目录
1、博主页面分析
2、在控制台预先获取所有作品页的URL
3、在 Python 中读入该文件并做准备工作
4、处理图文类型作品
5、处理视频类型作品
6、异常访问而被中断的现象
7、完整参考代码
任务:在 win 环境下,利用 Python、webdriver、JavaScript等,获取 xiaohongshu 某个博主的全部作品。
本文仅做学习和交流使用。
1、博主页面分析
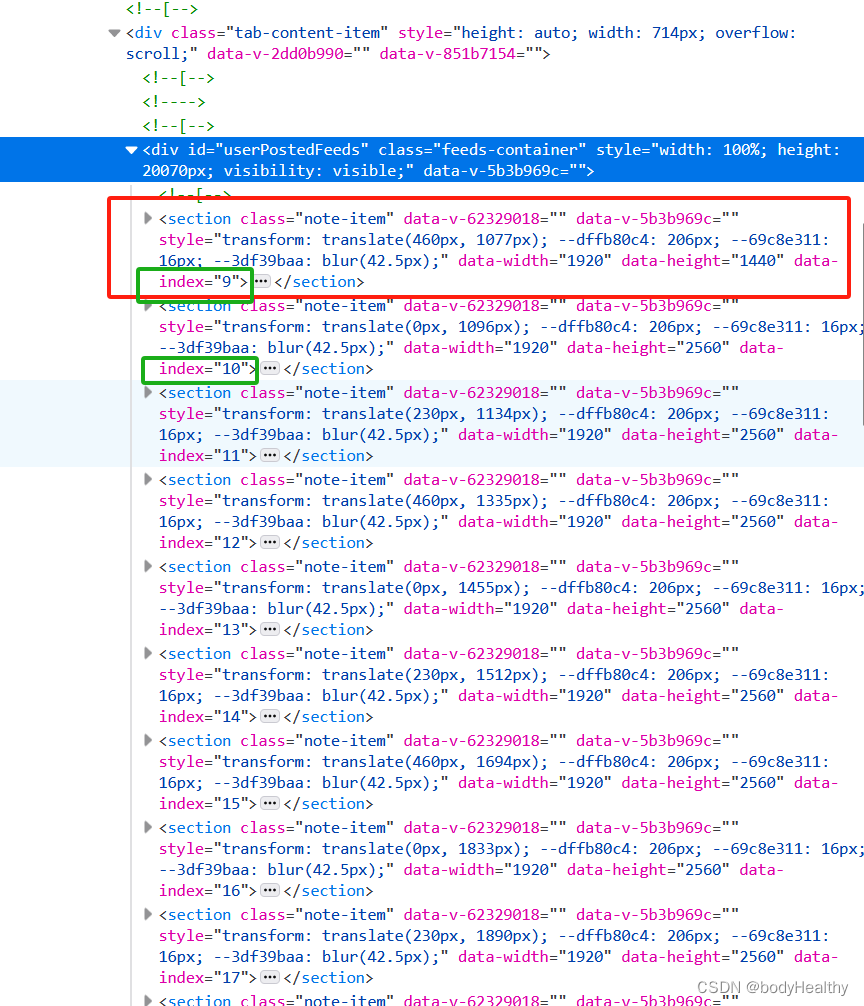
section 代表每一项作品,但即使博主作品有很多,在未登录状态下,只会显示 20 项左右。向下滚动页面,section 发生改变(个数不变),标签中的 index 会递增。
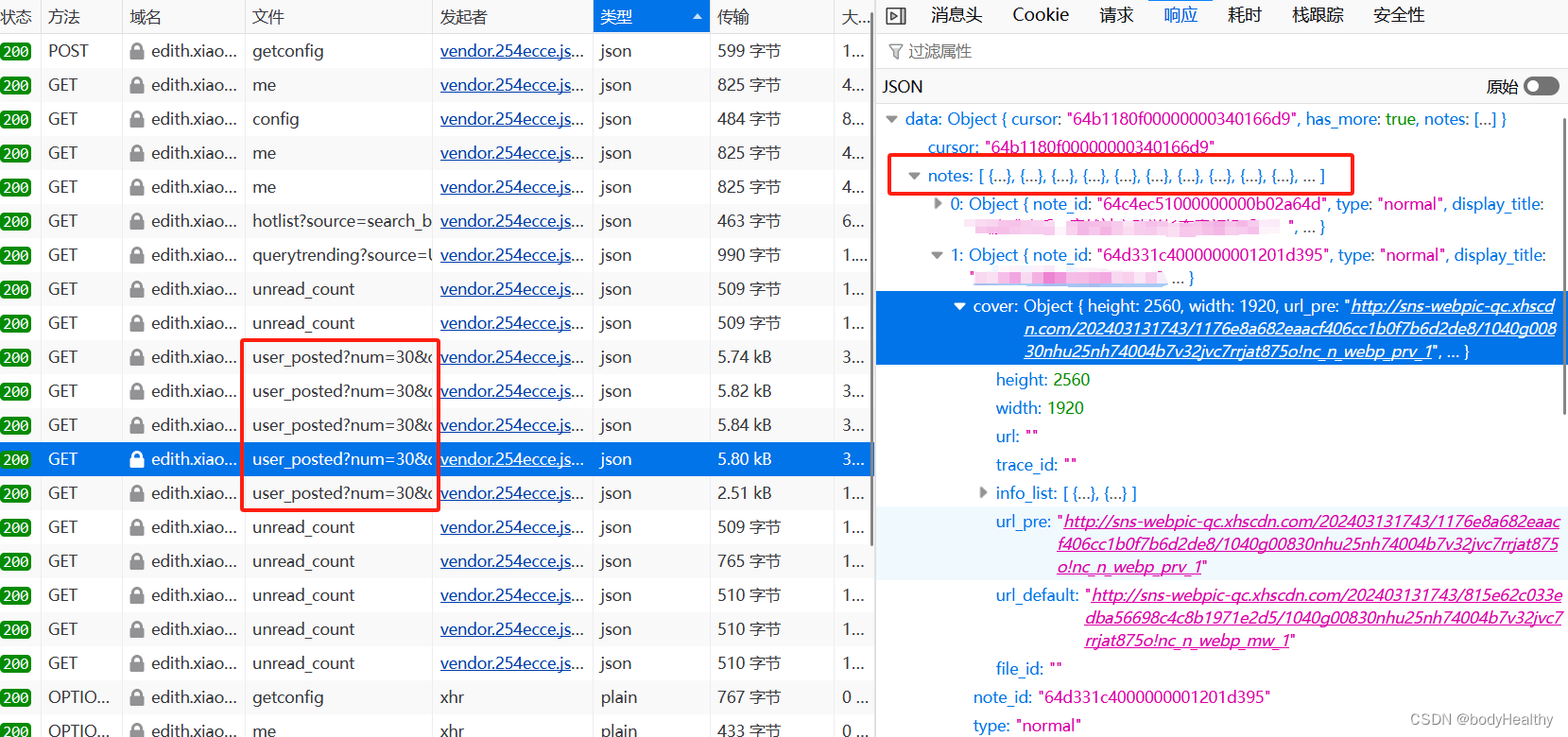
向下滚动页面时,到一定的范围时,会发送一个获取作品数据的请求,该请求每次只请求 30 项作品数据。该请求携带了 cookies 以及其他不确定值的参数。
2、在控制台预先获取所有作品页的URL
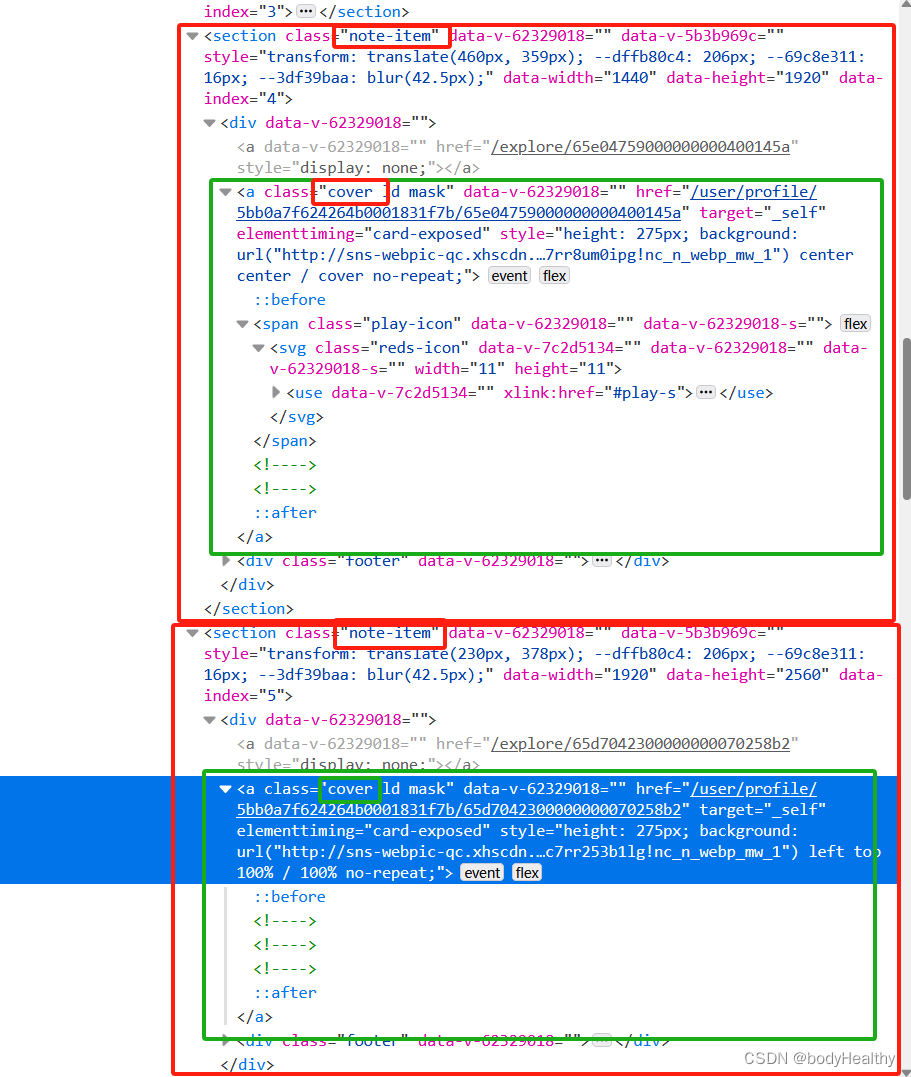
为了获取博主的全部作品数据,在登录的状态下访问目标博主页面,在控制台中注入JavaScript 脚本(在没有滚动过页面的情况下)。该脚本不断滚动页面到最底部,每次滚动一段距离后,都获取每一个作品的信息(通过a标签的 href 获取到作品页URL;通过判断a标签是否有一个 class='play-icon' 的后代元素来判断是图文还是视频类型的作品,如果有该标签就是视频作品,反之则是图文作品)。
将作品页 URL 作为键,作品是视频作品还是图文作品作为值,添加到 js 对象中。
显示完所有的作品,即滚动到最底部时,将所有获取到的作品信息导出为 txt 文件。
在控制台中执行:
// 页面高度
const vh = window.innerHeight
let work_obj = {}// 延迟
function delay(ms){ return new Promise(resolve => setTimeout(resolve, ms));
}async function action() { let last_height = document.body.offsetHeight;window.scrollTo(0, window.scrollY + vh * 1.5)ul = document.querySelector('#userPostedFeeds').querySelectorAll('.cover')ul.forEach((e,index)=>{// length 为 0 时是图片,为 1 时为视频work_obj[e.href] = ul[index].querySelector('.play-icon') ? 1 : 0})// 延迟500msawait delay(500);// console.log(last_height, document.body.offsetHeight)// 判断是否滚动到底部if(document.body.offsetHeight > last_height){action()}else{console.log('end')// 作品的数量console.log(Object.keys(work_obj).length)// 转换格式,并下载为txt文件var content = JSON.stringify(work_obj); var blob = new Blob([content], {type: "text/plain;charset=utf-8"}); var link = document.createElement("a"); link.href = URL.createObjectURL(blob); link.download = "xhs_works.txt"; link.click();}
}action()写出的 txt 文件内容如下:

3、在 Python 中读入该文件并做准备工作
# 获取当前时间
def get_current_time():now = datetime.now()format_time = now.strftime("_%Y-%m-%d__%H-%M-%S-%f__")return format_time# 下载的作品保存的路径,以作者主页的 id 号命名
ABS_BASE_URL = f'G:\\639476c10000000026006023'# 检查作品是否已经下载过
def check_download_or_not(work_id, is_pictures):end_str = 'pictures' if is_pictures else 'video'# work_id 是每一个作品的目录,检查目录是否存在并且是否有内容,则能判断对应的作品是否被下载过path = f'{ABS_BASE_URL}/{work_id}-{end_str}'if os.path.exists(path) and os.path.isdir(path):if os.listdir(path):return Truereturn False# 下载资源
def download_resource(url, save_path):response = requests.get(url, stream=True)if response.status_code == 200:with open(save_path, 'wb') as file:for chunk in response.iter_content(1024):file.write(chunk)读入文件,判断作品数量然后进行任务分配:
# 读入文件
content = ''
with open('./xhs_works.txt', mode='r', encoding='utf-8') as f:content = json.load(f)# 转换成 [[href, is_pictures],[href, is_pictures],...] 类型
# 每一维中分别是作品页的URL、作品类型
url_list = [list(pair) for pair in content.items()]# 有多少个作品
length = len(url_list)if length > 3:ul = [url_list[0: int(length / 3) + 1], url_list[int(length / 3) + 1: int(length / 3) * 2 + 1],url_list[int(length / 3) * 2 + 1: length]]# 开启三个线程并分配任务for child_ul in ul:thread = threading.Thread(target=thread_task, args=(child_ul,))thread.start()
else:thread_task(url_list)若使用多线程,每一个线程处理自己被分配到的作品列表:
# 每一个线程遍历自己分配到的作品列表,进行逐项处理
def thread_task(ul):for item in ul:href = item[0]is_pictures = (True if item[1] == 0 else False)res = work_task(href, is_pictures)if res == 0: # 被阻止正常访问break处理每一项作品:
# 处理每一项作品
def work_task(href, is_pictures):# href 中最后的一个路径参数就是博主的idwork_id = href.split('/')[-1]# 判断是否已经下载过该作品has_downloaded = check_download_or_not(work_id, is_pictures)# 没有下载,则去下载if not has_downloaded:if not is_pictures:res = deal_video(work_id)else:res = deal_pictures(work_id)if res == 0:return 0 # 无法正常访问else:print('当前作品已被下载')return 2return 14、处理图文类型作品
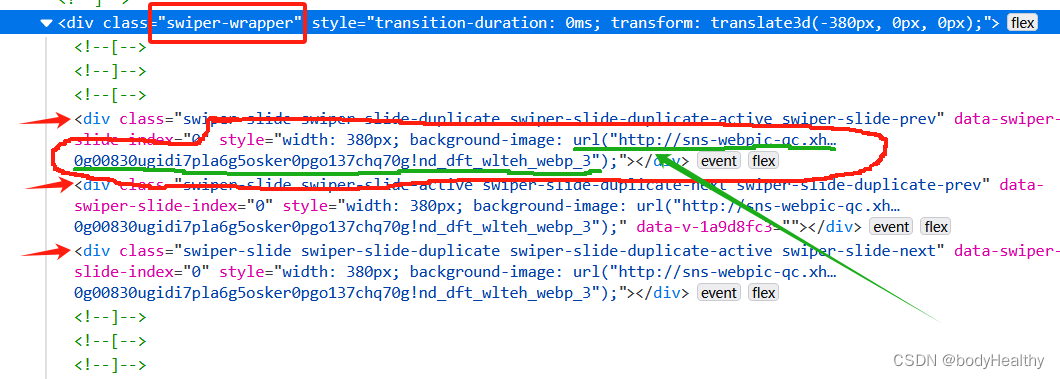
对于图文类型,每一张图片都作为 div 元素的背景图片进行展示,图片对应的 URL 在 div 元素的 style 中。 可以先获取到 style 的内容,然后根据圆括号进行分隔,最后得到图片的地址。
这里拿到的图片是没有水印的。
# 处理图片类型作品的一系列操作
def download_pictures_prepare(res_links, path, date):# 下载作品到目录index = 0for src in res_links:download_resource(src, f'{path}/{date}-{index}.webp')index += 1# 处理图片类型的作品
def deal_pictures(work_id):# 直接 requests 请求回来,style 是空的,使用 webdriver 获取当前界面的源代码temp_driver = webdriver.Chrome()temp_driver.set_page_load_timeout(5)temp_driver.get(f'https://www.xiaohongshu.com/explore/{work_id}')sleep(1)try:# 如果页面中有 class='feedback-btn' 这个元素,则表示不能正常访问temp_driver.find_element(By.CLASS_NAME, 'feedback-btn')except NoSuchElementException: # 没有该元素,则说明能正常访问到作品页面WebDriverWait(temp_driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, 'swiper-wrapper')))# 获取页面的源代码source_code = temp_driver.page_sourcetemp_driver.quit()html = BeautifulSoup(source_code, 'lxml')swiper_sliders = html.find_all(class_='swiper-slide')# 当前作品的发表日期date = html.find(class_='bottom-container').span.string.split(' ')[0].strip()# 图片路径res_links = []for item in swiper_sliders:# 在 style 中提取出图片的 urlurl = item['style'].split('url(')[1].split(')')[0].replace('"', '').replace('"', '')if url not in res_links:res_links.append(url)#为图片集创建目录path = f'{ABS_BASE_URL}/{work_id}-pictures'try:os.makedirs(path)except FileExistsError:# 目录已经存在,则直接下载到该目录下download_pictures_prepare(res_links, path, date)except Exception as err:print(f'deal_pictures 捕获到其他错误:{err}')else:download_pictures_prepare(res_links, path, date)finally:return 1except Exception as err:print(f'下载图片类型作品 捕获到错误:{err}')return 1else:print(f'访问作品页面被阻断,下次再试')return 05、处理视频类型作品
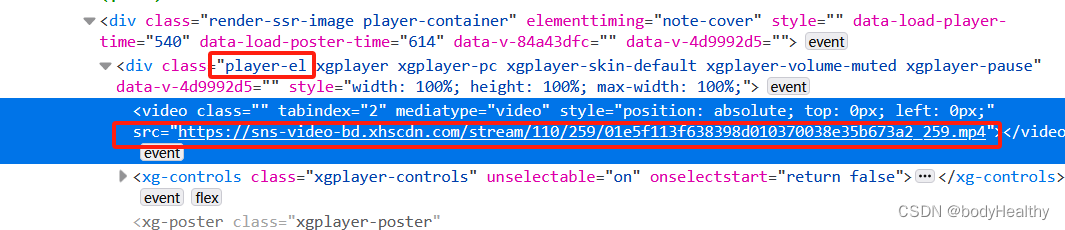
获取到的视频有水印。
