文章目录
- 核酸数据库
- 1 一级核酸数据库:GenBank
- 1.1 原核生物核酸序列
- 1.2 真核生物成熟mRNA
- 1.3 真核生物DNA序列
- 2 一级核酸数据库:基因组数据库:Ensemble
- 3 一级核酸数据库:微生物宏基因组数据库:JCVI
- 4 二级核酸数据库
- 蛋白质数据库
- 1 一级蛋白质序列数据库 UniProtKB
- 2 一级蛋白质结构数据库 PDB
- 3 二级蛋白质数据库
- 3.1 Pfam
- 3.2 Cath
- 3.3 SCOP2
- 专用数据库
- 1 KEGG
- 1.1 三羧酸循环
- 1.2 Toll样受体(Toll-like receptors, TLR)
- 2 OMIM
b站:山东大学生物信息学课程
概述了几种主要的生物信息学数据库,包括核酸序列、蛋白质序列及其结构和专用生物路径数据库。文章从一级核酸数据库开始,详细介绍了GenBank、Ensemble和JCVI等数据库,这些数据库提供了广泛的原核和真核生物的遗传信息。然后是蛋白质数据库,从UniProtKB的基本序列信息到PDB的三维结构信息,以及如Pfam、Cath和SCOP2等二级蛋白质数据库的深入分析。最后,探讨了KEGG和OMIM等专用数据库,提供了详细的生物化学路径和遗传疾病信息。
- 数据库
- 核酸数据库
- 一级核酸数据库
- 二级核酸数据库
- 蛋白质数据库
- 一级蛋白质数据库
- 一级蛋白质序列数据库
- 一级蛋白质结构数据库
- 二级蛋白质数据库
- 一级蛋白质数据库
- 专用数据库
- 文献数据库PubMed
- 核酸数据库
核酸数据库
-
一级核酸数据库
- NCBI GenBank:美国国家生物技术信息中心
- ENA
- DDBJ
- 这三合并为INSDC:国级核酸序列数据库合作联盟
1 一级核酸数据库:GenBank
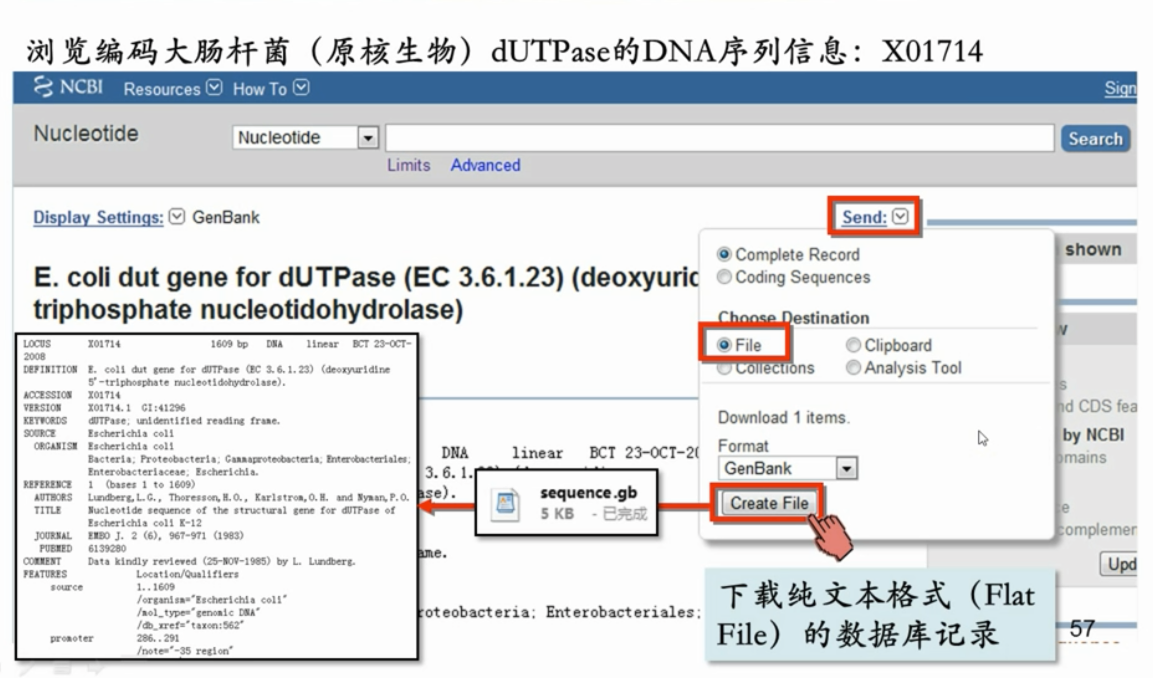
1.1 原核生物核酸序列
-
原核生物没有内含子

-
原核生物序列的一个基因序列,举例,同一个基因的名字是一样的,但是在不同数据库的检索号不同

-
LOCUS ACCESSION VERSION GI
- LOCUS 是姓名 ACCESSION是学号
- 同一个基因在不同的数据库中LOCUS是一样的,ACCESSION不同
-

-
Features
-

-

-
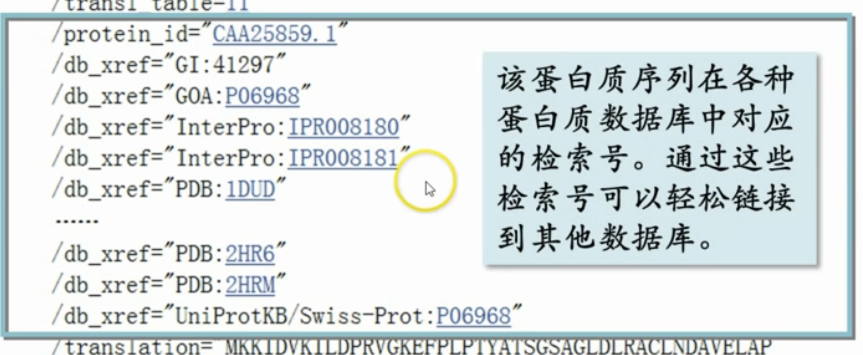
蛋白质数据库中的大部分蛋白质序列,都是核酸序列,根据翻译密码本,翻译过来的
-
计算机预测出来的该序列上的其他基因,还没有实验验证,这种情况很常见
-
完整序列
-
下载序列
-
下载纯文本格式
-




1.2 真核生物成熟mRNA
因为真核生物有内含子,所以真核生物的核酸序列信息比原核生物要复杂得多
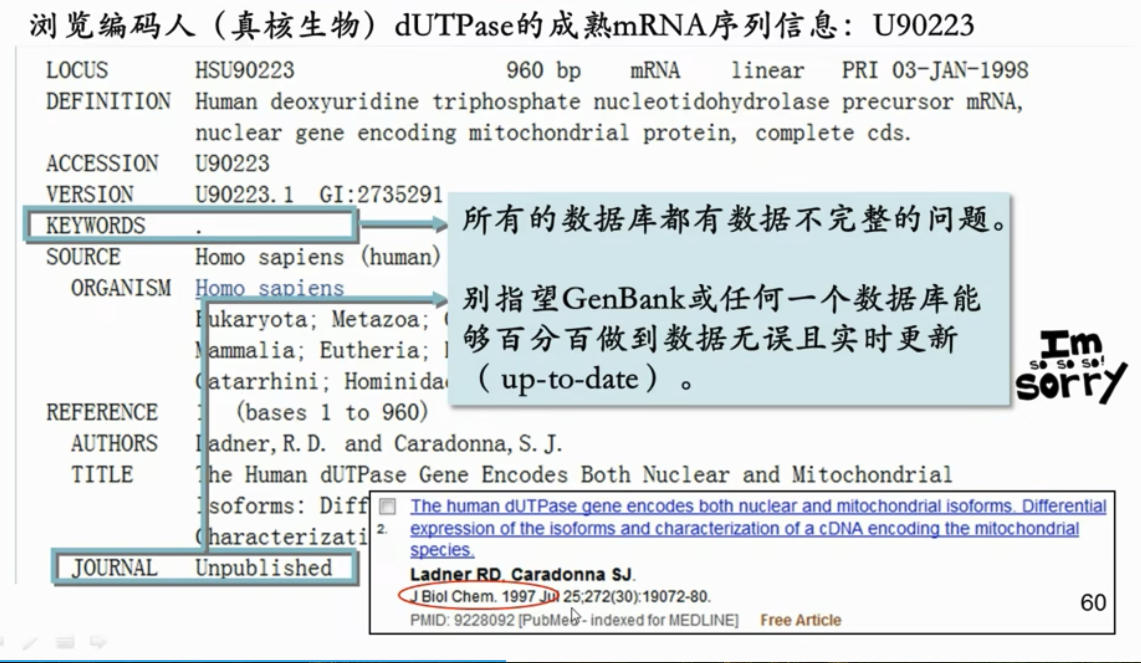
浏览编码人(真核生物)dUTPase的成熟mRNA(加工过之后的)序列信息:U90223
重点讲一下不同点
- 数据库经常出现数据不完整、更新不及时的问题,当然现在已经更新了
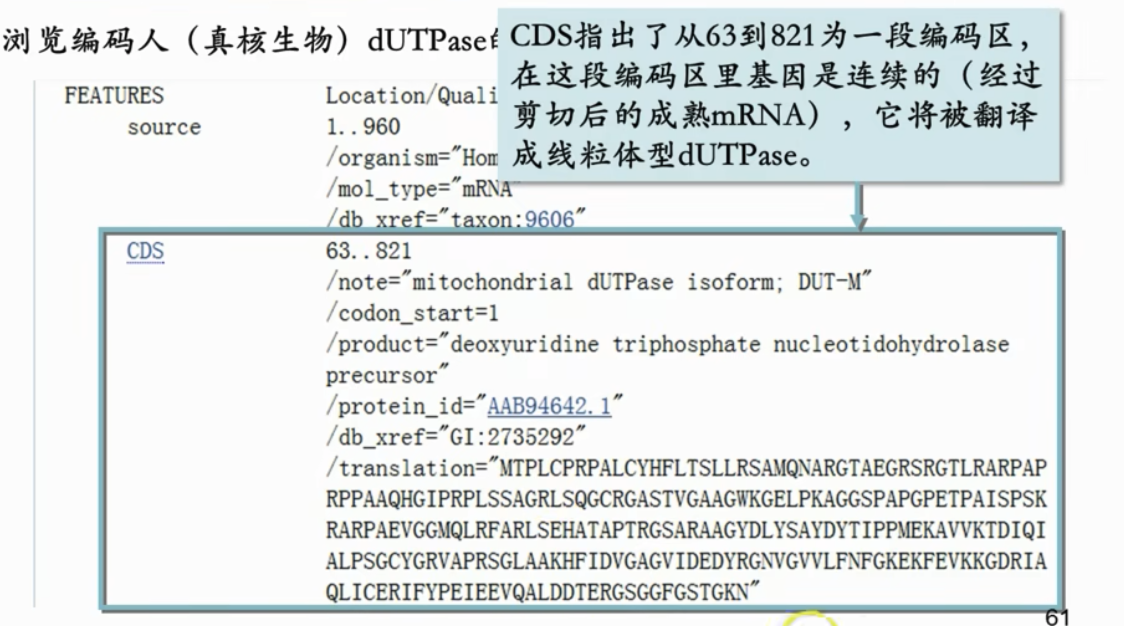
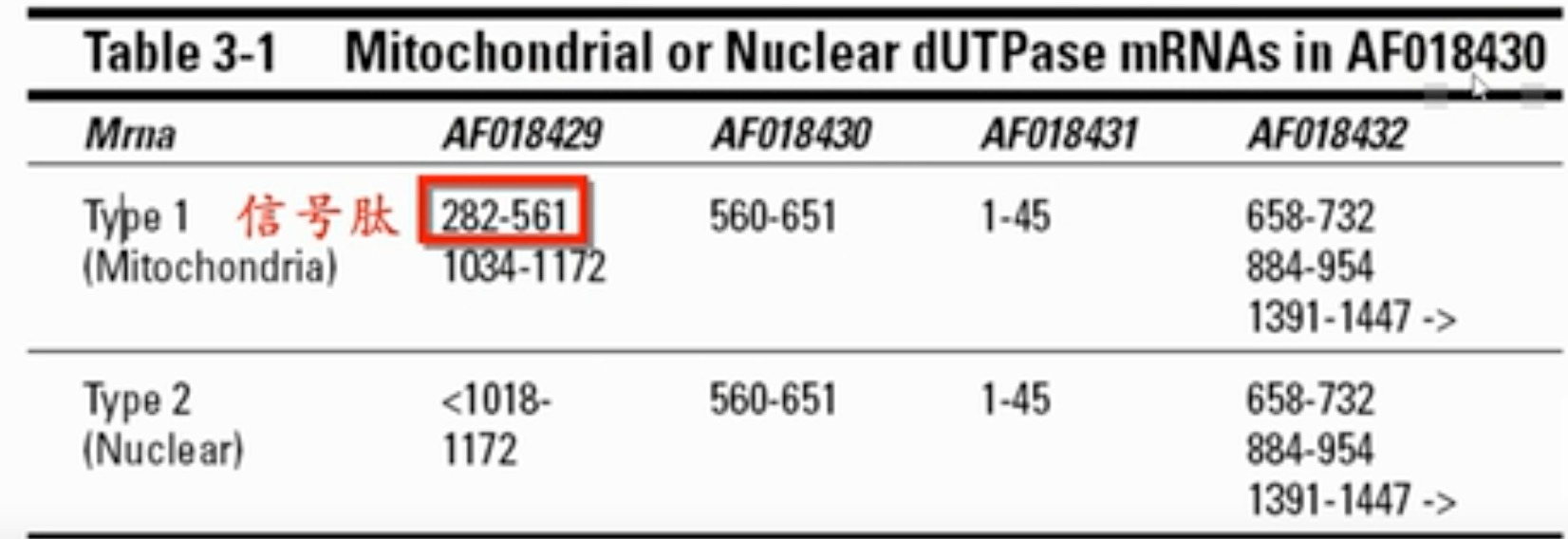
- 信号肽就是用于决定蛋白质工作的地方,后面matpeptide就是编码成熟蛋白的序列

- 编码区差三位,是因为最后三位是终止密码子

1.3 真核生物DNA序列
前面的都是线性的,这里是非线性的
浏览编码人(真核生物)dUTPase的基因组DNA序列信息:AF018430
当时还是第三个外显子,现在已经几个外显子被整合拼成完整基因了 AH005568

- 完整的gene 和 成熟的mrna(经过剪接)

- 对应多种mRNA 分别对应在线粒体中的蛋白质和细胞核中的蛋白质
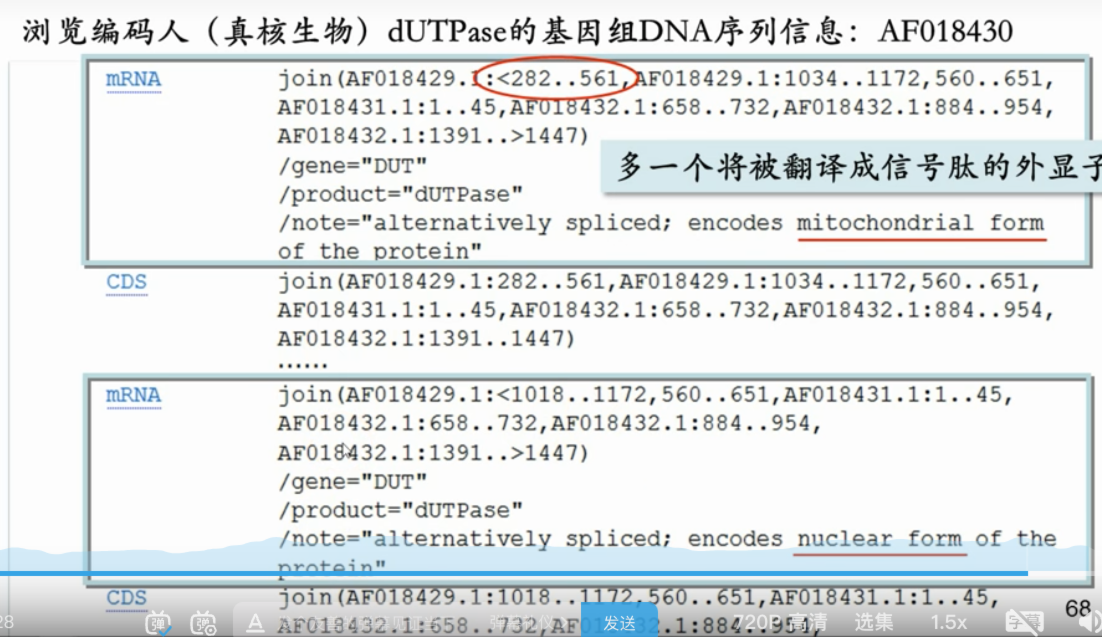
- 以下为四个外显子片段(四条序列上的该基因外显子部分)
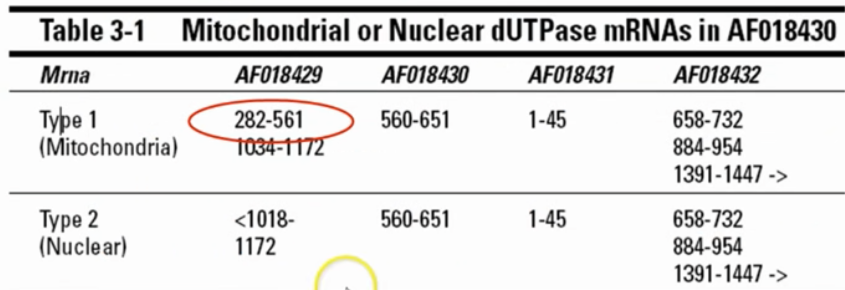
不同的剪接方式会有不同的外显子形成不同的氨基酸序列。这可能涉及基因的表达调控,不是简单分类。
选择性剪接:许多基因通过选择性剪接可以产生多个mRNA变体。这意味着从同一个基因序列中,通过在成熟的mRNA中包含或排除不同的外显子,可以制造出多种不同的蛋白质。这是蛋白质多样性的重要来源。
真核生物比原核生物复杂得多
2 一级核酸数据库:基因组数据库:Ensemble
这才是真正的天书!

- 显示演示了如何从染色体入手找到一个具体的基因
- 更多的方法需要大家去实践熟悉
3 一级核酸数据库:微生物宏基因组数据库:JCVI
-
微生物研究计划之一HMP
-
人们不知道微生物跟人的具体关系是什么,相互之间如何影响。
-
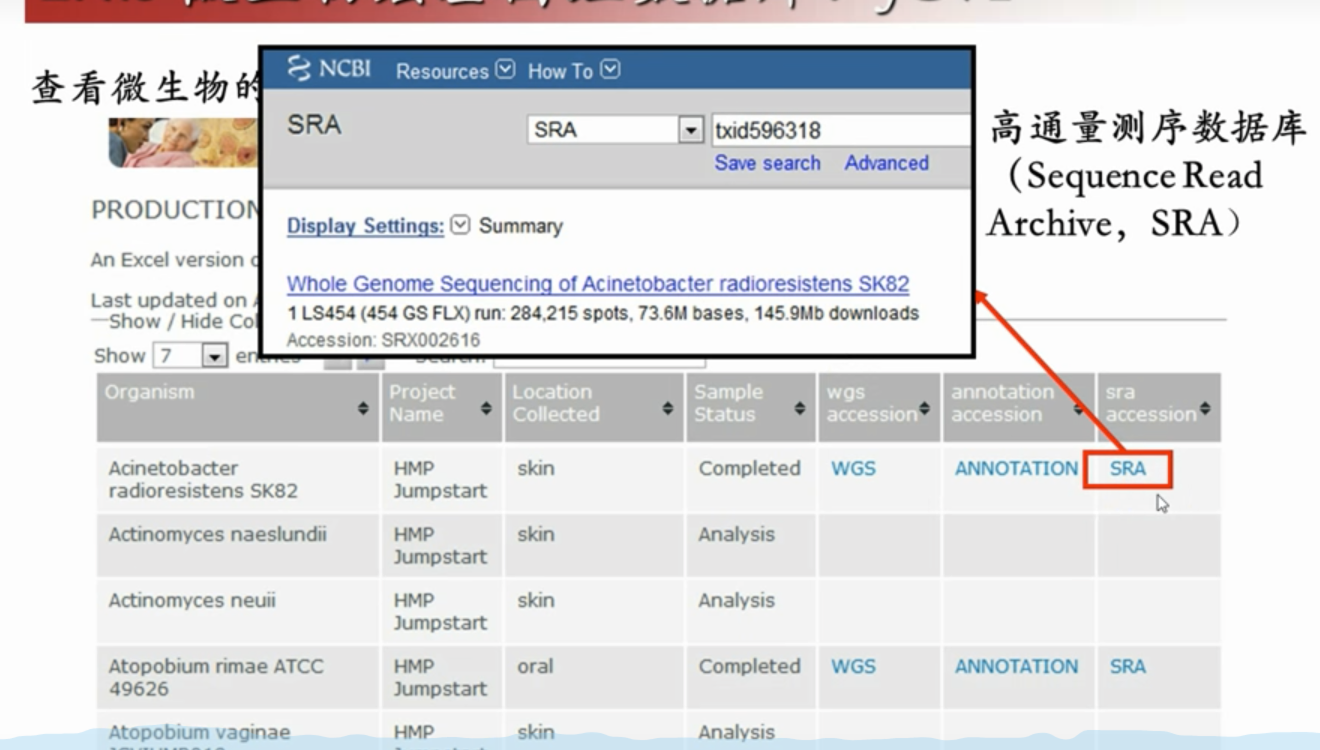
WGS全基因组鸟枪法测序项目数据库
-
SRA高通量测序数据库
-
Annotation是基因组在genbank中所有注释的链接
-
4 二级核酸数据库
一级数据库是直接实验得出的数据,二级数据库是经过处理、注释、分析的序列数据
- 二级核酸数据库(举例)
- RefSeg数据库:参考序列数据库,是通过自动及人工精选出的非冗余数据库,包括基因组序列、转录序列和蛋白质序列。
- dbEST数据库:表达序列标签数据库,包含来源于不同物种的表达序列标签 (EST)
- Gene数据库:为用户提供基因序列注释和检索服务,收录了来自5300多个物种的430万条基因记录
- 非编码RNA数据库:ncRNAdb,其不编码蛋白质,但在细胞中起调节作用
- microRNA数据库:miRBase,可以获得microRNA在基因组中的定位,挖掘microRNA序列之间的关系
蛋白质数据库
蛋白质数据库比核酸数据库种类多,但是annotation要直白的多
- 一级蛋白质数据库分为蛋白质序列数据库和蛋白质结构数据库
- 都是实验直接得出的数据
- 二级蛋白质数据库是基于一级数据库基础上,分析加工出来的
1 一级蛋白质序列数据库 UniProtKB
swissprot:人工标注的蛋白质序列数据库,可信度高,冗余度低
TrEMBL:蛋白质序列数据(由计算机完成):把数据库中能编码蛋白质的核酸序列,都翻译成蛋白质序列,然后存在里面,可信度低,冗余度大。所以剔除了所有swissprot中已经人工标注的序列
PIR:支持基因组学、蛋白质组学、和系统生物学综合研究的数据库
2002年这三个合并为Uniprot,
-
UniProt三个层次数据库:
- UniParc:收录所有UniProt数据库子库中的蛋白质序列,量大,粗糙。
- UniRef:归纳UniProt几个主要数据库并将重复序列去除后的数据库。
- UniProtKB:有详细注释并与其他数据库有链接的数据库,分为
-
swiss-port是经过检查的,TrEMBL是没经过检查的,计算机生成的

- 我们搜索"human dutpase"查看相关蛋白质序列信息
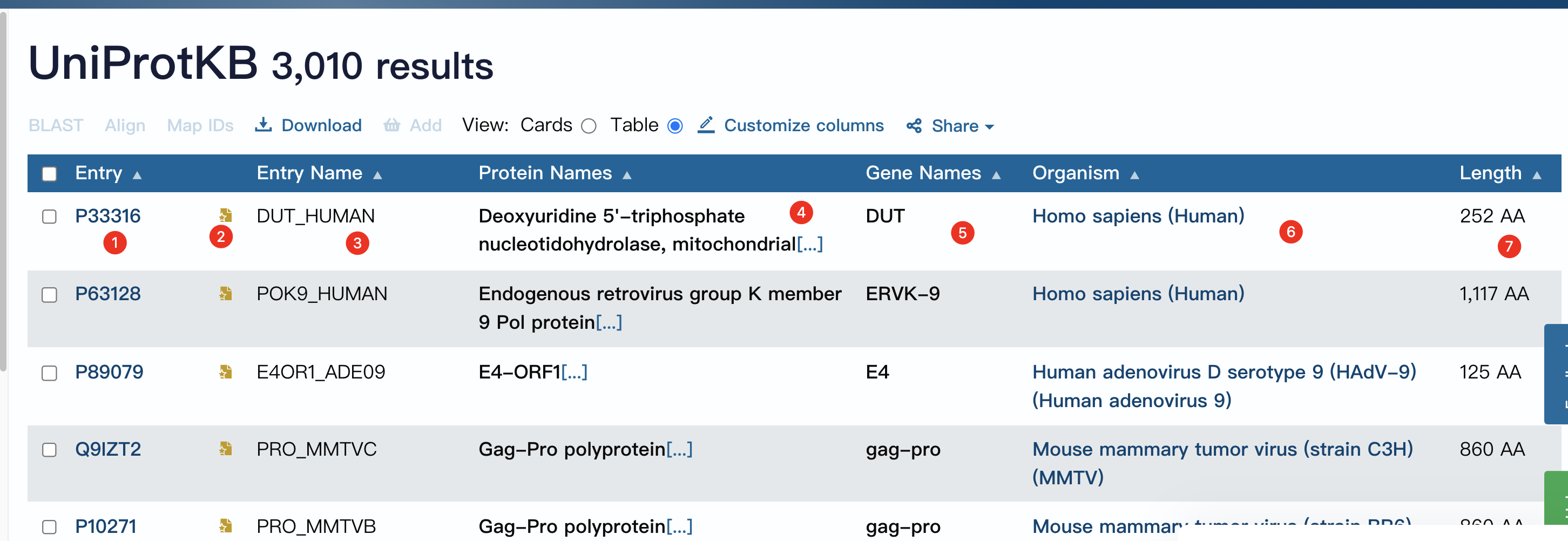
- 序列号
- 有这个标志的,就是swiss-port中的,也就是经过实验检查的
- 序列名 可以发现是来自哪个物种的
- 蛋白质名字
- 对应基因名
- 物种
- 长度
- 点击一条进去查看
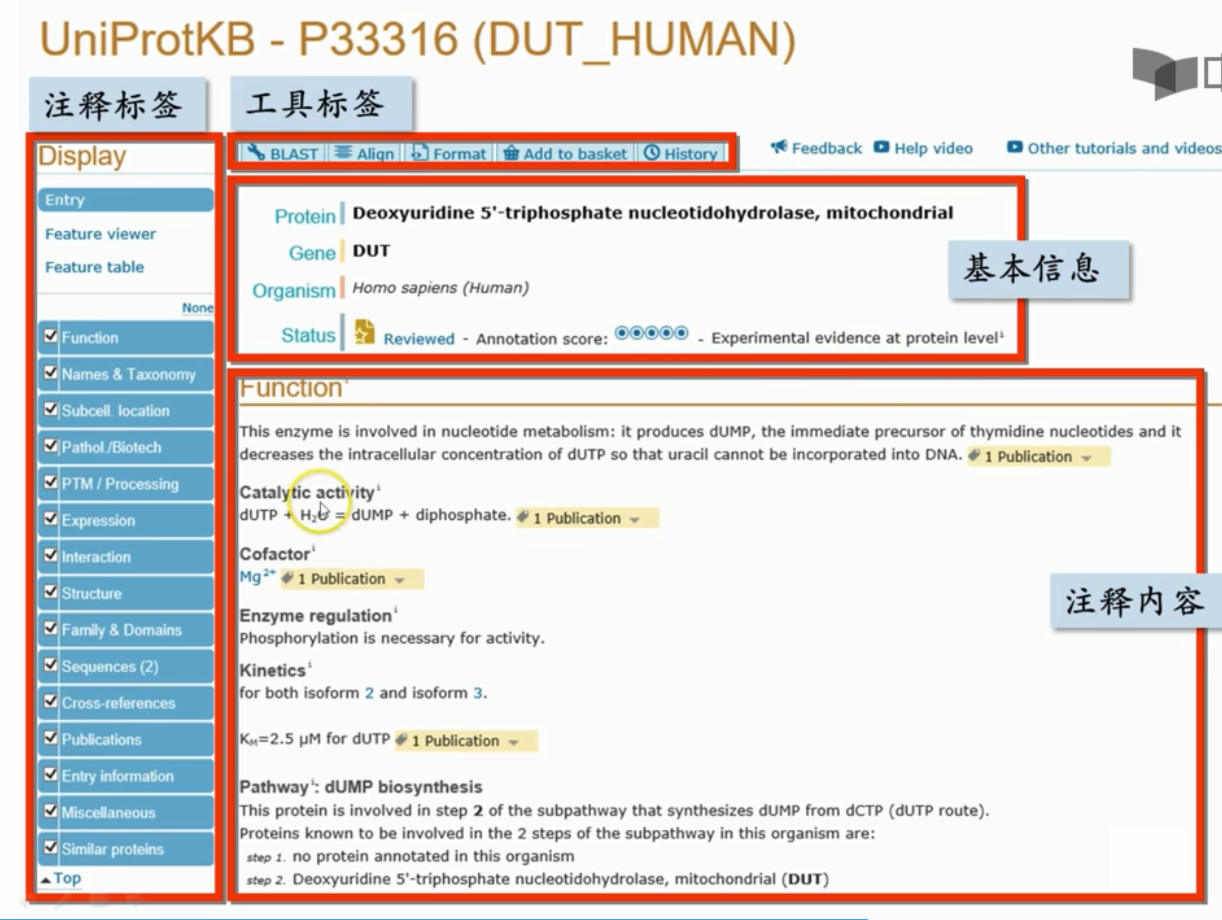
annotation score 就是注释打分,表示注释是否全面
-
具体注释
-
Function:蛋白质功能相关信息 描述、催化反应方程式、辅助因子、代谢途径
-
Names&Taxonomy:蛋白质名字,所属物种的分类学信息等基本信息
- 包括全称、别名等等 所属物种 分类谱系
-
Subcell location(重要)
-
成熟的蛋白质必须在特定的细胞位置才可以发挥其生物学功能。蛋白质在细胞内不同组分的定位,即为蛋白质的亚细胞定位
-
目前研究亚细胞定位的数据基本都来源于swissprot数据库
-
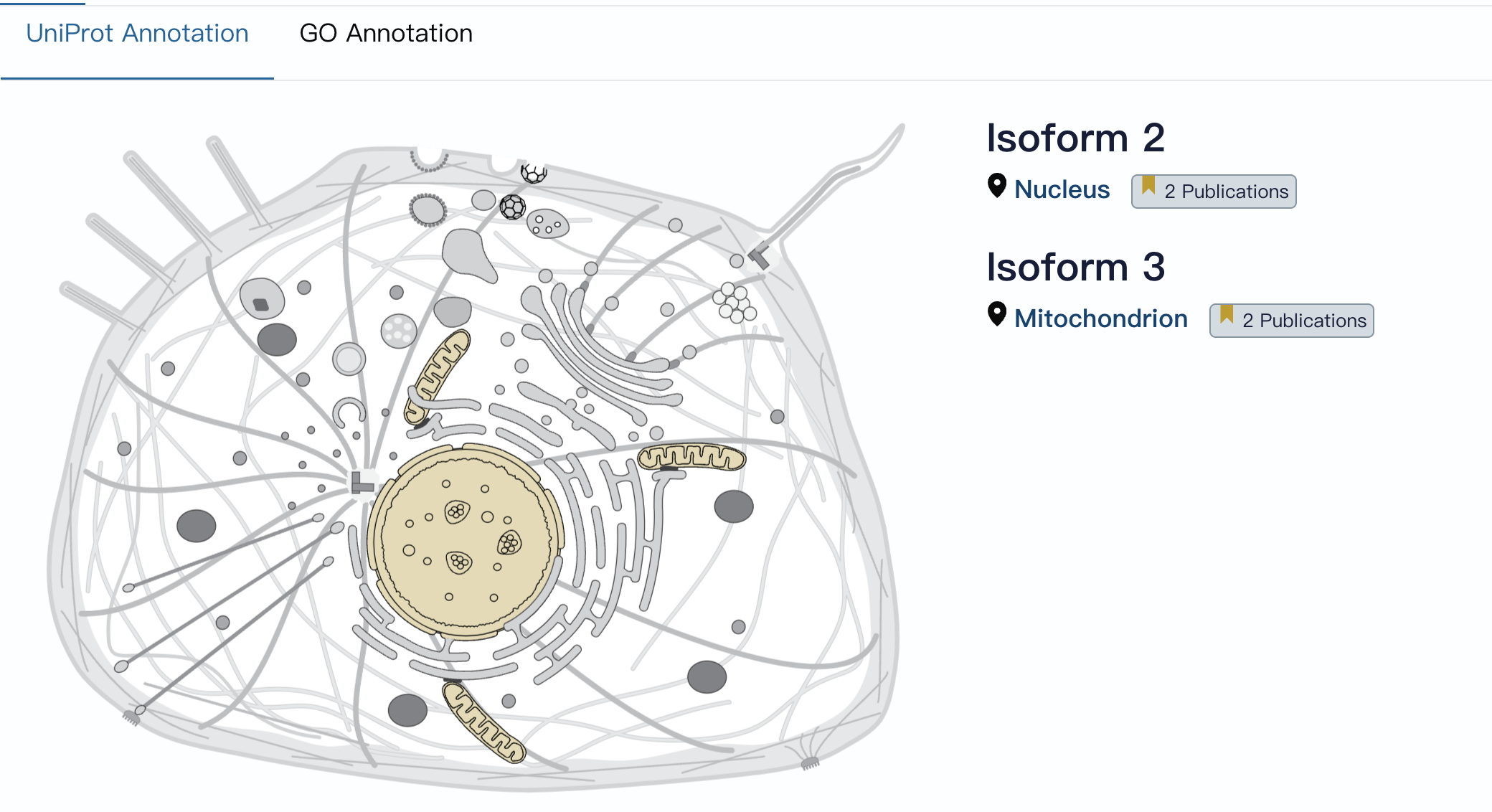
在上一节我们知道but基因有两种剪切方式,其中一种会保留前端的一种信号肽,会将蛋白质定位于线粒体,而没有的会留在细胞核。跟这里的注释是一样的
-
-
-
所以这个蛋白质有两个异构体
-
-
Pathology & Biotech: 提供蛋白质突变或缺失导致的族病及表型信息。
- 比如99位的丝氨酸会突变成丙氨酸,导致磷酸化的缺失,具体参考来源文献
-
PTM/ Processing:
- 提供蛋白质翻译后修饰 (Post-translationalmodification, PTM) 或翻译后加工的相关信息
- 比如信号肽到了指定位点后会被剪切掉
- 有些氨基酸位点上会发生甲基化 乙酰化 磷酸化的翻译后修饰
-
Eexpression:
- 提供了基因在mRNA水平上的表达信息,或者在细胞中蛋白质水平上的表达信息,或者在不同器官组织中的表达信息。
-
Interaction:
- 提供了蛋白质之间相互作用的信息
- 直接两两作用的蛋白质链接
- 蛋白质网络数据库中涉及的记录链接
-
Structure:提供蛋白质二级结构和三级结构信息注:只有那些通过实验方法测定三级结构并且已提交到蛋白质结构数据库PDB的蛋白质才有结构注释。
- 一条蛋白质对应多个结构
-
Family & Domains:
- 提供蛋白质家族及结构域信息。
- 与系统发生数据库和结构域数据库链接
-
Sequence:
- 提供蛋白质氨基酸序列信息。多个isoform(异构体)会显示多条序列。
-
Publications:列出了有关这个蛋白质已发表的所有文献信息
保存下载
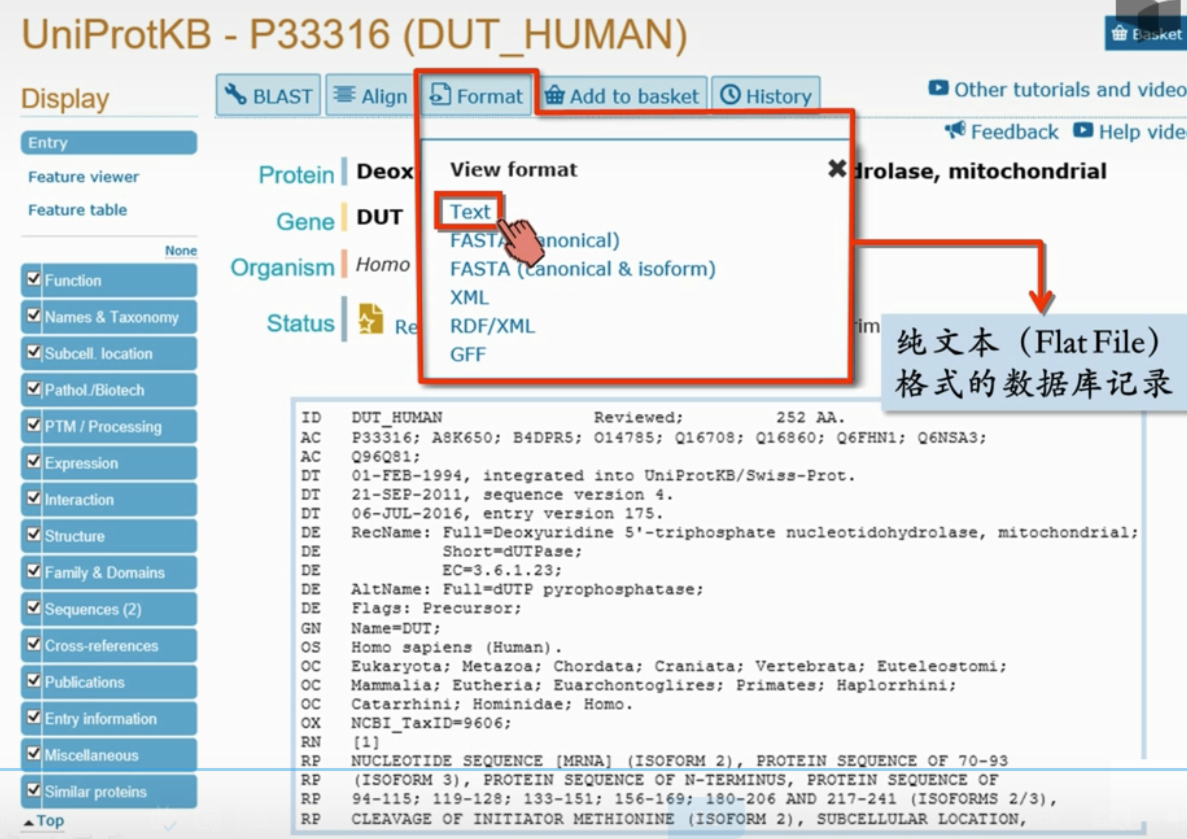
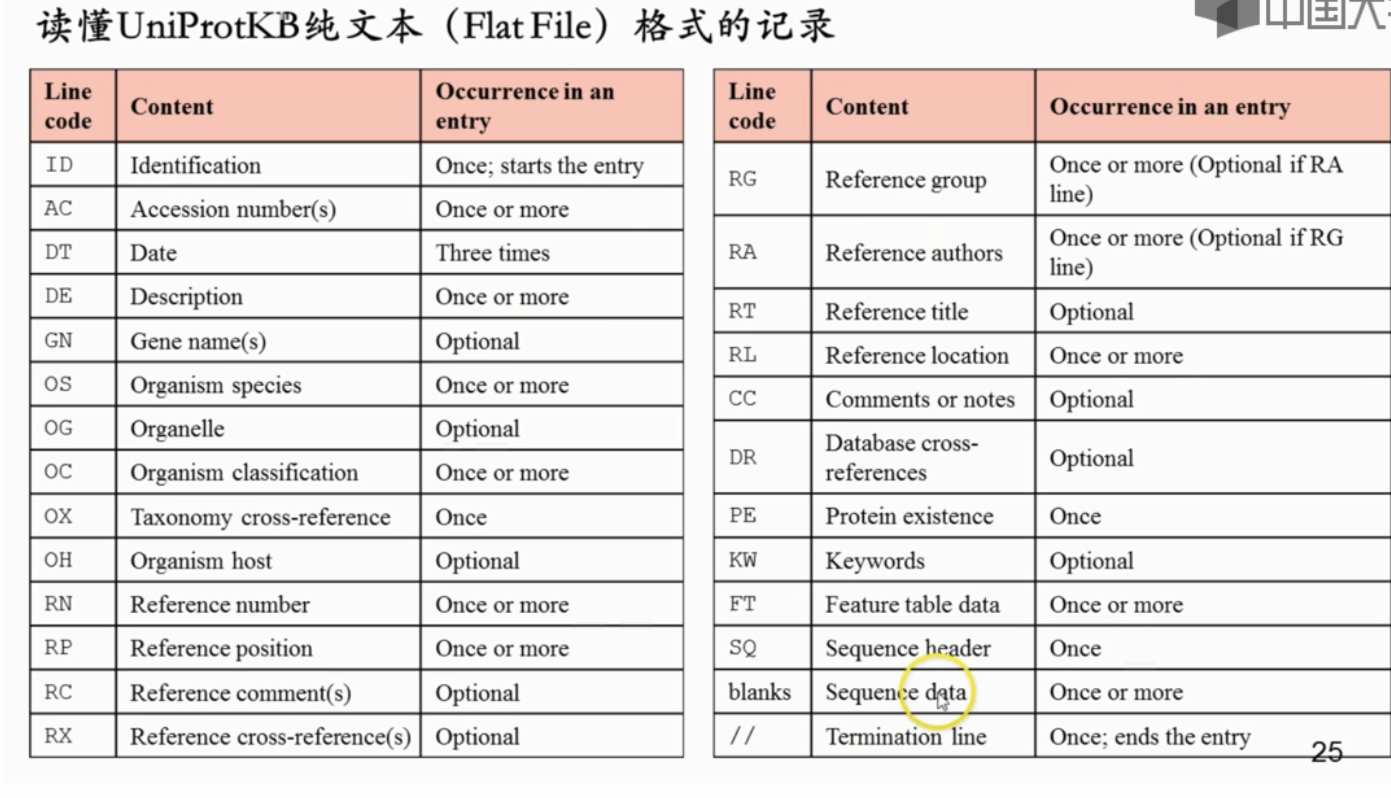
可以保存成纯文本格式的file,其中每行开头的字母表示这一行记录什么内容
参考如下表
2 一级蛋白质结构数据库 PDB

