1.对于一组电影数据,呈现出rating,runtime的分布情况:
#encoding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = "./youtube_video_data/IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
#print(df.head(1))#读取第一行
#print(df.info())#读取Data columns,显示数据条数#rating,runtime分布情况
#选择图形,直方图
#准备数据
runtime_data = df["Runtime (Minutes)"].values
#print(runtime_data)#读取运行时间的分钟数
max_runtime = runtime_data.max()
min_runtime = runtime_data.min()
num_bin = (max_runtime - min_runtime)//10#显示直方图的组数#设置图形的大小
plt.figure(figsize=(20,8),dpi=80)
plt.hist(runtime_data,num_bin)#显示直方图
plt.xticks(range(min_runtime,max_runtime+5,5))
plt.show()
#rating的显示类比以上代码2.统计电影分类(genre)的情况(重新构造一个全为0的数组,列名为分类,如果一条数据中分类出现过,就让0变为1):
#encoding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = "./youtube_video_data/IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
#print(df.head(1))
#print(df["Genre"])#输出Genre的数据
#统计分类的列表
temp_list = df["Genre"].str.split(",").tolist()#[[],[],[]...]
#print(temp_list)
genre_list = list(set([i for j in temp_list for i in j]))
#print(genre_list)
#构造全为0的数组
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns = genre_list)
#print(df.shape[0])#输出的结果为行数1000
#print(zeros_df)#给每个电影出现分类的位置赋值1
for i in range(df.shape[0]):#遍历每一行#zeros_df.loc[0,["Sci-fi","Mucical"]] = 1zeros_df.loc[i,temp_list[i]] = 1 #把第i行,第temp_list[i]列的数设置为1
#print(zeros_df.head(3))
#统计每个分类的电影的数量和
genre_count = zeros_df.sum(axis=0)
#print(genre_count)#排序
genre_count = genre_count.sort_values()
_x = genre_count.index
_y = genre_count.values
#print(_x)
#print(_y)
#画图
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.show()3.数据合并:
join : 默认情况下它是把行索引相同的数据合并到一起
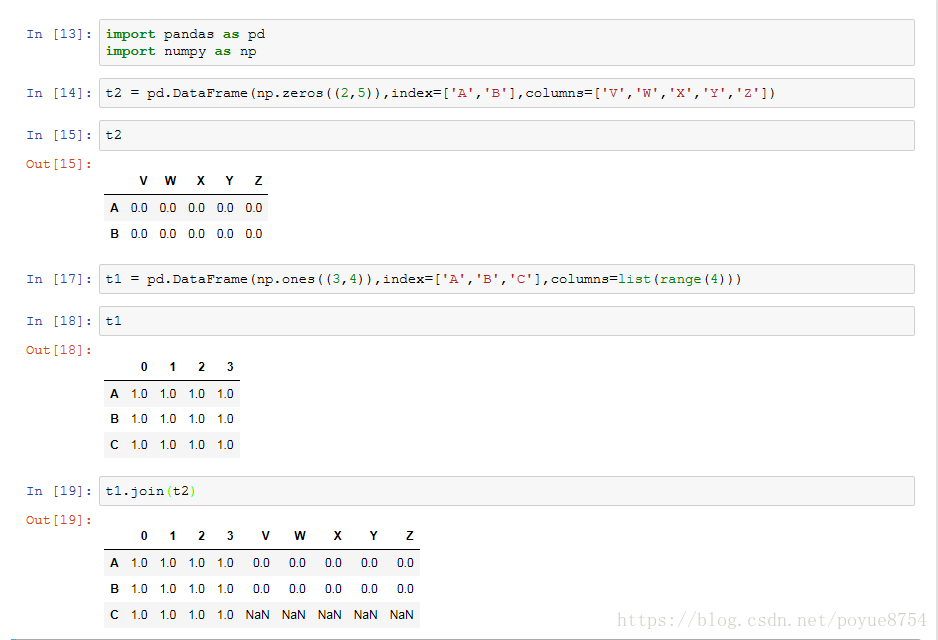
merge :按照指定的列把数据按照一定的方式合并到一起
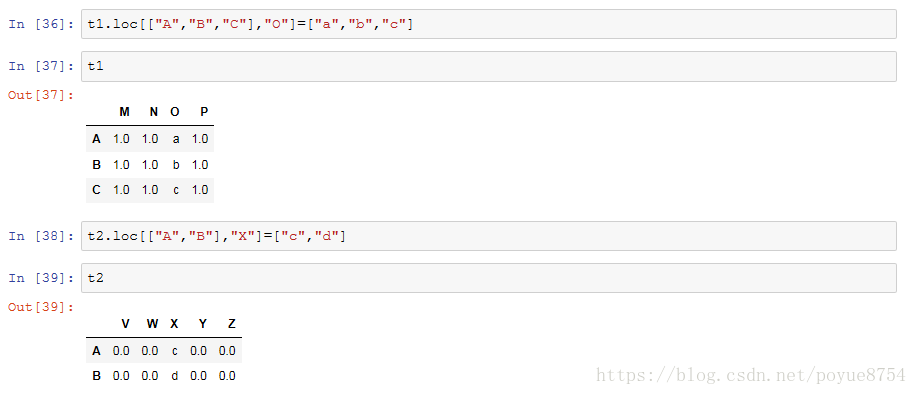
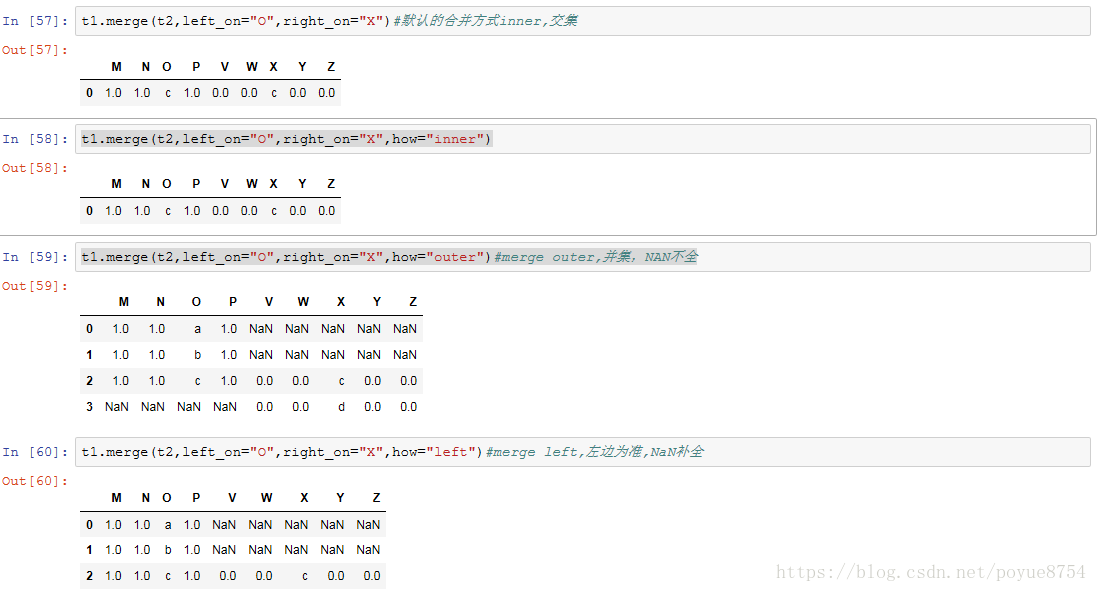

4.全球星巴克店铺的统计数据,美国的星巴克数量和中国的哪个多,中国每个省份星巴克的数量:
#encoding=utf-8
import pandas as pd
import numpy as np
file_path = './youtube_video_data/starbucks_store_worldwide.csv'
read_data = pd.read_csv(file_path)
#print(read_data)
#print(read_data.head(1))
#print(read_data.info())
grouped = read_data.groupby(by="Country")
print(grouped)
#DataFrameGroupBy
#可以进行遍历
# for i,j in grouped:
# print(i)
# print("-"*100)
# print(j,type(j))
# print("*"*100)
#read_data[read_data["Country"]=="US"]#调用聚合方法,显示中国和美国的店铺数量
#print(grouped["Brand"].count())
# country_count = grouped["Brand"].count()
# print(country_count["US"])
# print(country_count["CN"])#统计中国每个省店铺的数量
china_data = read_data[read_data["Country"] == "CN"]
#print(china_data)
grouped = china_data.groupby(by="State/Province").count()["Brand"]
#print(grouped)
df = read_data
#数据按照多个条件进行分组
grouped = df["Brand"].groupby(by=[(df["Country"]),df["State/Province"]]).count()
# print(grouped)
# print(type(grouped))#数据按照多个条件进行分组,返回DataFrame
grouped1 = df["Brand"].groupby(by=[(df["Country"]),df["State/Province"]]).count()
grouped2 = df.groupby(by=[df["Country"],df["State/Province"]])[["Brand"]].count()
grouped3 = df.groupby(by=[df["Country"],df["State/Province"]]).count()[["Brand"]]
# print(grouped1,type(grouped1))
# print(grouped2,type(grouped2))
# print(grouped3,type(grouped3))
print(grouped1.index)
5.分组和聚合:


# coding=utf-8
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_managermy_font = font_manager.FontProperties(fname=r"c:\windows\fonts\simsun.ttc")file_path = "./youtube_video_data/starbucks_store_worldwide.csv"df = pd.read_csv(file_path)
df = df[df["Country"]=="CN"]#使用matplotlib呈现出店铺总数排名前10的国家
#准备数据
data1 = df.groupby(by="City").count()["Brand"].sort_values(ascending=False)[:25]_x = data1.index
_y = data1.values#画图
plt.figure(figsize=(20,12),dpi=80)# plt.bar(range(len(_x)),_y,width=0.3,color="orange")
plt.barh(range(len(_x)),_y,height=0.3,color="orange")plt.yticks(range(len(_x)),_x,fontproperties=my_font)plt.show()显示结果:
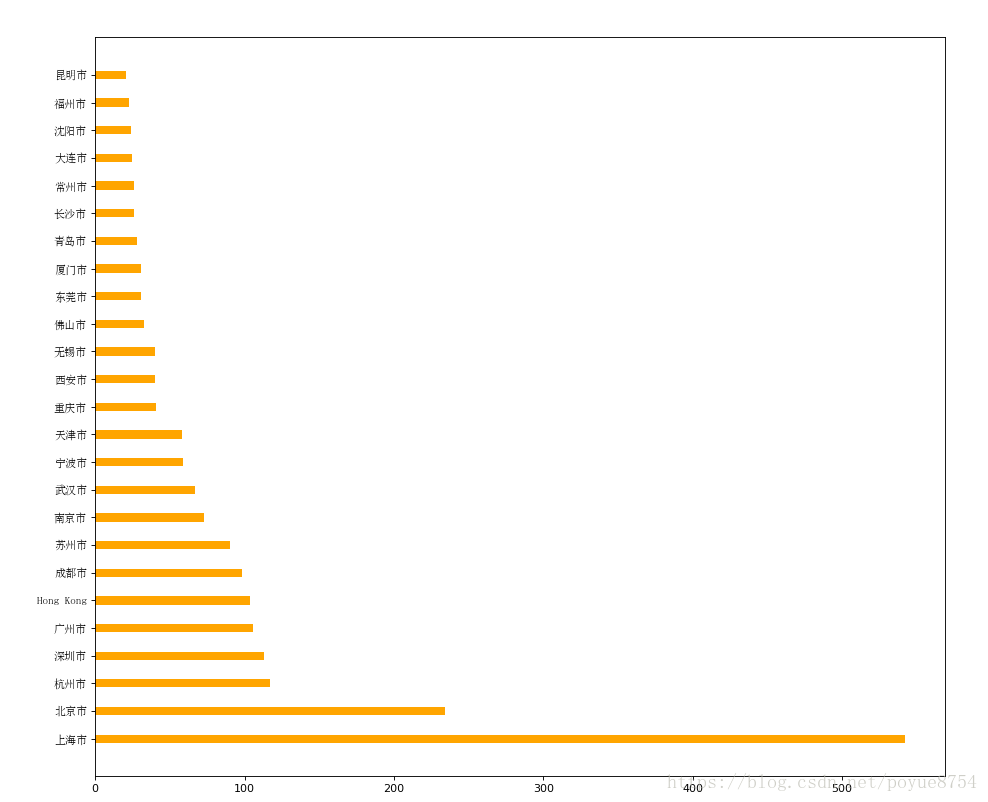
6.索引和复合索引:




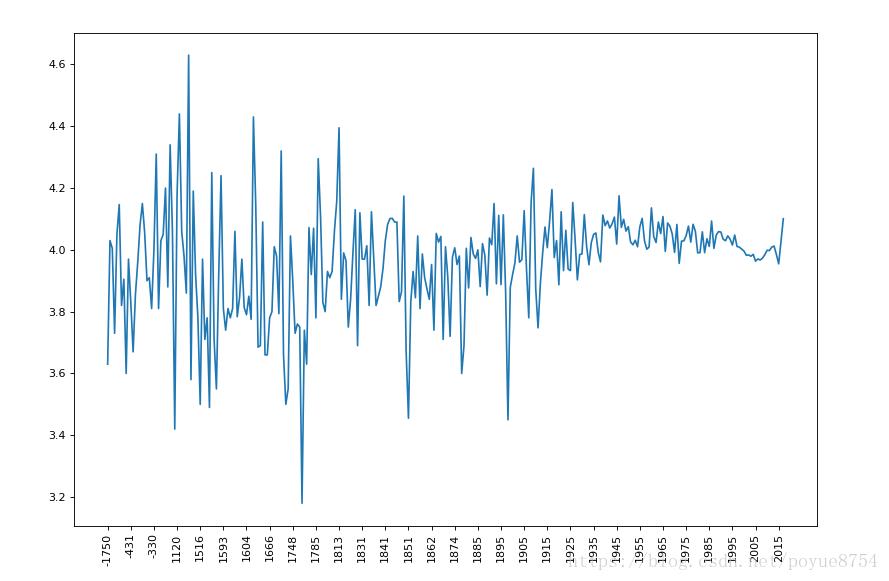
6.有全球排名靠前的10000本书的数据,统计不同年份的数量,不同年份书的平均评分情况:
#encoding=utf-8
from matplotlib import pyplot as plt
import numpy as np
import pandas as pdfile_path = "./youtube_video_data/books.csv"
df = pd.read_csv(file_path)
# print(df.head(2))
# print(df.info())
# data1 = df[pd.notnull(df["original_publication_year"])]
# grouped = data1.groupby(by="original_publication_year").count().title
# print(grouped)
#不同年份书的平均评分情况
#取出original_publication_year列中nan行
data1 = df[pd.notnull(df["original_publication_year"])]
grouped = data1["average_rating"].groupby(by=data1["original_publication_year"]).mean()
#print(grouped)_x = grouped.index
_y = grouped.values
#画图
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
plt.xticks(range(len(_x))[::10],_x[::10].astype(int),rotation=90)
#plt.xticks(list(range(len(_x)))[::100],_x[::100],rotation=90)
plt.show()
显示结果: