随想录日记part24
t i m e : time: time: 2024.03.10
主要内容:回溯算法在代码学习中尤其重要,所以今天继续加深对其的理解:1:递增子序列 ;2.全排列 ;3.全排列II
- 491.递增子序列
- 46.全排列
- 47.全排列 I
Topic1递增子序列
题目:
给你一个整数数组 n u m s nums nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两个元素 。你可以按 任意顺序 返回答案。数组中可能含有重复元素,如出现两个整数相等,也可以视作递增序列的一种特殊情况。
输入: n u m s = [ 4 , 6 , 7 , 7 ] nums = [4,6,7,7] nums=[4,6,7,7]
输出: [ [ 4 , 6 ] , [ 4 , 6 , 7 ] , [ 4 , 6 , 7 , 7 ] , [ 4 , 7 ] , [ 4 , 7 , 7 ] , [ 6 , 7 ] , [ 6 , 7 , 7 ] , [ 7 , 7 ] ] [[4,6],[4,6,7],[4,6,7,7],[4,7],[4,7,7],[6,7],[6,7,7],[7,7]] [[4,6],[4,6,7],[4,6,7,7],[4,7],[4,7,7],[6,7],[6,7,7],[7,7]]
思路:
本题求自增子序列,是不能对原数组进行排序的,排完序的数组都是自增子序列了。所以不能使用之前的去重逻辑!
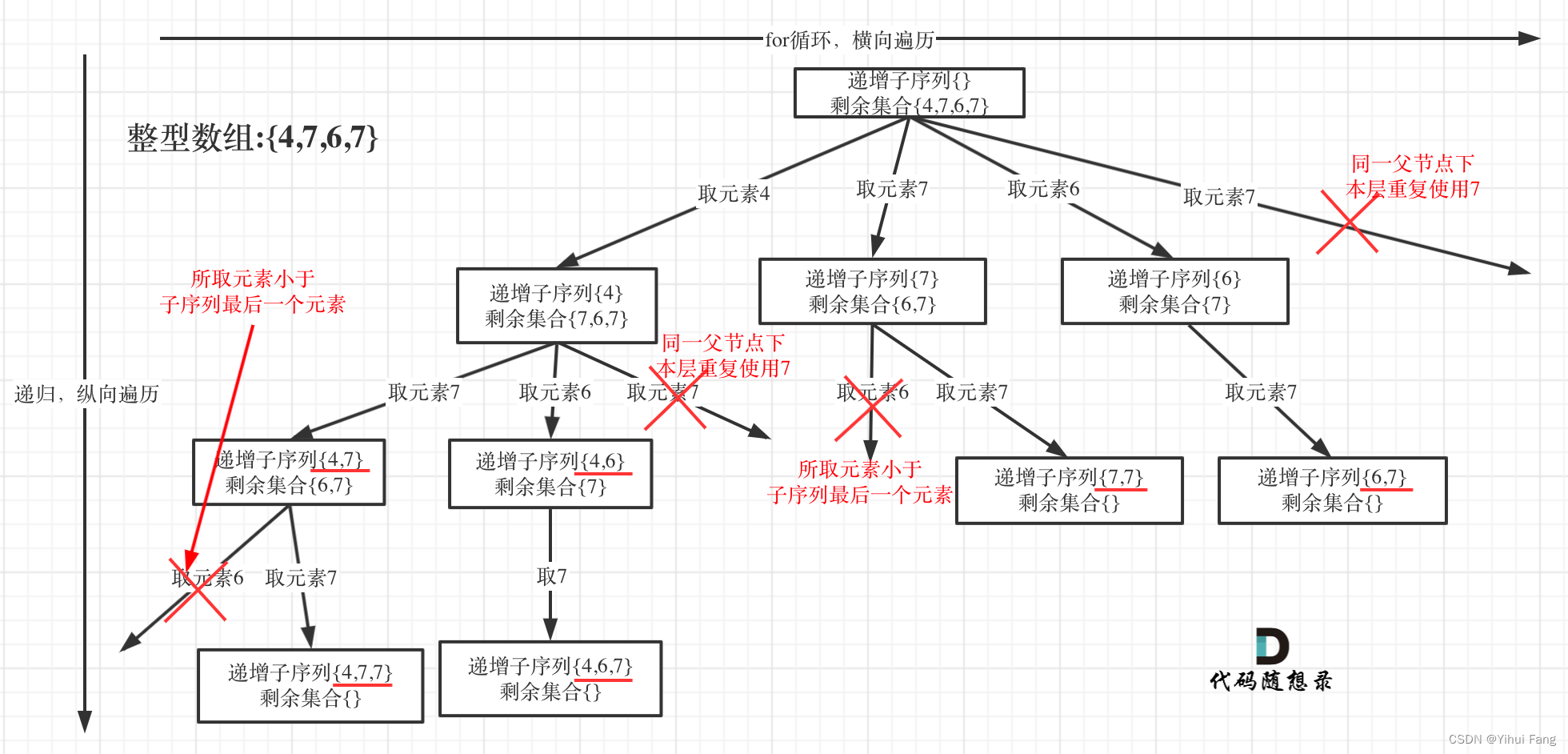
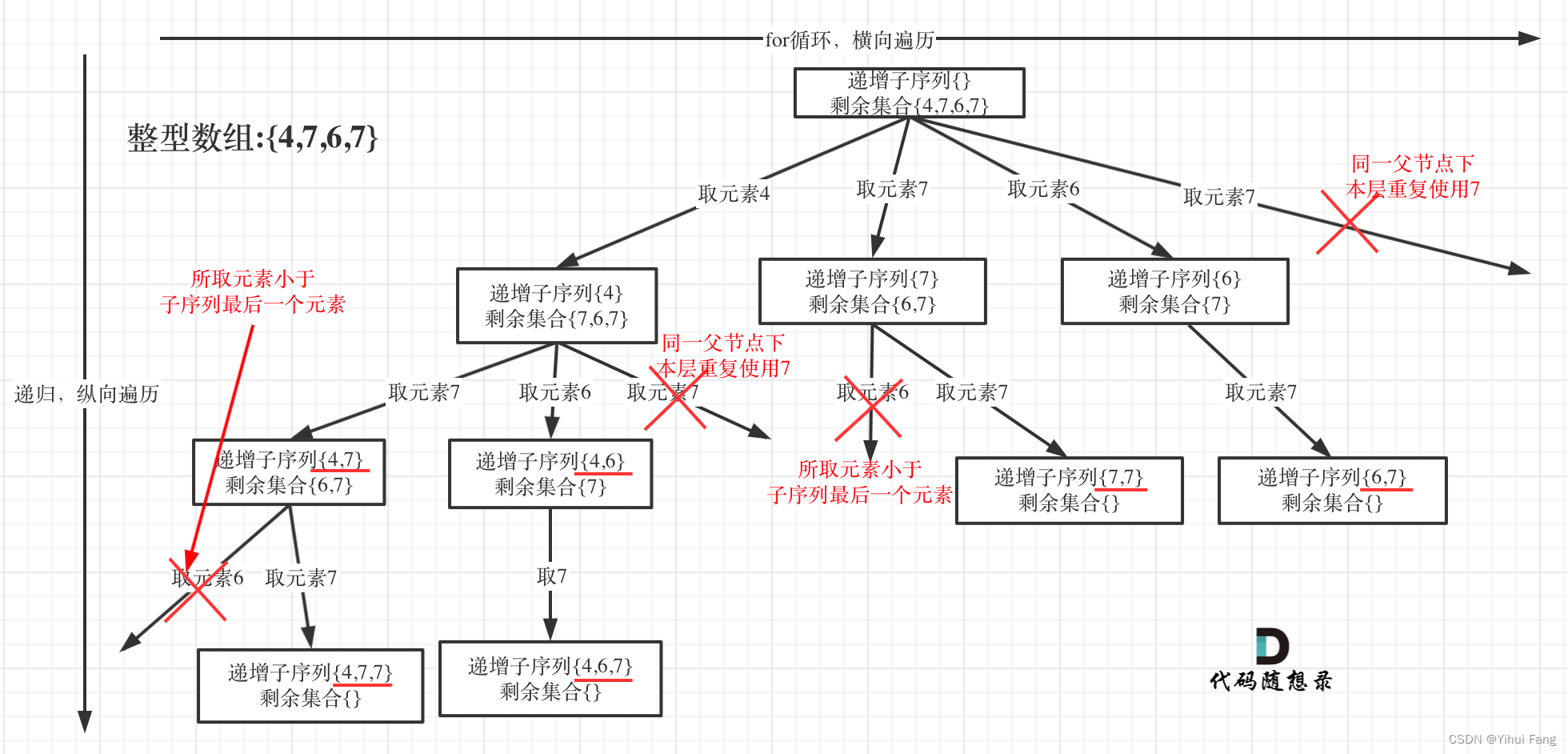
用 [ 4 , 7 , 6 , 7 ] [4, 7, 6, 7] [4,7,6,7] 这个数组来举例,抽象为树形结构如图:
按照回溯模板我们进行回溯三部曲:
递归三部曲:
1.回溯函数模板返回值以及参数
在这里要定义一个全局变量 r e s u l t result result用来存放符合条件结果的集合。回溯函数里需要一个参数为 i n t int int 型变量 s t a r t I n d e x startIndex startIndex,来表示索引,
所以整体代码如下:
List<List<Integer>> result = new ArrayList<>();// 记录最后输出的结果
