一、前言
1、文件的宏观理解
文件在哪呢?
从广义上理解,键盘、显示器、网卡、声卡、显卡、磁盘等几乎所有的外设都可以称之为文件,因为 “Linux 下,一切皆文件”。
从狭义上的理解,文件在磁盘(硬件)上放着,只有操作系统才能真正的去访问磁盘。磁盘是一种永久存储介质,不会受断电的影响,磁盘也是外设之一,所以对文件的所有操作都是对外设的输入输出,简称 IO(Input、Output)。
2、文件的操作范畴
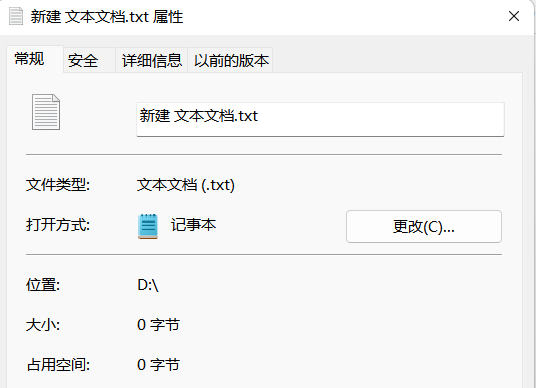
当我们在 Windows 下新建一个文本文件,它是否占用磁盘空间?
虽然它是一个空的文本文件,并且这里显示是 0KB,但它依旧会占用磁盘空间,因为一个文件新建出来之后,它的很多数据信息都需要维护,其中包括文件名、修改日期、类型、大小、权限等。
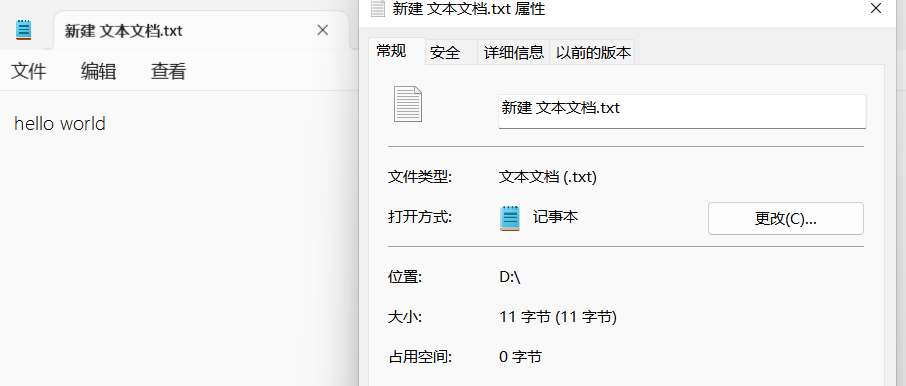
当我们对空文本写入字符时,可以直观的看到文本的大小发生了变化。
所以说一个文件 = 文件内容 + 属性(元数据),也就是说我们要学习的所有的文件操作无外乎就是对文件的内容或内容进行操作。
- 如果想往文件里写入 "hello world"、'a',这叫作对文件内容进行操作; fread、fwrite、fgets、fputs、fgetc、fputc 都是对文件内容进行操作。
- 如果想更改文件权限、拥有者所属组、文件名等,这叫作对文件属性进行操作;fseek、ftell、rewind 都是对文件属性进行操作。
3、系统看待文件访问
以前写的 fread、fwrite 等相关代码访问文件的 C 程序 ➡ 经过编译形成 .exe(可执行程序) ➡ 双击或 ./ 运行程序,把程序加载到内存中。所以对文件的访问本质上就是进程对文件的访问。

