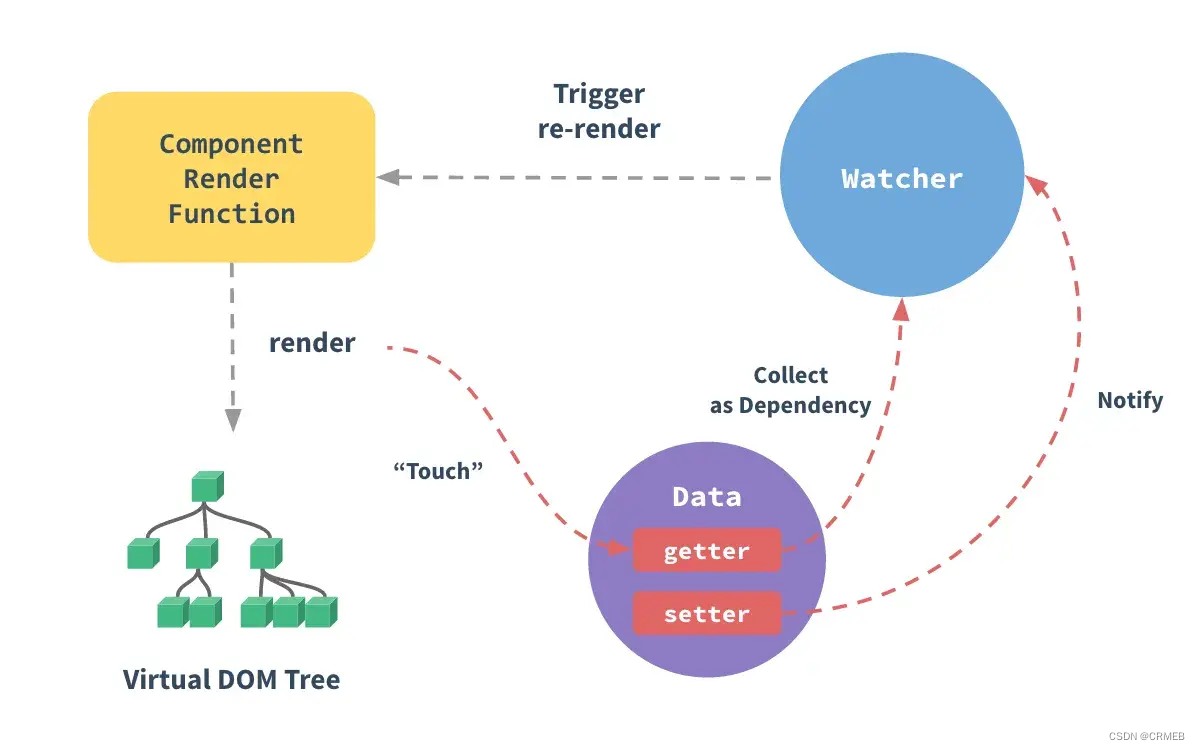
文章目录
- 前言
- 一、导入相关包与配置
- 二、主函数main
- 2.1 checks:检查rank值来判断是否打印参数、检查git仓库、检查包的安装
- 2.2 判断是否恢复上一次模型训练
- 提问:opt.data, opt.cfg, opt.hyp, opt.weights, opt.project各是什么?
- 2.3 DDP mode:
- 2.4 调用train模型训练函数
- 三、train(hyp, opt, device, callbacks)函数
- 3.1 参数解包赋值给对应的变量,并调用回调函数
- 3.2 保存权重文件的目录
- 3.3 超参数:加载了超参数文件
- 3.4 保存使用过的hyp和opt文件
- 3.5 记录日志信息
- 3.6 基本配置:(创建图表、是否有CUDA、检查数据集及路径、确定类别数和名称)
- 3.7 检查和加载权重文件yolov5s.pt
- 提问:既然我们已经有了yolov5的训练好的模型了,那为什么还要创建一个新的模型csd呢?
- 3.8 冻结yolo网络的指定层数
- 3.9 检查图片和批的大小
- 3.10 创建深度学习的优化器(Optimizer),学习率调度器(Scheduler)随机衰减策略以及指数移动平均(EMA)的方法
- 3.11 根据条件选择是否使用多显卡并行模式和分布式训练的同步批量归一化
- 3.12 训练数据加载器(Trainloader)的创建过程
- 3.13 处理进程0
- 提问:进程0是什么?
- 3.14 模型属性的设置
- 3.15 正式开始训练
- ①计算训练过程中的批次数量和预热迭代次数
- ②初始化训练的一些设置
- ③开始一轮一轮(epoch)的训练:for epoch in range(start_epoch, epochs)
- (1)首先更新图片的权重
- 提问:为什么每一轮都要更新图片的权重?