# 处理视频类型的作品
def deal_video(work_id):temp_driver = webdriver.Chrome()temp_driver.set_page_load_timeout(5)temp_driver.get(f'https://www.xiaohongshu.com/explore/{work_id}')sleep(1)try:temp_driver.find_element(By.CLASS_NAME, 'feedback-btn')except NoSuchElementException:WebDriverWait(temp_driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, 'player-container')))source_code = temp_driver.page_sourcetemp_driver.quit()html = BeautifulSoup(source_code, 'lxml')video_src = html.find(class_='player-el').video['src']# 作品发布日期date = html.find(class_='bottom-container').span.string.split(' ')[0].strip()# 为视频作品创建目录,以 作品的id号 + video 命名目录path = f'{ABS_BASE_URL}/{work_id}-video'try:os.makedirs(path)except FileExistsError:download_resource(video_src, f'{path}/{date}.mp4')except Exception as err:print(f'deal_video 捕获到其他错误:{err}')else:download_resource(video_src, f'{path}/{date}.mp4')finally:return 1except Exception as err:print(f'下载视频类型作品 捕获到错误:{err}')return 1else:print(f'访问视频作品界面被阻断,下次再试')return 06、异常访问而被中断的现象
频繁的访问和下载资源会被重定向到如下的页面,可以通过获取到该页面的特殊标签来判断是否被重定向连接,如果是,则及时中断访问,稍后再继续。
使用 webdriver 访问页面,页面打开后,在 try 中查找是否有 class='feedback-btn' 元素(即下方的 我要反馈 的按钮)。如果有该元素,则在 else 中进行提示并返回错误码退出任务。如果找不到元素,则会触发 NoSuchElementException 的错误,在 except 中继续任务即可。

try:temp_driver.find_element(By.CLASS_NAME, 'feedback-btn')except NoSuchElementException:# 正常访问到作品页面passexcept Exception as err:# 其他的异常return 1else:# 不能访问到作品页面return 07、完整参考代码
import json
import threading
import requests,os
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from datetime import datetime
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup# 获取当前时间
def get_current_time():now = datetime.now()format_time = now.strftime("_%Y-%m-%d__%H-%M-%S-%f__")return format_time# 下载的作品保存的路径,以作者主页的 id 号命名
ABS_BASE_URL = f'G:\\639476c10000000026006023'# 检查作品是否已经下载过
def check_download_or_not(work_id, is_pictures):end_str = 'pictures' if is_pictures else 'video'# work_id 是每一个作品的目录,检查目录是否存在并且是否有内容,则能判断对应的作品是否被下载过path = f'{ABS_BASE_URL}/{work_id}-{end_str}'if os.path.exists(path) and os.path.isdir(path):if os.listdir(path):return Truereturn False# 下载资源
def download_resource(url, save_path):response = requests.get(url, stream=True)if response.status_code == 200:with open(save_path, 'wb') as file:for chunk in response.iter_content(1024):file.write(chunk)# 处理图片类型作品的一系列操作
def download_pictures_prepare(res_links, path, date):# 下载作品到目录index = 0for src in res_links:download_resource(src, f'{path}/{date}-{index}.webp')index += 1# 处理图片类型的作品
def deal_pictures(work_id):# 直接 requests 请求回来,style 是空的,使用 webdriver 获取当前界面的源代码temp_driver = webdriver.Chrome()temp_driver.set_page_load_timeout(5)temp_driver.get(f'https://www.xiaohongshu.com/explore/{work_id}')sleep(1)try:temp_driver.find_element(By.CLASS_NAME, 'feedback-btn')except NoSuchElementException:WebDriverWait(temp_driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, 'swiper-wrapper')))source_code = temp_driver.page_sourcetemp_driver.quit()html = BeautifulSoup(source_code, 'lxml')swiper_sliders = html.find_all(class_='swiper-slide')# 当前作品的发表日期date = html.find(class_='bottom-container').span.string.split(' ')[0].strip()# 图片路径res_links = []for item in swiper_sliders:url = item['style'].split('url(')[1].split(')')[0].replace('"', '').replace('"', '')if url not in res_links:res_links.append(url)#为图片集创建目录path = f'{ABS_BASE_URL}/{work_id}-pictures'try:os.makedirs(path)except FileExistsError:# 目录已经存在,则直接下载到该目录下download_pictures_prepare(res_links, path, date)except Exception as err:print(f'deal_pictures 捕获到其他错误:{err}')else:download_pictures_prepare(res_links, path, date)finally:return 1except Exception as err:print(f'下载图片类型作品 捕获到错误:{err}')return 1else:print(f'访问作品页面被阻断,下次再试')return 0# 处理视频类型的作品
def deal_video(work_id):temp_driver = webdriver.Chrome()temp_driver.set_page_load_timeout(5)temp_driver.get(f'https://www.xiaohongshu.com/explore/{work_id}')sleep(1)try:# 访问不到正常内容的标准元素temp_driver.find_element(By.CLASS_NAME, 'feedback-btn')except NoSuchElementException:WebDriverWait(temp_driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, 'player-container')))source_code = temp_driver.page_sourcetemp_driver.quit()html = BeautifulSoup(source_code, 'lxml')video_src = html.find(class_='player-el').video['src']# 作品发布日期date = html.find(class_='bottom-container').span.string.split(' ')[0].strip()# 为视频作品创建目录path = f'{ABS_BASE_URL}/{work_id}-video'try:os.makedirs(path)except FileExistsError:download_resource(video_src, f'{path}/{date}.mp4')except Exception as err:print(f'deal_video 捕获到其他错误:{err}')else:download_resource(video_src, f'{path}/{date}.mp4')finally:return 1except Exception as err:print(f'下载视频类型作品 捕获到错误:{err}')return 1else:print(f'访问视频作品界面被阻断,下次再试')return 0# 检查作品是否已经下载,如果没有下载则去下载
def work_task(href, is_pictures):work_id = href.split('/')[-1]has_downloaded = check_download_or_not(work_id, is_pictures)# 没有下载,则去下载if not has_downloaded:if not is_pictures:res = deal_video(work_id)else:res = deal_pictures(work_id)if res == 0:return 0 # 受到阻断else:print('当前作品已被下载')return 2return 1def thread_task(ul):for item in ul:href = item[0]is_pictures = (True if item[1] == 0 else False)res = work_task(href, is_pictures)if res == 0: # 被阻止正常访问breakif __name__ == '__main__':content = ''with open('xhs_works.txt', mode='r', encoding='utf-8') as f:content = json.load(f)url_list = [list(pair) for pair in content.items()]length = len(url_list)if length > 3:ul = [url_list[0: int(length / 3) + 1], url_list[int(length / 3) + 1: int(length / 3) * 2 + 1],url_list[int(length / 3) * 2 + 1: length]]for child_ul in ul:thread = threading.Thread(target=thread_task, args=(child_ul,))thread.start()else:thread_task(url_list)