- 蛋白质的结构可分为四级:
- 一级结构 Primary structure
- 氨基酸序列
- 二级结构 Secondaty structure
- 周期性的结构构象,Q螺旋,阝折叠等
- 三级结构 Tertiary structure
- 整条多肽链的三维空间结构,3D结构
- 四级结构 Quaternary structure
- 几个蛋白质分子(亚基)形成的复合
体,如四聚体
- 几个蛋白质分子(亚基)形成的复合
- 一级结构 Primary structure
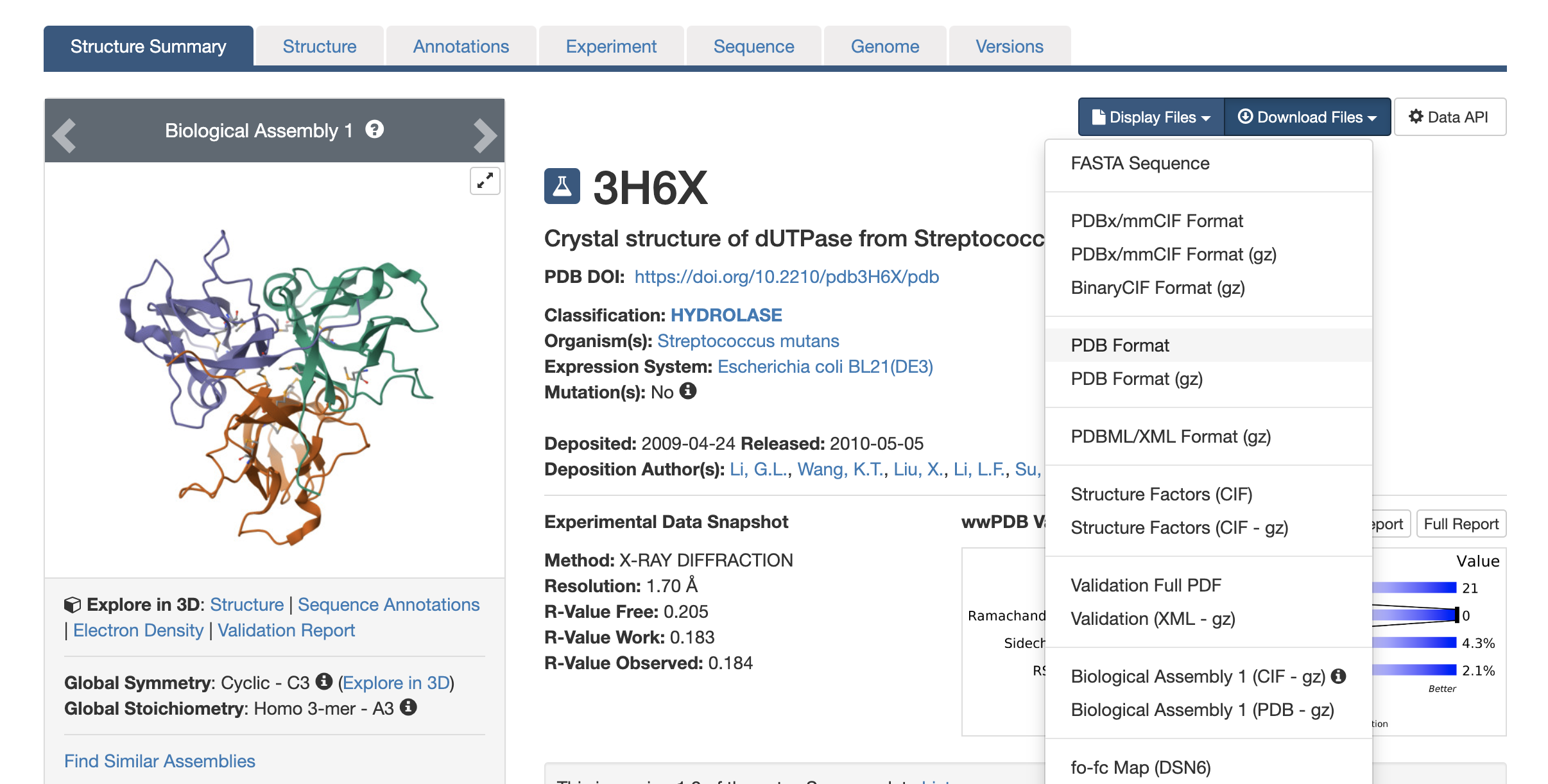
我们前面讲过苏教授发表的关于dUTPase晶体结构的文章,我们在PDB数据库中就查找该文章所发现的蛋白质晶体结构
搜索"Su X D dUTPase"
打开“3H6X”这个
-
PDB
-
蛋白质结构数据库
-
同一个蛋白质可能有多个不同结构,可能是不同的作者提交的,也有可能是不同形态
- 每个结构对应的PDB ID是唯一的,而不是蛋白质对应的PDB ID是唯一的。就如同上面这个“3H6X”一样
-
真正的结构存储在pdb纯文本文件中,需要download
- 打开后第一部分是基本信息描述

