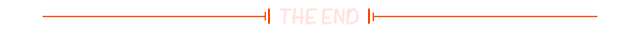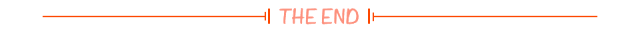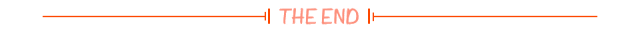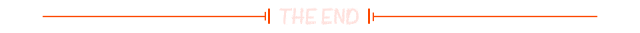1. 编程实践
在一些关键的地方,相应的编程技巧能够给性能带来重大提升。
1.1. 参数传递
传递非基本类型时,使用引用或指针,这样可以避免传递过程中发生拷贝。参数根据是否需要返回,相应加上const修饰,代码更安全,且编译器能够更大可能地进行参数优化。
1.2. 函数返回
函数返回非基本类型时,同样会发生拷贝,降低性能。C++代码中使用右值引用和返回值优化,不影响性能。
1.3. 循环展开
循环为什么慢,一次循环就要产生自加、比较、跳转3条指令。减少循环次数,就能提升性能。尤其是针对一些循环体内代码少的情况,性能影响更大。如下示例:
int64_t calc1(int64_t n)
{int64_t fact = 1;for (int64_t i = 1; i < n; i++){fact += i;}return fact;
}int64_t calc2(int64_t n)
{int64_t fact = 1;for (int64_t i = 1; i < n; i += 4){fact += i;fact += i + 1;fact += i + 2;fact += i + 3;}return fact;
}int64_t calc3(int64_t n)
{int64_t fact = 1;for (int64_t i = 1; i < n; i += 8){fact += i;fact += i + 1;fact += i + 2;fact += i + 3;fact += i + 4;fact += i + 5;fact += i + 6;fact += i + 7;}return fact;
}gcc分别测试优化级别-O2和-O3的效果,结果显示循环展开效果明显,但是-O3优化级别下展开4层和8层几无差异。
C:\Mingw64\mingw64\bin\g++.exe -std=c++17 -Wall -Wextra -g -O2 -mavx2 -Iinclude -c -MMD src/main.cpp -o src/main.o
C:\Mingw64\mingw64\bin\g++.exe -std=c++17 -Wall -Wextra -g -O2 -mavx2 -Iinclude -o output\main.exe src/main.o -Llib
Executing 'all' complete!
Calc1 932355974711512065:seconds: 26.159987
Calc2 932356074711512065:seconds: 19.535794
Calc3 932356074711512065:seconds: 9.783930C:\Mingw64\mingw64\bin\g++.exe -std=c++17 -Wall -Wextra -g -O3 -mavx2 -Iinclude -c -MMD src/main.cpp -o src/main.o
C:\Mingw64\mingw64\bin\g++.exe -std=c++17 -Wall -Wextra -g -O3 -mavx2 -Iinclude -o output\main.exe src/main.o -Llib
Executing 'all' complete!
Calc1 932355974711512065:seconds: 13.093723
Calc2 932356074711512065:seconds: 6.641366
Calc3 932356074711512065:seconds: 6.6052401.3. 查表
例如计算char类型中bit1的个数,事先准备256大小的数组,存储对应下标的bit1个数。这样在使用时,直接通过数据下标来查询对应的bit1个数,性能非常好。
1.4. 慎用位域
位域节省空间,但是其读写性能非常差,在性能关键处,慎用位域变量。
1.5. 尾递归
我们知道递归容易导致栈爆了,但是很多场景下递归又非常好用。如何避免递归调用栈爆了呢?使用尾递归技术。
尾递归的递归调用必须是函数体内的最后一个操作。这意味着在递归调用之后不应有任何其他计算或表达式。这个要求是为了确保在递归调用之后没有需要保存的局部变量或表达式结果,从而可以通过直接替换参数值并跳转到函数开头来优化。可以简单理解为递归调用发生时,前面的临时变量都可以覆盖操作,不用保存,这样就可以优化栈内存不断增加的问题。示例:
unsigned long long factorialTail(int64_t n, unsigned long long result)
{if (n == 0){return result;}return factorialTail(n - 1, result * n);
}unsigned long long factorial(int64_t n)
{if (n == 0){return 1;}return n * factorial(n - 1);
}factorial在很多讲解中被认为不符合尾递归优化,因为要暂存n,可能导致栈爆了。但是现代编译器很聪明,只要开启了-O2或-O3即会开启尾递归优化,上面两个代码都可以正常优化,无论多么深的调用,都不会异常。
1.6. 位运算替换算术运算
位运算在2的倍数操作时,非常方便,性能比较好。如
int x = y << 3; // 相当于y*8
int x = y >>4; // 相当于y/16
int x = y & 7; // 相当于y%8在低功耗嵌入式32位MCU中,位操作一般需要一个指令周期完成操作。而乘法要2个指令周期。在不支持浮点运算的MCU中,除法是编译器通过乘法操作来模拟的,所以性能更低。取余操作类似除法操作,性能很低。
所以像这些2的倍数的乘法除法取余操作,使用位运算性能会大幅提升。
1.7. 0大小数组
0大小数组不是C/C++的标准语法,是编译器的扩展语法,其也被称为"柔性数组"(Flexible Array)。armcc和gcc均支持此语法。0大小数组不占用结构大小,只是一个占位符。传统的指针可能导致结构体变量出现缓存不友好,影响性能。如果使用此结构,简单方法,且缓存非常友好。在Windows SDK和Linux内核中均有使用此语法形式。
1.8. 减少循环中的判断
分支预测错误非常影响性能,所以在循环中尽量少用判断。在性能关键处的判断,可以加上__builtin_expect来优化。
// Bad
void calc(bool bFlag)
{init();for (int i = 0; i < 10000000; i++){if (bFlag){dosomeA();}else{doSomeB();}}
}// Good
void calc(bool bFlag)
{init();if (bFlag){for (int i = 0; i < 10000000; i++){dosomeA();}}else{for (int i = 0; i < 10000000; i++){dosomeA();}}
}void main()
{calc(true);calc(false);
}1.9. const、restrict和static
const和static应用尽用,不仅代码更安全可靠,编译器也能更明确代码的意图,可以更进一步地对代码进行优化,如更好的内联,更好的变量替换等,进而提升性能。
restrict是C99中新引入的关键字,指示指针是唯一访问某个内存区域的,从而帮助编译器进行更好的优化。
1.10. 不定义不使用的返回值
函数定义并不知道函数返回值是否被使用,假如返回值从来不会被用到,应该使用void来明确声明函数不返回任何值。
1.11. 异步计算
1.11.1 单核
要提升性能,就不能让CPU停下来,那么在面对一些高时延IO操作时。有一些外设,如UART,一般配置了中断,这样就不轮询来监听UART,专心做正常的事情,UART中断产生了,就来处理UART即可,这样就可以充分利用CPU。
还有一些外设,操作响应慢,如NAND Flash,如果一直轮询来等待NAND Flash响应,非常浪费CPU资源。此时可以使用异步计算,先去做其他事情,估算到NAND Flash差不多结束操作时,再回来轮询NAND Flash状态进行相应的处理。在等待NAND Flash响应的这段时间,虽然可以去做A事情,但是A事件做到一半的时候,先暂存A事情的相差状态,再去响应NAND Flash。响应完NAND Flash之后,再回来接着恢复A事情的相关状态,继续A事情。这种操作方式,非常影响代码编写。在单核单线程CPU中,无法使用多线程,此时就非常需要一个好的异步架构来解决上述问题。方案有两个,一个是使用一些RTOS的多任务模型,一个是使用协程,都可以提升较好的异步计算方案来应对上述场景。
1.11.2 多核
在多核架构MCU中,依然会面临外设阻塞的问题,如果计算资源足够,可以某个核阻塞等待。如果计算资源有限,可以多核并行计算结合多任务模型或协程来实现异步计算。
1.12. 事件驱动框架
一个好的框架,能够提升代码的整体性能。事件驱动架构就是一个追求实时性能的框架。事件驱动的架构由生成事件流的事件生成者和侦听事件的事件使用者组成 。
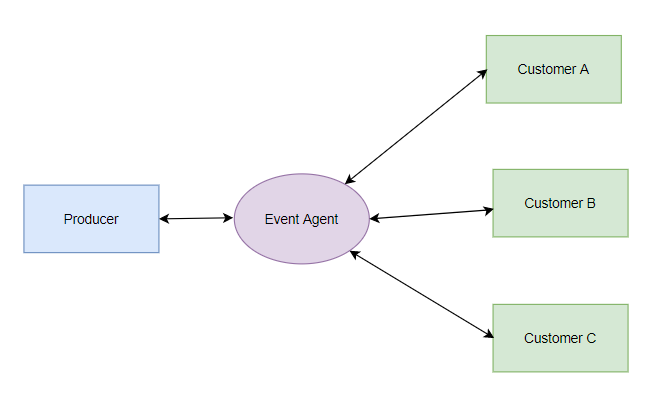
事件驱动框架是基于发布-订阅设计模式实现的,生产者产生需要处理的相关事件,消费者订阅想要处理的事件(通过回调函数注册),当事件产生时,事件代理将根据注册信息调用相应的消费者处理。多个消费者之间的采用多核或异步计算模型处理。事件代理可以将所有事件整理之后再来通知相应的消费者处理。
1.13. 生成式AI
生成式AI随着ChatGPT的出现,进化更加快了,越来越聪明了。GPT-4,Claude 3还有Gemini Pro都非常厉害。我们会因为思维、信息的局限,走进一些误区。所以在性能关键处的优化,我们都可以请教生成式AI,让它给我们一些意见或建议,指导我们更好地进行性能优化。优化的内容可以是具体代码,也可以是数据结构或算法的选择,也可以是架构的优缺点分析等。
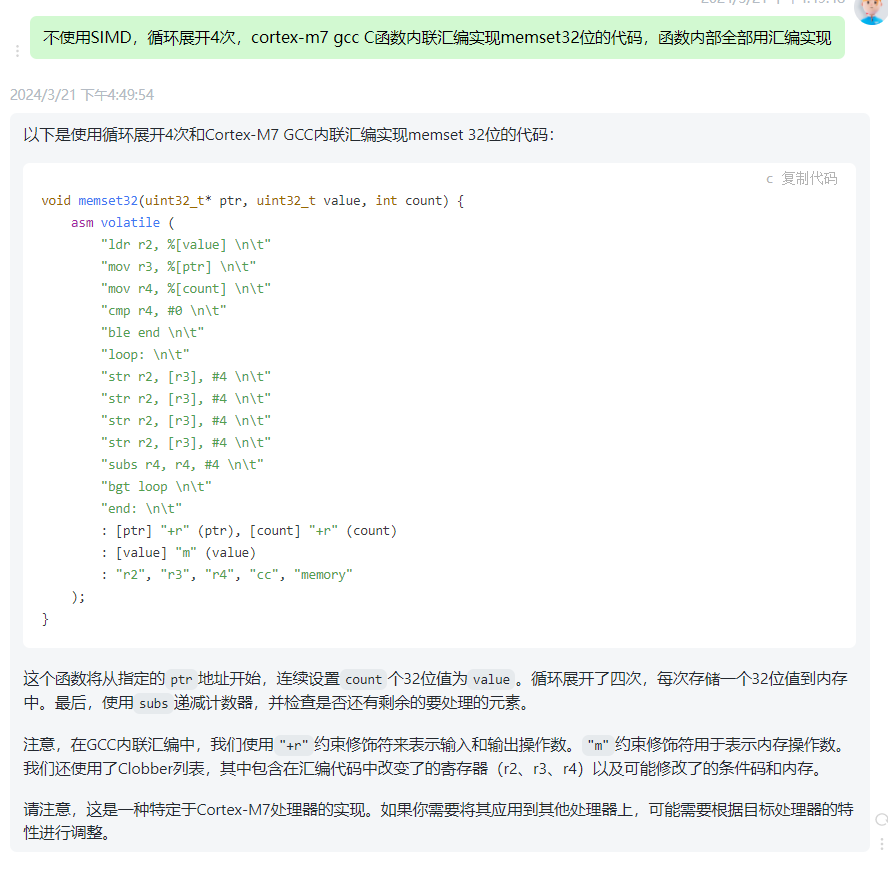
有些关键的地方,汇编代码更有效率,但是汇编代码编写比较麻烦。虽然内联汇编简化了传参和返回,但是编写依然不容易。此时我们就可以借助生成式AI,如下图所示的Prompt,生成的代码测试直接可用,不用修改。
2. 其他
避免性能负优化,也是一种优化性能的方法。另外,理论和实际可能存在一些误解,关键优化一定要真机验证。
2.1. 交换函数
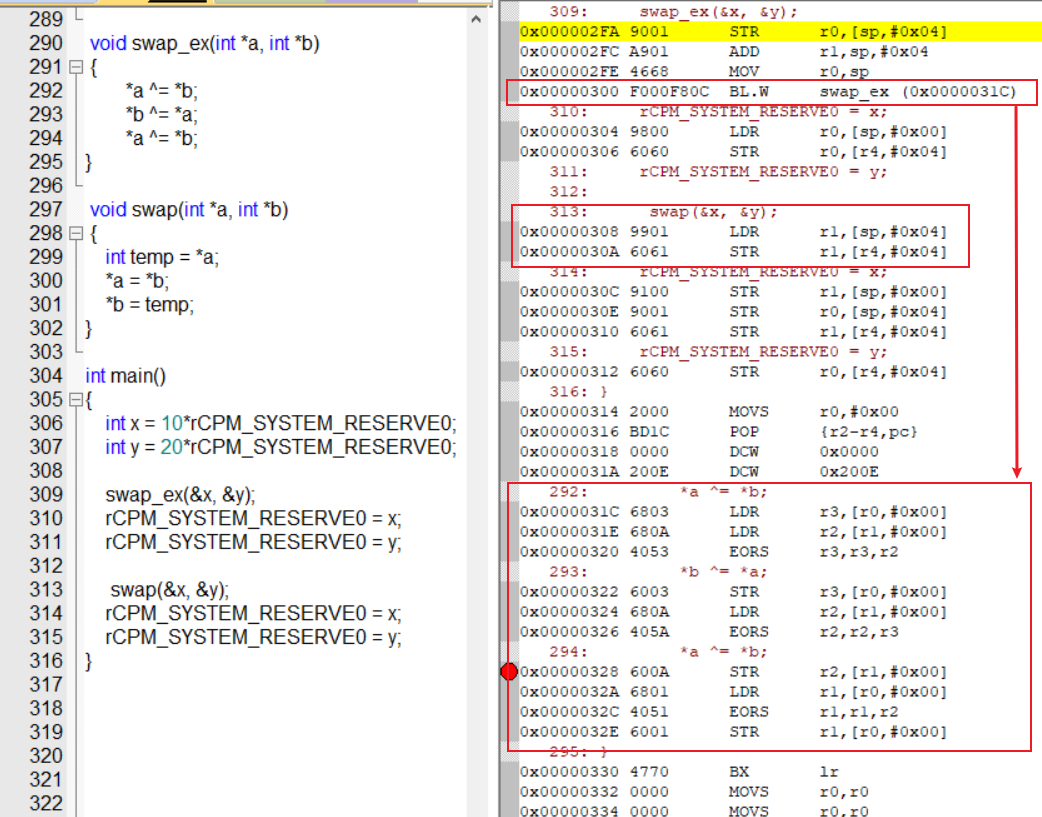
例如交换变量的函数,有人可能以为不用中间变量是不是效率更高,看起来可能是。但是在编译器性能优化下,交换变量的函数直接被优化掉了,编译器直接将两个变量对应的寄存器交换使用即可。gcc的编译结果略有差异,但是swap_ex函数的性能依然较差。
2.2. volatile
volatile作用是禁止编译器优化变量的访问,强制每次从主存上进行存取。
- 硬件寄存器对应的变量,需要实时响应,所以需要禁止优化到寄存器上操作。
- 中断函数与主流程函数的交互变量,也需要实时响应,所以要禁止优化。
- 多核交互的变量,,也需要实时响应,所以要禁止优化。
其他情况下,不要使用volatile,影响性能。
2.3. 不影响性能的代码
2.3.1. 前置自加和后置自加
i++;
++i;
i--;
--i;
for {;;}
while (1)如果上述代码未优化,性能上确实有差异,但是在开启优化之后,性能是完全一样的。
2.3.2. 栈变量
void test1()
{int sum = 0;for (int i = 0; i < 10; i++){int temp = i*2;sum += temp;}
}void test2()
{int sum = 0;int temp = 0;for (int i = 0; i < 10; i++){temp = i*2;sum += temp;}
}栈变量和堆变量不一样。堆变量需要申请释放。栈变量不需要申请释放,用与不用栈内存都在那里放着的。C99之后支持的新语法,栈变量可以随便放,不需要放置在块作用域的最前面。栈遵循最小作用域原则即可。
2.3.3. 寄存器
最终实际参与计算的都是寄存器,32位CPU上的大小都是32位的,64位CPU上一般是兼容32寄存器,也即64位CPU有两套寄存器。
在32位CPU上,计算时,无论是int,short还是char类似,最终都是加载到32位寄存器上进行计算,最终结果也是存在32位寄存器上。也就是说,参与计算的变量是int还是short或char,不影响计算的性能。
在64位CPU上,在数据真实大小小于32位时,用int64还是用int32参与计算,性能是一样的。
2.4. 避免过早优化
著名计算机科学家、图灵奖得主,Donald Knuth曾说过:Premature optimization is the root of all evil (过早优化是万恶之源)。
针对x86_64或Cortext-A系列,现在的编译器和CPU非常智能化,能够帮你极好地优化代码执行性能。所以在开发前期,不必过分花力气去优化代码。在后期发现需要提升性能的时候,再来针对性地优化代码,收益付出比会更大。
避免过早优化不是说设计之初始不考虑优化,而是不要花过多时间去关注一些非优先项的性能优化。
2.5. 验证
由于编译器和处理器的发展,有一些优化它们已经做得很好。过分的手动优化,反倒会干扰编译器和处理器来进行优化。如循环展开,预取指令等,针对一些基本的代码结构,编译器能够做得比较好,所以自行进行优化的代码,一定要进行基准测试。
有一些代码的场景,依据数据局部性的优化和依据分支预测的优化是相斥的,此时同样需要基于实际情况来模拟验证,决定最终优化方案。


![每日一题 --- 977. 有序数组的平方[力扣][Go]](https://img-blog.csdnimg.cn/direct/cc73369402bb40f0ba52de6a070fb35a.png)