- (2)更新数据增强参数、初始化平均损失、设置训练数据加载器的采样器、创建进度条并初始化优化器。
- 介绍一下在训练过程中一些参数的含义:
- (3)一个批次循环,涉及了多个操作,包括热身、模型前向传播、损失计算、反向传播优化等
- ④每一轮批次训练完后,更新学习率,并进行指标评估
- ⑤更新最佳mAP值,并进行检查记录
- ⑥保存模型
- 3.16 最后一轮,训练结束的收尾工作
- 总结
前言
看一下train文件的具体结构:

一、导入相关包与配置
try:import comet_ml # must be imported before torch (if installed)
except ImportError:comet_ml = Noneimport numpy as np
import torch
import torch.distributed as dist
import torch.nn as nn
import yaml
from torch.optim import lr_scheduler
from tqdm import tqdmFILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relativeimport val as validate # for end-of-epoch mAP
from models.experimental import attempt_load
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.autobatch import check_train_batch_size
from utils.callbacks import Callbacks
from utils.dataloaders import create_dataloader
from utils.downloads import attempt_download, is_url
from utils.general import (LOGGER,TQDM_BAR_FORMAT,check_amp,check_dataset,check_file,check_git_info,check_git_status,check_img_size,check_requirements,check_suffix,check_yaml,colorstr,get_latest_run,increment_path,init_seeds,intersect_dicts,labels_to_class_weights,labels_to_image_weights,methods,one_cycle,print_args,print_mutation,strip_optimizer,yaml_save,
)
from utils.loggers import LOGGERS, Loggers
from utils.loggers.comet.comet_utils import check_comet_resume
from utils.loss import ComputeLoss
from utils.metrics import fitness
from utils.plots import plot_evolve
from utils.torch_utils import (EarlyStopping,ModelEMA,de_parallel,select_device,smart_DDP,smart_optimizer,smart_resume,torch_distributed_zero_first,
)LOCAL_RANK = int(os.getenv("LOCAL_RANK", -1)) # https://pytorch.org/docs/stable/elastic/run.html
RANK = int(os.getenv("RANK", -1))
WORLD_SIZE = int(os.getenv("WORLD_SIZE", 1))
GIT_INFO = check_git_info()简而言之,导包。我举几个比较重要的:
- comet_ml 库,用于实时追踪和记录模型训练过程中的指标和结果。如果导入失败,则将 comet_ml 设置为 None。
- 导入必要的库,包括
numpy、torch、torch.distributed、torch.nn、yaml、lr_scheduler、tqdm 等。 - 导入验证模块 val,用于在每个epoch结束时计算mAP(mean Average Precision)。
- 导入模型加载函数 attempt_load、YOLO模型类
Model,以及一些辅助函数和工具类,如自动锚框检查、自动批处理大小检查、回调函数、数据加载器创建、下载函数、通用函数等。 - 导入损失计算函数 ComputeLoss、评估指标函数 fitness,以及绘图函数 plot_evolve。
- 导入与PyTorch相关的一些工具函数,如早停、模型指数移动平均、设备选择、DDP并行处理、智能优化器、智能恢复、分布式训练等。
- 获取本地进程号 LOCAL_RANK、进程号 RANK、世界大小 WORLD_SIZE,以及检查Git信息。
二、主函数main
if __name__ == "__main__":opt = parse_opt()main(opt)
跟detect检测文件差不多,训练文件也是在主函数里调用解析参数函数parse_opt()并返回参数值,将参数传入main函数执行。
2.1 checks:检查rank值来判断是否打印参数、检查git仓库、检查包的安装
# 如果当前进程的RANK为-1或0,则执行以下操作
if RANK in {-1, 0}:# 打印模型训练参数配置信息print_args(vars(opt))# 检查当前代码库的Git状态check_git_status()# 检查项目所需的Python依赖是否满足要求check_requirements(ROOT / "requirements.txt")
RANK是分布式训练的意思,我们是-1,就单指使用一台电脑进行训练。
2.2 判断是否恢复上一次模型训练
一般来说,如果在训练时,不小心关机或者中断训练了,我想重新训练,则opt.resume为真,执行if里面的语句,获取最后一个模型检查点。
可以利用这个参数将我们之前的训练给恢复过来。因为我们使用的是yolov5s.pt这个训练模型,因此并没有必要传入这个参数,所以它会执行else中的代码内容。
# Resume (from specified or most recent last.pt)
# 恢复模型训练(从指定或最近的last.pt文件)
if opt.resume and not check_comet_resume(opt) and not opt.evolve:# 如果需要恢复模型训练且不需要检查Comet恢复且不是进化模式last = Path(check_file(opt.resume) if isinstance(opt.resume, str) else get_latest_run())# 获取最后一个模型检查点路径opt_yaml = last.parent.parent / "opt.yaml" # train options yaml# 构建训练选项的yaml文件路径opt_data = opt.data # original dataset# 保存原始数据集路径if opt_yaml.is_file():with open(opt_yaml, errors="ignore") as f:d = yaml.safe_load(f)else:d = torch.load(last, map_location="cpu")["opt"]# 加载训练选项opt = argparse.Namespace(**d) # replace# 将加载的选项转换为命名空间opt.cfg, opt.weights, opt.resume = "", str(last), True # reinstate# 重置配置、权重和恢复选项if is_url(opt_data):opt.data = check_file(opt_data) # avoid HUB resume auth timeout# 如果数据集路径是URL,则检查文件以避免HUB恢复授权超时
else代码中首先它会去检查几个文件的路径,包括权重weights、数据集data,cfg、hpy超参数以及保存路径project等,这里我们没有用到cfg,因此它传入为空,紧接着判断cfg与weights是否都为空,如果为空的话,会进行报错。
接下来会进行是否输入evolve判断,决定保存在那个文件夹下面,这里我们没有输入evolve,所以保存在runs/train路径。接着是保存文件的名称。
else:opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = (check_file(opt.data),check_yaml(opt.cfg),check_yaml(opt.hyp),str(opt.weights),str(opt.project),) # checks# 检查数据集、配置、超参数、权重和项目路径assert len(opt.cfg) or len(opt.weights), "either --cfg or --weights must be specified"# 确保配置或权重至少有一个被指定if opt.evolve:if opt.project == str(ROOT / "runs/train"): # if default project name, rename to runs/evolveopt.project = str(ROOT / "runs/evolve")opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume# 如果是进化模式,则修改项目路径并传递恢复选项if opt.name == "cfg":opt.name = Path(opt.cfg).stem # use model.yaml as name# 如果名称为 "cfg",则将使用模型配置文件的名称作为名称opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))# 设置保存模型的目录路径提问:opt.data, opt.cfg, opt.hyp, opt.weights, opt.project各是什么?
opt.data:数据集路径,指定模型训练所使用的数据集的位置或名称。
opt.cfg:配置文件路径,指定模型训练所使用的配置文件的位置或名称,包括模型结构、超参数等信息。
opt.hyp:超参数文件路径,指定模型训练所使用的超参数文件的位置或名称,包括学习率、批大小等超参数设置。
opt.weights:权重文件路径,指定模型训练所使用的初始权重文件的位置或名称,用于模型初始化或恢复训练。
opt.project:项目路径,指定模型训练所在的项目路径或名称,用于保存训练过程中的日志、模型文件等输出结果。
这几个配置在parse_opt()函数里面有设置:
parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt", help="initial weights path")
parser.add_argument("--cfg", type=str, default="", help="model.yaml path")
parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="dataset.yaml path")
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path")
parser.add_argument("--project", default=ROOT / "runs/train", help="save to project/name")
也就是说,权重weights是yolov5s.pt,cfg的默认是没有,数据集data的默认是coco128数据集,超参数hyp的默认是hyps/hyp.scratch-low.yaml,保存路径是runs/train文件夹。
2.3 DDP mode:
就是选择具体的训练设备,opt.device默认是cuda device,即GPU来训练。后面的RANK上面说了是判断是否是分布式训练,这里不是,所以if里面的都不执行。
# DDP modedevice = select_device(opt.device, batch_size=opt.batch_size)if LOCAL_RANK != -1:msg = "is not compatible with YOLOv5 Multi-GPU DDP training"assert not opt.image_weights, f"--image-weights {msg}"assert not opt.evolve, f"--evolve {msg}"assert opt.batch_size != -1, f"AutoBatch with --batch-size -1 {msg}, please pass a valid --batch-size"assert opt.batch_size % WORLD_SIZE == 0, f"--batch-size {opt.batch_size} must be multiple of WORLD_SIZE"assert torch.cuda.device_count() > LOCAL_RANK, "insufficient CUDA devices for DDP command"torch.cuda.set_device(LOCAL_RANK)device = torch.device("cuda", LOCAL_RANK)dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo", timeout=timedelta(seconds=10800))
2.4 调用train模型训练函数
虽然上面讲了那么多代码,其实很多就是设计一个是否是分布式训练的选择,忽略之后,只需要关注最重要的代码,即train这个函数的调用。
opt.evolve是作者给出的一种净化超参数的方法,一般情况下,我们首先采用默认的参数配合部分手动调参,当训练完成后会得到一个效果最好的文件,紧接着会使用遗传算法去改变训练好的参数值,又去训练新的权重文件。不断循环得到多组权重文件,从中挑选出最好的。但是这种方法特别漫长,而且很浪费计算资源,所以我们普通人基本不用去管是否要使用超参数去训练。
# Trainif not opt.evolve:train(opt.hyp, opt, device, callbacks)
# Evolve hyperparameters (optional)else:# Hyperparameter evolution metadata (including this hyperparameter True-False, lower_limit, upper_limit)#..........#..........# 后面是极其冗长的一段代码,直到main函数结束都是超参数训练的代码
所以main函数看到这里就可以了。只关注 train(opt.hyp, opt, device, callbacks)这个函数的调用,后面极其冗长的关于Evolve hyperparameters超参数净化的代码,完全没必要看了。
三、train(hyp, opt, device, callbacks)函数
3.1 参数解包赋值给对应的变量,并调用回调函数
首先读取传入的opt参数并赋值给新的变量,用于后续使用。callback是回调函数,
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze = (Path(opt.save_dir),opt.epochs,opt.batch_size,opt.weights,opt.single_cls,opt.evolve,opt.data,opt.cfg,opt.resume,opt.noval,opt.nosave,opt.workers,opt.freeze,)callbacks.run("on_pretrain_routine_start")
3.2 保存权重文件的目录
先保存权重文件到weights文件夹,如果没有创建就帮助我们创建一个。last是最后一轮的权重文件,best是训练效果最好的权重文件。
# Directoriesw = save_dir / "weights" # weights dir(w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dirlast, best = w / "last.pt", w / "best.pt"
3.3 超参数:加载了超参数文件
先判断超参数是否是字符串类型,如果是就加载超参数文件,并存储到变量hyp中。
# Hyperparametersif isinstance(hyp, str):with open(hyp, errors="ignore") as f:hyp = yaml.safe_load(f) # load hyps dictLOGGER.info(colorstr("hyperparameters: ") + ", ".join(f"{k}={v}" for k, v in hyp.items()))opt.hyp = hyp.copy() # for saving hyps to checkpoints
超参数文件scratch_low.yaml如图所示:
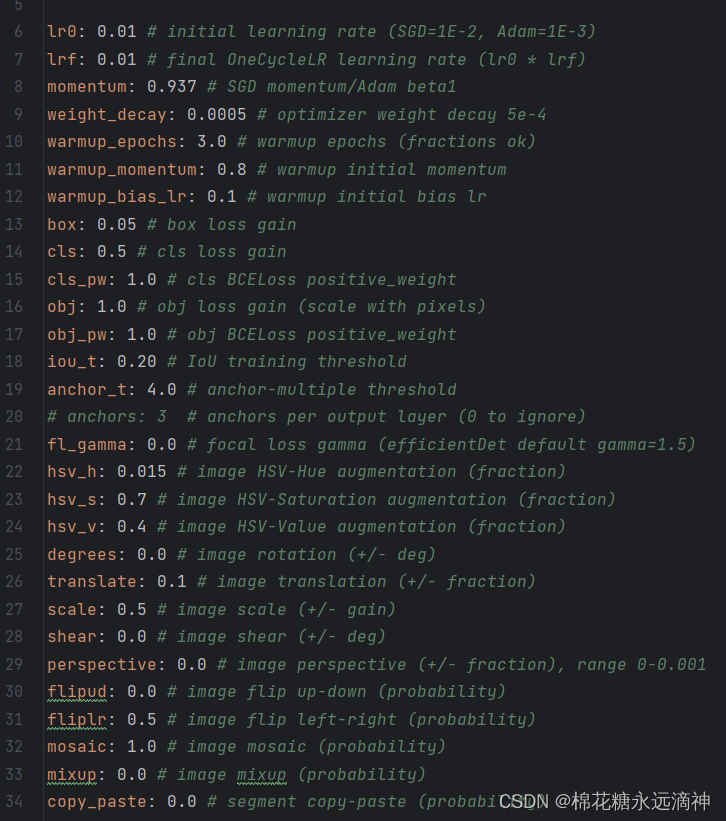
3.4 保存使用过的hyp和opt文件
顾名思义,就是保存使用过的hyp和opt文件。
# Save run settingsif not evolve:yaml_save(save_dir / "hyp.yaml", hyp)yaml_save(save_dir / "opt.yaml", vars(opt))
3.5 记录日志信息
代码设置了日志记录器对象,并注册了相应的回调函数,以便在训练过程中记录和处理日志信息。基于wandb与tensorboard这两个库来完成训练过程中的可视化操作。在这个文件中完成对于程序训练日志的记录过程。

3.6 基本配置:(创建图表、是否有CUDA、检查数据集及路径、确定类别数和名称)
Config文件中,首先基于plots的true或者false反馈是否将训练过程及结果给画出来,紧接着判断电脑是否支持cuda,第三行是为了保证我们的训练是否是可复现的,第四行是与分布式训练相关的,如果不进行分布式训练则不执行。第五行会进行数据集检查读取操作,第六行会取出数据集的训练路径以及验证路径,第七行取出你的类名,第八行会进行类的种数以及类的名称是否相同的判断,不相同会进行报错处理,最后一行会进行是否是coco数据集进行判断,如果是的话会进行一些额外的操作,本次不是,回复false。
# Configplots = not evolve and not opt.noplots # create plotscuda = device.type != "cpu"init_seeds(opt.seed + 1 + RANK, deterministic=True)with torch_distributed_zero_first(LOCAL_RANK):data_dict = data_dict or check_dataset(data) # check if Nonetrain_path, val_path = data_dict["train"], data_dict["val"]nc = 1 if single_cls else int(data_dict["nc"]) # number of classesnames = {0: "item"} if single_cls and len(data_dict["names"]) != 1 else data_dict["names"] # class namesis_coco = isinstance(val_path, str) and val_path.endswith("coco/val2017.txt") # COCO dataset
这里有一个重要问题:check_dataset(data)这一步,第一次训练时我们是没有coco128数据集的,因此执行代码时会自动下载一个coco128数据集并创建一个datasets文件夹来保存。
3.7 检查和加载权重文件yolov5s.pt
模型加载部分,首先会去检测传进来的权重参数后缀名是否以.pt结尾,如果本地没有就回去会尝试去yolov5官方仓库去下载权重文件,加载权重文件,紧接着会根据你的权重文件中会带着一个yolov5s.yaml文件,代码根据yolov5s.yaml进行模型的训练。
提问:既然我们已经有了yolov5的训练好的模型了,那为什么还要创建一个新的模型csd呢?
这块的主要意思通俗的理解就是我们预训练模型是yolov5s.pt,我们的新模型是基于我们自己的识别检测需求在yolov5s的基础上完成的。 看这行代码:
model = Model(cfg or ckpt["model"].yaml, ch=3, nc=nc, anchors=hyp.get("anchors")).to(device)
模型的ch通道是RGB,即3通道。而nc是类别数(number of classes),即目标检测或分类任务中需要识别的类别数量。官方预训练好的模型可以识别80种物体,而我们实际用于其他领域的识别时,需要训练自己的数据集(比如要10种类型),就可以把官方模型参数加载到新的模型中使用。
# Modelcheck_suffix(weights, ".pt") # check weightspretrained = weights.endswith(".pt")if pretrained:with torch_distributed_zero_first(LOCAL_RANK):weights = attempt_download(weights) # download if not found locallyckpt = torch.load(weights, map_location="cpu") # load checkpoint to CPU to avoid CUDA memory leakmodel = Model(cfg or ckpt["model"].yaml, ch=3, nc=nc, anchors=hyp.get("anchors")).to(device) # createexclude = ["anchor"] if (cfg or hyp.get("anchors")) and not resume else [] # exclude keyscsd = ckpt["model"].float().state_dict() # checkpoint state_dict as FP32csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersectmodel.load_state_dict(csd, strict=False) # loadLOGGER.info(f"Transferred {len(csd)}/{len(model.state_dict())} items from {weights}") # reportelse:model = Model(cfg, ch=3, nc=nc, anchors=hyp.get("anchors")).to(device) # createamp = check_amp(model) # check AMP
3.8 冻结yolo网络的指定层数
Freeze是一个冻结过程,跟我们的传递参数有关,默认不冻结,如果在opt中我们传入10即表示我们冻结了backbone部分,也就是说我们训练过程中只用了head部分。通过Freeze这部分代码,你可以手动去控制你想冻结哪些层。
freeze默认是0。

10层就是backbone的结构。

# Freezefreeze = [f"model.{x}." for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freezefor k, v in model.named_parameters():v.requires_grad = True # train all layers# v.register_hook(lambda x: torch.nan_to_num(x)) # NaN to 0 (commented for erratic training results)if any(x in k for x in freeze):LOGGER.info(f"freezing {k}")v.requires_grad = False
3.9 检查图片和批的大小
Image size主要是用于检查输入图片的尺寸满不满足32的倍数,如果不满足的话它会帮你自动补成32的倍数。Batchsize部分一般不会去执行,除非我们手动输入-1,默认是16。
# Image sizegs = max(int(model.stride.max()), 32) # grid size (max stride)imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple# Batch sizeif RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch sizebatch_size = check_train_batch_size(model, imgsz, amp)loggers.on_params_update({"batch_size": batch_size})
3.10 创建深度学习的优化器(Optimizer),学习率调度器(Scheduler)随机衰减策略以及指数移动平均(EMA)的方法
这一块不细讲了,比较复杂。
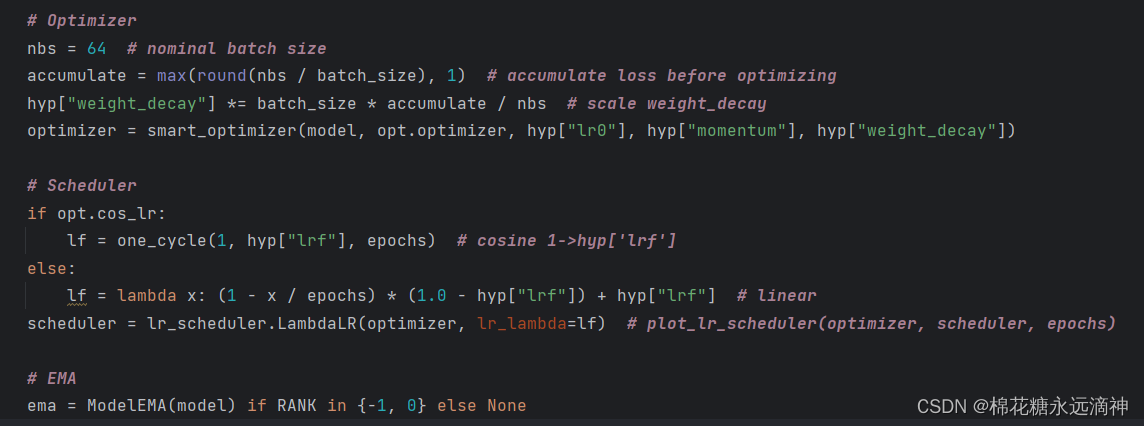
3.11 根据条件选择是否使用多显卡并行模式和分布式训练的同步批量归一化
#DP mode会判断是不是用了多张显卡,#SyncBatchNorm是跟分布式训练相关的,可以忽略。