我们在操作文件时所使用到的接口,例如 fread、fwrite,这是 C 语言给我们提供的接口,而要操作的文件是在磁盘这个硬件上,同时我们很明确磁盘的管理者是操作系统,普通用户不可能直接去访问硬件,在计算机体系结构中用户是通过不同语言所提供的这些被封装过的接口来贯穿式的访问硬件(用户 ➡ 库函数 ➡ 系统调用接口 ➡ 操作系统 ➡ 驱动程序 ➡ 硬件)。导致了不同语言有不同的语言级别的文件访问接口,但封装的都是系统接口,所以本质上并不是 C 语言帮我们把数据写到磁盘文件中,真正干活的是操作系统所提供的与文件相关的系统调用接口。
为什么要学习 OS 层面上的文件接口呢?
因为这样的接口只有一套(OS 只有一个)。
如果语言不提供对文件系统接口的封装,那是不是所有访问文件的操作都必须直接使用 OS 的接口?
是。
选择使用语言的用户要不要访问文件呢?
要。一旦使用系统接口编写文件代码,那么这份代码就无法在其它平台直接运行了,因为其不具备跨平台性。
显示器是硬件吗?printf 向显示器打印也是一种写入,为什么不觉得奇怪呢?
是的。 因为我们往显示器上打印时随即能够看到结果,而往文件里写入时并不直观,具有滞后性。其实这与磁盘写入到文件里没有本质区别。
4、如何理解 “Linux 下,一切皆文件”
默认情况下,标准输入是键盘文件,标准输出是显示器文件,标准错误是显示器文件。
而这三个本身是硬件,如何理解 “Linux 中,一切皆文件”?
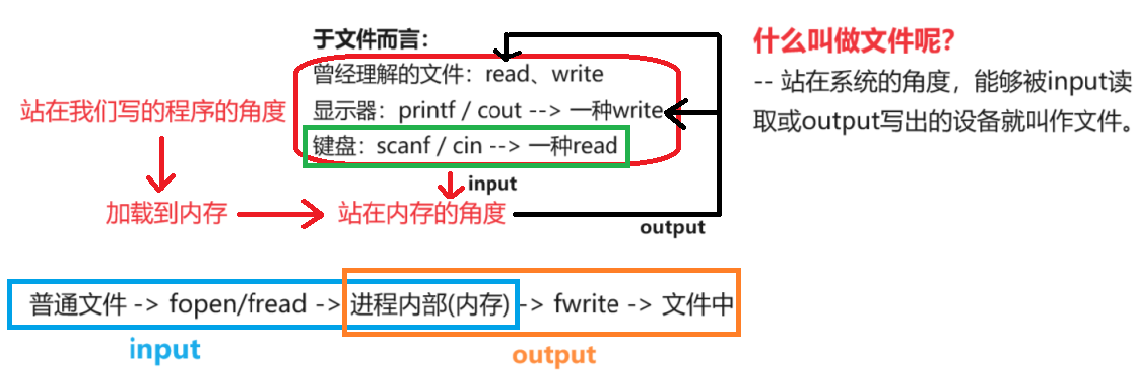
- 所有的外设硬件本质对应的核心操作无外乎是 read / write。对于键盘文件,它的读方法就是从键盘读取数据到内存;它的写方法设置为空,因为没有把数据写到键盘上这种说法。
- 对于显示器文件,如调用 printf 函数和 cout 时,操作系统是要往显示器上写入的,本质就是一种 write。理论上来说,操作系统是不会往显示器上读数据的,所以设置为空吗?不对,我们通过键盘在命令行输入 ls 命令显示在 Xshell 上,系统要执行命令时不就是应该往显示器上读数据然后再执行吗?如果是往显示器上读,那么我们在输入密码时,密码是不显示的,系统也能往显示器上读吗?其实我们输入的命令是通过键盘输入的,所以系统应该是往键盘读数据。至于用户能看到输入的命令,仅仅是为了方便用户,操作系统把从键盘输入的数据一份给了系统进行读取,一份给了显示器方便用户查看。
- 所以不同的硬件对应的读写方式肯定是不一样的,但是它们都有自己的 read 和 write 方法。也就是说,这里的硬件可以统一看作成一种特殊的文件。比如这里设计一种结构:struct file,它包括文件的属性、文件的操作或方法等,Linux 说一切皆文件,Linux 操作系统就必须要能够保证这点。在 C 语言中,怎么让一个结构体既有属性又有方法呢?函数指针。此时每一个硬件都对应这样一个结构,硬件一旦数量很多,操作系统就需要对它们进行管理 —— 先描述,再组织。所谓的描述就是 struct file;而组织就是要把每一个硬件对应的结构体关联起来,并用 file header 指向。所以在操作系统的角度,它所看到的就是一切皆文件,也就是说所有硬件的差异经过描述就变成了同一种东西,只不过当具体访问某种设备时,使用函数指针执行不同的方法达到了不同的行为。现在就能理解为什么可以把键盘、显示器这些设备当作文件,因为本质不同,设备的读写方法是有差异的,但我们可以通过函数指针让不同的硬件包括普通文件在操作系统看来是同样的方法、同样的文件。

二、简单回顾 C 文件接口及相关文件操作
1、fopen
#include <stdio.h>FILE *fopen(const char *path, const char *mode);
FILE *fdopen(int fd, const char *mode);
FILE *freopen(const char *path, const char *mode, FILE *stream); (1)打开文件的方式
r Open text file for reading. The stream is positioned at the beginning of the file.r+ Open for reading and writing.The stream is positioned at the beginning of the file.w Truncate(缩短) file to zero length or create text file for writing.The stream is positioned at the beginning of the file.w+ Open for reading and writing.The file is created if it does not exist, otherwise it is truncated.The stream is positioned at the beginning of the file.a Open for appending (writing at end of file). The file is created if it does not exist. The stream is positioned at the end of the file.a+ Open for reading and appending (writing at end of file).The file is created if it does not exist. The initial file positionfor reading is at the beginning of the file, but output is always appended to the end of the file.2、写文件



虽然没有 ./ 指定路径,但它还是在当前路径下新建文件了。因为每个进程都有一个内置的属性 cwd(可以在 /proc 目录下查找对应进程的属性信息),cwd 可以让进程知道自己当前所处的路径。这也就解释了在 VS 中不指明路径,它也能新建对应的文件在对应的路径的原因。所有,进程在哪个路径运行,新建的文件就在哪个路径。
什么叫做当前路径?
当一个进程运行起来时,每个进程都会记录自己当前所处的工作路径。


(1)❌错误写法:fwrite(msg, strlen(msg)+1, 1, fp);

strlen(msg)+1 会导致乱码,也就是把 '\0' 也追加造成的,因为 '\0' 结尾是 C 语言的规定,和文件无关,文件不用遵守。


这里 cat myfile.txt 并没有看到乱码的原因是:'\0' 是不可见的,所以在这里只有 vim myfile.txt 才会看到乱码。
size_t fwrite (const void* ptr, size_t size, size_t count, FILE* stream);
- size 表示你要写入的基本单元是多大(以字节为单位),count 表示你要写入几个这样的基本单元。换而言之,最终往文件中写的字节数 = size*count。比如要写入 10 个字节,那么 size=1 && count=10、size=2 && count=5,不过一般建议把 size 写大一点,count 写小一点。
- fwrite 的返回值是成功写入元素的个数,也就是期望写 count 个,每个是 size,那么实际最后返回的就是你实际写入成功了几组 size。比如你期望 size 是 10,count 是 1,那么大部分情况下都会把这 1 个单元都写入的,写入成功且返回值是 1;这里的你期望写入多少和实际写入多少就好比下面这个例子:
小明:爸,我想要 10 块钱。(这是期望的)
爸:我只有 5 块钱,给你 3 块钱吧。(这是实际的)
当然,这里是后面网络部分才会涉及到,目前在往磁盘文件中写入时,大部分情况下硬件设备是能够满足我们的要求的,所以这里不关心 fwrite 的返回值。
(2)现象


注意:fopen 以 "w" 方式打开文件,默认先将文件内容清空(在 fwrite 之前)。

tips:可以把 > 看成一个命令,向文件写入内容,直接输入命令:>log.txt 的话就相当于先打开文件清空。
3、读文件


perror 函数可以打印出错误信息。
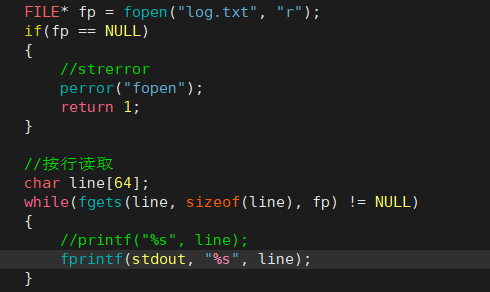

(1)写一个 cat 命令


4、追加文件


注意:fopen 以 "a" 方式打开文件,表示直接往文件末尾追加,不断地向文件中写入新增内容。
5、输出信息到显示器的方法

#include <stdio.h>
#include <string.h>int main()
{const char *msg = "hello fwrite\n";fwrite(msg, strlen(msg), 1, stdout);printf("hello printf\n");fprintf(stdout, "hello fprintf\n");return 0;
}6、三个标准输入输出流:stdin & stdout & stderr

- 这里需要理清一个概念,不是任何 C 程序运行会默认打开,而是进程在启动时会默认打开三个 “文件”,分别是 stdin,stdout,stderr。
- 仔细观察发现这三个流的类型都是 FILE*,与 fopen 返回值类型相同,都是文件指针。
这里可以直接使用 fwrite 这样的接口,向显示器写数据的原因是因为 C 进程一运行,stdout 就默认打开了。同理 fread 能从键盘读数据的原因是 C 进程一运行,stdin 就默认打开了。
也就是说 C 接口除了对普通文件进行读写之外(需要手动打开),还可以对 stdin、stdout、stderr 进行读写(不需要手动打开)。
为什么 C 进程运行就会默认打开 stdin、stdout、stderr?
scanf -> 键盘、printf -> 显示器、perror -> 显示器
如果不默认打开,那么我们是不能直接调用这些接口的,所以默认打开的原因是便于我们直接上手,且大部分编码都会有输入输出的需求。也就是说,scanf、printf、perror 这样的库函数,底层一定使用了 stdin、stdout、stderr 文件指针来完成对应不同的功能。此外还有一些接口和 printf、scanf 很像,它们本身是把使用的过程暴露出来,比如 fprintf(stdout, “%d, %d, %c\n”, 9, 17, a)。
仅仅只是 C 这样吗?
这里可以肯定的是,不仅是 C 进程运行会打开 stdin、stdout、stderr,其它语言几乎都是这样的,C++ 是 cin、cout、cerr。
所以我们可以发现一个现象,不管是学习什么语言,第一个程序永远是 "Hello World!"。这里说几乎所有语言都这样也就意味着不仅仅是语言层提供的功能了。比如一条人山人海的路从头到尾只有个别商贩在摆摊,那么我们认为这是商贩的个人行为,当地的管理者是排斥这种行为的;但如果一整路从头到尾都有商贩在摆摊,那么我们就认为是当地的管理者支持这种行为的。同样,不同语言彼此之间并没有进行过任何商量,而最终都会默认打开,所以这不仅仅是语言支持,也一定是操作系统支持的。
三、系统文件 I/O
1、为什么要学习文件系统接口
在 C 语言中要访问硬件必须贯穿计算机体系结构,而 fopen、fclose 等系列的库函数,其底层都要调用系统接口,这里它们对应的系统接口也很好记忆 —— 去掉 "f" 即为系统接口。不同语言所提供的接口本质上是对系统接口进行封装,学习封装的接口本质上学的就是语言级别的接口。也就是要学习不同的语言,就得学会不同语言操作文件的方法,但实际上对特定的操作系统最终都会调用系统所提供的接口。
接下来学习系统接口,我们要学习它的原因主要有两点:
- 只要学懂了系统接口,后面再学习其它语言上的文件操作,就只是学习它的语法,底层不需要再学习了。
- 这些系统接口更贴近于系统,所以我们就能通过接口来学习文件的若干特性。

四、系统调用接口介绍
1、man open
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);使用 open 需要包含三个头文件,它有两个版本:
- 以 flags 方式打开 pathname。(读取)
- 以 flags 方式打开 pathname,并设置 mode 权限。(创建)
flags 可以是 O_RDONLY(read-only)、O_WRONLY(write-only)、O_RDWR(read/write),且必须包含以上访问模式之一,此外访问模式还可以带上 ‘|’ 标志位。
- pathname:要打开或创建的目标文件。
- flags:打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行 “或” 运算,构成 flags。
参数:
- O_RDONLY:只读打开
- O_WRONLY:只写打开
- O_RDWR:读,写打开
这三个常量,必须指定一个且只能指定一个
- O_CREAT:若文件不存在则创建它。需要使用 mode 选项来指明新文件的访问权限。
- O_APPEND:追加写。
返回值:
- 成功:新打开的文件描述符。
- 失败:-1。
(1)操作系统传递标志位的方案

grep -ER 'O_CREAT | O_RDONLY' /usr/include/ 筛选标志位。

接着我们的 vim 标志位所在路径,发现默认是只读,而 O_CREAT 以下是使用了八进制,不管如何,它们经过转换后,最终只有一个唯一比特位。我们也可以通过组合标志位,传入多个选项。
vim /usr/include/asm-generic/fcntl.h

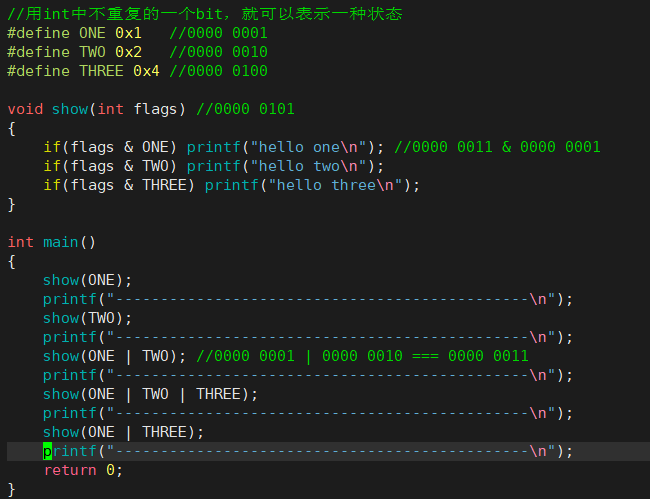

为什么传两个标志位时需要使用 ‘|’ 操作符?
O_WRONLY、 O_RDONLY、O_CREATE、O_APPEND 都是标志位。
如果我们自己在设计 open 接口时,这里通常是使用整数,0 表示不要,1 表示要。
而系统是怎么做的呢?一个整数有 32 个比特位,所以一个标志位传一个整数显得有点浪费,所以我们可以让一个标志位占一个比特位:用最低比特位来表示是否读、第二低比特位表示是否写、第三低比特位表示是否追加等等。之后我们可以定义一些宏,将来传入了 flags,系统要检测是什么标志位,它只需要 falgs & O_RDONLY,这也解释了为什么上面需要两个标志位时是 O_WRONLY|O_APPEND。
语言都要对系统接口做封装,本质是兼容自身语法特性,系统调用使用成本较高且不具备可移植性,那么在封装后就可以在语言层屏蔽操作系统的底层差异,从而实现语言本身的可移植性。如果所有语言都用 open 这一套接口, 那么这套接口在 Windows 下是不能运行的,所以我们写的程序是不具备可移植性的,而 fopen 能在 Windows 和 Linux 下运行的原因是 C 语言对 open 进行了封装,也就是说这些接口会自动根据平台来选择底层对应的文件接口。同样的,fopen 在 Windows 和 Linux 中头文件的实现也是不同的 。
2、open 函数的返回值
- 上面的 fopen fclose fread fwrite 都是 C 标准库当中的函数,我们称之为库函数(libc)。
- open close read write lseek 都属于系统提供的接口,称之为系统调用接口。

系统调用接口和库函数的关系,一目了然。那么可以认为,f# 系列的函数都是对系统调用的封装,方便二次开发。

在应用层看到一个很简单的动作,在系统接口层面甚至 OS 层面可能要做非常多的工作。
如果没有设置权限:
![]()

加上权限之后:









