深度强化学习(五)(蒙特卡洛与自举)
一.蒙特卡洛与自举
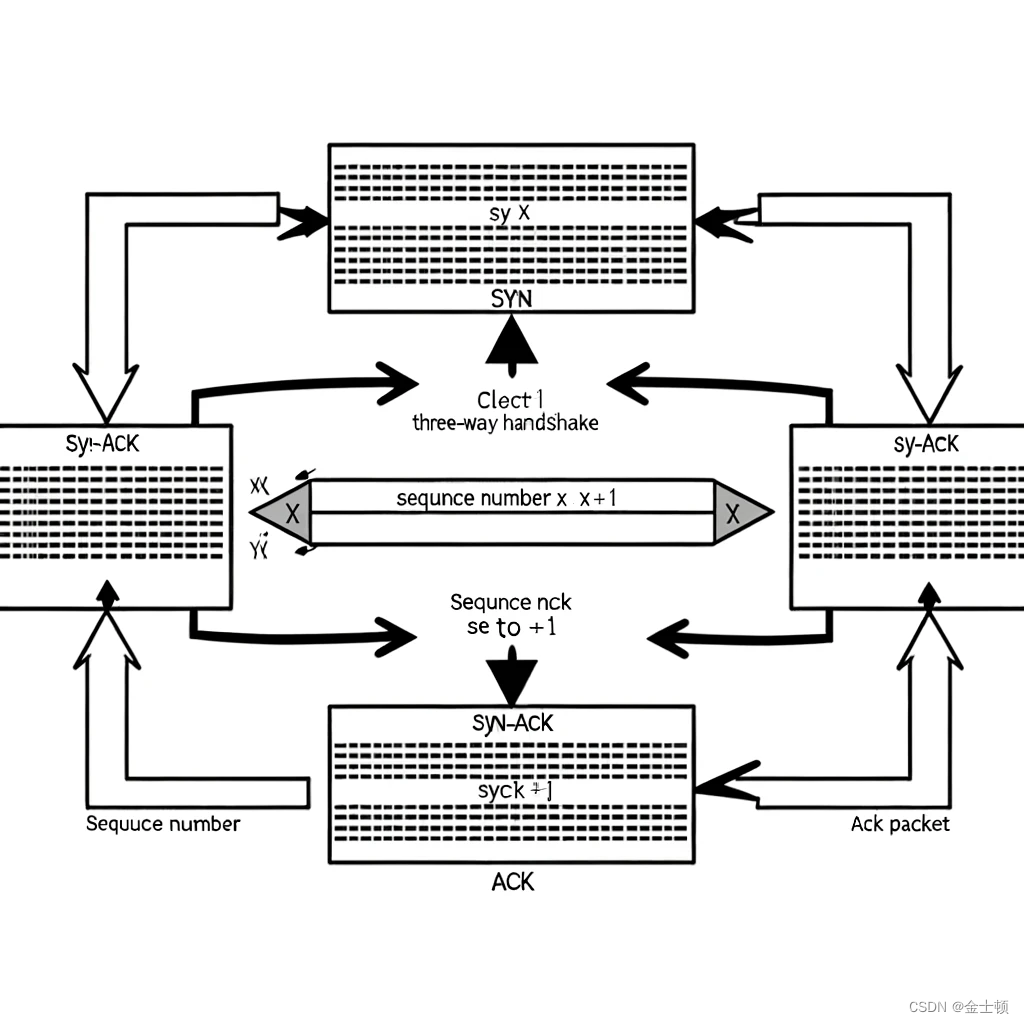
上一节介绍了多步 TD 目标。单步 TD 目标、回报是多步 TD 目标的两种特例。如下图所示, 如果设 m = 1 m=1 m=1, 那么多步 TD 目标变成单步 T D \mathrm{TD} TD 目标。如果设 m = n − t + 1 m=n-t+1 m=n−t+1, 那么多步 TD 目标变成实际观测的回报 u t u_t ut 。

二.蒙特卡洛
我们可以将一局游戏进行到底, 观测到所有的奖励 r 1 , ⋯ , r n r_1, \cdots, r_n r1,⋯,rn, 然后计算回报 u t = ∑ i = 0 n − t γ i r t + i u_t=\sum_{i=0}^{n-t} \gamma^i r_{t+i} ut=∑i=0n−tγirt+i 。拿 u t u_t ut 作为目标, 鼓励价值网络 q ( s t , a t ; w ) q\left(s_t, a_t ; \boldsymbol{w}\right) q(st,at;w)接近 u t u_t ut 。定义损失函数:
L ( w ) = 1 2 [ q ( s t , a t ; w ) − u t ] 2 . L(\boldsymbol{w})=\frac{1}{2}\left[q\left(s_t, a_t ; \boldsymbol{w}\right)-u_t\right]^2 . L(w)=21[q(st,at;w)−ut]2.
然后做一次梯度下降更新 w \boldsymbol{w} w :
w ← w − α ⋅ ∇ w L ( w ) , \boldsymbol{w} \leftarrow \boldsymbol{w}-\alpha \cdot \nabla_{\boldsymbol{w}} L(\boldsymbol{w}), w←w−α⋅∇wL(w),
这样可以让价值网络的预测 q ( s t , a t ; w ) q\left(s_t, a_t ; \boldsymbol{w}\right) q(st,at;w) 更接近 u t u_t ut 。这种训练价值网络的方法被称作“蒙特卡洛”
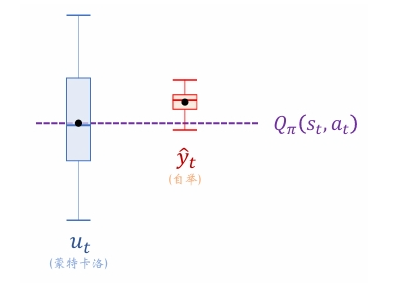
蒙特卡洛的好处是无偏性: u t u_t ut 是 Q π ( s t , a t ) Q_\pi\left(s_t, a_t\right) Qπ(st,at) 的无偏估计。由于 u t u_t ut 的无偏性, 拿 u t u_t ut 作为目标训练价值网络, 得到的价值网络也是无偏的。
蒙特卡洛的缺点是方差大。随机变量 U t U_t Ut 依赖于 S t + 1 , A t + 1 , ⋯ , S n , A n S_{t+1}, A_{t+1}, \cdots, S_n, A_n St+1,At+1,⋯,Sn,An 这些随机变量, 其中不确定性很大。观测值 u t u_t ut 虽然是 U t U_t Ut 的无偏估计, 但可能实际上离 E [ U t ] \mathbb{E}\left[U_t\right] E[Ut] 很远。因此,拿 u t u_t ut 作为目标训练价值网络,收敛会较慢。
三.自举
在强化学习中,“自举”的意思是“用一个估算去更新同类的估算”,。SARSA使用的单步TD目标定义为:
y ^ t = r t + γ ⋅ q ( s t + 1 , a t + 1 ; w ) ⏟ 价值网络做出的估计 \widehat{y}_t=r_t+\underbrace{\gamma \cdot q\left(s_{t+1}, a_{t+1} ; \boldsymbol{w}\right)}_{\text {价值网络做出的估计 }} y t=rt+价值网络做出的估计 γ⋅q(st+1,at+1;w)
SARSA 鼓励 q ( s t , a t ; w ) q\left(s_t, a_t ; \boldsymbol{w}\right) q(st,at;w) 接近 y ^ t \widehat{y}_t y t, 所以定义损失函数
L ( w ) = 1 2 [ q ( s t , a t ; w ) − y ^ t ⏟ 让价值网络拟合 y ^ t ] 2 . L(\boldsymbol{w})=\frac{1}{2}[\underbrace{q\left(s_t, a_t ; \boldsymbol{w}\right)-\widehat{y}_t}_{\text {让价值网络拟合 } \widehat{y}_t}]^2 . L(w)=21[让价值网络拟合 y t q(st,at;w)−y t]2.
自举的好处是方差小。单步 TD 目标的随机性只来自于 S t + 1 S_{t+1} St+1 和 A t + 1 A_{t+1} At+1, 而回报 U t U_t Ut 的随机性来自于 S t + 1 , A t + 1 , ⋯ , S n , A n S_{t+1}, A_{t+1}, \cdots, S_n, A_n St+1,At+1,⋯,Sn,An 。很显然, 单步 T D \mathrm{TD} TD 目标的随机性较小, 因此方差较小。用自举训练价值网络,收敛比较快。
自举的缺点是有偏差。价值网络 q ( s , a ; w ) q(s, a ; \boldsymbol{w}) q(s,a;w) 是对动作价值 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a) 的近似。因我们认为 y ^ t \hat y_t y^t是真实估计,是一常数,如果本身 y ^ t \hat y_t y^t就是有偏差的,则价值网络就会在逼近 y ^ t \hat y_t y^t中学习放大这一偏差。
也就是说, 自举会让偏差从 ( s t + 1 , a t + 1 ) \left(s_{t+1}, a_{t+1}\right) (st+1,at+1) 传播到 ( s t , a t ) \left(s_t, a_t\right) (st,at) 。