zk
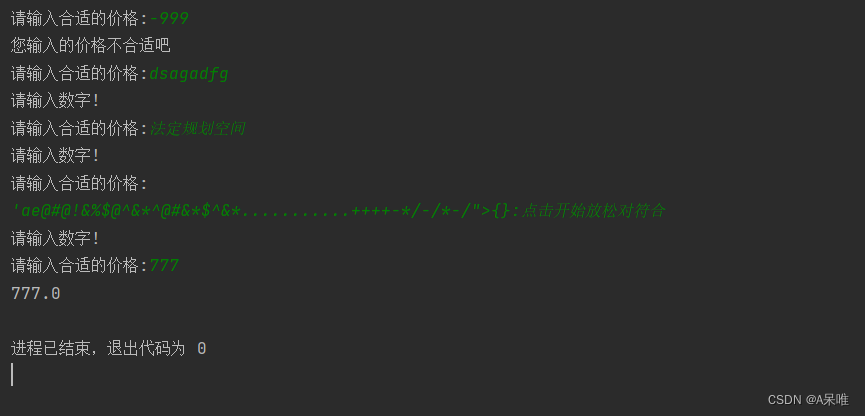
临时节点和watch机制实现注册中心自动注册和发现,数据都在内存,nio 多线程模型;
cp注重一致性,数据不一致时集群不可用
事务请求处理方式
1.all事务由唯一服务器处理
2.将客户端事务请求转成proposal分发follower
3.等待半数ack,再commit
对事务性支持依赖
zoo_create_op_int / zoo_delete_op_init / zoo_set_op_init /zoo_check_op_init
每个函数在客户端初始化operation,准备好事务all操作后,zoo_multi提交所有操作,一个失败返回第一个失败操作的状态信号,版本号同一原子性操作
zab
支持崩溃恢复的原子广播协议,
领导选举:leader(写)维护follower列表
数据同步:所有节点数据要和leader保持一致,高可用分区容错,follower本地事务日志
请求广播:leader收到写请求,两阶段提交(事务proposal形式)广播写请求,一半ack=成功
模式:崩溃恢复 消息广播
消息广播
所有请求由leader转成proposal分发给其他服务follower
过半follower反馈信息,leader广播commit,将之前的proposal提交
崩溃恢复
被leader提交的proposal最终被follower服务提交
- 新选举的leader节点含最大的zxid
丢弃被leader提出但未被提交的proposal
- 被选举出来的leader不能有未提交的proposal
leader网络中断 崩溃退出 重启 ,选新leader后过半机器该leader完成同步 进入广播模式
新加入的机器 先恢复模式然后同步完广播
保证消息有序
1.先分配全局递增id(zxid) 每个follower分配单独FIFO队列(异步解耦) 发送proposal广播
2.follower接到写本地事务,返回ack
leader收半数以上follower的ack响应消息,广播commit消息 自身完成事务提交
3.follower接收到commit消息 将上一条事务提交
数据同步
完成leader选举,leader先确认事务日志所有proposal已被集群过半服务器commit
确保follower能接收每条事务的proposal,能将提交的事务应用到内存,完成后才加入到真正的follower列表
丢失的proposal
zxid 64位
低32位单增计数器针对每一个请求
高32位leader周期的epoch编号:当前集群所处年代/周期 leader变更+1
新的leader中取本地事务日志最大编号的proposal的zxid解析epoch编号+1,低32归零
节点状态
following / leading / election looking选举状态正在找leader / observing只读节点
投票再同一轮,logicalClock标识标记轮数 开始前先清空上一轮投票情况
watch
znode设置,一次性触发器;3.6可递归触发多次
角色:客户端线程/客户端的watchManager/zk服务器
客户端向zk服务器注册watcher监听,监听信息存储到客户端watchManager中
zk节点变化通知客户端,客户端调用相应watcher到回调
串行同步顺序性(w放队列中)
选举
zxid myid 投票pick,大的优先
观察者机制observer节点
动态扩展zk集群,不降低写性能
不参与投票,只获取投票结果,可处理读写请求,写转leader
负责接收leader同步过来的提交数据
数据一致性模型
cap 强一致,更新操作完 多个后续进程访问返回最新的更新过的值
弱一致:系统数据写入后 不一定立即读取最新写入数据
最终一致性:所有数据副本 经过一段时间的同步后 最终能够达到一致的状态
因果一致性:因果关系的操作顺序得到保证
会话一致性:对系统数据的访问过程框定在一个会话中
paxos强一致
角色:
proposer提议者:发出的提案被多数acceptor接受,该提案value被选定
acceptor接受者:只要acceptor接受了某个提案,acceptor该提案的value被选定
learners记录员:acceptor告诉learner哪个value被选定,learner认为哪个value被选定
阶段:
proposer收到client请求或发现本地有未提交的值,选择提案编号n,发送prepare请求
acceptor收到编号n的prepare请求,如已有提交的value对比编号,大于n则拒绝回应 否返v和号
无提交记录,判断是否有编号n1,n1>n 拒绝响应,否则n1改为n,响应prepare
proposer收到多数acceptor发出n的响应,[n,v]提案的accept请求给半数以上的acceptor
acceptor收到accept请求,对比本地的编号 =< n 接受该值 提交记录value 否则拒绝请求
proposer收到大多数acceptor,选定value 同步给leader
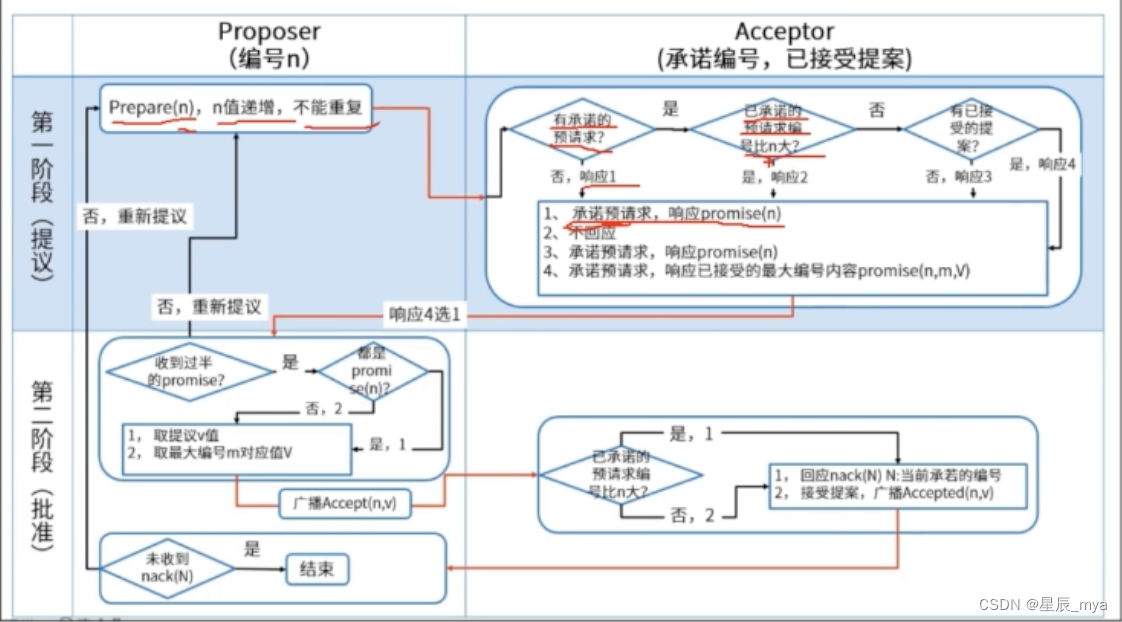
活锁:accept一直被拒绝,加n,另一个proposer也这么操作,accept一致失败
multi-paxos:确定多个值,接收accept请求后,一定时间内不再accept其他节点的请求,保证后续编号不需要prepre
raft算法:分布式一致性
leader负责replicated log管理,负责客户端更新请求,复制到follower
状态: leader/follower/candidate选举产生新的leader
选举:
初始化,all都是follower 随机超时 变成candidate 发起选举
f在election timeout内没有收到l心跳 发起选举
term:任期,每个节点维持着,递增 存储在log的entry中
每次rpc通信传递该任期号,大于本地切换为follower,小于报错
通信:requestVote RPC 负责选举(lastindex lastTerm)
appendEntries RPC负责数据交互
日志序列:每个节点维持着持久化log,一致性协议算法 每个节点log一致 顺序存放
选举:增加term切换到candidate 最多投一票 多数则leader发送心跳
数据模型
持久节点: 一致存储zk上
临时节点:会话超时/异常 删除
有序节点:单调递增的数字作为后缀追加
节点内容
二进制数组byte data: 存储节点的数据 ACL访问控制 子节点数据 自身信息的stat
stat+节点路径:状态信息
czxid创建节点的事务id ctime创建时间 mzxid最后一次被更新的事务id mtime最后更新时间
version版本号 pzxid子节点最后一次被修改的事务id cversion子节点版本 averson:acl版本号
ephemeralOwner创建节点的sessionId 持久节点 值为0
dataLenght数据内容长度 numChildren子节点个数
命名服务
指定名字获取资源或服务地址,zk创建全局唯一的路径,路径可作为名字
机器 服务地址 远程对象 据特定名字获取资源的实体 服务地址 提供者信息
配置管理
配置信息保存到znode,改变时watcher通知
集群管理
监控和控制,机器挂了 对应临时目录删除 被感知
应用场景
发布/订阅:配置中心
负载均衡:提供服务者列表
命名服务:服务名到服务地址映射
分布式协调/通知:watch机制和临时节点,任务进度
集群管理:临时节点 加入 退出
分布式锁
分布式队列: