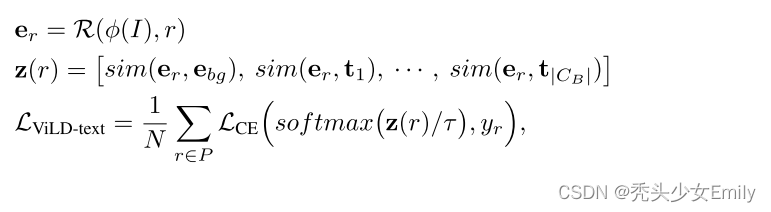
表示图片,
表示抽取图片特征,
为proposals。
计算得到
(region embeddings,图片特征)
表示背景embedding,
表示基础类CB的文本特征Text Embeddings。
- 图像特征
做softmax后和groud truth计算交叉熵得到这部分的损失。
projection层的引入是为了统一图像文本特征的尺寸。
- 根据下列ViLD-text的点积计算公式来理解训练过程。
- (c) ViLD-image分支:引入CLIP特性,这部分只在训练时进行蒸馏,推理时不蒸馏。考虑到 CLIP的图片编码器训练的很好,而且和文本紧密关联,所以希望ViLD-image-encoder输出的region embeddings和CLIP输出的image embedding尽可能的接近,这样就可以学习到CLIP图像编码器中开放世界的图像特征提取能力。做到这一点的最简单方式就是知识蒸馏(Knowledge Distillation)。
- 右侧teacher分支:将M个proposals resize到比如224×224的尺寸,然后输入预训练好的CLIP-image-encoder(冻结,不参与训练,保证抽出来的特征和CLIP一样好)得到M image embeddings
- 左侧student分支:和ViLD-text 分支前面的结构一样,输入M个proposals 得到M个region embeddings
- 计算region embeddings和 image embeddings的L1 loss来进行知识蒸馏,让检测器学习 CLIP 提取的特征。
- 为了加速模型训练,在训练 ViLD-image 时先用 CLIP 模型提取好图像区域特征,保存在硬盘中,在训练时直接从硬盘读取即可。
- 此分支监督信号不再是人工标注的数据,而是CLIP的图像编码,所以就不再受基础类CB的限制了,对于任何的语义区域都可以由 CLIP 抽取图像特征。利用ViLD-image,大大加强了做Open-vocabulary检测的能力。
-
ViLD-image分支的弊端:预加载训练好的proposals,而不是随时可以变的N proposals。
(1) 此分支输入是M pre-complete proposals,这是为了训练加速。
(2) 理论上第一阶段输出的N proposals应该输入text和image两个分支进行训练,但如果每次训练时再去抽取CLIP特征就太慢了。因为ViLD选用的CLIP-L模型非常大,做一次前向过程非常贵。比如M=1000时等于每一次迭代都需要前向1000次才能得到所有图像特征,这样训练时间会拉到无限长。
(3)作者在这里的做法就是在ViLD-image开始训练之前,利用RPN网络预先抽取M pre-complete proposals,然后按照图中顺序算好M image embeddings。ViLD-image训练时,只需要将其load进来,这样loss算起来就很快,蒸馏过程也就训练的很快。
-
- (d) ViLD-text 和 ViLD-image的合体
- 为了训练简单,将M pre-complete proposals和N proposals一起输入检测头Head得到n+m个embedding,然后拆分为N region embeddings和M region embeddings。前者算ViLD-text 分支的交叉熵损失,后者算ViLD-image的蒸馏L1损失。
2.1.2 模型总览

- 训练过程:
- 图片通过RPN网络得到proposals。然后经过RoIAlign和一些卷积层得到N region embeddings,也就是图中的
和
。
- 基础类通过prompt得到文本,经过文本编码器得到文本编码
。然后和
一起计算交叉熵。
- 将已经抽取好的M image embeddings(图中的骰子、停车标识等等)输入CLIP图像编码器得到特征
,用它们对
- 图片通过RPN网络得到proposals。然后经过RoIAlign和一些卷积层得到N region embeddings,也就是图中的
- 推理过程:
ViLD的特点:第一个在LVis这么难的数据集上做Open-vocabulary目标检测的模型,是目标检测里的一个里程碑式的工作。ViLD借鉴了CLIP的思想,也借鉴了CLIP的预训练参数,最后的结果也不错。
2.2 GLIP
论文:Grounded Language-Image Pre-training
GLIP的名字就和CLIP的名字,只不过是把contrast变成了grounded。它的主要研究动机:怎么才能利用给更多的数据呢?跟分割一样,这些精心标注好的数据非常难得且对于现实生活中那些边边角角的类以及层出不穷的新类,没法训练一个涵盖这么多类的好模型。所以我们只能依赖做open vocabulary的detection模型,去把corner case处理好。
如果想训练一个特别强大的open vocabulary的detection模型,就必须像CLIP一样,能有一个很好的预训练数据集且规模最好上千万、上亿,还可以把文本的图片之间的关系以及定位学得很好。那么重点就是使用图片-文本对数据集的高效使用 ,因为很好收集。
由此得出结论一:open vocabulary object detection是必要的
Vision Language任务(图片-文本多模态任务)里有一类定位任务Vision grounding,主要就是根据文本定位出图片中对应的物体(短语定位phrase grounding),这与目标检测任务非常类似,都是去图中找目标物体的位置。
GLIP 的文章的出发点,就是将检测问题转换为短语定位(phrase grounding)问题,这样GLIP 模型就统一了目标检测和定位两个任务,可以使用更多的数据集。再配合伪标签的技术来扩增数据,使得训练的数据量达到了前所未有的规模(3M人工标注数据和24M图文对数据)。最后训练出来的模型GLIP-L,直接以 zero-shot 的方式在COCO 和LVIS 上进行推理,mAP分别达到了 49.8 和26.9,可见其性能非常的强。
由此得出结论二:phrase grounding + object detection+伪标签训练
- groudning模型的输入是短语、短语中名词对应的框和图片。
- 目标检测转为phrase grounding:通过prompt的方式将标签名转化为短语。例如coco有80个类别标签,将80个标签用逗号连接,并在短语前加“Detect:”来组成短句。这样做有两个好处:
- 目标检测和phrase grounding的数据集就都可以拿来训练
- 对于基础类 和其它各种类,可以都构建到 prompt 短语中一起检测,更加的灵活,可以方便的将任务迁移到开放式目标检测任务当中。
- 伪标签训练(self training):
- 将所有目标检测任务和phrase grounding任务的数据集(一共3M)全部拿来做有监督训练,得到GLIP-T(C)模型。
- 将这个模型对网上爬取到的24M图像-文本对数据进行推理,得到bounding box。然后将这些bounding box全部作为GroundTruth(伪标签),这样就得到了24M的有监督数据。
- 最在这24M的有监督数据上继续训练,得到最终模型GLIP-L。由此可见整个GLIP都是用有监督的方法进行训练的。
2.2.1 zero-shot 推理效果展示
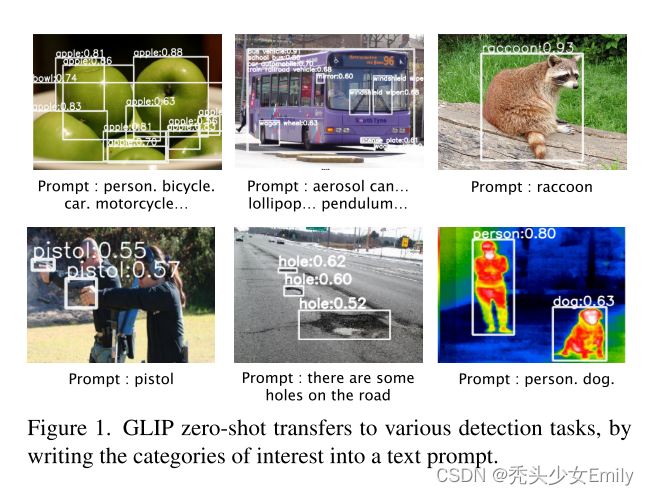
直接像ViLD一样给出物体类别生成一句话(Prompt : person. bicycle.car. motorcycle…)或者是像phrase grounding任务一样生成短语“马路上有很多坑”(Prompt : there are some holes on the road),都可以将物体检测出来。
2.2.2 目标检测背景
目标检测的损失函数由分类损失和定位损失组成。对于目标检测和Vision grounding而言,定位部分都差不多,二者的区别主要在于如何计算分类loss。因为 detection的标签是one-hot的类别单词,而Vision grounding的标签是一个句子。所以需要把二者的分类loss统一到一个框架下面,也就是:
- detection 分类损失计算:
表示图片编码器(例如swin transformer),处理img之后得到N region embeddings,即
(n个bounding box,每一个的维度是d);
- N region embeddings
。其中分类头
由矩阵
表示,和N region embeddings相乘后得到
。
:使用nms筛选这些bounding box,然后和GroundTruth计算交叉熵,得到分类损失。
- Vision grounding分类损失计算:(其实和ViLD text分支一模一样)
- 表示图片编码器的
- 文本编码器
(比如BERT)处理Prompt得到text embedding,即
- 图像特征O和文本特征P相乘得到相似度结果
,即论文中说的region-word aligment scores。
- 表示图片编码器的
上式中,M((sub-word tokens数量)总是大于短语数c,有四个原因:
- 一个短语总是包含很多单词
- 一个单词可以分成几个子词,比如toothbrush分成了 tooth#, #brush
- 还有一些添加词added tokens,像是“Detect:”,逗号等,或者是语言模型中的特殊token
- tokenized序列末尾会加入token [NoObj]
训练的时候,如果短语phrase都是正例( positive match)并且added tokens都是负例negative match(added tokens和任何图片的物体都无法匹配),那就使用subwords(subwords也都是正例,此时标签矩阵由
扩展为
。测试时多个token的平均pro作为短语的probability。
使用上面的方式统一损失之后,就可以用grounding模型方法来预训练检测任务,从而使GLIP模型可以做zero-shot检测。之后作者使用统一过后的框架验证了在 COCO 数据集上的指标,发现是完全匹配的 ,因此从实验上也验证了自己的想法
2.2.3 训练数据集
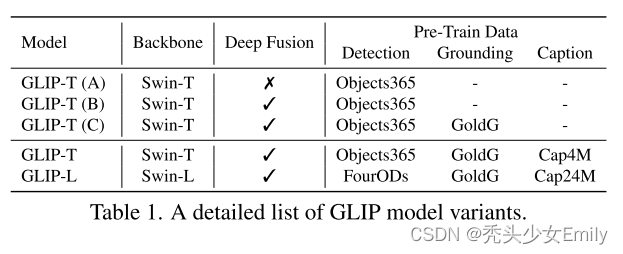
- 上面三行A,B,C展示的是GLIP模型可以同时使用目标检测的数据集,例如Objects365和Grounding的数据集GoldG(几个数据集的合并,还是很大的)。
- GLIP-L:backbone为Swin-L模型,然后同时使用FourODs(目标检测有监督训练中能用的所有的数据集)、GoldG和图片文本对Cap24M数据集一起训练,此时数据集已经非常大了,足以训练出一个很强的模型。
2.2.4 模型框架

由于所有数据集都是有标注的,所以模型是以有监督的方式进行训练。计算得到文本特征与图像特征的相似度之后,直接与 GT box计算对齐损失alignment loss即可(和ViLD-text分支一样)。这样就完成了文本和图像的特征融合,就可以进行zero-shot检测了。而定位损失也是直接与GT box计算L1 损失。
模型中间的融合层(Deep Fusion)和LSeg的做法一样,都是为了使图像特征和文本特征进一步交互,使最终的图像-文本联合特征空间(joined embedding space)训练得更好(相似的embedding拉近,不相似的拉远),图像特征和文本特征被训练的更强更有关联性,这样后面计算相似度矩阵的效果肯定就更好。
Deep Fusion层:
- 图片编码器是DyHead(L层),第一层输出图片特征表示为
- 文本编码器是预训练好的BERT(L层),第一层输出文本特征表示为
- X-MHA表示跨模态多头注意力模块。
- 从结构图和公式可以看出,每一层输出的图文特征
都会在X-MHA中进行交互,交互后的特征和原特征相加之后一起输入到下一层进行编码,得到下一层的特征
。
在X-MHA模块中,图像特征和文本特征交互使用的是Cross Attention:
分割和检测都属于稠密性任务(dence prediction)的一种,都需要同时分类和定位,所以很多方法是可以互相借鉴的,所以Deep Fusion也可以用到分割领域,比如GroupViT。GroupViT只有在图像分支和文本分支的最后做了一下对比学习,如果在此之前做了一些Deep Fusion,可能效果更好。
GLIP的特点:GLIP创造性地将目标检测任务转换为短语定位任务。即,对待任意一张训练图片,把标签用句号隔开,拼接成一句话。再结合伪标价签的技术来扩增数据。至此使Glip能把corner case处理得不错。
2.3 CLIPv2
论文:GLIPv2 Unifying Localization and Vision-Language Understanding
GLIPv2大概思想:与GLIP差不多,框架上也很相似。只不过带入了更多的任务和数据。在上图中,GLIPv2增加了一切text encoder的训练任务,使得表征更加丰富。 比如定位任务不光有目标检测还有实例分割,Understanding任务包含了Vision grounding、vision Caption和VQA任务。
2.3.1 模型框架

Vision-Language:语言-视觉任务,包括:
- vision Caption:图像描述生成,根据一张图片生成描述性文本;
- VQA:给定一张图片和一个与该图片相关的自然语言问题,计算机能产生一个正确的回答。文本QA即纯文本的回答,与之相比,VQA把材料换成了图片形式,所以这是一个典型的多模态问题;
- Vision grounding:根据短语定位图片中对应的物体。
2.3.2 损失函数
在GLIPv2 当中对损失函数做了改进,在原有ground损失的基础上加入两种损失:

- 添加MLM 损失:添加这一损失可以强化模型的语言特性。能够使得训练出来的模型能够扩展到 VQA / ImageCaption 任务上。
- 图片间的对比学习损失
。原先的image-text pair,只能看到pair内部的信息。比如一对数据是一个人抱着猫的照片和对应的文本描述。按照原先的 loss 设计,图片中的人只能够做到和 ‘person’ 相似, 和 ‘cat” 不相似,但是没有办法和所有其它图片中各种各样的实体进行区分。所以在此考虑加入图片间的对比损失。
除了增加了两种损失函数,还修改了对比损失函数:

- 对一个batch 当中所有的pair ,抽取其未交互的图片特征和文本特征
- 计算一个batch内,所有图片特征和文本特征的相似度
,这样就可以通过跨图像匹配的方式,使得每一个object/token 都能够看到更多的负样本。所以我们不仅仅对图片和文字交互后的特征建模,也要对于图片和文本交互前的特征建模,类似loopiter。
- 跨样本匹配的时候,图片A 当中的‘人’这个物体,和图片B 对应的prompt 当中的 ‘person’类别,也应该是匹配的。
2.3.3 模型总览

GLIPv2的特点:将定位预训练和视觉语言预训练 (VLP) 与三个预训练任务(短语接地作为检测任务的 VL 重构,区域-词对比学习作为新的区域-词级对比学习任务,以及掩码语言建模相结合)。 这种统一不仅简化了之前的多阶段 VLP 程序,而且实现了定位和理解任务之间的互惠互利。
三、图像生成
3.1 CLIPasso
论文:CLIPasso: Semantically-Aware Object Sketching
CLIPpasso=CLIP+Passo(毕加索)的思想:给机器一张真实的照片,机器就能还给他一张最简形式的简笔画。用最简单的素描,几笔就把物体描述出来,同时大家又能认出来,这样就必须保证语义上和结构上都能被识别才行。可以看出这种素描是很难的,必须抓住物体最关键的特征才行,也就是摘要提到的要有对物体抽象的能力。
训练数据集的种类和风格少,由此引出下面两个问题:
- 如何摆脱对有监督训练数据集的依赖
- 怎么找到能把一个图像的语义信息抽取得特别好得模型
能解决上述两个问题的最直接答案就是CLIP,CLIP图文配对学习的方式,使其对物体特别敏感,对物体的语义信息抓取的非常好;而且还有出色的zero-shot能力,完全不用在下游任务上进行任何的微调,拿过来就能直接用,所以就有了CLIPasso。
在可视化期刊distill上发表的博客《Multimodal Neurons in Artificial Neural Networks》中,作者对CLIP模型的对抗性攻击、OCR攻击、稳健性等等都分析的非常透彻,非常值得一读,这其中就包括CLIP对简笔画的迁移问题。因为之前CLIP都是处理的自然图像,所以迁移到检测分割效果都很好。但是简笔画和自然图像分布完全不同,无法判断CLIP是否能很好的工作。
在文章中,作者观察到不管图片风格如何,CLIP都能把物体的视觉特征抽取的很好 ,也就是非常的稳健,由此才奠定了CLIPasso的工作基础。(其实本文也借鉴了CLIPDraw)
从摘要可知,CLIPasso一种可以在几何简化和语义简化的指导下实现不同程度抽象的物体速写方法。虽然速写生成方法往往依赖明确的素描数据集进行训练,但是作者利用CLIP的强大能力,从速写和图像中提炼语义概念 ,将速写定义为一组贝兹曲线(贝塞尔曲线)。然后用一个可微调光栅化器直接针对基于CLIP的感知损失,优化曲线参数。
3.1.1 方法总览
什么是贝兹曲线?它是通过一系列空间上2维的点控制的一个曲线。每一个曲线
,式子中上面的数字4表示四个点。这四个点控制了这个曲线,通过模型的训练,更改这4个点的位置,再利用贝兹曲线计算,就能慢慢改变这条曲线的形状,最后变成所想要的简笔画形式。

训练方法:
- 初始定义一些贝兹曲线
到
,然后扔给光栅化器Rasterizer,就可以在二维画布上绘制出我们看得到的图像。
- 根据loss训练笔画参数,得到最终的模型输出。
其中,Rasterizer为光栅化器,图形学方向根据参数绘制贝塞尔曲线的一种方法,可导。所以这部分是是以前就有的方法,不做任何改动。
3.1.2 目标函数
这篇文章研究的重点:如何选择一个更好的初始化以及如何选择合适的loss进行训练。
作者提到生成的简笔画有两个要求,即在语义和结构上和原图保持一致。比如马还是马、牛还是牛;而且不能生成了马,但是马头的朝向反了,或者马从站着变成趴着。在 CLIPasso 中,这两个要求分别由两个损失函数——语义损失和几何距离
来保证。
:semantics loss,计算原图特征和简笔画特征,使二者尽可能相似。
- 使用 CLIP蒸馏CLIPasso模型(类似ViLD),可以让模型提取到的图像特征和 CLIP 图像编码器提取的特征接近。这样就借助了刚刚提到的CLIP的稳健性,即无论在原始自然图像上还是简笔画上都能很好的抽取特征。如果二者描述的是同一物体,那么编码后的特征都是同一语义,其特征必然相近。
:geometric distance loss,计算原图和简笔画的浅层编码特征的loss。
- 借鉴了一些LowerLevel的视觉任务。因为在模型的前几层,学习到的还是相对低级的几何纹理信息,而非高层语义信息,所以其包含了一些长宽啊这些信息,对几何位置比较敏感。因此约束浅层特征可以保证原图和简笔画的几何轮廓更接近。(比如CLIP预训练模型backbone是ResNet50,就将ResNet50的stage2,3,4层的输出特征抽出来计算loss,而非池化后的2048维特征去计算)
3.1.3 初始化
作者发现,如果使用完全随机初始化贝兹曲线的参数,会使得模型训练很不稳定。生成的简笔画有的既简单又好看,有的怎么训练都恢复不了语义,甚至就是一团糟,所以需要找到一种更稳定的初始化方式。
基于saliency(显著性)的初始化:将图像输入ViT模型,对最后的多头自注意力取加权平均,得到saliency map。然后在saliency map上更显著的区域采点完成贝塞尔曲线参数的初始化,这样训练稳定了很多,效果也普遍好了很多。
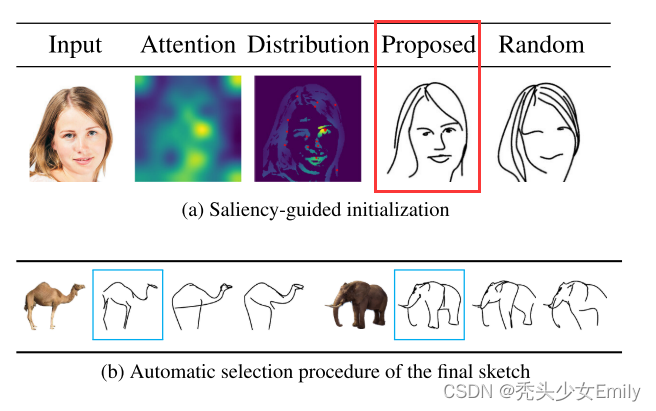
上图中,可以看到更换初始化方法后,Proposed的脸部特征更接近原图,而且头发更加简约。
3.1.4 局限性
- 输入图片有背景时,生成的效果大打折扣。
- 输入图片必须是一个物体,且在纯白色的背景上,生成的效果才最好。因为只有这样,自注意力图才更准,初始化效果才会好,而有了背景,自注意力就会复杂很多。
- 所以作者是先将图片输入U2Net,从背景中抠出物体,然后再做生成。这样就是两阶段的过程,不是端到端,所以不是最优的结构。如何能融合两个阶段到一个框架,甚至是在设计loss中去除背景的影响,模型适用就更广了。
- 简笔画是同时生成而非序列生成。如果模型能做到像人类作画一样,一笔一画,每次根据前一笔确定下一笔的作画位置,不断优化,生成效果可能更好
- 复杂程度不同物体,需要抽象你的程度不同。CLIPasso控制抽象程度的笔画数必须提前指定,所以最好是将笔画数也设计成可学习的参数。这样对不同的图片上不同复杂程度的物体,都能很好的自动抽象。目前用户每次输入图片,还得考虑用几笔去抽象。
CLIPasso的特点:可以适应任意语义类别的输入图像,而不再局限于数据集中固有的几个类别;并且可以做到对物体不同程度的抽象,同时保持和原图的语义和结构的一致性。
3.2 CLIP4Clip
CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
这篇文章的主要思想是:利用CLIP模型去做视频里的video-text retrival(视频-文本跨模态检索)。因为CLIP天生就很适合做检索工作,它就是在算图像和文本之间的相似性,根据相似性来做ranking、mathcing、retrieve各种类似的任务。
3.2.1 模型框架

视频比图片多了一个维度,由于视频时一系列的视频帧组成的,它有时序的概念。如果用最简单的形式,就是每一帧都单独设为image patch,再把image patch丢进Video Encoder(ViT),得到最后的cls token。得到的cls token不再是像文本一样是一个,而是一系列的cls token。这样就出现了一个问题,原来是一个文本特征对应一个图片特征,直接做点乘或者是相似度计算。但是现在一个文本特征对应一系列的图片特征,怎么做相似度计算呢?
本篇论文提出了3种方法来解决上述问题,分别为:
- 无参型(Parameter-free type):一系列图片特征直接取平均。缺点是没有考虑视频帧之间的时序性,没办法区分先后顺序。
- 顺序型(Sequential type):加入LSTM。把一系列的图片特征给Transformer Encoder或LSTM,得到结果。
- 紧凑型(Tight type):文本得到的特征给Transformer Encoder,一系列图片特征也同样给Transformer Encoder,最后利用文本特征通过MLP进行相似度计算。
3.2.2 文本、视频编码器
文本编码器模型直接采用CLIP模型的Transformer网络。模型为12层,宽度为512,包含8个注意力头。
视频编码器类似clip采用ViT-B/32,网络深度为12层,包含32个patch。通过将视频帧进行分patch,并结合位置attention输入ViT模型中,进行线性投影,得到代表视频的embedding向量。
,
其中,V为输入视频序列,Z为视频生成的embedding,W为文本的embedding。
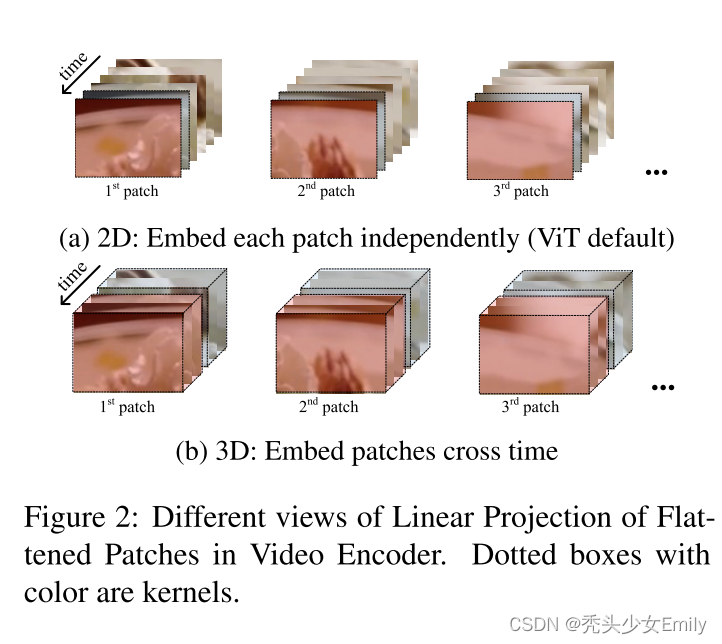
由于2D线性投影忽略了视频帧之间的时序关系,因此采用3D线性投影。两者主要的区别在于卷积核的选择上。2D线性投影卷积核的维度为[h× w],2D线性投影卷积核的维度为[t × h × w]。其中t表示时序,h表示高度,w表示宽度。
3.2.3 三种特征相似性度量计算
- 无参型(Parameter-free type):先对视频的特征进行平均池化,然后将池化后的视频特征和文本特征计算cos距离。
- 顺序型(Sequential type):先对视频特征基于LSTM/Transformer编码,然后对编码后的特征进行平均池化操作,最后按照同样的方法计算cos距离。
- 紧凑型(Tight type):将文本特征W和视频特征Z拼接起来,得到拼接后的特征U,并将U和位置编码P,类型编码T进行拼接,输入Transformer进行编码,然后使用2个全连接层做特征投影,得到最终的输出。
3.2.4 损失函数

CLIP4Clip的特点:图像特征也可以促进视频文本检索; 对优秀的图像文本预训练CLIP进行后预训练可以进一步提高视频文本检索的性能;用于视频文本检索的CLIP是学习率敏感的。
3.3 ActionCLIP
论文:ActionCLIP: A New Paradigm for Video Action Recognition
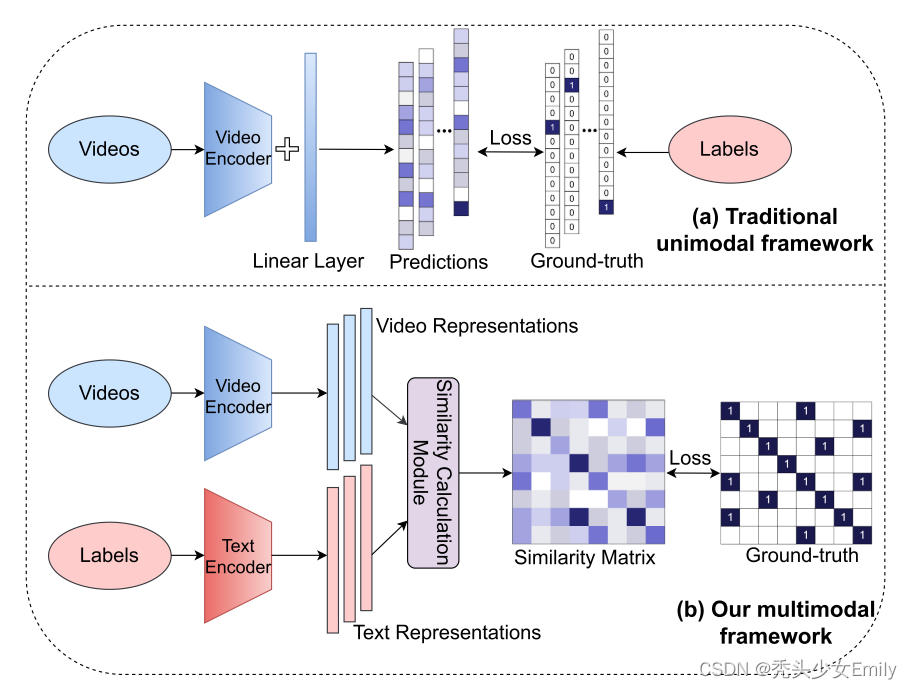
用CLIP研究视频理解动作识别的研究动机:传统的动作识别模型,视频经过一个视频编码器(2D/3D)得到一个向量(512维或者2048维),再经过一个分类头就得到了输出,得到的输出与有标签的数据集计算loss。这就存在有监督学习的局限性:一定需要标签。但是对于视频理解,有标签就会受限于数据集的规模,如何定义标签,如何标签更多数据都是很棘手的问题。对于视频理解来说,如何能拜托这种带标签的数据、如何真的能够从海量视频数据里先取学一个比较好的特征,然后再用zero-shot或者few-shot做下游任务,其实是最理想的。
由此,CLIP是首选,CLIP本身就能够做很好的zero-shot。
Action CLIIP过程:文本和视频分别进入各自的编码器提取各自的特征,然后计算相似度得到相似度矩阵,然后将其与定义好的数据集标签矩阵算一下损失。
改进有两个方面:
- 如何将图像变成视频,也就是每一帧的特征如何与文本特征求相似度,这与CLIP4clip非常类似(平均池化、LSTM或带编码的Transformer时序信息、早期融合tight type)。CLIP是完全自监督的学习方式,图像文本对,对角线上是正样本。
- 标签矩阵。使用的文本是标记好的标签,当batch比较大的时候,不是对角线的地方也可能是正样本(比如一个batch中可能有多个描述跑的动作)。这个问题可以将交叉熵损失换成KL散度(衡量两个分布的相似性)就可以解决。
3.3.1 模型框架
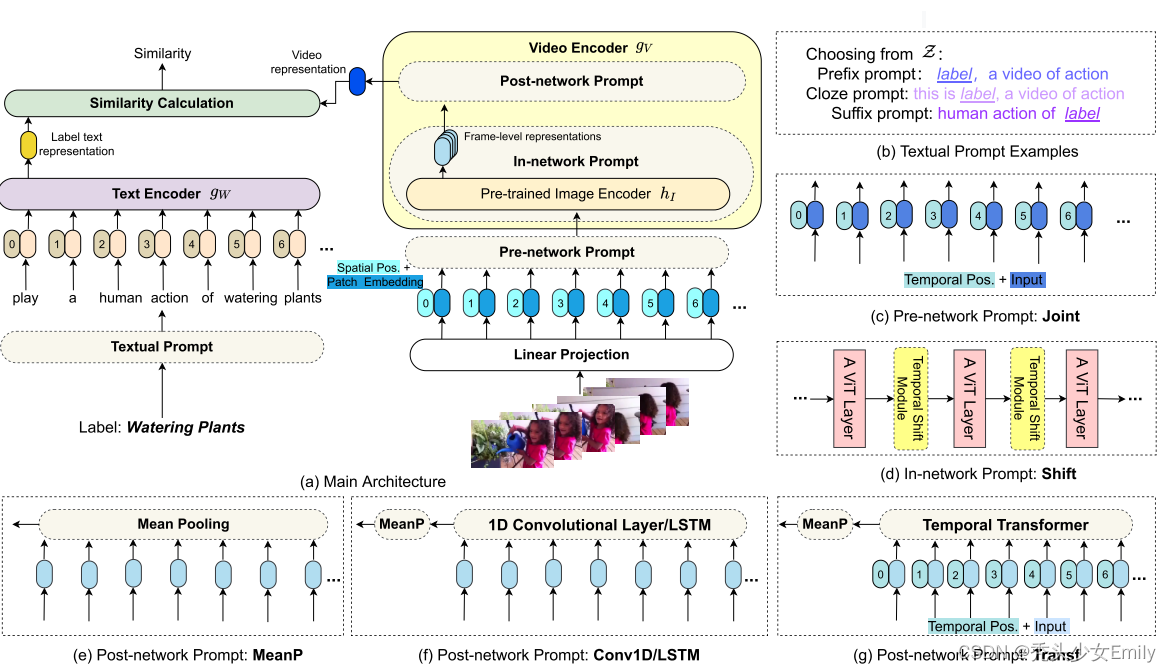
看模型框架就能看出了和上一篇的CLIP4C相差不多,都是利用三种方式来计算相似度。
prompt(提示):在原来已经预训练好的参数之上,通过加一些小的模块,训练这些小的模块让训练好的模型参数尽快的迁移到下游任务上。
文本Prompt:前缀prefix、完形填空cloze、后缀suffix。和CLIP里的prompt一致,只不过被分成三类。
- Pre-network Prompt:joint。输入层面加入了时序信息。
- In-network Prompt:shift。特征图上做各种移动,达到更强的特征建模能力。
- Post-network Prompt:其实就是CLIP4clip中的三种相似度计算。
ActionCLIP的特点:
- 建模为多模态学习框架内的视频-文本匹配问题,通过更多的语义语言监督来增强视频表示:实现零样本学习
- 采用“ 预训练,提示和微调 ”的范式:解决标签文本的不足和利用大量的网络数据导致资源开销过大的问题。