哈希算法是程序开发过程中最广泛接触到的的算法之一,典型的应用有安全加密、数据校验、唯一标识、散列函数、负载均衡、数据分片、分布式存储。前些天刚接触到夜莺项目,听介绍目前V6版本集群方式部署,告警生成是通过一致性哈希(哈希环)去分片处理,不过我细想一下,对一致性哈希这个知识点好像了解过,但是又没太深印象,说不出具体是什么原理,怎么用,有哪些注意的地方。本文简单记录,希望也能给其他人作为初步了解所用。
另外强烈推荐大家在需要落地企业级观测平台方案考虑使用 夜莺(nightingale) ,开源、用户多而且社区氛围不错,官方怕大家网络不方便访问,还特地开了答疑论坛。
1.解决怎样的问题
一个常见的结论是在需要均匀的解决数据分布场景时通过引入一致性哈希算法可以很好解决此类问题。
一致性哈希诞生,是麻省理工学院在1997年提出的一种分布式哈希(DHT)实现算法,其设计目标是为了解决因特网中的热点(Hot Spot)问题,将来自网络上的流量动态的均匀分发到不同的服务器处理;
处理大量数据时很可能是遇到类似这样的难点:
- 1.处理文件很大单台机器内存受限无法计算;
- 2.如果单台机器处理这样大量数据处理耗时很大;
为了突破单机内存,cup资源限制,借助分片思路,先切分数据,再利用多台机器提高处理速度,最后在合并起来得到最终结果,这个处理过程也是MapReduce的基本思想,不过再思考一下,仅仅是解决上面问题话,一个普通的哈希算法就能解决;为什么会要引入一致性哈希算法呢?
当数据增多,需要扩容机器时,直接加上新机器,那么所有数据会遇到一个问题,就是之前哈希值不对了,通常哈希值计算和机器数量有关,最简单就是对机器数量取模,当数量变化是需要重新计算哈希值,然后搬移数据到正确的机器上,用在缓存场景就相当于所有缓存失效,请求数据穿透缓存,直接请求数据库,这样就很容易发生雪崩效应。所以就需要一种新方法,让加入机器后,不需要做大量数据迁移。
2.原理介绍
ask:致性哈希原理介绍
answer:
一致性哈希是一种用于分布式系统中数据分片和负载均衡的算法。它的核心思想是将数据根据哈希值映射到一个环形空间中,然后将节点也映射到环上。当需要查找某个数据时,先计算该数据的哈希值,然后沿着环的顺时针方向找到第一个大于等于该哈希值的节点,即为该数据所在的节点。这样可以将数据均匀地分布在各个节点上,并且在节点动态添加或删除时,只需要重新映射该节点的哈希值,而不需要重新映射所有数据的哈希值,从而避免了数据迁移的开销。
一致性哈希算法的优点是具有高度的可扩展性和容错性,能够自动适应节点的动态变化,同时保证数据的一致性和负载均衡。它被广泛应用于分布式缓存、分布式数据库、负载均衡等领域。
Powered by ChatGPT
再借用大牛们对一致性哈希原理介绍的,通过hash函数映射到一个哈希环上,哈希环可以理解为一个连续变好的循环链表,一般会用32位的哈希值,可以映射2^32个值。
假设key1和key2经过计算都命中哈希环上一个机器节点0,此时新加入一个节点n,节点n接管了部分原来归属于节点0的区域(只有key2在其中),此时再次访问key1和key2,只会有key2因为变更节点,需要重新迁移数据。
3.一致性哈希优点
从上面原理介绍,我们可以很容易看到一致性哈希算法在可伸缩性的优点,我们简单模拟下看看是否解决之前的雪崩问题,另外这里我们再讨论下它均衡性优点。
我们模拟一下当机器B故障,需要在服务列表里摘除机器B。我们直接将故障机器B从哈希环上移除,原来归属于机器B的数据按照一致性哈希规则,应该被缓存到哈希环上下一个机器节点例如机器C。其他数据并不会因此产生变化,只有一部分缓存失败需要重新构建,从而不至于所有全部缓存失效导致的雪崩效应问题。
不过就像买家秀和买家秀的巨大差距一样,通常理想很丰满,现实很骨感。只是按照上述定义,哈希环上机器映射大概率是没法均分的,缓存对象很大可能被集中在某一台机器上,分布极度不均,产生hash环的偏斜,极端情况下,仍然可能引起系统崩溃。所以一致性哈希算法中使用‘虚拟节点’解决这个问题。
所谓‘虚拟节点’就是有实际节点虚拟复制而来的节点,填充在哈希环上,让机器尽量多,均匀的出现在哈希环上,所以通常是一个实际节点对应多个虚拟节点。有虚拟节点加入后再看哈希环,我们就可以达到良好的均衡性,减少哈希环偏斜带来的影响,缓存也就被均匀分布概率越大。
4. 夜莺项目-告警
根据关键字hashring我们可以看到这些相关的代码,确实都是和告警相关,我们再细细研究一下
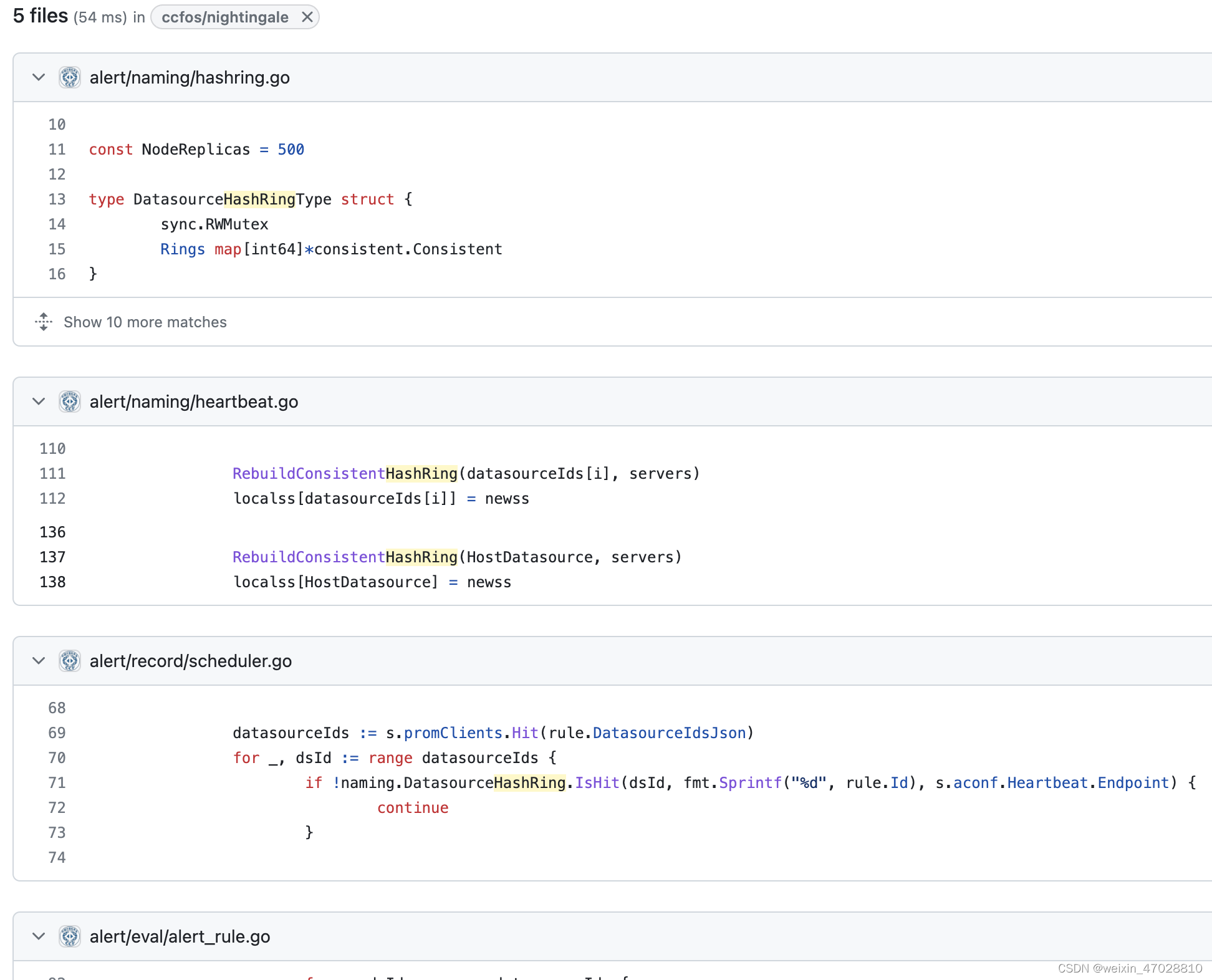
首先很明显,通过 hashring.go中 DatasourceHashRingType 这个结构体我们可以看这里用的是golang 一致性hash 库consistent,我们再看看具体是如何使用的
package namingimport ("errors""sync""github.com/toolkits/pkg/consistent""github.com/toolkits/pkg/logger"
)
//节点副本个数500
const NodeReplicas = 500
//hashring结构体,一个支持并发的map,key是int类型,value是hashring
type DatasourceHashRingType struct {sync.RWMutexRings map[int64]*consistent.Consistent
}// for alert_rule sharding
var HostDatasource int64 = 100000
//hashring对象实例
var DatasourceHashRing = DatasourceHashRingType{Rings: make(map[int64]*consistent.Consistent)}
//创建一个哈希环方法
func NewConsistentHashRing(replicas int32, nodes []string) *consistent.Consistent {ret := consistent.New()ret.NumberOfReplicas = int(replicas)for i := 0; i < len(nodes); i++ {ret.Add(nodes[i])}return ret
}
//重建key为datasourceId的hashring
func RebuildConsistentHashRing(datasourceId int64, nodes []string) {r := consistent.New()r.NumberOfReplicas = NodeReplicasfor i := 0; i < len(nodes); i++ {r.Add(nodes[i])}DatasourceHashRing.Set(datasourceId, r)logger.Infof("hash ring %d rebuild %+v", datasourceId, r.Members())
}
//根据datasourceId获取hashring,并查询hashring上pk命中的节点
func (chr *DatasourceHashRingType) GetNode(datasourceId int64, pk string) (string, error) {chr.RLock()defer chr.RUnlock()_, exists := chr.Rings[datasourceId]if !exists {chr.Rings[datasourceId] = NewConsistentHashRing(int32(NodeReplicas), []string{})}return chr.Rings[datasourceId].Get(pk) //Get returns an element close to where name hashes to in the circle.
}
//判断datasourceId获取的hashring上pk是否和currentNode相同
func (chr *DatasourceHashRingType) IsHit(datasourceId int64, pk string, currentNode string) bool {node, err := chr.GetNode(datasourceId, pk)if err != nil {if errors.Is(err, consistent.ErrEmptyCircle) {logger.Debugf("rule id:%s is not work, datasource id:%d is not assigned to active alert engine", pk, datasourceId)} else {logger.Debugf("rule id:%s is not work, datasource id:%d failed to get node from hashring:%v", pk, datasourceId, err)}return false}return node == currentNode
}
//根据datasourceId设置hashring
func (chr *DatasourceHashRingType) Set(datasourceId int64, r *consistent.Consistent) {chr.RLock()defer chr.RUnlock()chr.Rings[datasourceId] = r
}
具体用到的地方
1.heartbeat() 维护心跳(实例和集群的对应关系),当发现某台机器离线,也就hashingring节点需要摘除故障节点,调用RebuildConsistentHashRing重建离线实例对应的哈希环,新哈希环的节点摘除离线节点。
oldss, exists := localss[datasourceIds[i]]if exists && oldss == newss {continue}RebuildConsistentHashRing(datasourceIds[i], servers)
2.syncRecordRules() 同步规则,遍历所有规则,用每个规则匹配PromClientMap 根据当前有效的 datasourceId 和规则的 datasourceId 配置计算有效的cluster列表,确认在哈希环中这条规则是否命中当前节点,命中存入recordRules等待调度(这部分规则应该就是哈希环节点变更迁移的规则,应该是少数),接着在调度缓存中的s.recordRules(这部分规则是哈希环上没有变更节点的规则)
datasourceIds := s.promClients.Hit(rule.DatasourceIdsJson)for _, dsId := range datasourceIds {if !naming.DatasourceHashRing.IsHit(dsId, fmt.Sprintf("%d", rule.Id), s.aconf.Heartbeat.Endpoint) {continue}recordRule := NewRecordRuleContext(rule, dsId, s.promClients, s.writers)recordRules[recordRule.Hash()] = recordRule}
3.syncAlertRules()同步告警规则,同syncRecordRules类似最后匹配的告警规则添加alertRuleWorkers,进行告警判断调度
4.makeEvent()路由事件,转发对应事件给哈希环上命中的节点。
4.总结和思考
一致性哈希主要解决数据分布场景,它存在这样的优点:
- 1.可伸缩性
- 2.负载平衡 (将节点与Hash算法解耦,而且通过交错分配虚拟节点的方式解决了负载不均衡导致的缓存热点问题)
缺点(有个观点是用错了场景才是缺陷,用对了,那是特性):
- 1.key值通过hash算法算出,映射固定,不灵活,而且节点数量变化时虚拟节点数量也会变化,这种耦合限制哈希算法进一步优化
- 2.数据分布均匀,不代表流量和负载的均匀,热点key导致节点实际表现不均匀
5.参考资料
https://github.com/ccfos/nightingale
https://time.geekbang.org/column/article/67388
https://www.wikiwand.com/zh-cn/%E4%B8%80%E8%87%B4%E5%93%88%E5%B8%8C
https://juejin.cn/post/7134656152452726792
https://www.geeksforgeeks.org/consistent-hashing-in-distributed-systems/
https://www.zsythink.net/archives/1182
https://blog.csdn.net/randompeople/article/details/103723839