文章目录
- 1、 缘起
- 1.1 啤酒与尿布 - 发现商业价值
- 1.2 数据挖掘 - 让数据说话
- 2、数据挖掘的难点
- 3、数据挖掘的方法 Part 1 - 专业技术流
- 3.1 网络数据采集 - 代理技术
- 3.2 网络数据采集 - 爬虫浏览器
- 3.3 网络数据采集 - 网络解锁器
- 3.4 网络数据采集 - Web Scraper IDE
- 4、数据挖掘的方法 Part 2 - 偷懒伸手党
- 4.1 数据集商城介绍
- 4.2 数据集商城使用
- 4.3 按需定制数据集
- 5 数据挖掘应用
- 5.1 数据应用 - 房产数据
- 5.2 数据应用 - 金融投资
- 6、小结和期许
1、 缘起
1.1 啤酒与尿布 - 发现商业价值
相信大家都听过啤酒与尿布的故事:全球零售业巨头沃尔玛在对消费者购物行为分析时发现,男性顾客在购买婴儿尿片时,常常会顺便搭配几瓶啤酒来犒劳自己,于是尝试推出了将啤酒和尿布摆在一起的促销手段。没想到这个举措居然使尿布和啤酒的销量都大幅增加了 !!

数据挖掘的意义非常重大,它可以帮助我们从大量的数据中发现有价值的信息和知识,从而为决策提供支持。
而数据挖掘的应用,西红柿总结可以分为 3 步走:
-
获取数据:这是数据挖掘的第一步,需要从各种来源收集相关的数据。这些数据可以来自数据库、文件、网络等,并且需要进行清理和预处理,以确保数据的质量和可用性。
-
分析数据:在获取到数据后,接下来需要运用各种数据分析技术和算法,对数据进行深入的分析和挖掘。这包括数据的统计分析、模型建立、关联规则挖掘等,以发现数据中的模式、趋势和关系。
-
应用数据:最后一步是将分析得到的结果应用到实际问题中。如:炒股、开店选址选品、产品设计、药物研发等等。
1.2 数据挖掘 - 让数据说话
我们正处于数据爆炸的时代,每天都有大量的数据产生,这些数据包含着潜在的有用信息,但由于其规模庞大、复杂多样,传统的数据分析方法已经无法满足需求。数据挖掘作为一种新兴的技术,应运而生。而它的重要性也不可小觑,比如:
-
发现隐藏的模式和关系:帮助企业或组织发现数据中隐藏的模式、规律和关系,从而做出更明智的决策。
-
预测未来趋势:通过对历史数据的分析,预测未来的趋势和行为,为企业战略规划提供支持。
-
提升用户体验:挖掘用户数据,了解客户需求和行为,从而提供更个性化的服务,提升客户满意度。
-
提高效率和竞争力:帮助企业优化业务流程,发现潜在问题,提高运营效率,增强在市场中的竞争力。
2、数据挖掘的难点
数据挖掘不是挖土豆,有力气就行。数据挖掘存在一些技术难点,需要掌握一些基本的技术方法。我先讲难点,再讲方法。

随着网络技术的不断提高,要从目标网站上获取所需数据和信息变得越来越困难。即使很多网站的信息是公开的,但是要进入并抓取网站信息却并不容易。主要存在 3 个难点:
-
目标网站的不配合:目标网站可能由于各种原因不愿意与数据挖掘者合作。这可能导致无法获取所需的数据,或者只能获得有限的访问权限。
-
地理位置限制访问:地理位置的限制可能会影响数据的获取和分析。例如,某些地区可能存在网络封锁、法律限制或地理障碍,使得无法访问特定的数据来源。
-
虚假信息:数据中可能存在虚假或错误的信息,这会对数据挖掘的结果产生负面影响。虚假信息可能是由于人为错误、恶意行为或数据采集不当导致的。
3、数据挖掘的方法 Part 1 - 专业技术流
3.1 网络数据采集 - 代理技术
四大代理网络覆盖 195 个国家超 7200 万 IP 全方位满足各种代理需求
- 静态住宅代理:全球超 70 万 IP
- 动态住宅:覆盖 195 个国家超 7200 万 IP
- 机房代理:全球超 700 万 IP
- 移动代理:全球超 77 万 IP
适用人群:假如你有一定的编程基础,推荐使用。
在众多的代理类型中最独特的是:动态住宅代理。动态 IP 网络位于世界上每个国家、州和市,完全 属于真人住宅 IP。
下面,西红柿将展示一个使用代理 IP 的方法,大概分为这样几个步骤:
1. 判断执行环境
2. 导入 request 和 random 包
3. 输入代理账户信息
4. 执行代理访问
#!/usr/bin/env pythonimport sys
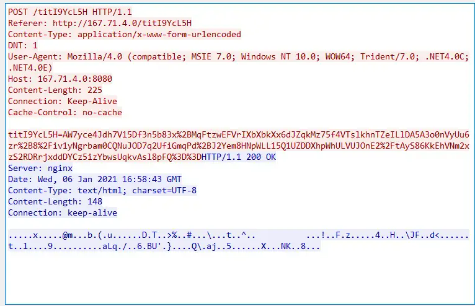
if sys.version_info[0]==3: ## 判断你的环境版本import urllib.requestimport randomusername = 'brd-customer-hl_31f1e46f-zone-residential'password = '3ztz8xik7777' ## 换成你自己的哟port = 22225session_id = random.random()super_proxy_url = ('http://%s-session-%s:%s@brd.superproxy.io:%d' %(username, session_id, password, port))proxy_handler = urllib.request.ProxyHandler({'http': super_proxy_url,'https': super_proxy_url,})opener = urllib.request.build_opener(proxy_handler)print('Performing request')print(opener.open('http://lumtest.com/myip.json').read())代理效果展示:

输入代理账户信息:实例代码是我个人的,仅供参考,可自助申请你的账号。
3.2 网络数据采集 - 爬虫浏览器
这是一个非常强大的浏览器,他利用内置解锁功能和代理一体的爬虫浏览器,大规模轻易解锁网站,抓取数据。简单来说,帮你自动实现了数据所见即所得。
同时,这也是一款非常方便的浏览器,浏览器内置的解锁功能,包括验证码解决、浏览器指纹识别和代理管理,可以节省大量时间和资源。也可以使用浏览器自动化 API,启动和操控大量爬虫浏览器会话。
亮数据为粉丝提供了10美金的抵用券,成功注册账户,并登录后在用户界面里输入折扣代码即可享受抵扣!
折扣代码:buchixihongshi
访问页面: 亮数据 - 爬虫浏览器
如有问题,可以关“Bright_Data”注亮数据官W,联系后台客服。
3.3 网络数据采集 - 网络解锁器
适用范围:完全模拟真实用户的 API,从反爬取技术最高的网页挖掘数据。

利用亮数据的强大动态住宅 IP 网络,自动解锁网站屏蔽,包括解决验证码的阻止和限制、自动 IP 轮动、识别并绕开蜜罐陷阱、自动重试和指纹管理。
最适合需要使用 API 从难以抓取的网页中提取数据的大规模 Web 数据收集。
3.4 网络数据采集 - Web Scraper IDE
Web Scraper IDE 是亮数据推出的一款专为开发者设计的数据采集 IDE。具备强大的代理基础设施和完全托管的云环境。
强大的代理基础设施:网页抓取工具集成开发环境,得益于亮数据强大的代理基础构架和专利支持的网络解锁技术,使您能够从任何地理位置采集大量数据,同时绕过复杂的机器人验证和验证码处理。
完全托管的云环境:基于顶级网站运营商的基础组建,和丰富的预封装好的 JavaScript 函数,用于产品发现和 PDP 收集。按计划或按需通过应用程序接口触发抓取,支持多种交付方式,灵活交付到您选择的存储空间和下游程序。

通过以下 4 个步骤,就能轻松完成数据采集。
-
发现所有网站页面
如果您想在某个类别或整个网站中发现完整的产品列表,则需要运行发现阶段。您将需要使用我们现成的功能来进行站点搜索并单击类别菜单。
-
PDP - 产品详细信息页面
使用固定 URL 或使用 API 动态网址或直接从发现阶段为任何页面构建抓取工具。利用以下功能更快地构建网络爬虫工具:网页格式解析、捕获浏览器网络调用、预建 GraphQL API 工具、抓取网站 JSON API。
-
数据验证
确保收到结构化和完整数据。
-
数据交付集成
通过所有流行的存储目的地传送交付数据,如:API、亚马逊 S3 等。
4、数据挖掘的方法 Part 2 - 偷懒伸手党
如果想更加简单高效的获取数据, 也可以直接使用数据集商城。亮数据为粉丝提供了10美金的抵用券,成功注册账户,并登录后在用户界面里输入折扣代码即可享受抵扣!
折扣代码:buchixihongshi
访问页面: 亮数据 - 数据集商城
如有问题,可以关“Bright_Data”注亮数据官W,联系后台客服。
4.1 数据集商城介绍
数据集商城 的最大的优势:全平台覆盖,实时更新。
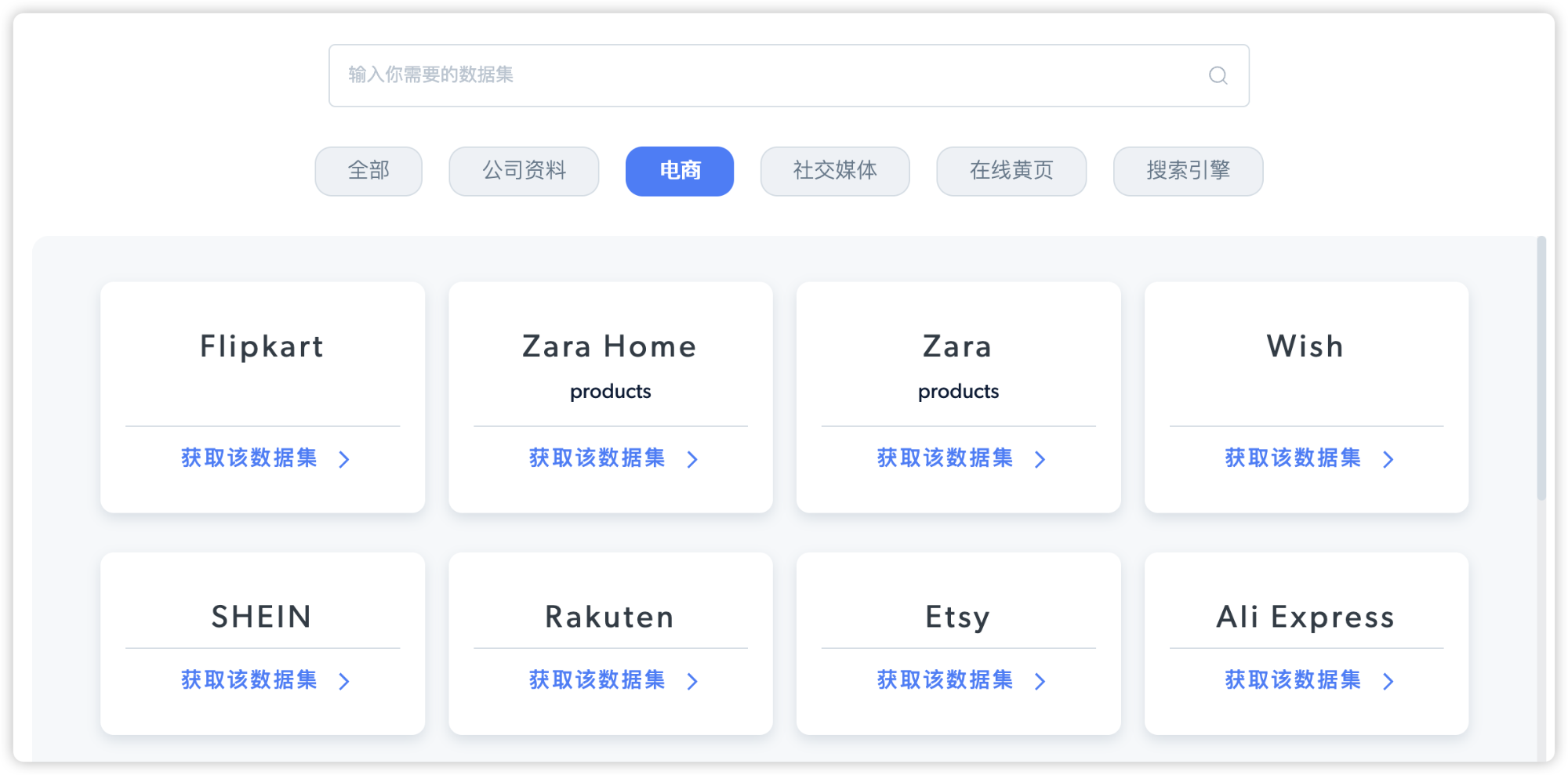
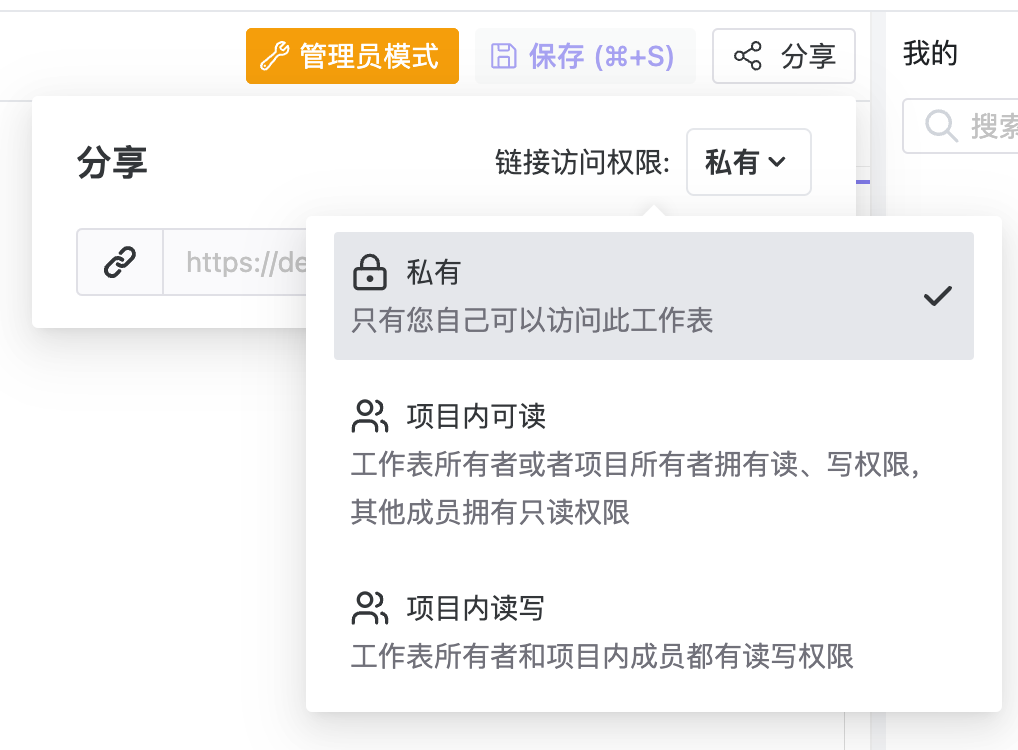
全平台覆盖是指覆盖全域使用场景的,已经采集好的,结构化的,准确的公开大数据集。比如,各个公司的基本状况信息汇总整理,对于金融股票相关需求的人来说,这可能会提供重要的帮助。
当然,最重要的是我们的操作必须安全合规,大家也可以放心。首先,亮数据全部为外网数据(如互联网公司的基本信息,类似于国内的企查查的部分功能),另外,所有数据集都是在法律允许和网站协议允许的条件下的。
4.2 数据集商城使用
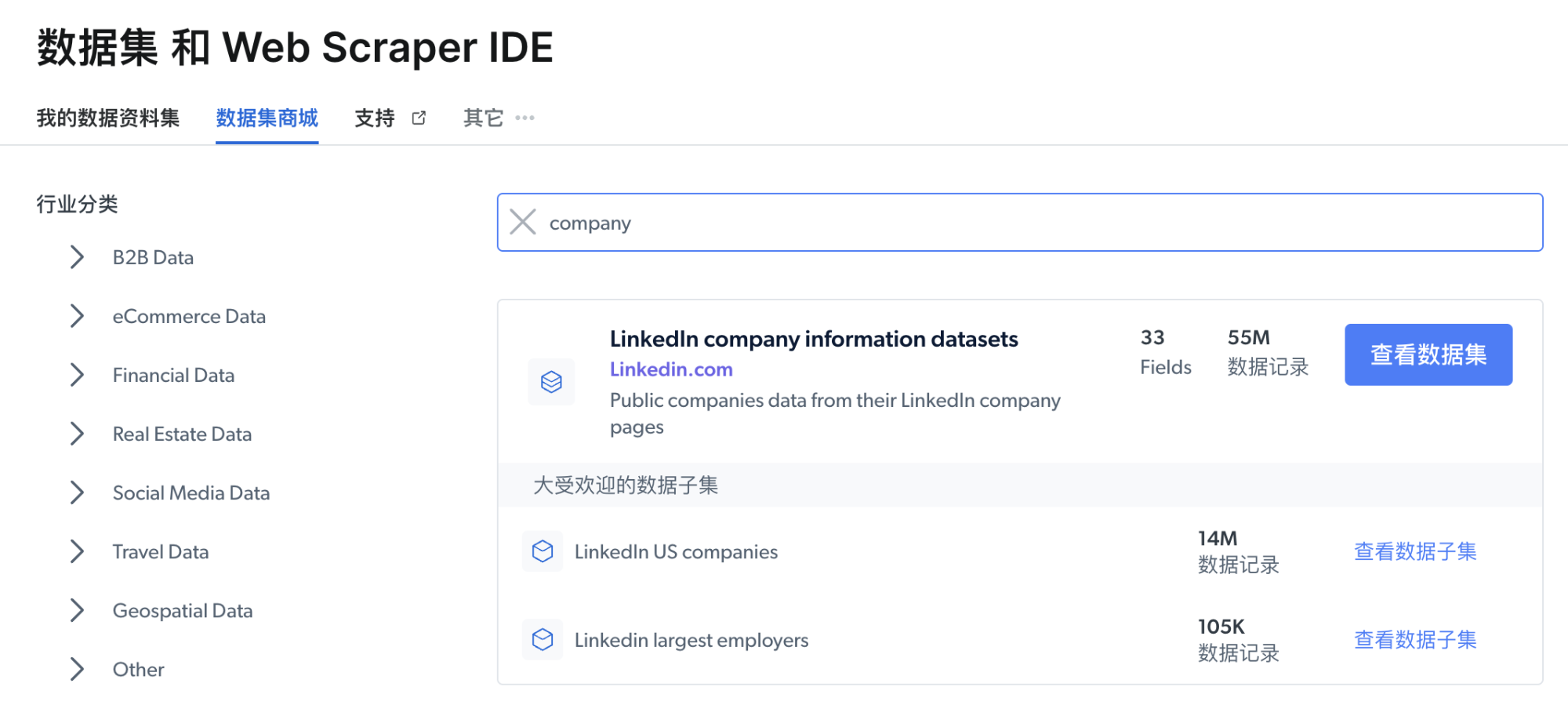
有 3 种方式帮助我们快速获取想要的数据:
- 数据按照受欢迎程度,进行了推荐;
- 数据按照行业分类进行关联;
- 支持模糊搜索,输入关键词快速查找想要的数据。

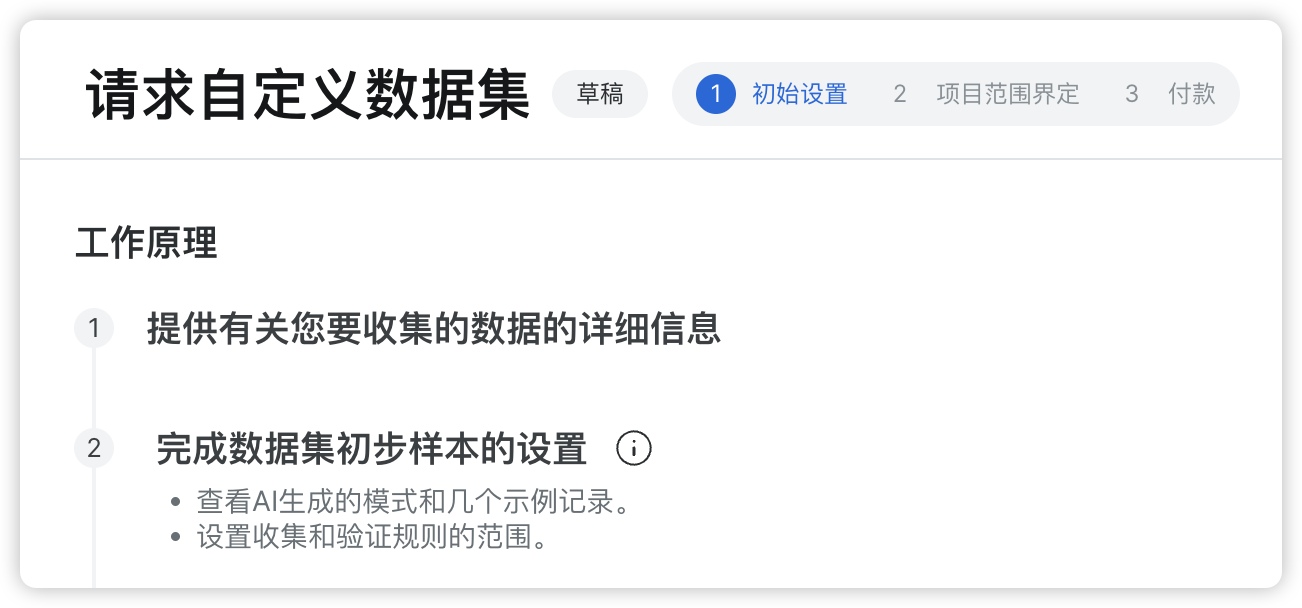
4.3 按需定制数据集
如果在现有数据集中,都没有你想要的数据,也可以为你订制采集,或者使用在线 IDE 自己创建一个数据采集器。当然,偷懒是要付费的啦~
5 数据挖掘应用
通过前面的步骤,我们拿到了想要的数据。但如何分析和使用数据,除了传统的分类、预测和聚类分析,这里我推荐 2 个亮数据在金融投资 和房产数据 方面的应用。
更多精彩案例请访问: 亮数据 - 数据挖掘应用经典案例
折扣代码:buchixihongshi
5.1 数据应用 - 房产数据
房产数据:除了价格走势和市场趋势的预测,房产数据还可以用于评估房产的投资价值。结合地理位置、周边设施、人口流动等因素,分析不同区域的房产投资潜力。同时,通过对历史数据的分析,可以了解不同类型房产的租赁收益和资本增值情况,为投资者提供更全面的投资建议。
- 从不同平台同时采集的数据对比房产价格;
- 建立你自己的综合房产清单数据库;
- 在中介和业主发布新房产时收到实时提醒;
- 通过数据深入了解房产所在社区环境,采集影响房价的核心数据:面积、楼层、停车位、是否有电梯等;
- 监控理想位置的价格趋势和便利设施,并通过本地化数据了解不同社区的购房者期望。
经过一顿操作猛如虎的分析,西红柿得出了以下结果(部分展示):
| 城市 | 二手房均价(元/㎡) | 二手房均价同比 | 二手房均价环比 | 新房均价(元/㎡) | 新房均价同比 | 新房均价环比 | 推荐购买指数 |
|---|---|---|---|---|---|---|---|
| 天津 | 28680 | 2.3% | 0.4% | 21000 | 0.8% | 0.2% | ☆☆☆ |
| 广州 | 45265 | 2.1% | 0.0% | 42570 | 1.5% | 0.0% | ☆☆☆ |
| 上海 | 71255 | 1.7% | 0.2% | 56522 | 2.3% | 0.6% | ☆☆ |
| 北京 | 65200 | 0.8% | -0.2% | 58642 | 0.7% | -0.1% | ☆ |
| 深圳 | 63236 | 0.7% | -0.3% | 63774 | 1.3% | 0.0% | ☆ |
| 厦门 | 51565 | -2.7% | -0.9% | 33302 | -0.4% | 0.0% | 不敢推荐 |
注:以上分析结果,仅代表个人观点。
环比数据可能会受到政策因素、市场波动和其他因素的影响,而且不同城市的房地产市场具有各自的特点和趋势😉 你还想了解这些城市的其他信息吗?数据挖掘起来吧~
5.2 数据应用 - 金融投资
金融投资:利用金融另类数据,分析股票市场的波动和趋势,发现潜在的投资机会。通过大数据分析和机器学习算法,可以对股票进行估值和预测,帮助投资者做出更明智的投资决策。此外,金融数据还可以用于风险管理,监测市场风险和信用风险,及时调整投资组合,降低风险敞口。
- 通过市场价格、库存数据、客户投资组合、公司新闻、产品数据和评论等数据确定投资的可行性;
- 跟踪实时消费者行为和需求变化,通过社交媒体和客户评论数据为投资决策提供信息;
- 利用公司简介数据集和初创公司名单发现市场趋势、行业利基和投资机会。
通过股票日环比分析,有多少只股票今天涨了,明天还涨? 一目了然。
6、小结和期许
本文中,西红柿简单介绍了数据挖掘的基本概念、方法和应用。希望大家能够掌握数据挖掘的技能,利用数据驱动的决策,创造更好的商业和社会效益。
让我们共同努力,推动数据挖掘技术的发展,为自己创造收益价值,为实现更加智能化的世界贡献自己的力量💪