爬虫爬取图片的简单实例
这里以图片之家为例
首先分析网页
每一页与每一页之间只是list_176_后面的数字不同,所以我们可以根据不同的需求来进行翻页

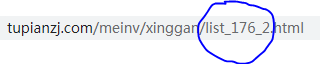
图片的定位:
小编这里使用的是xpath来进行的定位,比较简单,适合新手
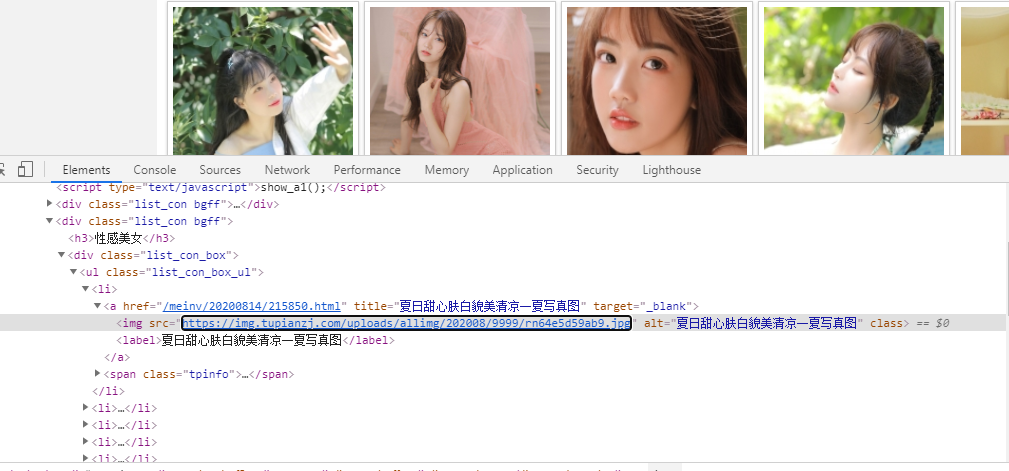
在谷歌浏览器中选中其src中的地址右键copy其xpath直接定位到该图片的定位
分析完后就可以写python代码了
import requests
from lxml import etreep = 1
print("请输入爬取的页数:")
num = int(input())
for i in range(num+1):if i != 0:url = f'https://www.tupianzj.com/meinv/xinggan/list_176_{i}.html'# 伪装请求头header = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36"}# 发送请求respons = requests.get(url, headers=header)# 查看返回结果 content返回时时byte 需要手动转码html = respons.contenthtml = html.decode("gb2312")# print(html)# 调用lxml中的etree方法txt = etree.HTML(html)src = txt.xpath('//*[@id="container"]/div/div/div[3]/div/ul/li/a/@href')# print(src)for k in src:# print(k[:-5])p2 = 1for j in range(1,11):# 拼接新的网址page = 'https://www.tupianzj.com' + k[:-5] + f"_{j}.html"# print(page)# 重新发送请求imgdata = requests.get(page,headers=header)# 查看返回结果 并解码html1 = imgdata.contenttry:html1 = html1.decode('gb2312')txt1 = etree.HTML(html1)xsrc = txt1.xpath('//*[@id="bigpicimg"]/@src')except:passif len(xsrc) == 0:continueprint(xsrc[0])imgdata2 = requests.get(xsrc[0],headers=header)# 图片另存为f = open('./img/'+str(p)+'.'+str(p2)+xsrc[0][-4:], 'wb')# 写入f.write(imgdata2.content)f.close()p2 += 1p += 1
运行时需要在当前文件夹下创建一个img文件夹
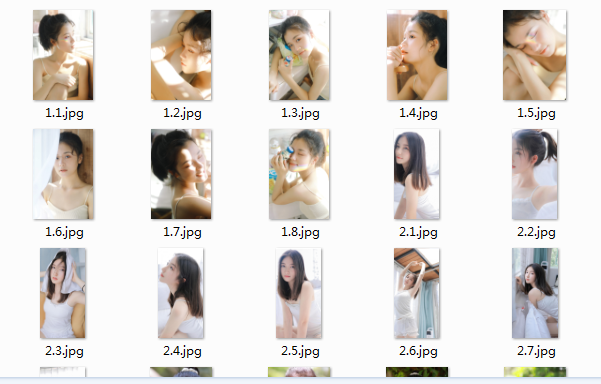
这是运行结果: