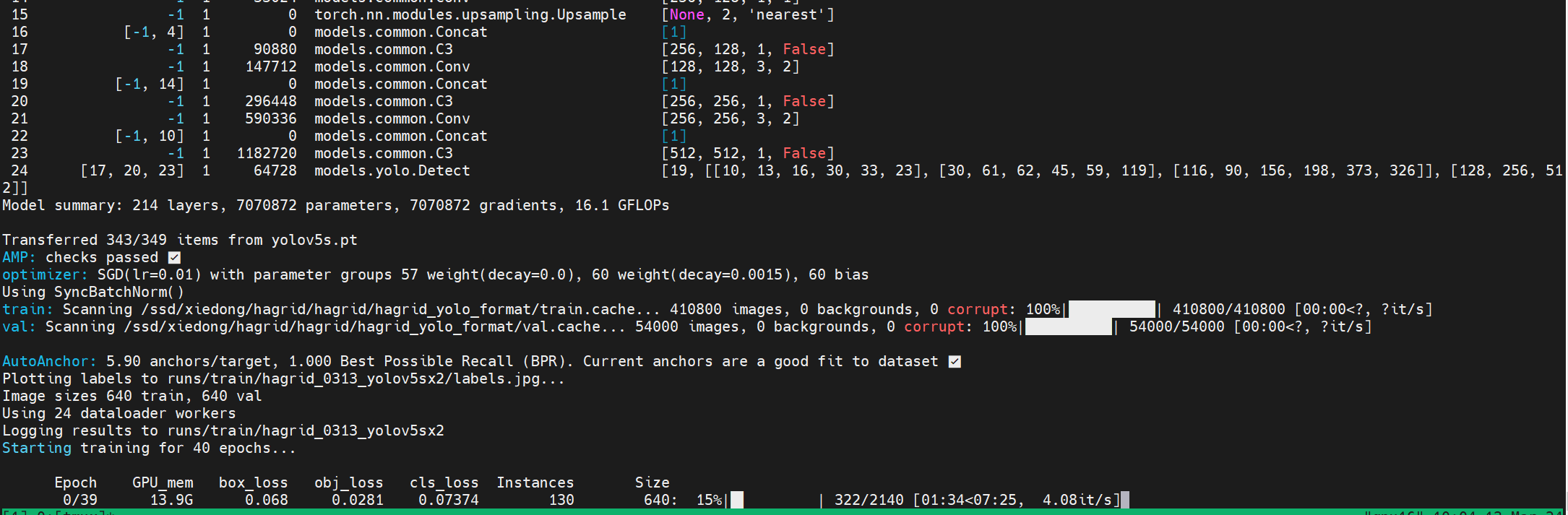
import pandas as pd
import requests
from lxml import etree
#数据请求
url="https://www.maigoo.com/brand/list_1715.html"
headers={'User-Agent':''}
#数据响应
res=requests.get(url,headers=headers)
tree = etree.HTML(res.text)
#数据解析
title=tree.xpath('.//div[@class="info"]/a/text()')
company=tree.xpath('.//div[@class="info"]//span//text()')
company=" ".join(company).replace('(', '').replace(')', '')#获取数据,进行简单的处理,转成列表类型暂存数据。
company=company.split(' ')
content=tree.xpath('.//div[@class="rongyu dhidden2 c888"]/text()')
adress=tree.xpath('.//div[@class="brandlogo"]/a/@href')
picture=tree.xpath('.//div[@class="brandlogo"]//img/@src')
#数据保存
for i in title,content,adress,picture:data = pd.DataFrame([title,company,content,adress,picture],index=['title','company','content','adress','picture'])
print(data.T)
---如有侵权,请即使联系。谢谢~