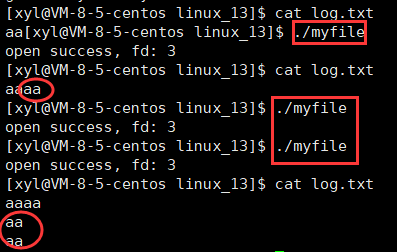


前面说到返回小于 0 的数代表 open 失败,这里显示 open 成功了,但这里为什么不从 0 开始依次返回呢?
因为它们已经被使用了,C 程序运行起来会默认打开三个文件(stdin、stdout、stderr),所以 0、1、2 分别与之对应。
为什么这里每打开一个文件所返回的文件描述符都是类似数组下标的呢?一个进程可以打开多个文件吗?
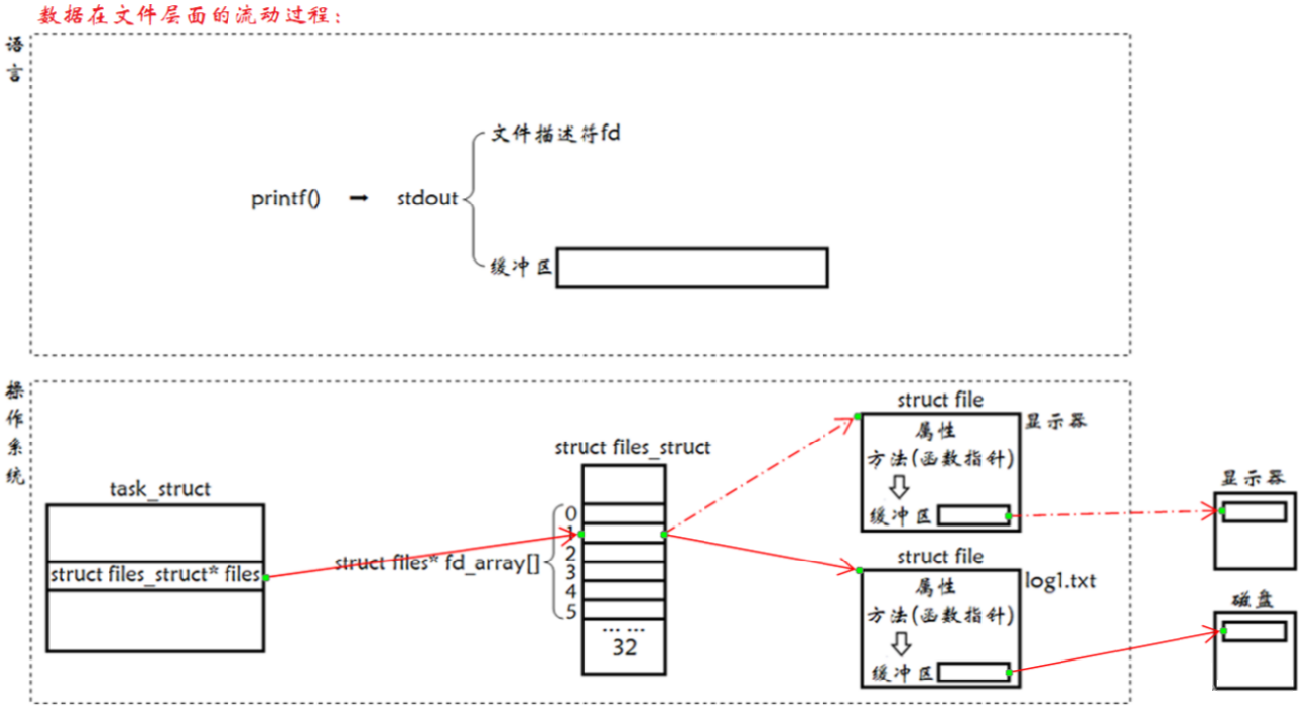
这里返回的文件描述符就是数组下标。一个进程是可以打开多个文件的,且系统内被打开的文件一定是有多个的,一般而言,进程:打开的文件 = 1:n。如果是多个进程都打开自己的文件呢?系统中会存在大量被打开的文件,那么这些多个被打开的文件,操作系统使用 “先描述,再组织” 的方式将它们管理起来,描述一个打开文件的数据结构叫做 struct file,组织一堆 struct file 就是在 task_struct 中有一个 struct files_struct* files 指针指向 struct files_struct,它的作用就是构建进程和文件之间的对应关系,其中包含了一个指针数组,这里可以理解为定长数组,struct file* fd_array[NR_OPEN_DEFAULT] ➡ #define NR_OPEN_DEFAULT BITS_PER_LONG ➡ #define BITS_PER_LONG 32。
所以用户层看到的 fd 返回值,本质上是系统中维护进程和文件对应关系的数组的下标。比如创建一个文件会多一个 struct file,再把地址存储于指针数组中最小且没有使用过的数组中,这里对应是下标 6,然后把 6 作为返回值返回给用户。所以当用户后续要对文件进行操作时就可以使用 fd 返回值作为参数,比如 read(fd) ,当前进程就会拿着 fd 去 struct files_struct* 指向的指针数组中找 fd 下标,根据 fd 下标对应的地址找到对应的文件,再从文件中找到对应的 read 方法,对 disk 中的数据进行读取或者写入。
FILE 是什么?由谁提供的?
FILE 是一个 struct 结构体,C 标准库提供的。
C 文件的库函数内部一定要调用系统调用。在系统的角度,要读写文件是一定要有 FILE,还是 fd?
fd。结合前一个问题,可以得出:在 FILE 结构体里面必定封装了 fd。
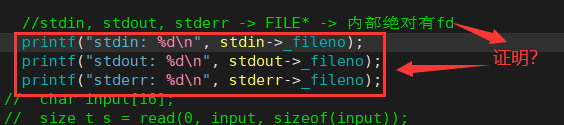


Linux 2.6 内核源码验证:
对于 file_operations,不同硬件是有不同的方法的。在大部分情况下,方法是和我们的硬件驱动匹配的。虽然如此,但最终文件通过函数指针实现你要打开的是磁盘,那就让所有的方法指向磁盘的方法,你要打开的是其它硬件,那就让所有的方法指向其它硬件的方法,而这里底层的差异在上层看来,已经被完全屏蔽了。
所以于进程而言,对所有的文件进行操作统一使用一套接口(现在我们明确了它是一组函数指针),也就是说,对进程来讲,我们的操作和属性接口统一使用 struct file 来描述,那么在进程看来就是 “一切皆文件”。上面所画的内容全部都在操作系统内部完成,而用户只需要通过 fd 来进行文件的读写。
五、文件描述符 fd
通过对 open 函数的学习,知道了文件描述符就是一个小整数。
1、0 & 1 & 2
- Linux 进程默认情况下会有 3 个缺省打开的文件描述符,分别是标准输入 0, 标准输出 1, 标准错误 2。
- 0、1、2 对应的物理设备一般是:键盘、显示器、显示器。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>int main()
{char buf[1024];ssize_t s = read(0, buf, sizeof(buf));if(s > 0){buf[s] = 0;write(1, buf, strlen(buf));write(2, buf, strlen(buf));}return 0;
}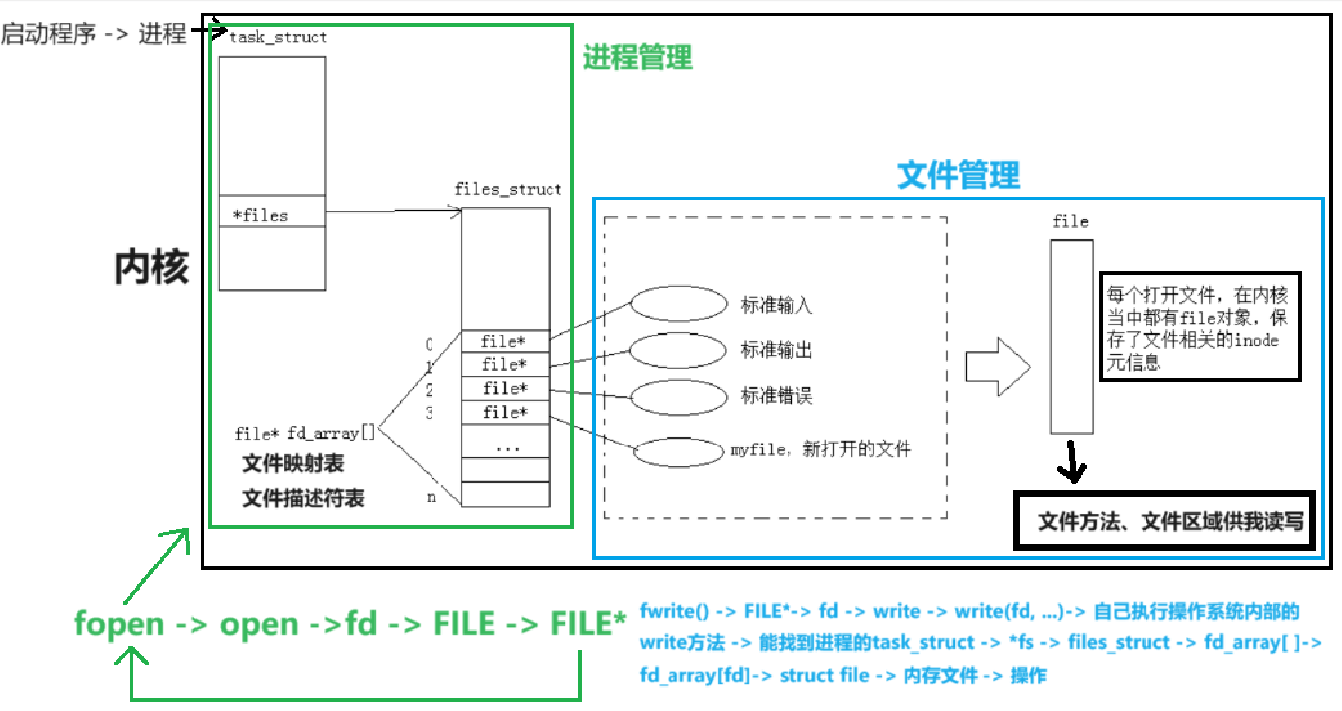
现在知道,文件描述符就是从 0 开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件,于是就有了 file 结构体,表示一个已经打开的文件对象。而进程执行 open 系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针 *files, 指向一张表 files_struct, 该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针。所以在本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件。
2、文件描述符的分配规则
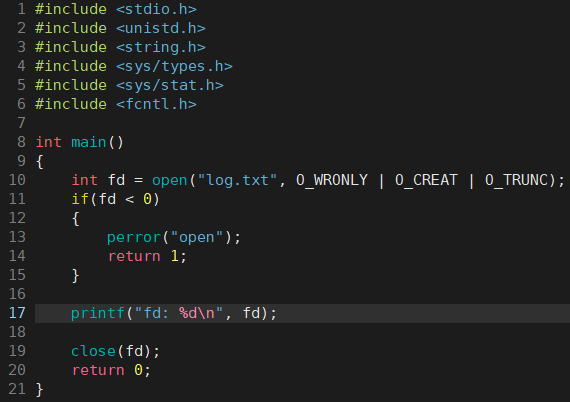
-
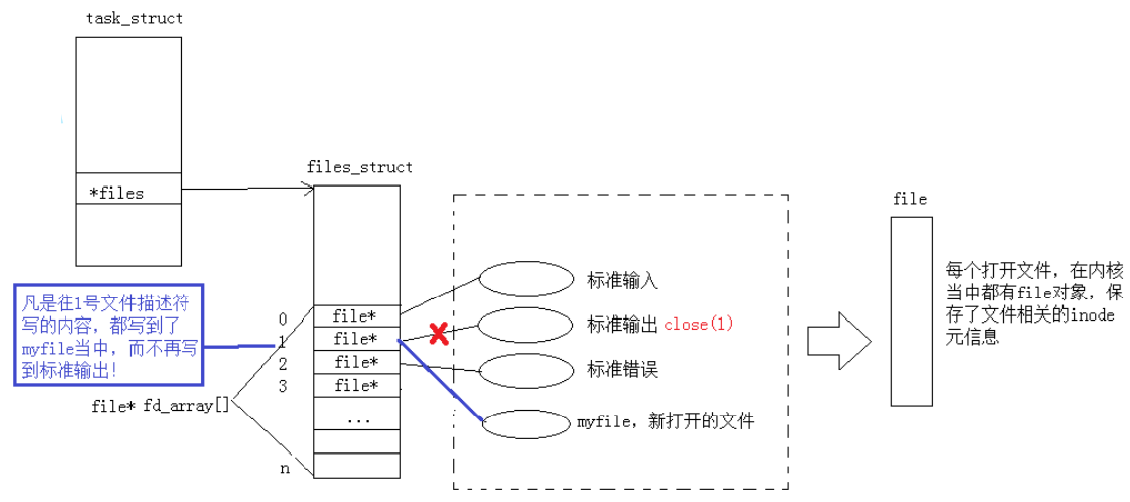
关闭 0:

- 关闭 2:

![]()
可见,文件描述符的分配规则:在 files_struct 数组当中,找到当前没有被使用的最小且没有被占用的文件描述符来作为新的文件描述符。


这里我们先搞明白 fopen 和 open 之间的耦合关联:

其实 FILE 结构体是被 _IO_FILE typedef 的(typedef struct_IO_FILE FILE),_IO_FILE 在 /usr/include/libio.h 下,在 _IO_FILE 结构中包含两个重要的成员:
- 底层对应的文件描述符下标 int _fileno,它是封装的文件描述符。也就是说,在 C 的文件接口中一定是使用 fileno 来调用系统接口 read(fp->fileno),所以 fopen 和 open 是通过 C 语言结构体内的文件描述符耦合的。
- 应用层 C 语言提供的缓冲区。之前写进度条小程序时,没有 '\n',数据不显示,必须以 fflush 强制刷新,其中数据所处的缓冲区就是由 __IO_FILE 维护的。