List<Integer> path = new LinkedList<>();// 记录中间合理子序列
void reback(int[] nums, int startIndex)
2.回溯函数终止条件
题目要求递增子序列大小至少为2,所以代码如下
代码如下:
if (path.size() >= 2) {result.add(new ArrayList(path));}
if (startIndex >= nums.length) {return;}
3.回溯搜索的遍历过程
然后就是递归和回溯的过程:
在图中可以看出,同一父节点下的同层上使用过的元素就不能再使用了。
实现代码使用 H a s h S e t HashSet HashSet实现如下:
HashSet<Integer> hs = new HashSet<>();for (int i = startIndex; i < nums.length; i++) {// 去重if ((path.size() > 0 && path.getLast() > nums[i]) || hs.contains(nums[i]))continue;hs.add(nums[i]);path.add(nums[i]);reback(nums, i + 1);path.removeLast();}
完整的代码如下:
class Solution {List<List<Integer>> result = new ArrayList<>();// 记录最后输出的结果List<Integer> path = new LinkedList<>();// 记录中间合理子序列public List<List<Integer>> findSubsequences(int[] nums) {reback(nums, 0);return result;}private void reback(int[] nums, int startIndex) {// 回溯函数if (path.size() >= 2) {result.add(new ArrayList(path));}if (startIndex >= nums.length) {return;}HashSet<Integer> hs = new HashSet<>();for (int i = startIndex; i < nums.length; i++) {// 去重if ((path.size() > 0 && path.getLast() > nums[i]) || hs.contains(nums[i]))continue;hs.add(nums[i]);path.add(nums[i]);reback(nums, i + 1);path.removeLast();}}
}
时间复杂度: O ( n ∗ 2 n ) O(n * 2^n) O(n∗2n)
空间复杂度: O ( n ) O(n) O(n)
Topic2全排列
题目:
给定一个不含重复数字的数组 n u m s nums nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
输入: n u m s = [ 1 , 2 , 3 ] nums = [1,2,3] nums=[1,2,3]
输出: [ [ 1 , 2 , 3 ] , [ 1 , 3 , 2 ] , [ 2 , 1 , 3 ] , [ 2 , 3 , 1 ] , [ 3 , 1 , 2 ] , [ 3 , 2 , 1 ] ] [[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] [[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
思路:
按照回溯模板我们进行回溯三部曲:
递归三部曲:
1.回溯函数模板返回值以及参数
在这里要定义两个全局变量, p a t h path path用来存放符合条件单一结果, r e s u l t result result用来存放符合条件结果的集合。排列问题需要一个 u s e d used used 数组,标记已经选择的元素,如图橘黄色部分所示:
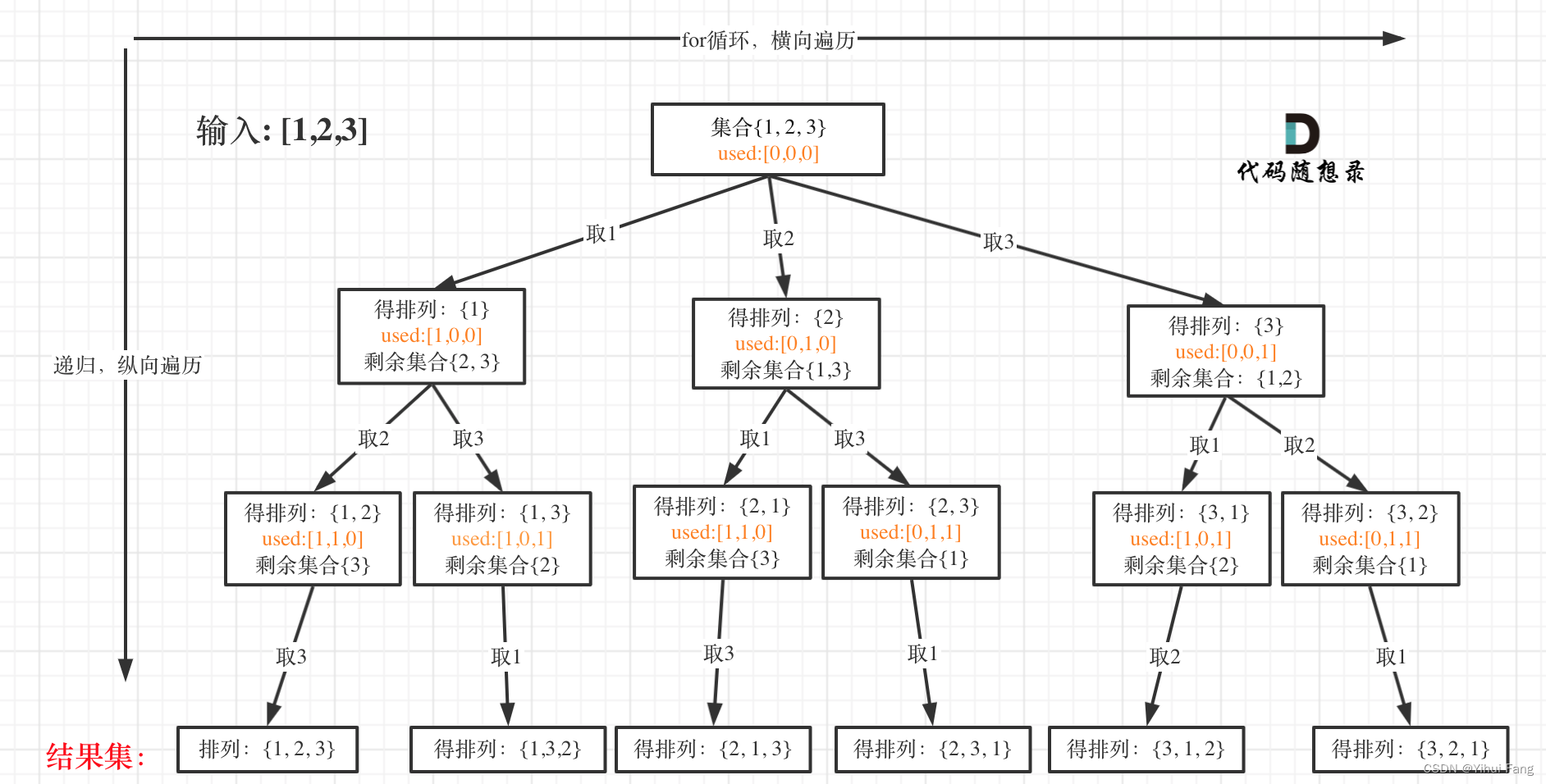
所以整体代码如下:
List<List<Integer>> result=new ArrayList<>();
LinkedList<Integer> path=new LinkedList<>();
boolean[] used;
private void permuteHelper(int[] nums)
2.回溯函数终止条件
当收集元素的数组 p a t h path path的大小达到和 n u m s nums nums数组一样大的时候,说明找到了一个全排列
if (nums.length == path.size()) {result.add(new ArrayList(path));return;}
3.回溯搜索的遍历过程
实现代码如下:
for (int i = 0; i < nums.length; i++) {if (used[i] == false) {used[i] = true;path.add(nums[i]);permuteHelper(nums);path.removeLast();used[i] = false;}}
完整的代码如下:
class Solution {List<List<Integer>> result = new ArrayList<>();List<Integer> path = new LinkedList<>();boolean[] used;public List<List<Integer>> permute(int[] nums) {used = new boolean[nums.length];Arrays.fill(used, false);permuteHelper(nums);return result;}private void permuteHelper(int[] nums) {// 回溯的结束条件if (nums.length == path.size()) {result.add(new ArrayList(path));return;}for (int i = 0; i < nums.length; i++) {if (used[i] == false) {used[i] = true;path.add(nums[i]);permuteHelper(nums);path.removeLast();used[i] = false;}}}
}
时间复杂度: O ( n ! ) O(n!) O(n!)
空间复杂度: O ( n ) O(n) O(n)
Topic3全排列II
题目:
给定一个可包含重复数字的序列 n u m s nums nums ,按任意顺序返回所有不重复的全排列。
输入: n u m s = [ 1 , 1 , 2 ] nums = [1,1,2] nums=[1,1,2]
输出: [ [ 1 , 1 , 2 ] , [ 1 , 2 , 1 ] , [ 2 , 1 , 1 ] ] [[1,1,2], [1,2,1], [2,1,1]] [[1,1,2],[1,2,1],[2,1,1]]
思路:
这个就是上面的方法加上了去重操作直接给出代码:
class Solution {List<List<Integer>> result = new ArrayList<>();List<Integer> path = new LinkedList<>();boolean[] used;public List<List<Integer>> permuteUnique(int[] nums) {used = new boolean[nums.length];Arrays.fill(used, false);Arrays.sort(nums);reback(nums);return result;}private void reback(int[] nums) {if (path.size() == nums.length) {result.add(new ArrayList(path));return;}for (int i = 0; i < nums.length; i++) {if (used[i] == false) {if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false)continue;used[i] = true;path.add(nums[i]);reback(nums);path.removeLast();used[i] = false;}}}
}
时间复杂度: O ( n ! ∗ n ) O(n! * n) O(n!∗n)
空间复杂度: O ( n ) O(n) O(n)
拓展:
去重最为关键的代码为:
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {continue;
}
如果改成 u s e d [ i − 1 ] = = t r u e used[i - 1] == true used[i−1]==true, 也是正确的!,去重代码如下:
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == true) {continue;
}
对于排列问题,树层上去重和树枝上去重,都是可以的,但是树层上去重效率更高!
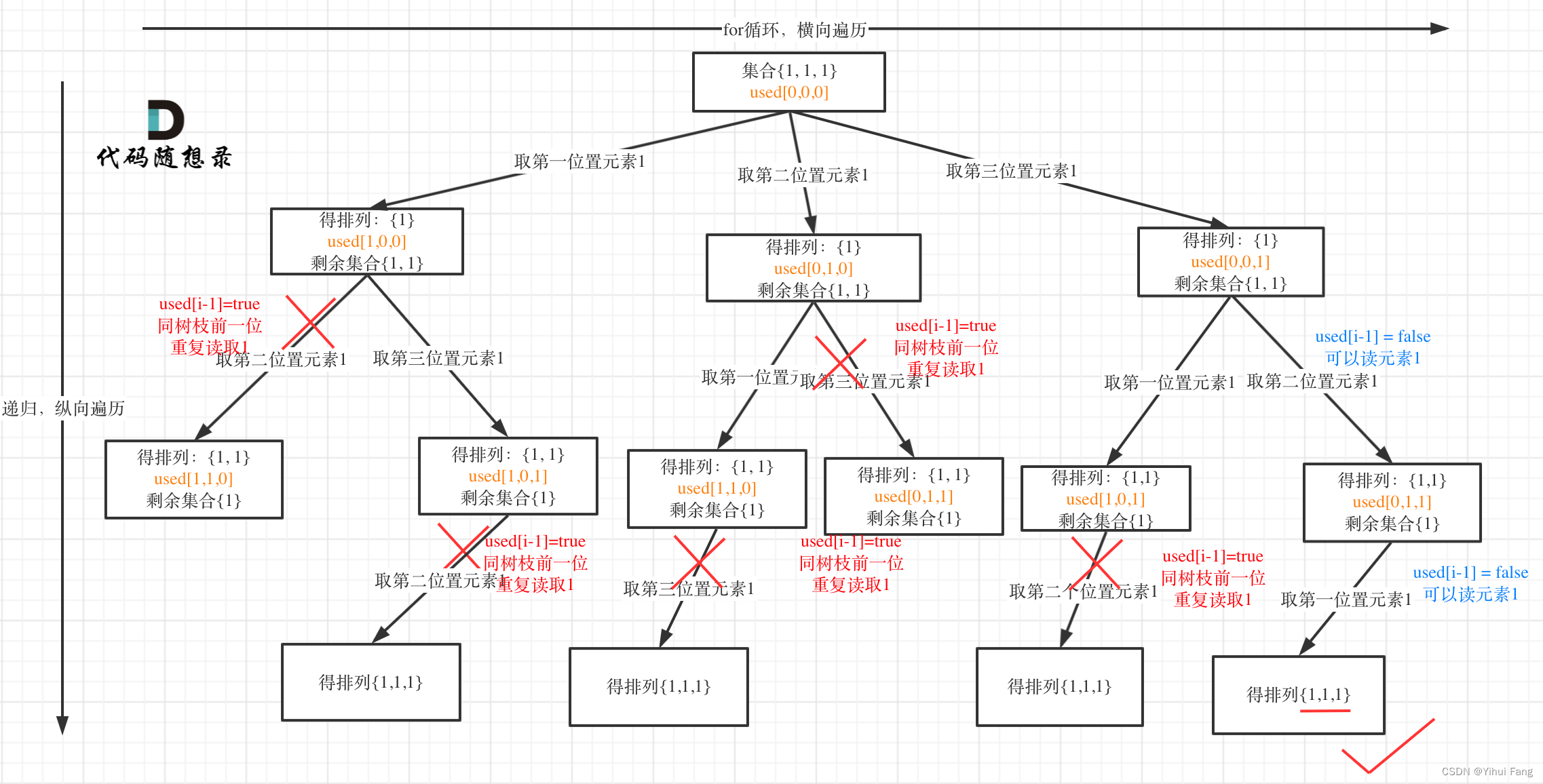
用输入: [ 1 , 1 , 1 ] [1,1,1] [1,1,1] 来举一个例子。
树层上去重 ( u s e d [ i − 1 ] = = f a l s e ) (used[i - 1] == false) (used[i−1]==false),的树形结构如下:
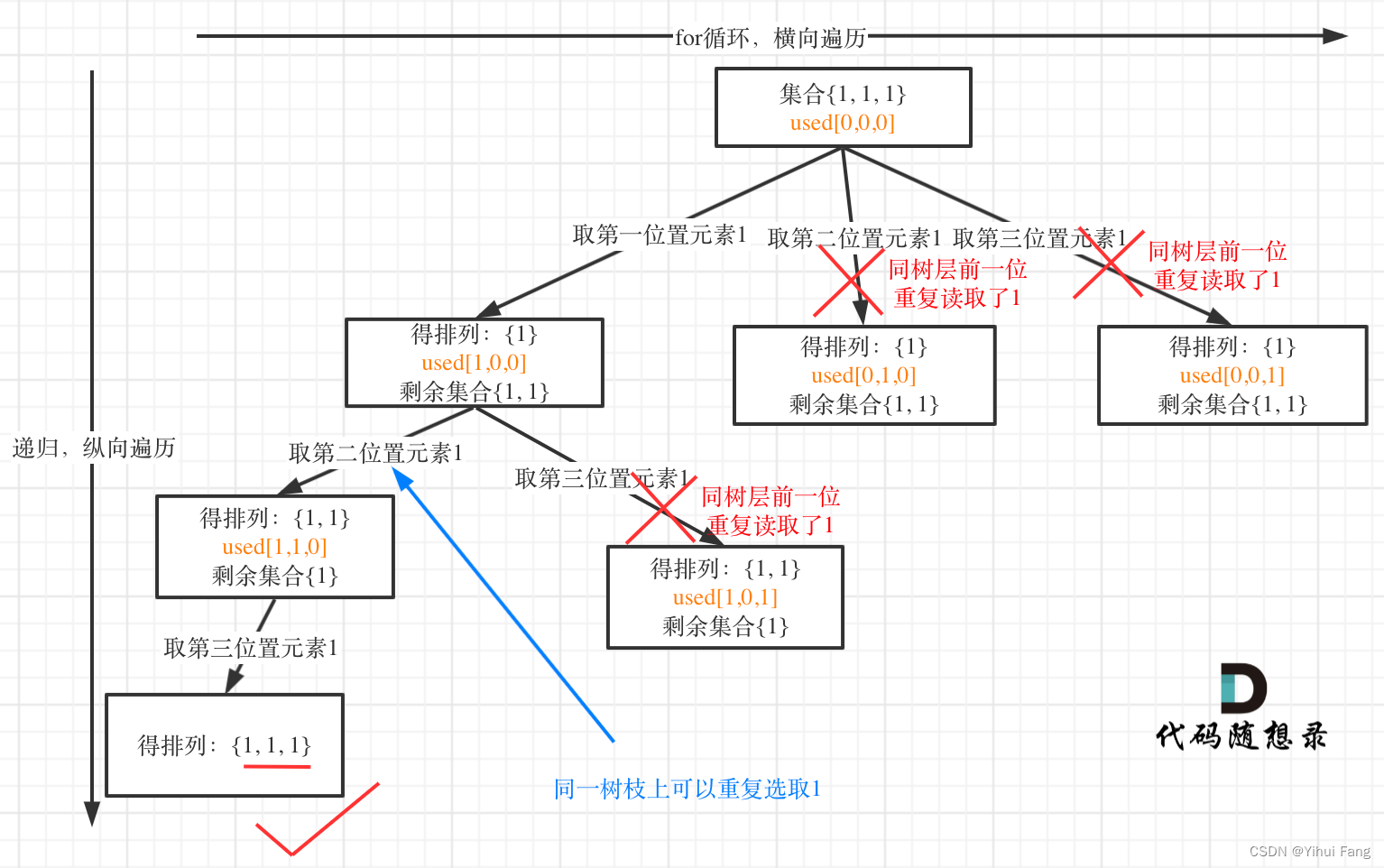
树枝上去重 ( u s e d [ i − 1 ] = = t r u e ) (used[i - 1] == true) (used[i−1]==true)的树型结构如下:


![练习 9 Web [SUCTF 2019]CheckIn (未拿到flag)](https://img-blog.csdnimg.cn/direct/ce6fbec3c49342ce90021571deaa6860.png)