一、前言
在前面一篇文章《Whisper与ChatGPT联手,轻松实现音频转录文本总结》给大家介绍过如何使用OpenAI的在线API接口和开源的离线Whisper模型做语音转录文本,以及对于转录后的文本内容基于GPT模型进行摘要总结。 主要应用于对音频或视频做文本转录、视频或音频摘要总结、以及视频字幕翻译等场景。 甚至对于实时视频会议转录也是支持的。
实际上当时留了个悬念,本来也有计划再写一篇后续来接着第一篇深入实践,对于长语音分割方面的问题,有位粉丝朋友当天就提出了自己的一些建议,希望对原来的案例进行优化,那今天就接着说说一些优化思路吧。

看得出来,这位朋友确实对于语音这块有过实践,认真思考过,上一篇我们采取的是根据时间间隔来对语音进行分片切割的方案,这个方案其实存在一定的缺陷。我们在将长音频分片进行转录的过程里,是完全按照精确的时间去切割音频文件的。但是实际上音频的断句其实并不在那一毫秒。所以转录的时候,效果也不一定好,特别是在录音的开头和结尾部分,很有可能不是一个完整的句子,也容易出现一些错漏的情况。
二、解决思路
针对长音频文件提供两种分片切割方案,第一种在前面一篇文章中已经介绍,今天重点来介绍第二种方案,顺便结合GPT模型对转录的文本做翻译。
-
将音频文件按固定时间间隔分割成块,并使用Whisper API进行语音识别转录
-
将音频文件根据静音部分分割成块,并使用Whisper API进行语音识别转录
除了以上两种针对开源Whisper模型自己实现的方案外,也有一些比较成熟的商用解决方案,大家可以根据自己的需求进行选择,这里介绍两款产品,可以非常方便的支持可视化流程配置的方式实现LLMs的集成应用。
- Gglot(https://app.gglot.com/register?ref=DYQjn57U)
Gglot 一款非常简单易用的音频和视频转录解决方案,只需要选择音频或视频文件然后指定要翻译的语言即可,也支持Youtube视频直接转录,不过源视频或者音频的质量太差可能效果不好太好。

- Shipyard(https://www.shipyardapp.com/)
Shipyard 设计为一流的工作流程自动化平台,提供了许多开箱即用的功能,可以帮助数据团队比以往更快地投入生产。团队可以在不到 5 分钟的时间内启动、监控、扩展和共享业务解决方案,而无需接触基础设施。用Shipyard只需要不到5分钟即可完成Youtube视频转录翻译的功能。
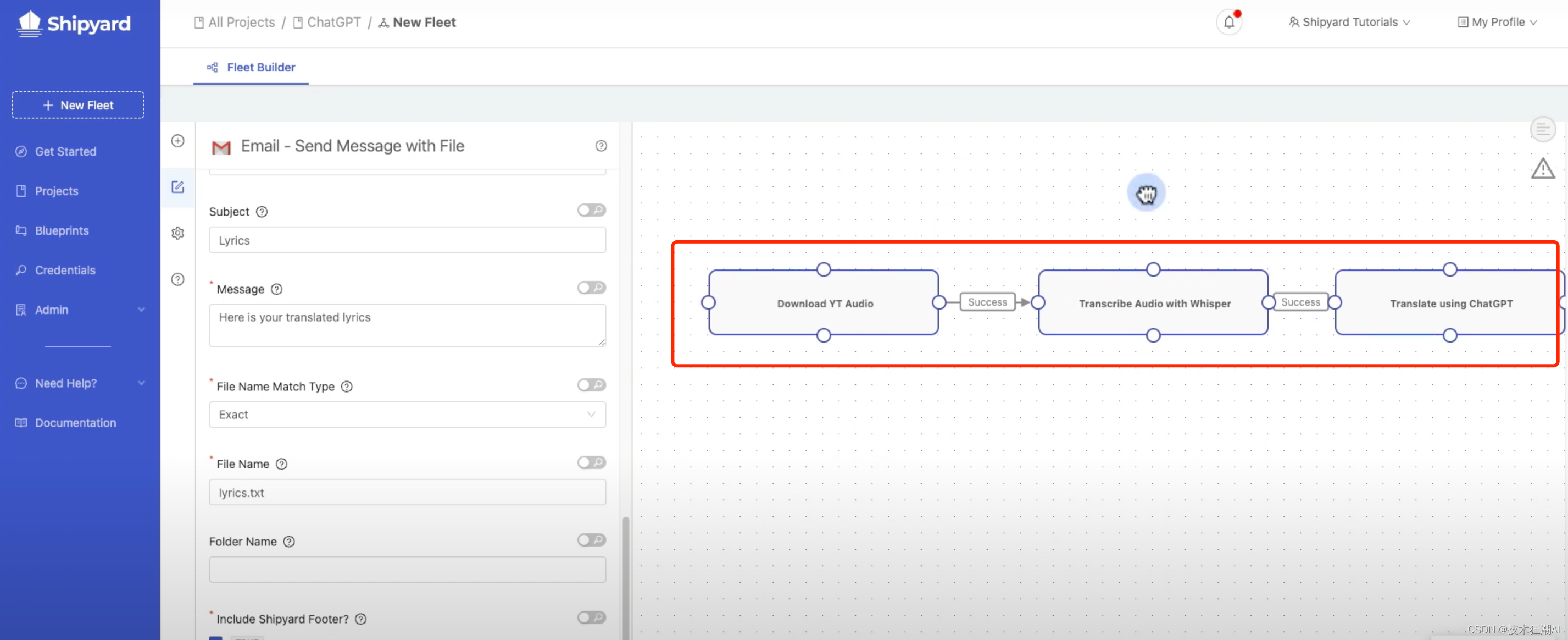
三、开发实践
接下来,开始对于第二种解决方案音频文件根据静音部分分割成块的方案进行具体的编码实践。
由于OpenAI 限制了 Whisper 一次只能转录25MB大小的文件,因此我们需要将大的播客文件分割成小的片段,转录完后再将它们拼接起来。我们可以使用OpenAI在官方文档中提供的PyDub库来分割文件。
3.1、安装依赖
- 首先确保安装了PyDub库。
%pip install pydub- 使用开源模型,需安装 openai-whisper 的相关的依赖包。
%pip install openai-whisper
%pip install setuptools-rust- 如需要翻译则需要安装 `openai` 的相关的依赖包。
!pip install openai --upgrade -q
3.2、音频切割(固定间隔)
我们先来回顾一下采用固定时间间隔进行拼音切割,然后使用Whisper进行转录的一个实际效果。
import os
import whisper
from pydub import AudioSegment
from pydub.silence import split_on_silencemodel = whisper.load_model("large")# 使用Whisper本地进行音频转录
def transcribe_audio_whisper(path):result = model.transcribe(path)text = result['text']return text# 将音频文件按固定时间间隔分割成块,并使用Whisper API进行语音识别的函数
def get_large_audio_transcription_fixed_interval_whisper(path, minutes=5):sound = AudioSegment.from_file(path)chunk_length_ms = int(1000 * 60 * minutes)chunks = [sound[i:i + chunk_length_ms] for i in range(0, len(sound), chunk_length_ms)]folder_name = "audio-fixed-chunks"if not os.path.isdir(folder_name):os.mkdir(folder_name)whole_text = ""for i, audio_chunk in enumerate(chunks, start=1):chunk_filename = os.path.join(folder_name, f"chunk{i}.mp3")audio_chunk.export(chunk_filename, format="mp3")try:text = transcribe_audio_whisper(chunk_filename)except Exception as e:print("Error:", str(e))else:text = f"{text.capitalize()}. "print(chunk_filename, ":", text)whole_text += textreturn whole_textpath="generative_ai_topics_clip.mp3"print("\nFull text:", get_large_audio_transcription_fixed_interval_whisper(path, minutes=1/6))输出结果:
audio-fixed-chunks/chunk1.mp3 : 欢迎来到onboard,真实的一线经验,走新的投资思考。我是monica。我是高宁。我们一起聊聊软件。.
