说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。
知乎专栏地址:
语音生成专栏
系列文章地址:
【GPT-SOVITS-01】源码梳理
【GPT-SOVITS-02】GPT模块解析
【GPT-SOVITS-03】SOVITS 模块-生成模型解析
【GPT-SOVITS-04】SOVITS 模块-鉴别模型解析
【GPT-SOVITS-05】SOVITS 模块-残差量化解析
【GPT-SOVITS-06】特征工程-HuBert原理
1.SOVITS 鉴别器
1.1、概述
GPT-SOVITS 在鉴别器这块在SOVITS原始版本上做了简化,先回顾下SOVITS的鉴别器。主要包含三类:

各个鉴别器的输出都包括两类,即各层中间输出和最终结果输出,分别用来计算特征损失和生成损失。如下:

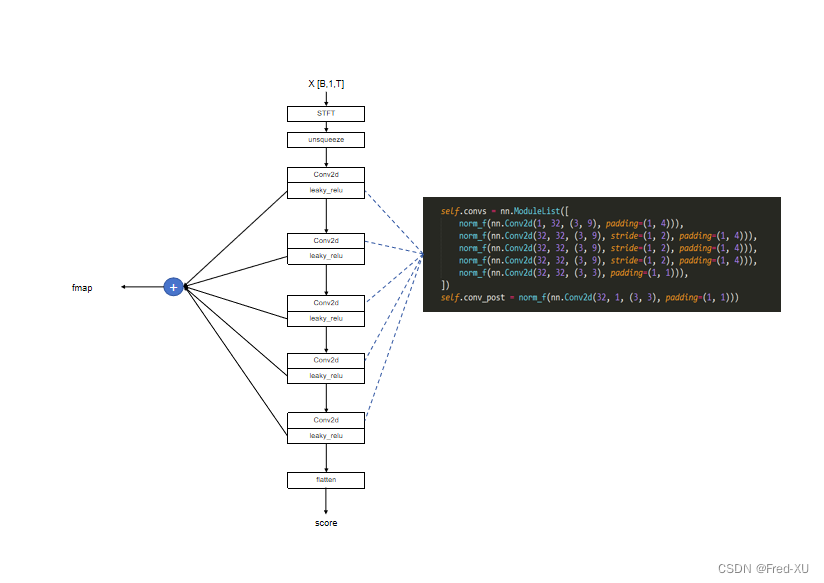
1.2、MRD举例
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.utils import weight_norm, spectral_normclass DiscriminatorR(torch.nn.Module):def __init__(self, hp, resolution):super(DiscriminatorR, self).__init__()self.resolution = resolutionself.LRELU_SLOPE = hp.mpd.lReLU_slopenorm_f = weight_norm if hp.mrd.use_spectral_norm == False else spectral_normself.convs = nn.ModuleList([norm_f(nn.Conv2d(1, 32, (3, 9), padding=(1, 4))),norm_f(nn.Conv2d(32, 32, (3, 9), stride=(1, 2), padding=(1, 4))),norm_f(nn.Conv2d(32, 32, (3, 9), stride=(1, 2), padding=(1, 4))),norm_f(nn.Conv2d(32, 32, (3, 9), stride=(1, 2), padding=(1, 4))),norm_f(nn.Conv2d(32, 32, (3, 3), padding=(1, 1))),])self.conv_post = norm_f(nn.Conv2d(32, 1, (3, 3), padding=(1, 1)))def forward(self, x):fmap = []# 获取频谱,这里是做了窗口傅里叶变换# 傅里叶变换时,频谱数量、窗口的移动、窗口大小由参数 resolution 决定x = self.spectrogram(x)x = x.unsqueeze(1)for l in self.convs:# 与其他鉴别器一样经过conv-1d 和 leak-relue 形成中间层特征x = l(x)x = F.leaky_relu(x, self.LRELU_SLOPE)# 中间层特征被保存在 fmap 中fmap.append(x)x = self.conv_post(x)fmap.append(x)x = torch.flatten(x, 1, -1)# 返回各层的中间层特征 fmap 和 最终输出 xreturn fmap, xdef spectrogram(self, x):n_fft, hop_length, win_length = self.resolutionx = F.pad(x, (int((n_fft - hop_length) / 2), int((n_fft - hop_length) / 2)), mode='reflect')x = x.squeeze(1)x = torch.stft(x, n_fft=n_fft, hop_length=hop_length, win_length=win_length, center=False, return_complex=False) #[B, F, TT, 2]mag = torch.norm(x, p=2, dim =-1) #[B, F, TT]return magclass MultiResolutionDiscriminator(torch.nn.Module):def __init__(self, hp):super(MultiResolutionDiscriminator, self).__init__()self.resolutions = eval(hp.mrd.resolutions)self.discriminators = nn.ModuleList([DiscriminatorR(hp, resolution) for resolution in self.resolutions])def forward(self, x):ret = list()# 这里做了一个不同尺度的 DiscriminatorR"""在 base.yml 中 mrd 的参数如下,有四个不同的尺度:mrd:resolutions: "[(1024, 120, 600), (2048, 240, 1200), (4096, 480, 2400), (512, 50, 240)]" # (filter_length, hop_length, win_length)use_spectral_norm: FalselReLU_slope: 0.2"""for disc in self.discriminators:ret.append(disc(x))return ret # [(feat, score), (feat, score), (feat, score)]
2.GPT-SOVITS 鉴别器
2.1、主要更改
GPT-SOVITS 鉴别器结构与 SOVITS基本类似,只是去除了多分辨率鉴别器,其余基本一样,包括多周期鉴别器的尺度也是 2, 3, 5, 7, 11。其返回结果也包含最终【生成鉴别结果】和各层输出【特征鉴别结果】两类。
class MultiPeriodDiscriminator(torch.nn.Module):def __init__(self, use_spectral_norm=False):super(MultiPeriodDiscriminator, self).__init__()periods = [2, 3, 5, 7, 11]discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]discs = discs + [DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods]self.discriminators = nn.ModuleList(discs)def forward(self, y, y_hat):y_d_rs = []y_d_gs = []fmap_rs = []fmap_gs = []for i, d in enumerate(self.discriminators):y_d_r, fmap_r = d(y) # 原始音频输入,返回鉴别结果y_d_g, fmap_g = d(y_hat) # 推测音频输入,返回鉴别结果y_d_rs.append(y_d_r)y_d_gs.append(y_d_g)fmap_rs.append(fmap_r)fmap_gs.append(fmap_g)return y_d_rs, y_d_gs, fmap_rs, fmap_gs
2.2、损失函数
y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(y, y_hat)
with autocast(enabled=False):loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_melloss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_klloss_fm = feature_loss(fmap_r, fmap_g)loss_gen, losses_gen = generator_loss(y_d_hat_g)
如前文所述,这里特征损失基于各层输出,计算逻辑在 feature_loss
def feature_loss(fmap_r, fmap_g):loss = 0for dr, dg in zip(fmap_r, fmap_g):for rl, gl in zip(dr, dg):rl = rl.float().detach()gl = gl.float()loss += torch.mean(torch.abs(rl - gl))return loss * 2
最终生成损失判别基于最终结果,计算逻辑在 generator_loss
def generator_loss(disc_outputs):loss = 0gen_losses = []for dg in disc_outputs:dg = dg.float()l = torch.mean((1 - dg) ** 2)gen_losses.append(l)loss += lreturn loss, gen_losses