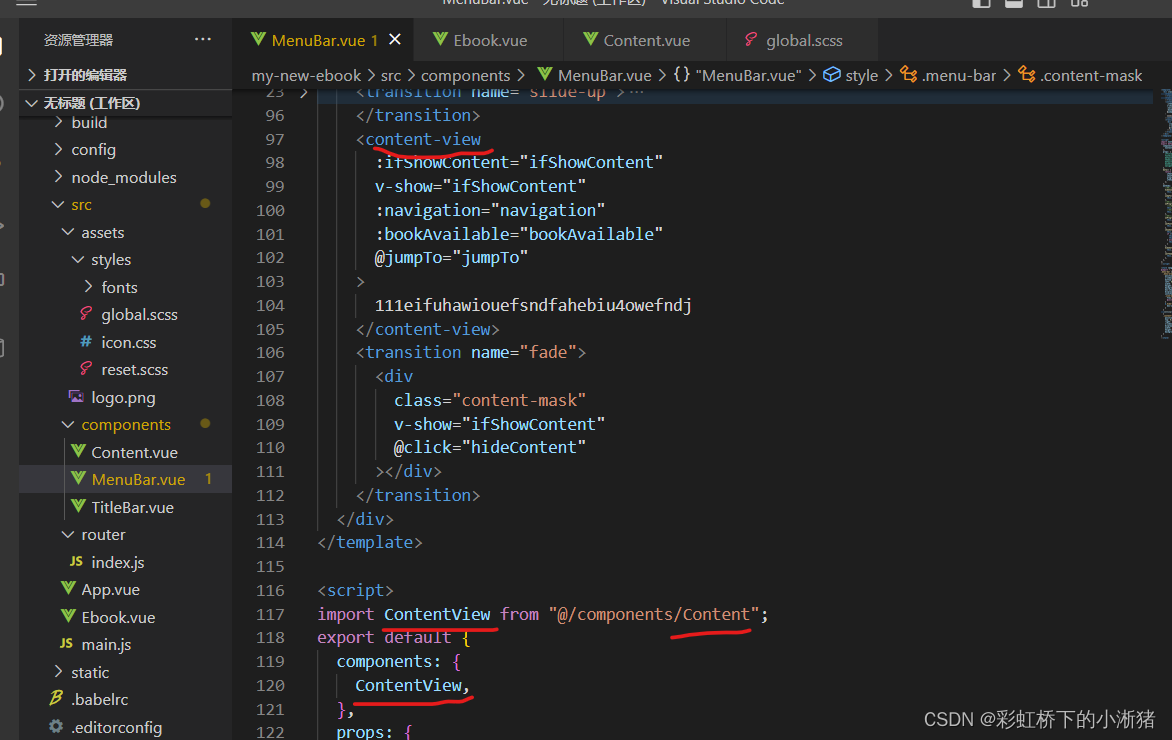
PP-YOLO系列,均是基于百度自研PaddlePaddle深度学习框架发布的算法,2020年基于YOLOv3改进发布PP-YOLO,2021年发布PP-YOLOv2和移动端检测算法PP-PicoDet,2022年发布PP-YOLOE和PP-YOLOE-R。由于均是一个系列,所以放一起解读,方便对比前后改进地方。
PP-YOLO系列算法解读:
- PP-YOLO算法解读
- PP-YOLOv2算法解读
- PP-PicoDet算法解读
- PP-YOLOE算法解读
- PP-YOLOE-R算法解读
YOLO系列算法解读:
- YOLOv1通俗易懂版解读
- SSD算法解读
- YOLOv2算法解读
- YOLOv3算法解读
- YOLOv4算法解读
- YOLOv5算法解读
- YOLOR算法解读
文章目录
- 1、算法概述
- 2、PP-YOLOE-R细节
- 3、实验
PP-YOLOE-R(2022.11.4)
论文:PP-YOLOE-R: An Efficient Anchor-Free Rotated Object Detector
作者:Xinxin Wang, Guanzhong Wang, Qingqing Dang, Yi Liu, Xiaoguang Hu, Dianhai Yu
链接:https://arxiv.org/abs/2211.02386
代码:https://github.com/PaddlePaddle/PaddleDetection
1、算法概述
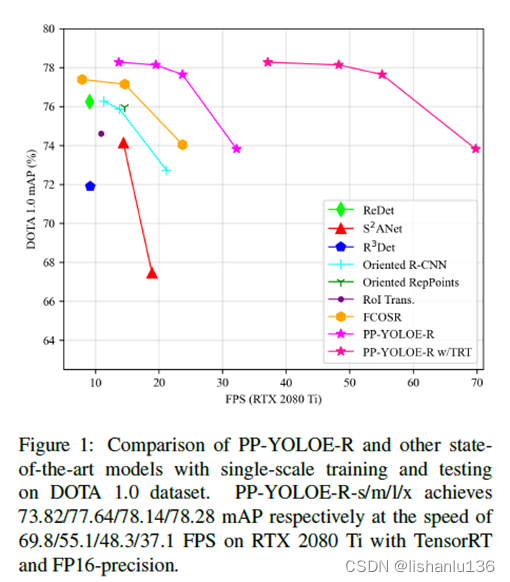
面向任意方向的目标检测是航拍场景、遥感图像和文本视觉场景中的一项基本任务。作者基于PP-YOLOE检测算法提出高效无锚框旋转目标检测器PP-YOLOE-R。作者在PP-YOLOE-R中引入了一套有用的技巧来提高检测精度,并减少了额外的参数和计算成本。结果表明,通过单尺度训练和测试,PP-YOLOE-R-l和PP-YOLOE-R-x在DOTA1.0数据集上的mAP分别达到78.14%和78.28%,优于几乎所有其他旋转目标检测器。通过多尺度训练和测试,PP-YOLOE-R-l和PP-YOLOE-R-x进一步提高了检测精度,分别达到80.02%和80.73%mAP。在这种情况下,PP-YOLOE-R-x超越了所有无锚点的方法,与目前最先进的基于锚点的两阶段模型相比,也非常具有竞争力。此外,PP-YOLOER具有部署友好性,PP-YOLOE-R-s/m/l/x在RTX 2080 Ti上使用TensorRT和fp16精度分别可以达到69.8/55.1/48.3/37.1 FPS,可以看出这个推理速度是满足实时性要求的。
2、PP-YOLOE-R细节
PP-YOLOE-R基于PP-YOLOE改进而来,和PP-YOLOE网络结构非常相似,其网络结构图如下所示:
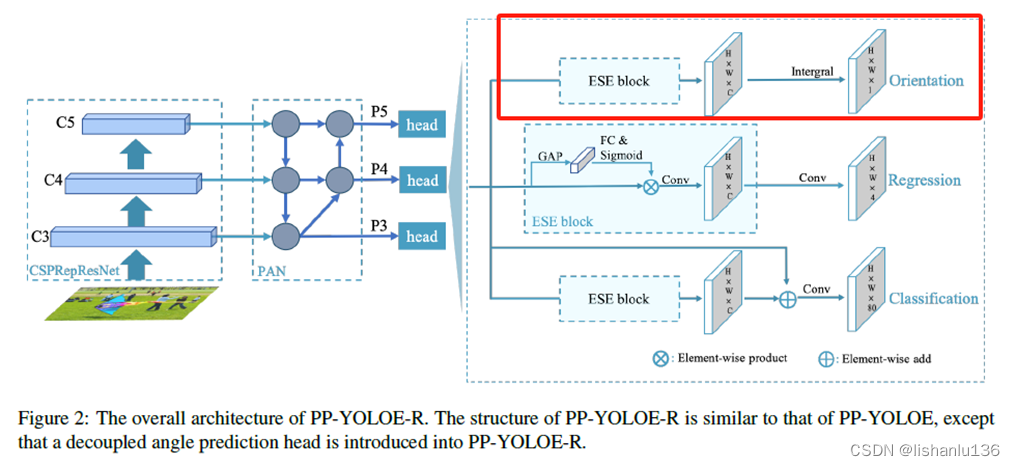
图中画红框的就是PP-YOLOE-R新增的角度预测头分支,除此之外,backbone,neck,及剩余head部分结构一模一样。
相对于PP-YOLOE,PP-YOLOE-R主要做了4点改进:
- 1、借鉴FCOSR[1]的方式也引入了ProbIoU loss[2]作为回归损失以避免边界不连续问题。
- 2、改进任务一致性学习(Task Alignment Learning, TAL)以适配旋转目标检测算法。
- 3、设计了一个解耦的角度预测头,通过DFL损失直接学习角度的一般分布,以获得更准确的角度预测。
- 4、对重新参数化机制做了一些修改,增加了一个可学习的门控单元来控制来自前一层的信息量。
做的改进:
Baseline:添加FCOSR的标签分配策略和引入ProbIoU损失作为回归损失到PP-YOLOE中作为实验baseline;其backbone与neck部分和PP-YOLOE保持一样,但是head中的回归分支被调整为预测旋转矩形框5个值,即(x,y,w,h,θ),单尺度训练和测试情况下,baseline能在DOTA1.0数据集上达到75.61%mAP。
改进地方及其消融实验结果如下:
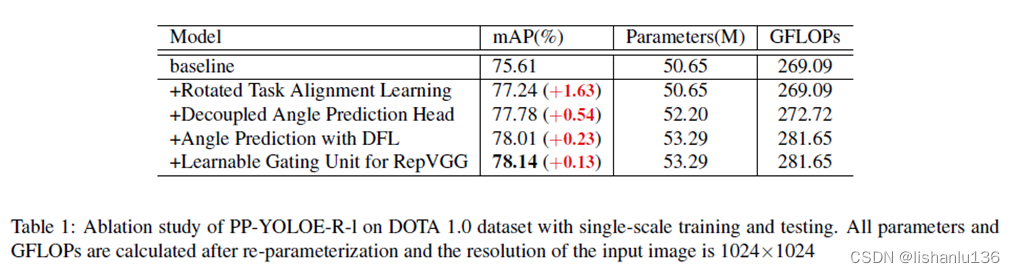
Rotated Task Alignment Learning: 任务一致性学习由任务对齐的标签分配和任务对齐的损失组成。任务对齐标签分配构建了一个任务对齐度量,用来从候选锚点中选择正样本;当候选锚点坐标落在任何gt真值框中,就可以根据这个对齐度量判定是否属于正样本。其计算公式如下:

这里s代表预测类别分数,u代表预测框和gt框的IoU大小。
在带旋转的任务一致性学习(Rotated Task Alignment Learning)中,候选锚点的选取过程则利用了gt真值边界框及其锚点的几何特性,采用预测值与gt真值边界框的SkewIoU值作为u。经过如上改变就可将任务对齐的标签分配策略应用在旋转框检测任务中。对于TAL的另一部分,任务对齐的损失,作者没有做出改变,经过上述改变后,mAP提升至77.24%。
Decoupled Angle Prediction Head: 大多数旋转目标检测算法都是在回归分支中预测5个参数(x,y,w,h,θ)用来预测带旋转的矩形框。这里作者假设了θ可能和其他4个坐标需要不同的特征,所以作者设计了另外的一个角度预测分支。这个改进措施给模型带来0.54%mAP的提升。
Angle Prediction with DFL: ProbIoU损失作为回归损失是通过联合优化(x,y,w,h,θ)这5个参数,为了计算ProbIoU损失,旋转矩形框被转换到高斯矩形框(Gaussian bounding box)。当旋转矩形框大致为正方形时,由于高斯矩形框中的方向是继承自椭圆表示,因此无法确定旋转矩形框的方向。为了克服这个问题,作者引入了Distribution Focal Loss(DFL)来预测角度。DFL的目的是学习角度的一般分布。在本文中,作者离散了角度值,用等间隔角度w来切分,预测角度值θ可表示为:

Pi代表角度落在第i个间隔的可能性,本文的旋转矩形框遵从OpenCV的定义,w设置为π/180。通过在角度预测时引入DFL,mAP提升了0.23%。
Learnable Gating Unit for RepVGG: RepVGG提出了一个由3x3卷积、1x1卷积和一个shortcut路径组成的多分支架构。其训练阶段的信息流可表示为:
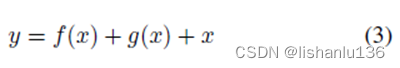
其中f(x)代表3x3卷积,g(x)代表1x1卷积。在推理过程中,将该体系结构重新参数化为等效的3x3卷积。虽然RepVGG相当于卷积层,但在训练过程中使用的RepVGG多分支架构可以使得训练收敛效果更好,这得益于多分支结构引入了有用的先验知识。受此启发,作者在RepVGG中引入了一个可学习的门控单元来控制来自前一层的信息量。本设计主要针对微小物体或密集物体,自适应融合不同感受野的特征,可表述如下:
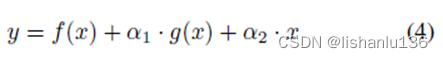
其中α1和α2是可学习参数,在PP-YOLOE的网络结构RepResBlock中,没有使用shortcut连接,所以这里RepResBlock只有一个参数α1,在推理过程中,可学习参数可以随着卷积层的变化而重新参数化,这样既不会改变参数的速度,也不会改变参数的数量。通过引入这个改变,mAP提升0.13%。
ProbIoU Loss: 在ProbIoU损失中,使用两个高斯分布的Bhattacharyya系数来度量两个旋转边界盒的相似度。但是GWD、KLD、KFIoU也能度量高斯矩形框的相似性。作者拿KLD Loss和ProbIoU Loss做对比,证明ProbIoU Loss确实更合适,如下:

3、实验
PP-YOLOE-R在DOTA1.0数据集上与现如今先进的旋转框检测算法对比情况如下表所示:
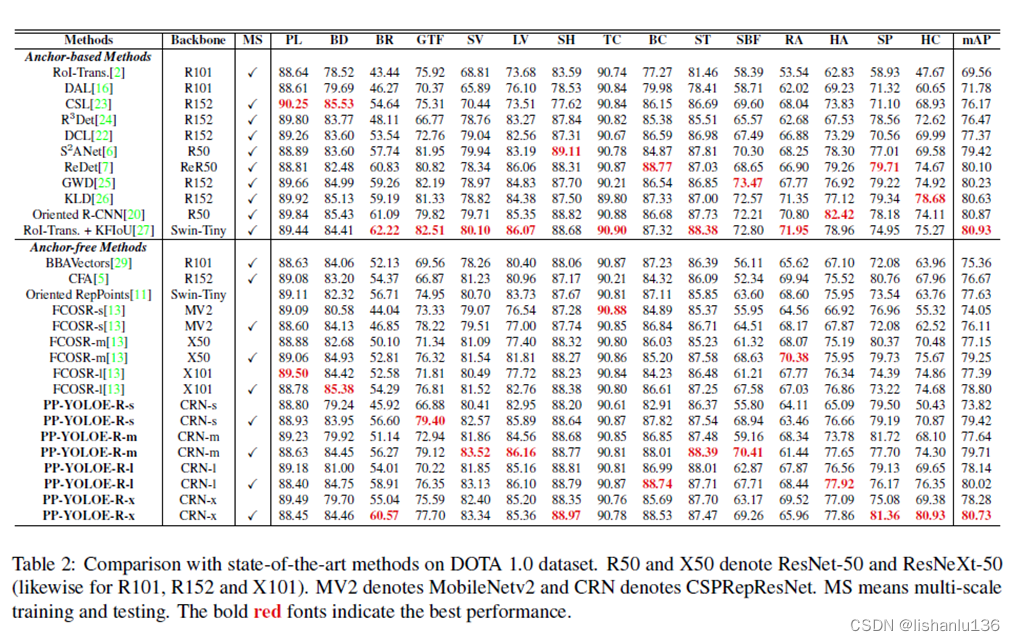
从表中结果可以看出,PP-YOLOE-R是具有高精度、实时性高,参数少,计算成本低的检测算法,优于所有无锚旋转框目标检测算法。
参考文献:
[1] Zhonghua Li, Biao Hou, Zitong Wu, Licheng Jiao, Bo Ren, and Chen Yang. Fcosr: A simple anchor-free rotated detector for aerial object detection. arXiv preprint arXiv:2111.10780, 2021. 1, 2, 3, 4, 5
[2] Jeffri M Llerena, Luis Felipe Zeni, Lucas N Kristen, and Claudio Jung. Gaussian bounding boxes and probabilistic intersection-over-union for object detection. arXiv preprint arXiv:2106.06072, 2021. 1, 2, 3, 4, 5