audio-fixed-chunks/chunk2.mp3 : 如何改變世界.
audio-fixed-chunks/chunk3.mp3 : 在gbt掀起了席卷世界的ai热潮不到三个月就积累了超过一亿的热火用户超过1300万的热火用户真的是展现了ai让人.
audio-fixed-chunks/chunk4.mp3 : 也让很多人直呼这就是下一个互联网的未来有不少观众都说希望我们再做一期ai的讨论于是这次硬盘的讨论就开始了.
audio-fixed-chunks/chunk5.mp3 : 进行一个讨论就来了这次我们请来了google brain的研究员雪芝她是google大语言模型pompathway language model的作者之一要请雪芝介绍一下她的研究雪芝雪芝雪芝雪芝雪芝雪芝雪芝雪芝雪芝.
audio-fixed-chunks/chunk6.mp3 : 这个模型的参数量是gpt-3的三倍还多另外还有两位ai产品大牛一位来自著名的stable diffusion背后的商业公司.
audio-fixed-chunks/chunk7.mp3 : Solidity ai 另一位来自某硅谷科技大厂也曾在吴恩达教授的landing ai中担任产品负责人此外,莫妮凯还.
audio-fixed-chunks/chunk8.mp3 : 我還邀請到一位一直關注ai的投資人朋友 bill當作我的特邀共同主持嘉賓我們主要討論幾個話題一方面從研究的視角.
audio-fixed-chunks/chunk9.mp3 : 最前沿的研究者在关注什么?现在的技术的天花板和未来大的变量可能会在哪里?从产品和商业的角度,什么是一个好的ai产品?.
audio-fixed-chunks/chunk10.mp3 : 整个生态可能随着技术有怎样的演变更重要的,我们又能从上一波ai的创业热潮中学到什么最后,摩登的技术是如何发展的?.
audio-fixed-chunks/chunk11.mp3 : 在本集发布的时候,google也对爆发式增长的一些新的技术提供了一些新的提示。这些提示包括了,在新的版本上,我们可以看到,在新版本上,我们可以看到,在新版本上,我们可以看到,在新版本上,我们可以看到,在新版本上,我们可以看到,在新版本上,我们可以看到,.
audio-fixed-chunks/chunk12.mp3 : 我们在这次的测试中,我们与一位非常有名的chatgbt作出了回应。正在测试一个基于lambda模型的聊天机器人apprenticebot。证实发布后会有怎样的惊喜,我们就要来看看了。.
audio-fixed-chunks/chunk13.mp3 : 都拭目以待ai无敌是未来几年最令人兴奋的变量之一monica也希望未来能邀请到更多一线从业者从不同角度来进行.
audio-fixed-chunks/chunk14.mp3 : 讨论这个话题。不论是想要做创业、研究、产品还是投资的同学,希望这些对话对于大家了解这些技术演进。.
audio-fixed-chunks/chunk15.mp3 : 商业的可能 甚至未来对于我们每个人 每个社会意味着什么 都能引发一些思考 提供一些启发这次的讨论有些技术硬核.
audio-fixed-chunks/chunk16.mp3 : 需要各位对生成式ai大模型都有一些基础了解讨论中涉及到的论文和重要概念也会总结在本集的简介中.
audio-fixed-chunks/chunk17.mp3 : 供大家複習參考幾位嘉賓在北美工作生活多年夾雜英文在所難免也請大家體諒了歡迎來到未來.
audio-fixed-chunks/chunk18.mp3 : 大家enjoy. 我这里用的是一个中文的mp3音频文件,从输出结果可以看到对于中文略微有一点瑕疵,穿插着简体和繁体的内容。
3.3、音频提取
如果你需要对视频文件进行转录,PyDub也支持从视频文件中提取音频,然后交给Whisper做音频识别转录。下面的代码简单介绍了如何使用PyDub从视频文件中提取音频。也可以用前面介绍的PyTube库(主要是基于Youtube视频)
# 从MP4文件中提取音频
video_path = "01-beginner_python_developer.mp4"
audio_path = "01-beginner_python_developer.mp3"video = AudioSegment.from_file(video_path, format="mp4")
audio = video.set_channels(1) # 转为单声道
audio.export(audio_path, format="mp3")3.4、音频切割(静音切割)
除了使用固定间隔的方式外,还可以使用PyDub库提供的函数,将音频文件根据静音部分来分割成块,并使用Whisper进行语音识别。按静音来分割可能会产生很多小的静音文件,为了降低过多的碎片文件,下面的代码对分割的文件进行了优化,可以设置每个segment的固定大小,小于segment的碎片都合并为一个segment。
其中对于静音分割主要是使用PyDub库中的split_on_silence()函数将音频文件分割成多个部分,其中参数的设置会影响到分割的效果。
-
min_silence_len(最小静音长度):这个参数表示静音的最小持续时间(以毫秒为单位)。如果静音的持续时间小于这个值,则不会被认为是分割点。较小的值会导致更多的分割点,而较大的值则会导致更少的分割点。 -
silence_thresh(静音阈值):这个参数表示音频的静音阈值。PyDub使用dBFS(分贝全幅值)来表示音频的音量。sound.dBFS-14表示将音频的音量降低14dBFS作为静音的阈值。较低的值会使更多的部分被认为是静音,从而导致更多的分割点,而较高的值则会使更少的部分被认为是静音,导致更少的分割点。 -
keep_silence(保留静音):这个参数表示在分割音频时,每个分割部分之间保留的静音时间(以毫秒为单位)。如果设置为0,则不会保留任何静音。较大的值会在分割部分之间添加更多的静音,而较小的值则会减少静音时间。
要根据具体的音频文件和需求来确定这些参数的最佳设置。你可以尝试不同的值并观察分割结果,根据需要进行调整。
sound.dBFS表示音频文件的分贝全幅值。在这里,sound.dBFS-14表示将音频的音量降低14dBFS,作为静音的阈值。这是一种常见的做法,因为静音通常比正常音频的音量低很多。
import whisper
from pydub import AudioSegment
from pydub.silence import split_on_silencemodel = whisper.load_model("large")# 使用Whisper本地进行音频转录
def transcribe_audio_whisper(path):result = model.transcribe(path)text = result['text']return textdef translate_text_to_chinese(text):translation = openai.Completion.create(engine="text-davinci-003",prompt=f"将以下英文文本翻译成中文: '{text}'",max_tokens=1000,)translated_text = translation.choices[0].text.strip()return translated_text# 将音频文件根据静音部分分割成块,并使用Whisper API进行语音识别的函数
def get_large_audio_transcription_on_silence_whisper(path, export_chunk_len):sound = AudioSegment.from_file(path)chunks = split_on_silence(sound, min_silence_len=500, silence_thresh=sound.dBFS-14, keep_silence=500)folder_name = "audio-chunks"if not os.path.isdir(folder_name):os.mkdir(folder_name)# 现在重新组合这些块,使得每个部分至少有export_chunk_len长。output_chunks = [chunks[0]]for chunk in chunks[1:]:if len(output_chunks[-1]) < export_chunk_len:output_chunks[-1] += chunkelse:# 如果最后一个输出块的长度超过目标长度, 我们可以开始一个新的块output_chunks.append(chunk)whole_text = ""for i, audio_chunk in enumerate(output_chunks, start=1):chunk_filename = os.path.join(folder_name, f"chunk{i}.mp3")audio_chunk.export(chunk_filename, format="mp3")try:text = transcribe_audio_whisper(chunk_filename)except Exception as e:print("Error:", str(e))else:text = f"{text.capitalize()}. "print(chunk_filename, ":", text)whole_text += textreturn whole_textpath="01-beginner_python_developer.mp3"
export_chunk_len = 90 * 1000audio_text = get_large_audio_transcription_on_silence_whisper(path, export_chunk_len)
print("\nAudio Full text:", audio_text)chinese_audio_translation = translate_text_to_chinese(audio_text)
print("\nAudio Translate text:", chinese_audio_translation)输出结果:
100%|█████████████████████████████████████| 2.87G/2.87G [00:59<00:00, 52.2MiB/s]
audio-chunks/chunk1.mp3 : hello, and welcome to the world's best python bootcamp. my name is angela, i'm a senior developer and the lead instructor at the appbury, london's highest rated programming bootcamp. to date, i've taught over half a million students in person and online, and i'm so excited to be your instructor on this course. as a student on this course, you're going to get access to over 56 hours of hd video content which contains step-by-step tutorials, interactive coding exercises, quizzes, and more. the course is structured around the 100 days of code challenge, so you can look forward to 100 days of lovingly crafted content that is going to cover every aspect of python programming, from web development to data science. it's the only course you need to become a professional python developer. every day on the course, you're going to use what you've learnt to build a new project. you'll build a bot that texts you in the morning if it will rain that day, so you never forget your umbrella again. you'll build classic arcade games like snake and pong to impress your friends by challenging them to a game that you built. you'll learn to make sense of complex data and create beautiful visualizations to impress your colleagues at work. you'll create a program that automatically sends happy birthday emails to your friends and family..
audio-chunks/chunk2.mp3 : never forget mom's birthday again. you'll work on projects that clone real-world startups. cheap flight club? check. build your own blog? check. twitter bot? check. and there are so many more projects waiting to be discovered by you. 100 projects in total. so if you're somebody who wants to get a job as a python developer, then this is perfect for building up your portfolio to show off at your next interview. now this course assumes absolutely no prior programming experience. so if you're somebody who's never coded before, i'll be with you every step of the way as i take you from programming fundamentals through to more intermediate and advanced programming concepts. you're going to learn python from scratch. now if you're an advanced developer on the other hand, then take a look at the curriculum and start at the level that suits you best. from beginner to professional, every level is covered in the course. got school? working a full-time job? have to look after kids? i know you're busy. i've timed each day of the course to take less than two hours to complete so you can fit the course around your life. this course has exactly the same curriculum as our in-person programming bootcamp. so instead of spending thousands of dollars and taking time off work, you'll get access to exactly the same curriculum with years of design and testing behind it to ensure that you don't just know what to do, but know how to use it..
audio-chunks/chunk3.mp3 : but also why you're doing it. now don't just take my word for it. check out what my past students had to say about my courses. so what are you still waiting for? find out why over half a million students have rated my course five stars and see what you can do by mastering python.. Audio Full text: hello, and welcome to the world's best python bootcamp. my name is angela, i'm a senior developer and the lead instructor at the appbury, london's highest rated programming bootcamp. to date, i've taught over half a million students in person and online, and i'm so excited to be your instructor on this course. as a student on this course, you're going to get access to over 56 hours of hd video content which contains step-by-step tutorials, interactive coding exercises, quizzes, and more. the course is structured around the 100 days of code challenge, so you can look forward to 100 days of lovingly crafted content that is going to cover every aspect of python programming, from web development to data science. it's the only course you need to become a professional python developer. every day on the course, you're going to use what you've learnt to build a new project. you'll build a bot that texts you in the morning if it will rain that day, so you never forget your umbrella again. you'll build classic arcade games like snake and pong to impress your friends by challenging them to a game that you built. you'll learn to make sense of complex data and create beautiful visualizations to impress your colleagues at work. you'll create a program that automatically sends happy birthday emails to your friends and family.. never forget mom's birthday again. you'll work on projects that clone real-world startups. cheap flight club? check. build your own blog? check. twitter bot? check. and there are so many more projects waiting to be discovered by you. 100 projects in total. so if you're somebody who wants to get a job as a python developer, then this is perfect for building up your portfolio to show off at your next interview. now this course assumes absolutely no prior programming experience. so if you're somebody who's never coded before, i'll be with you every step of the way as i take you from programming fundamentals through to more intermediate and advanced programming concepts. you're going to learn python from scratch. now if you're an advanced developer on the other hand, then take a look at the curriculum and start at the level that suits you best. from beginner to professional, every level is covered in the course. got school? working a full-time job? have to look after kids? i know you're busy. i've timed each day of the course to take less than two hours to complete so you can fit the course around your life. this course has exactly the same curriculum as our in-person programming bootcamp. so instead of spending thousands of dollars and taking time off work, you'll get access to exactly the same curriculum with years of design and testing behind it to ensure that you don't just know what to do, but know how to use it.. but also why you're doing it. now don't just take my word for it. check out what my past students had to say about my courses. so what are you still waiting for? find out why over half a million students have rated my course five stars and see what you can do by mastering python.. Audio Translate text: 您好,欢迎来到世界上最好的Python引导班。我叫安吉拉,我是一位资深开发人员,也是伦敦最受欢迎的编程引导班——Appbury的首席讲师。到目前为止,我已在线上和线下教授了50多万的学生,我非常激动能成为您在本课程中的讲师。作为本课程的学生,您将获得超过56小时的HD视频内容,包含逐步教程、交互式编码练习、小测验等等。该课程围绕“100天代码挑战”而结构,因此您可以期待精心精心构思出的100天内容,涵盖Python编程的各个方面,从Web开发到数据科学。这是您成为专业Python开发者所需的唯一课程。在本课程中,每天您都将使用所学知识来构建新项目。您将构建一个如果隔天要下雨就发送短信的机器人,这样您就不会忘记带伞了。您将构建经典街机游戏,如Snake和Pong,让朋友为您自己构建的游戏而感到惊讶。您将学习如何解释复杂数据,并创建漂亮的可视化以给工作中的同事留下深刻的印象。您将创建一个自动给朋友和家人发送生日祝福的程序,再也不用担心把妈妈的生日忘记了。您还将开发类似于真实世界中的创业公司的项目,如廉价航班俱乐部? 建立自己的博客? Twitter机器人?总共有100个项目等着您去发现。因此,如果您想要成为一名Python开发者,那么这正是构建这里演示了一个视频文件,按每90秒一个segment进行分割,最后调用OpenAI的接口进行翻译,因为设置了max_token限制,加上OpenAI本身的token有限制,所以你可以选择按segment进行翻译后合并,也可以最后统一来进行翻译。这里为了隔离,我暂时选择的是独立处理文本翻译。
3.5、转录翻译
-
首选设置你的 OPENAI_API_KEY 来设置你的KEY
import os
os.environ['OPENAI_API_KEY'] = "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"-
下面演示了对于大文本翻译,采取了文本切片的方案,同时基于Python的多线程并发解决翻译效率问题。
import openai
from concurrent.futures import ThreadPoolExecutoropenai.api_key = os.getenv("OPENAI_API_KEY")
# 定义要翻译的大文本
text = audio_text# 将文本分割成较小的段落或句子
segments = []
segment_size = 800 # 每个段落的最大长度(以token为单位)for i in range(0, len(text), segment_size):segment = text[i:i+segment_size]segments.append(segment)# 使用线程池进行并发请求
executor = ThreadPoolExecutor(max_workers=5) # 根据需要调整并发请求数量def translate_text_to_chinese(text):translation = openai.Completion.create(engine="text-davinci-003",prompt=f"将以下英文文本翻译成中文: '{text}'",max_tokens=1000,)translated_text = translation.choices[0].text.strip()return translated_text# 提交并发请求
translated_segments = list(executor.map(translate_text_to_chinese, segments))# 合并翻译结果
translated_text = ' '.join(translated_segments)print(translated_text)在这个例子中,我们使用了concurrent.futures.ThreadPoolExecutor来实现并发请求。我们将每个段落的翻译任务作为一个函数translate_segment提交给线程池进行并发执行。通过调整max_workers参数,可以控制并发请求数量。这样可以并行处理多个请求,提高效率。
注意:在使用并发请求时,请确保你的OpenAI API帐户具有足够的配额以支持并发请求。请参考OpenAI API文档了解有关配额和限制的详细信息。
通过批量翻译和并发请求这两种优化方法,可以加快处理大文本的速度,并提高代码的效率和性能。根据具体需求和环境,可以选择适合的优化策略。
输出结果:
你好,欢迎来到世界上最好的Python强化培训班。我是安吉拉,一位资深开发人员,也是位于伦敦最受欢迎的编程强化培训班Appbury的主讲教师。到目前为止,我曾在线上和线下教学超过50万学生,我非常高兴成为你们这次课程的主讲教师。 作为本门课程的学生,你将获得超过56小时的HD视频内容,其中包含逐步教程,交互式编码练习,测验等等。 本课程围绕100天代码挑战展开,因此你可以期待100天体贴入微的内容,涵盖Python编程的方方面面,从网页开发到数据科学等。 这是唯一一门帮助你成为专业Python开发人员所需要的课程。每天,你都会受益匪浅。 在这门课程上,你将用已学到的知识来构建一个新项目,你将建造一个智能机器人,如果那天将要下雨,它将在早上给你发短信提醒你,这样你永远不会忘记带伞了。你还将建造经典的街机游戏,比如贪吃蛇和乒乓球等,让你的朋友受到你的邀请一起玩你自己建造的游戏去挑战他们。你将学习如何处理复杂的数据,创建漂亮的可视化界面以给你的同事们留下深刻的印象。你将建造一个程序,自动给你的朋友和家人发送生日祝贺邮件--再也不用担心忘记妈妈的生日。你会参与一些项目来克隆现实世界中的创业公司,例如廉价航空俱乐部,撰写自己的博客,搭建Twitter机器人等等,还有许多有待发现的项目,一共有100个项目。所以,如果你想要掌握全新技能,让你的知识革新,那么就加入我们吧! 如果你是想成为一名Python开发者的人,那么这课程非常适合用来建设你的作品集,展示在下次面试中。这门课程完全不需要预先的编程经验,所以如果你是从未编码过的人,我会指导你掌握从基础编程到中级和高级编程概念的每一步。你将从零学习Python。如果你已经是一名高级开发者,那么可以查看课程大纲,找到最适合你的水平开始学习。从初学者到专业人士,每个水平都在这个课程中都有涵盖。还要上学?还要全职工作?还要照顾小孩?我知道你是很忙的,我为每一天的课程安排了不超过2小时的时间。 这门课程可以让你围绕自己的生活安排完成,它的课程跟我们现场编程军训营的一样,所以你既省去了上千美元的花费,也不需要请假上课,你可以获得完全相同的课程,这门课程经过多年的设计和测试,保证你不仅知道该做什么,更知道如何去使用,而且还知道为什么要做这项任务。现在不要只相信我的话,看看我过去的学生如何评价我的课程。所以你还在等什么?为什么超过50万学生评价我的课程5星级,让你通过掌握Python来实现自己的收获吧。四、总结
今天我们主要是基于前面我们介绍的Whipser语音转录中对于长语音的分割方案进行优化。我们在将长音频分片进行转录时,我们完全按照精确时间进行切割,但实际上断句并不是发生在每个毫秒上。因此,在转录过程中可能会出现效果不理想的情况,尤其是在录音开头和结尾部分可能出现不完整句子或错误遗漏。
今天主要针对长音频文件,我们提供了两种分片切割方案。第一种方案已经在之前的文章中介绍过,今天我们重点介绍第二种方案,并结合GPT模型对转录文本进行翻译。
除了以上两种自行实现的针对开源Whisper模型的方案,还有一些成熟的商用解决方案可供选择。以下是两款产品推荐,它们提供了可视化流程配置的方式来集成LLMs应用。
通过这些优化思路和商业产品推荐,我们可以更好地实现长语音分割和转录翻译的需求。无论是选择自己实现还是使用商业解决方案,都能提升我们在语音转录和处理领域的效率和质量。