# DP modeif cuda and RANK == -1 and torch.cuda.device_count() > 1:LOGGER.warning("WARNING ⚠️ DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n""See Multi-GPU Tutorial at https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training to get started.")model = torch.nn.DataParallel(model)# SyncBatchNormif opt.sync_bn and cuda and RANK != -1:model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)LOGGER.info("Using SyncBatchNorm()")
3.12 训练数据加载器(Trainloader)的创建过程
这段代码的作用是准备训练数据,包括创建数据加载器、处理标签信息以及确保数据集的类别数符合要求。这些步骤是为了在训练模型之前对数据进行适当的预处理和准备工作,以确保训练过程的顺利进行和模型的有效训练
# Trainloadertrain_loader, dataset = create_dataloader(train_path,imgsz,batch_size // WORLD_SIZE,gs,single_cls,hyp=hyp,augment=True,cache=None if opt.cache == "val" else opt.cache,rect=opt.rect,rank=LOCAL_RANK,workers=workers,image_weights=opt.image_weights,quad=opt.quad,prefix=colorstr("train: "),shuffle=True,seed=opt.seed,)labels = np.concatenate(dataset.labels, 0)mlc = int(labels[:, 0].max()) # max label classassert mlc < nc, f"Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}"
3.13 处理进程0
代码对进程0进行了特殊处理,包括创建验证数据加载器、自动锚框调整、模型精度设置等,并在分布式数据并行模式下对模型进行了设置,以优化训练过程并提高训练效果。
提问:进程0是什么?
在分布式计算中,进程0通常指的是主进程或主节点(Master Process/Node)。在一个分布式系统中,通常会有多个进程或节点同时运行,而进程0通常被用作主要的控制节点或协调节点,负责整个系统的管理和协调工作。进程0通常会承担以下功能:
- 进程0负责分配任务给其他进程或节点,并协调它们的工作流程。
- 进程0通常负责管理整个系统的全局状态信息,包括参数设置、模型初始化等。
- 进程0可能会负责加载和预处理数据,然后将数据分发给其他进程进行处理。
- 进程0通常会负责初始化模型参数,并在需要时同步各个进程的模型状态。
- 进程0可能会负责收集各个进程的计算结果,并最终汇总输出结果。
# Process 0if RANK in {-1, 0}:val_loader = create_dataloader(val_path,imgsz,batch_size // WORLD_SIZE * 2,gs,single_cls,hyp=hyp,cache=None if noval else opt.cache,rect=True,rank=-1,workers=workers * 2,pad=0.5,prefix=colorstr("val: "),)[0]if not resume:if not opt.noautoanchor:check_anchors(dataset, model=model, thr=hyp["anchor_t"], imgsz=imgsz) # run AutoAnchormodel.half().float() # pre-reduce anchor precisioncallbacks.run("on_pretrain_routine_end", labels, names)# DDP modeif cuda and RANK != -1:model = smart_DDP(model)
3.14 模型属性的设置
包括调整一些超参数(hyperparameters)以及将相关信息附加到模型上.模型的属性进行了调整和设置,包括调整损失权重、附加类别数、超参数、类别权重和类别名称等信息到模型上,以便在训练过程中使用这些信息进行模型优化和评估
# Model attributesnl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)hyp["box"] *= 3 / nl # scale to layershyp["cls"] *= nc / 80 * 3 / nl # scale to classes and layershyp["obj"] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layershyp["label_smoothing"] = opt.label_smoothingmodel.nc = nc # attach number of classes to modelmodel.hyp = hyp # attach hyperparameters to modelmodel.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weightsmodel.names = names
3.15 正式开始训练
这里面还有很多步骤,一步一步来。
①计算训练过程中的批次数量和预热迭代次数
代码计算了训练过程中的批次数量和预热迭代次数,预热迭代次数通常用于在训练初期逐渐增加学习率,以帮助模型更快地收敛到最优解。
t0 = time.time()nb = len(train_loader) # number of batchesnw = max(round(hyp["warmup_epochs"] * nb), 100) # number of warmup iterations, max(3 epochs, 100 iterations)
②初始化训练的一些设置
初始化最后一次优化步骤last_opt_step的值为-1。
初始化存储每个类别平均精度map的数组maps。
初始化存储训练结果指标的元组results。
设置学习率调度器的 last_epoch 属性。是pytorrch源码相关,比较复杂,忽略。
初始化混合精度训练的梯度缩放器。
初始化早停策略。
初始化损失计算类。
last_opt_step = -1maps = np.zeros(nc) # mAP per classresults = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)scheduler.last_epoch = start_epoch - 1 # do not movescaler = torch.cuda.amp.GradScaler(enabled=amp)stopper, stop = EarlyStopping(patience=opt.patience), Falsecompute_loss = ComputeLoss(model) # init loss classcallbacks.run("on_train_start")LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'f"Logging results to {colorstr('bold', save_dir)}\n"f'Starting training for {epochs} epochs...')
③开始一轮一轮(epoch)的训练:for epoch in range(start_epoch, epochs)
(1)首先更新图片的权重
提问:为什么每一轮都要更新图片的权重?
在深度学习训练中,更新图像权重的操作通常用于解决类别不平衡(class imbalance)的问题。类别不平衡是指在训练数据中不同类别的样本数量差异很大,导致模型在训练过程中更倾向于学习样本数量多的类别,而忽略样本数量少的类别,从而影响模型的性能和泛化能力。 通过更新图像权重,可以调整不同类别样本在训练过程中的重要性,使模型更加关注那些难以分类的样本,从而提高模型对少数类别的学习效果。
# Update image weights (optional, single-GPU only)if opt.image_weights:cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weightsiw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weightsdataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
(2)更新数据增强参数、初始化平均损失、设置训练数据加载器的采样器、创建进度条并初始化优化器。
# Update mosaic border (optional)# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)# dataset.mosaic_border = [b - imgsz, -b] # height, width bordersmloss = torch.zeros(3, device=device) # mean lossesif RANK != -1:train_loader.sampler.set_epoch(epoch)pbar = enumerate(train_loader)LOGGER.info(("\n" + "%11s" * 7) % ("Epoch", "GPU_mem", "box_loss", "obj_loss", "cls_loss", "Instances", "Size"))if RANK in {-1, 0}:pbar = tqdm(pbar, total=nb, bar_format=TQDM_BAR_FORMAT) # progress baroptimizer.zero_grad()
介绍一下在训练过程中一些参数的含义:

epoch:训练的轮数
gpu_mem:显存占用
box、obj、cls:盒子损失(box loss)、目标损失(object loss)和分类损失(class loss)
labels:平均每轮训练中出现的标注框的个数
img_size:画面尺寸
后面是显示的进度条,每一轮训练所需的时间,处理速度。
(3)一个批次循环,涉及了多个操作,包括热身、模型前向传播、损失计算、反向传播优化等
①warmup:在训练初期进行学习率的warmup操作,逐渐增加学习率,同时调整动量等优化器参数。
②Multi-scale:如果启用了多尺度训练选项,随机选择一个尺度对图像进行缩放,以增加模型对不同尺度目标的适应能力。
③前向传播(forward):使用模型进行前向传播,得到预测结果,并计算损失值,同时根据目标数据计算损失函数。
④反向传播(Backward):使用自动混合精度(Automatic Mixed Precision, AMP)进行反向传播,计算梯度并更新模型参数。
⑤优化器更新(Optimize):根据累积梯度次数进行优化器更新,包括梯度裁剪、梯度反向传播、优化器步骤等操作。
⑥日志记录log:记录训练过程中的损失值、GPU内存占用情况等信息,并在每个批次结束时运行相应的回调函数。
④每一轮批次训练完后,更新学习率,并进行指标评估
如果跑完的这一轮不是最终的一轮的话,就会在验证集上跑一次,对这一轮的模型进行评价指标评估。
# Schedulerlr = [x["lr"] for x in optimizer.param_groups] # for loggersscheduler.step()if RANK in {-1, 0}:# mAPcallbacks.run("on_train_epoch_end", epoch=epoch)ema.update_attr(model, include=["yaml", "nc", "hyp", "names", "stride", "class_weights"])final_epoch = (epoch + 1 == epochs) or stopper.possible_stopif not noval or final_epoch: # Calculate mAPresults, maps, _ = validate.run(data_dict,batch_size=batch_size // WORLD_SIZE * 2,imgsz=imgsz,half=amp,model=ema.ema,single_cls=single_cls,dataloader=val_loader,save_dir=save_dir,plots=False,callbacks=callbacks,compute_loss=compute_loss,)⑤更新最佳mAP值,并进行检查记录
在每个训练周期结束时更新最佳mAP值,并进行早停检查,同时记录日志值并运行相应的回调函数
# Update best mAPfi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]stop = stopper(epoch=epoch, fitness=fi) # early stop checkif fi > best_fitness:best_fitness = filog_vals = list(mloss) + list(results) + lrcallbacks.run("on_fit_epoch_end", log_vals, epoch, best_fitness, fi)
⑥保存模型
先保存本轮模型为last.pt,在适当的时机保存模型,包括保存最新模型、最佳模型以及按周期保存模型,同时记录保存的相关信息
# Save modelif (not nosave) or (final_epoch and not evolve): # if saveckpt = {"epoch": epoch,"best_fitness": best_fitness,"model": deepcopy(de_parallel(model)).half(),"ema": deepcopy(ema.ema).half(),"updates": ema.updates,"optimizer": optimizer.state_dict(),"opt": vars(opt),"git": GIT_INFO, # {remote, branch, commit} if a git repo"date": datetime.now().isoformat(),}# Save last, best and deletetorch.save(ckpt, last)if best_fitness == fi:torch.save(ckpt, best)if opt.save_period > 0 and epoch % opt.save_period == 0:torch.save(ckpt, w / f"epoch{epoch}.pt")del ckptcallbacks.run("on_model_save", last, epoch, final_epoch, best_fitness, fi)
3.16 最后一轮,训练结束的收尾工作
训练结束:记录训练完成的信息,包括完成的周期数和训练所花费的时间。如果当前模型是最佳模型,则再次在验证集上验证评估,计算结果并保存相关信息。
运行回调函数 “on_train_end”,传递最新模型、最佳模型、当前周期数和验证结果等参数。
最后释放CUDA缓存,清理GPU内存。返回验证结果。
# end epoch ----------------------------------------------------------------------------------------------------# end training -----------------------------------------------------------------------------------------------------if RANK in {-1, 0}:LOGGER.info(f"\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.")for f in last, best:if f.exists():strip_optimizer(f) # strip optimizersif f is best:LOGGER.info(f"\nValidating {f}...")results, _, _ = validate.run(data_dict,batch_size=batch_size // WORLD_SIZE * 2,imgsz=imgsz,model=attempt_load(f, device).half(),iou_thres=0.65 if is_coco else 0.60, # best pycocotools at iou 0.65single_cls=single_cls,dataloader=val_loader,save_dir=save_dir,save_json=is_coco,verbose=True,plots=plots,callbacks=callbacks,compute_loss=compute_loss,) # val best model with plotsif is_coco:callbacks.run("on_fit_epoch_end", list(mloss) + list(results) + lr, epoch, best_fitness, fi)callbacks.run("on_train_end", last, best, epoch, results)torch.cuda.empty_cache()return results
总结
到此为止,训练的全过程就结束了。总结一下train运行的流程:
- 参数解析(parse_opt函数): 在训练开始前,首先解析用户提供的参数,包括模型配置、数据路径、训练参数等。
确定训练的一些设置,如批次大小、学习率、训练周期数等。 - 主函数(main函数): 在主函数中,首先进行参数解析,获取用户设置的训练参数。 加载数据集,并准备训练所需的数据,如训练集、验证集等。
初始化模型、优化器和其他必要组件。 调用训练函数(train)开始训练过程。 - 训练函数(train函数): 在训练函数中,循环执行多个训练周期,每个周期包括以下步骤: 对训练集进行迭代,计算损失值并更新模型参数。
在适当的时机进行模型评估,计算mAP等指标。 更新最佳mAP值,并进行早停检查。 保存模型,包括最新模型、最佳模型以及按周期保存模型。 - 训练结束: 当所有训练周期完成后,进行收尾工作: 记录训练完成的信息,包括周期数和训练时间。
处理最新模型和最佳模型,去除优化器信息并进行验证评估。 运行训练结束的回调函数,传递相关信息。 释放GPU内存。 返回结果:
返回训练过程中的验证结果。




![每日一题 --- 977. 有序数组的平方[力扣][Go]](https://img-blog.csdnimg.cn/direct/cc73369402bb40f0ba52de6a070fb35a.png)