这里 close 1 后,1 下标就不再指向显示器文件,而是指向 log1.txt,FILE* stdout 当然还在,stdout 依然认为它的文件描述符值是 1,这里 printf 时会先把数据放到 C 语言提供的 __IO_FILE 缓冲区中,还没来得及刷新,但已经把 fd1 关闭了,所以操作系统没有办法由用户语言层刷新到操作系统底层的,所以自然也没看到结果。但这里不是有 '\n' 吗,为什么没有往操作系统刷新?因为此时 1 指向的是磁盘文件,磁盘文件是全缓冲,必须等待缓冲区满了再刷新,或者 fflush 强制刷新。在显示器文件中,无论用户层还是内核层都是行刷新,因为它无论怎样最终都会往显示器上刷新。
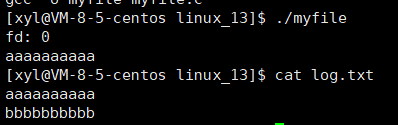
六、重定向
此时,我们发现本来应该输出到显示器上的内容,输出到了文件 myfile 当中。其中, fd = 1 。这种现象叫做输出重定向。常见的重定向有:>,>>,<
1、重定向的本质
重定向的本质其实就是在 OS 内部更改 fd 对应的内容指向。

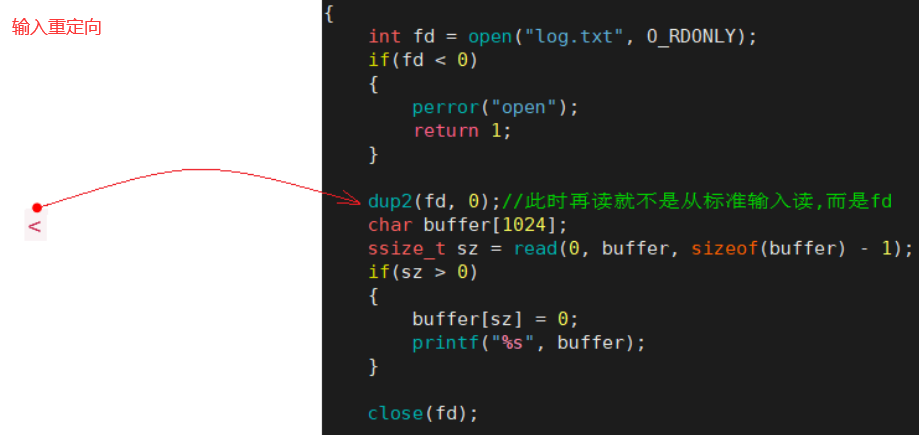
本应该从键盘读取的内容,现在从 log.txt 中读取。这就叫作输入重定向。


-
追加重定向:


2、使用 dup2 系统调用

要输出的文件描述符是 1,而要重定向的目标文件描述符是 fd (echo “hello” > log.txt),dup2 应该怎么传参 —— dup2(1, fd) || dup2(fd, 1) ?

很明显依靠函数原型,我们就能认为 dup2(1, fd),因为 1 是先打开的,而 fd 是后打开的.可实际上并不是这样的,文档中说 newfd 是 oldfd 的一份拷贝,这里拷贝的是文件描述符对应数组下标的内容,所以数组内容最终应该和 oldfd 一致。
换而言之,这里就是想把让 1 不要指向显示器了,而指向 log.txt,fd 也指向 log.txt。所以这里的 oldfd 对应 fd,newfd 对应 1,所以应该是 dup2(fd, 1)。
oldfd copy to newfd -> 最后要和谁一样?
oldfd。
假设输出重定向:显示器(1) -> log.txt(3)。应该是 dup2(1, 3);,还是dup2(3, 1); ?
dup2(3, 1);
3 的内容 copy 到 1 里面 -> 最终和 3 一致
(1)输入重定向


- < 就是 dup2(fd, 0),且 open 文件的方式是 O_RDONLY;
(2)追加重定向
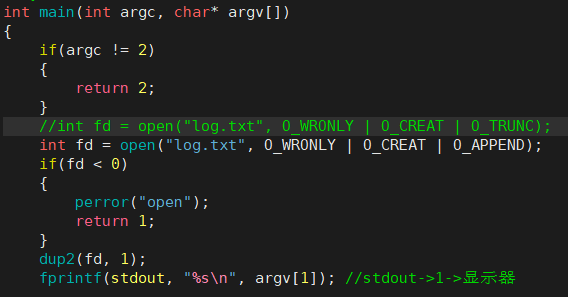
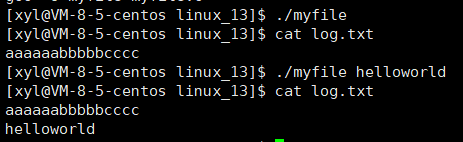
- >> 同 >,都是 dup2(fd, 1),只不过它打开文件的方式是 O_WRONLY | O_APPEND;

(3)输出重定向
echo "hello world" > log.txt —— echo 是一个进程。“hello world” 默认是调用 printf 或 write 往显示器上输出,log.txt 是调用 open 使用 O_WRONLY|O_CREAT 打开,> 是调用 dup2,将默认标准输出 1 的内容改为 log.txt。

3、在 minishell 中添加重定向功能




七、FILE
因为 IO 相关函数与系统调用接口对应,并且库函数封装系统调用。所以本质上,访问文件都是通过 fd 访问的。 所以 C 库当中的 FILE 结构体内部,必定封装了 fd,还包含该文件 fd 对应的语言层的缓冲结构。
1、对进程实现输出重定向

同样一个程序,向显示器打印输出 4 行文本,而向普通文件(磁盘)上打印输出 7 行文本。其中,printf 和 fwrite (库函数)都输出了 2 次,而 write 只输出了一次(系统调用),为什么呢?
- 一般 C 库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
- printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。
- 而我们放在缓冲区中的数据,就不会被立即刷新,甚至 fork 之后。
- 但是进程退出之后,会统一刷新,写入文件当中。
- 但是 fork 的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。
- write 没有变化,说明没有所谓的缓冲。
- fork 执行的时候,一定是函数已经执行完了,但是数据还没有刷新。在当前进程对应的 C 标准库中的缓冲区中,这部分数据是父进程的数据。return 0; 代表父子进程各自退出。
进程替换时,是否会干扰重定向对应的数据结构?
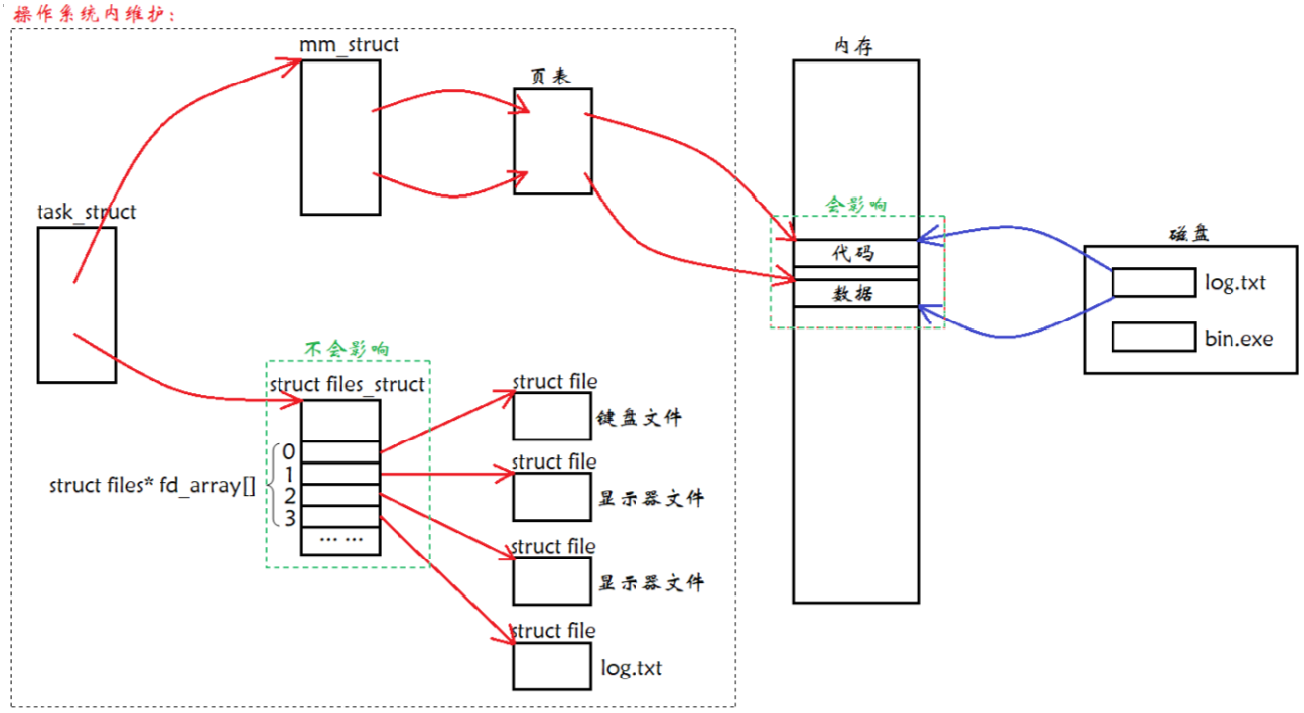
它们当然不会互相影响。换而言之,将来 fork 创建子进程,子进程会以父进程的大部分数据为模板,子进程进行程序替换时并不会影响曾经打开的文件,也就不会影响重定向对应的数据结构。
2、有关缓冲区的认识
一般而言,行缓冲的设备文件 -- 显示器,全缓冲的设备文件 -- 磁盘文件。
所有的设备永远都倾向于全缓冲,因为缓冲区满了才刷新,也就意味着需要更少次数的 IO,也就是更少次的访问,提高效率。
和外部设备 IO 时,数据量的大小不是主要矛盾,与外部设备 IO 的过程才是最耗费时间的。
其它刷新策略是结合具体情况做的妥协。比如:显示器是行刷新,因为显示器直接给用户看的,一方面要照顾效率,一方面要照顾用户体验。在极端情况下,是可以自己自定义规则的。磁盘经过效率考量,采用的是全缓冲的策略。
什么是缓冲区?
就是 一段内存空间。
那这个缓冲区是谁提供的呢?用户?语言?还是 OS?
绝对不是 OS,否则上面的例子应该都是 4 条文本。printf fwrite 是库函数, write 是系统调用,库函数在系统调用的 “ 上层 ” , 是对系统调用的 “ 封装 ”, 但是 write 没有缓冲区,而 printf fwrite 有,足以说明该缓冲区是二次加上的,又因为是 C,所以由 C 标准库提供。
为什么要有缓冲区?
提高整机效率,主要是为了提高用户的响应速度。
刷新策略 = 一般策略 + 特殊策略
- 一般策略:
- 立即刷新
- 行刷新(行缓冲) \n aaaaa\n bbbb
- 满刷新(全缓冲)
特殊策略:
- 用户强制刷新(fflush)
- 进程退出