- HEADER:分子类别,日期,PDBID
- COMPND:对各个分子的描述
- KEYWDS:系列关键词, 可用于数据库搜索
- SOURCE:结构中包括的每一个分子的实验来源(生物学/化学
- EXPDTA:测定结构所用的实验方法:
- 绝大多数:X-RAY DIEERACTION X-射线衍射
- REVDAT:历史上曾经对该数据库记录进行过的修改
- JRNL:发表这个结构的文献
- REMARK:无法归入以上内容的注释
- 一级结构信息部分
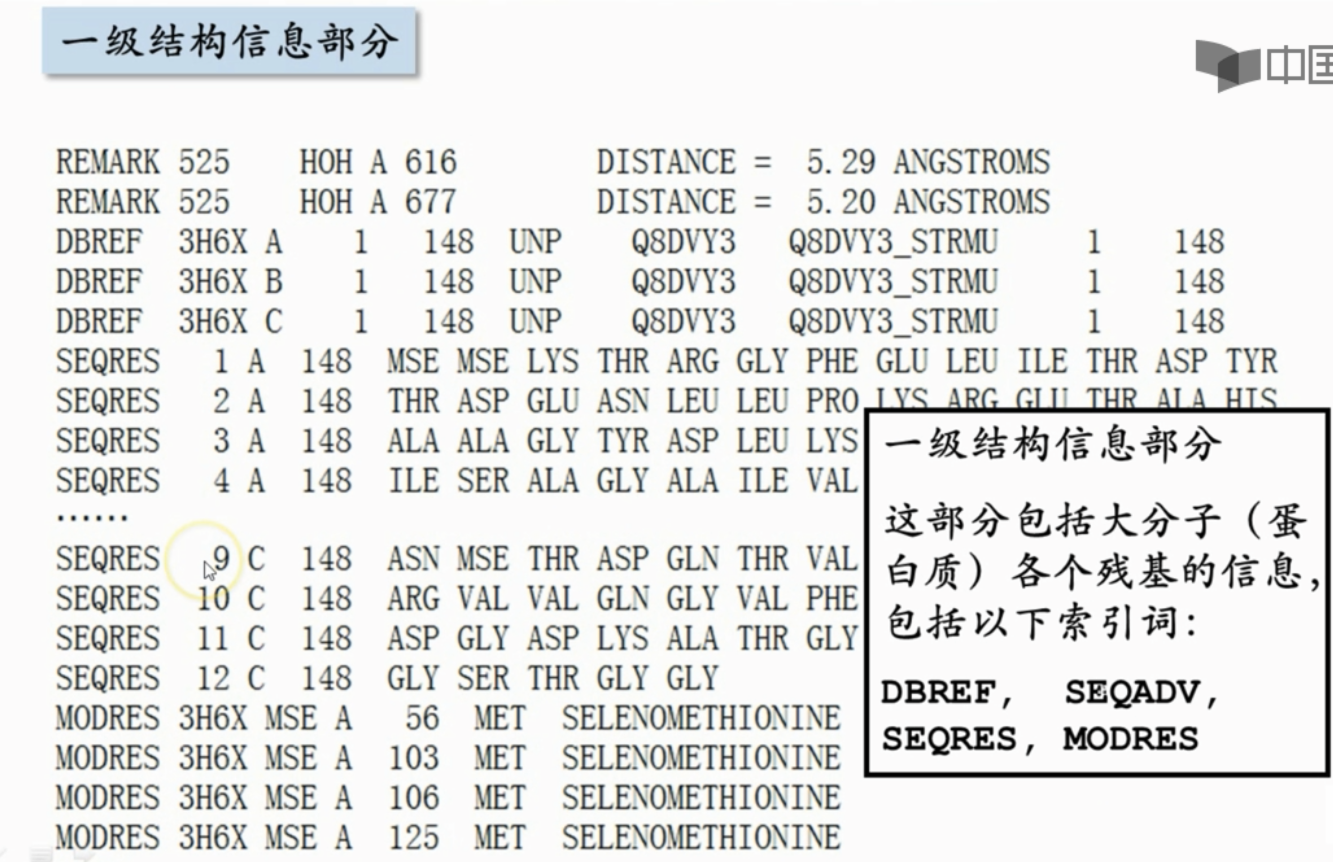
- 一级结构
- DBREF:一级结构信息:该蛋白质在蛋白质序列数据库UniProt中的检索号等信息
- SEQRES:氨基酸序列
- MODRES:对标准残基上的修饰
- 比如这些位置上的蛋氨酸被硒代蛋氨酸给取代
- 非标准残基部分

- 二级结构部分
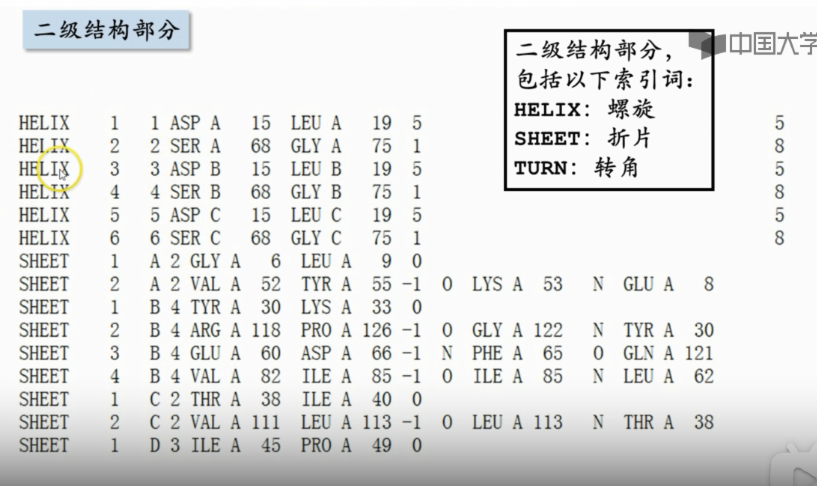
- 哪里是螺旋、哪里是折变

- 比如106号氨基酸上的C和107号上的氨基酸上的N形成肽键,键长1.32
- 除了肽键,还有氢键、二硫键等等
-
3D坐标部分,每个原子的一些信息,蛋白上的每一个氨基酸上的每一个原子都能找到自己的位置,也就是因为这个,可以实现3d蛋白质结构的建模
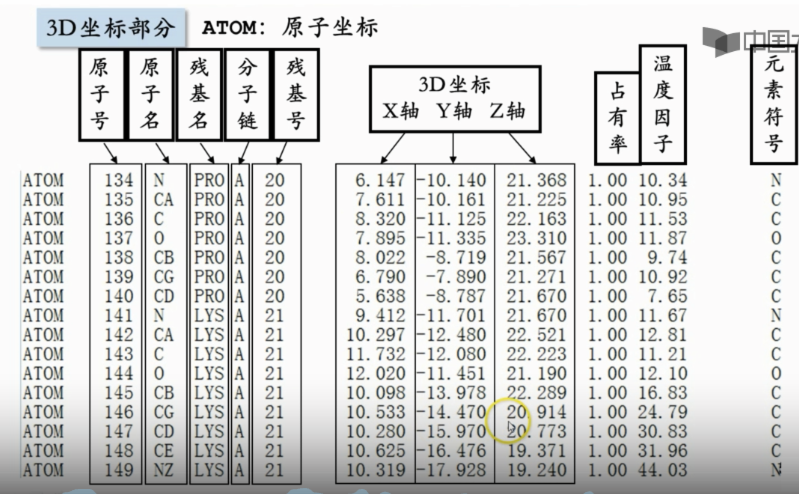
-
-
3D结构直观呈现:
- 很多软件,如JMOL,会根据原子坐标、大小,以及原子间距离画上化学键
- 安装java
PDB在线的查看只能看,没有分析功能,具体会在第六章介绍
3 二级蛋白质数据库
蛋白质一般是由一个或多个功能区城组成,这些功能区域通常称作结构域(domain)。在不同的蛋白质中结构域以不同的组合出现,形成了蛋白质的多样性。识别出蛋白质中的结构域对于了解蛋白质的功能有重要意义
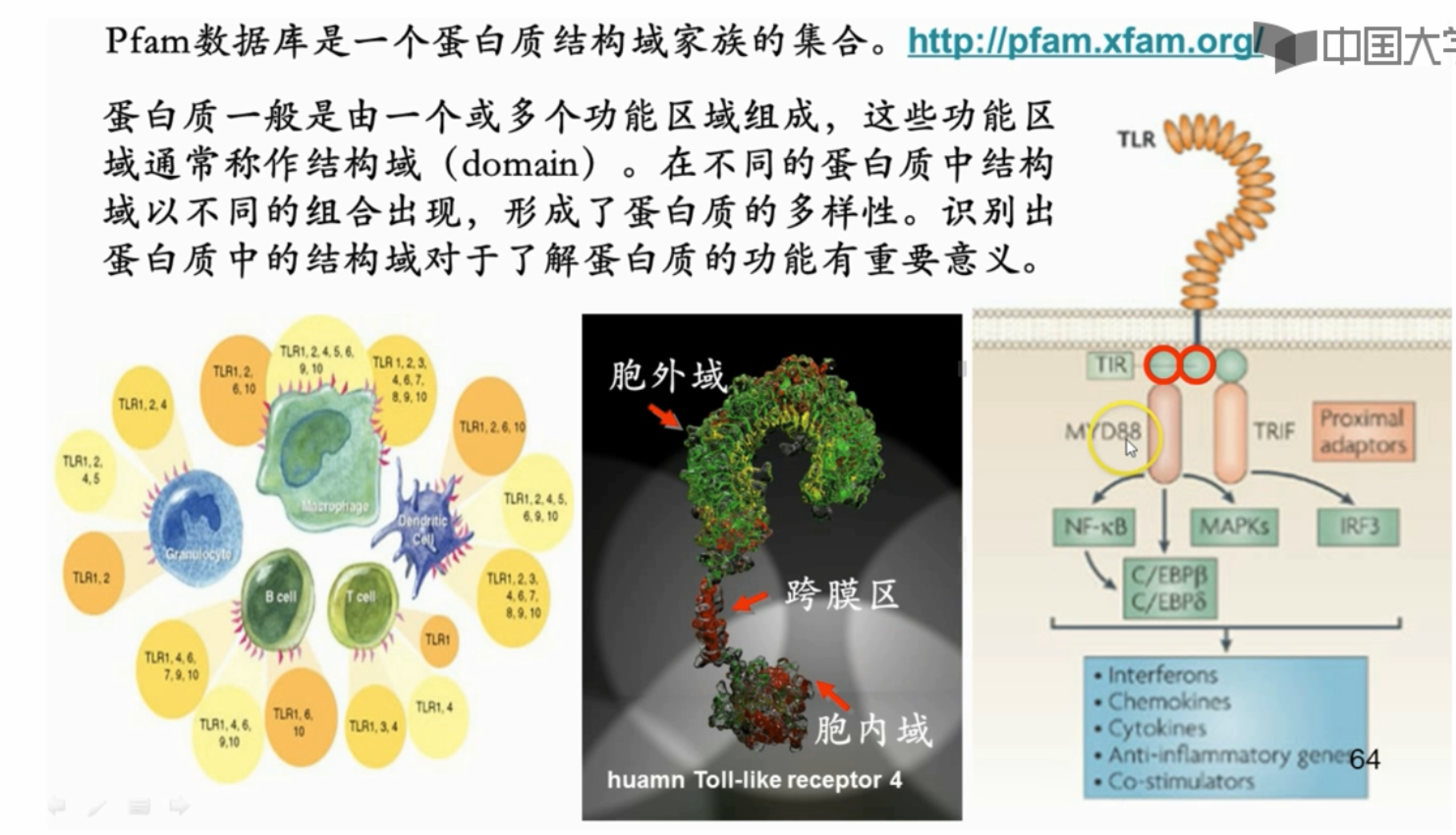
-
比如人体内有很多toll样受体蛋白,但是他们都分为三个结构域,如上图
- 胞外域识别入侵的东西,跨膜区穿模,胞内域行使一些胞内信号传导
-
最右边这个图可以看到,有一个免疫蛋白MYD88存在于细胞内,虽然功能与Toll样受体不同,但是有一个与Toll样受体胞内域相同的结构域,可以结合激活下游的一些信号传导
-
所以如果我们能够探明一个未知功能的蛋白质上有哪些已知的结构域,那就大致可以推测出它的功能了
3.1 Pfam
在Pfam平台(现已停用)查找该蛋白相关结构域
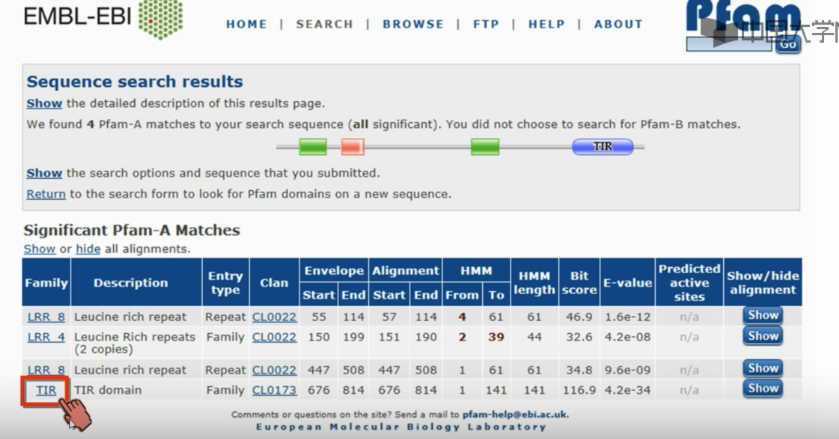
TIR就是胞内域,可以点开查看其具体注释
- 有一些平台,可以输入蛋白质序列,然后检测出其上有已知的结构域
- 可以获得结构域的功能注释和功能信息
3.2 Cath
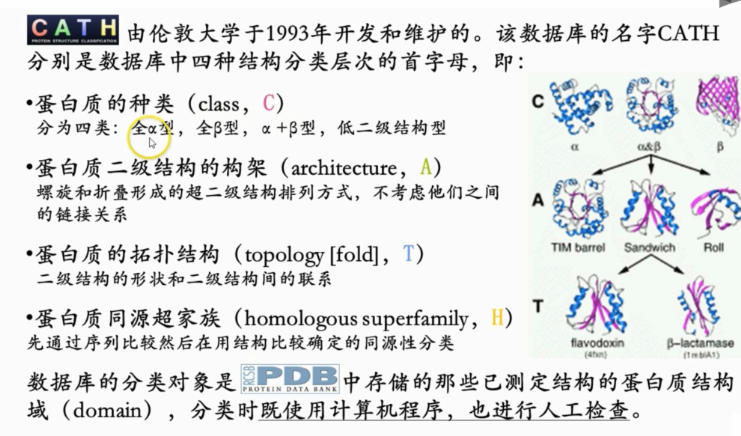
结构分类是针对结构域进行的,而不是整个蛋白质 ,所以CATH中一个蛋白质可能对应多个分类
- 蛋白质结构分类数据库
- CATH分类对象是PDB中存储的已经测定结构的结构域名(domain)
- 分类代码

目前CATH已经为15万个蛋白质的50多万个结构域进行了分类,可以归类进5481多个蛋白质超家族中(2024.3.16)
- 聚类
- 所有拥有2.70.40.10.10.1.1.2.1结构域的蛋白质序列,进行聚类
-

3.3 SCOP2

4层分类
专用数据库
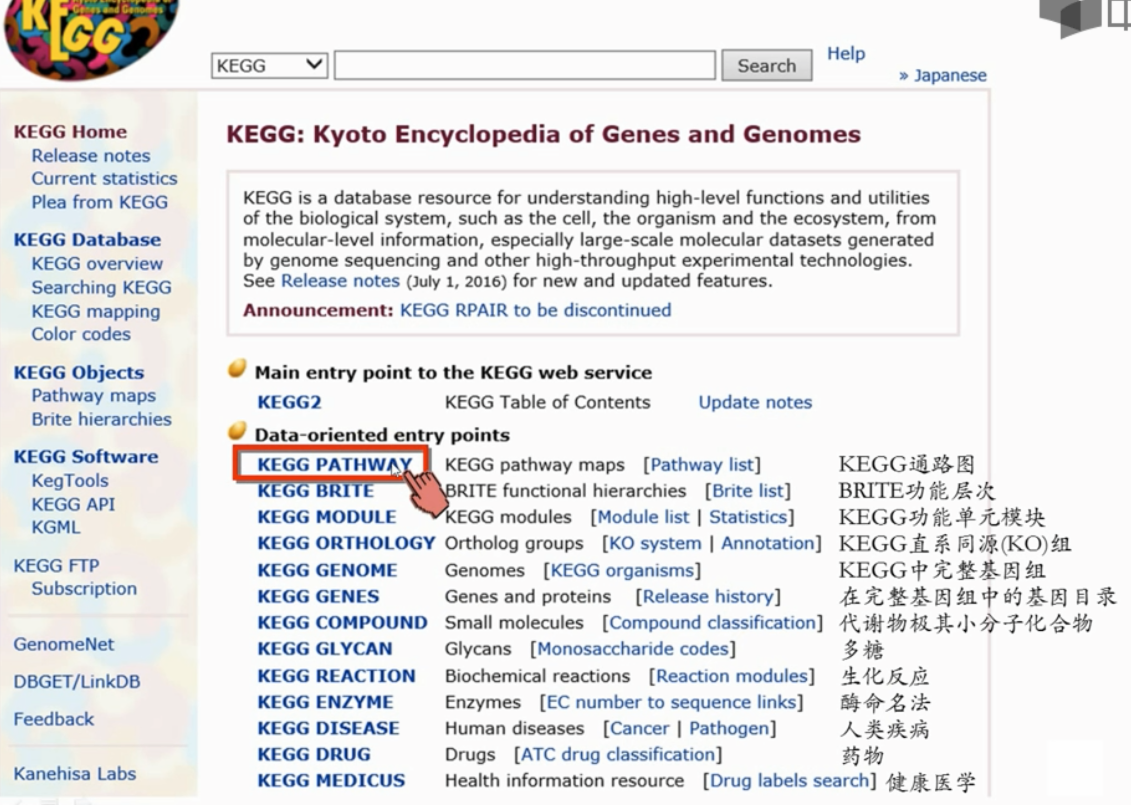
1 KEGG
KEGG:生物总的代谢通路图,百科全书

1.1 三羧酸循环
点击pathway-metabolism(global)-metabolic pathways
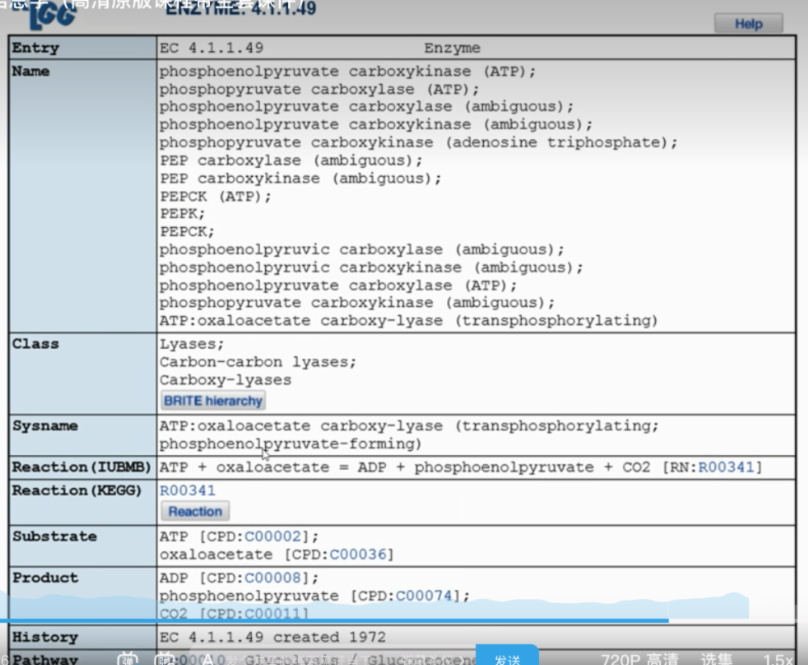
- 节点:代表特定的生化分子,如酶、代谢物或中间体。节点通常会被标注为特定的化合物(如“Fumarate”),或者以数字代码表示特定的酶,如“1.1.1.37”代表某个特定的酶的EC编号(酶的编码系统)。
- 线:代表生化反应,显示了分子如何转化为另一种分子,或者如何通过酶的作用被修改。通常,线的方向表示反应的方向。
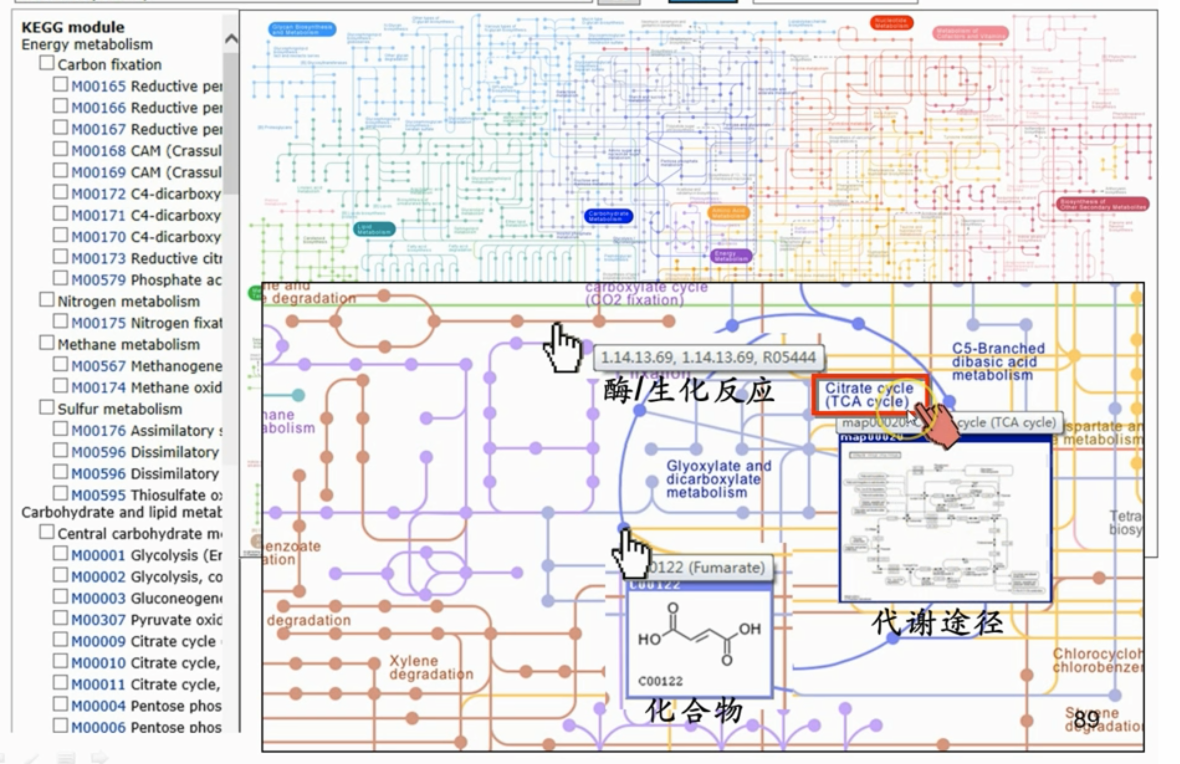
- 进一步详细查看三羧酸循环的具体路径

- 具体点开一个酶,展示了一个pathway条目,可以发现KO体系,提供酶在代谢网络中的上下文,包括它所参与的所有生化通路
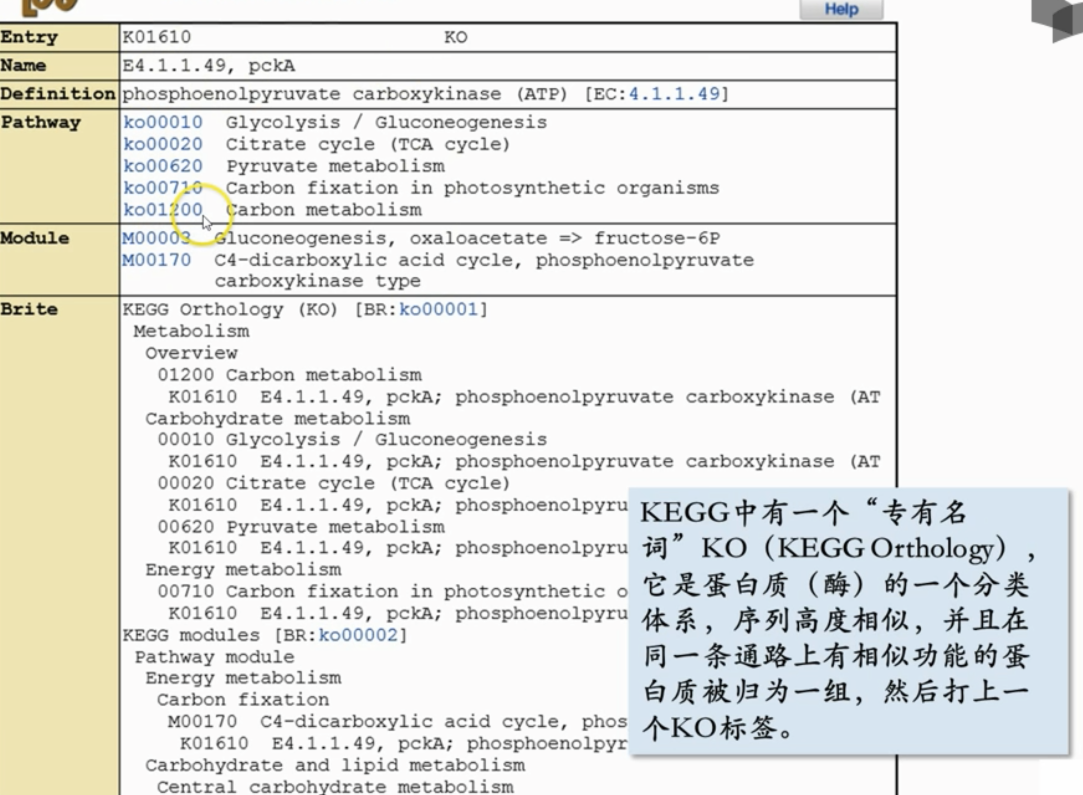
- 酶学分类:提供对该酶更具体的生化特征的深入信息,包括它催化的特定反应以及在这些反应中使用的底物和产物。
1.2 Toll样受体(Toll-like receptors, TLR)
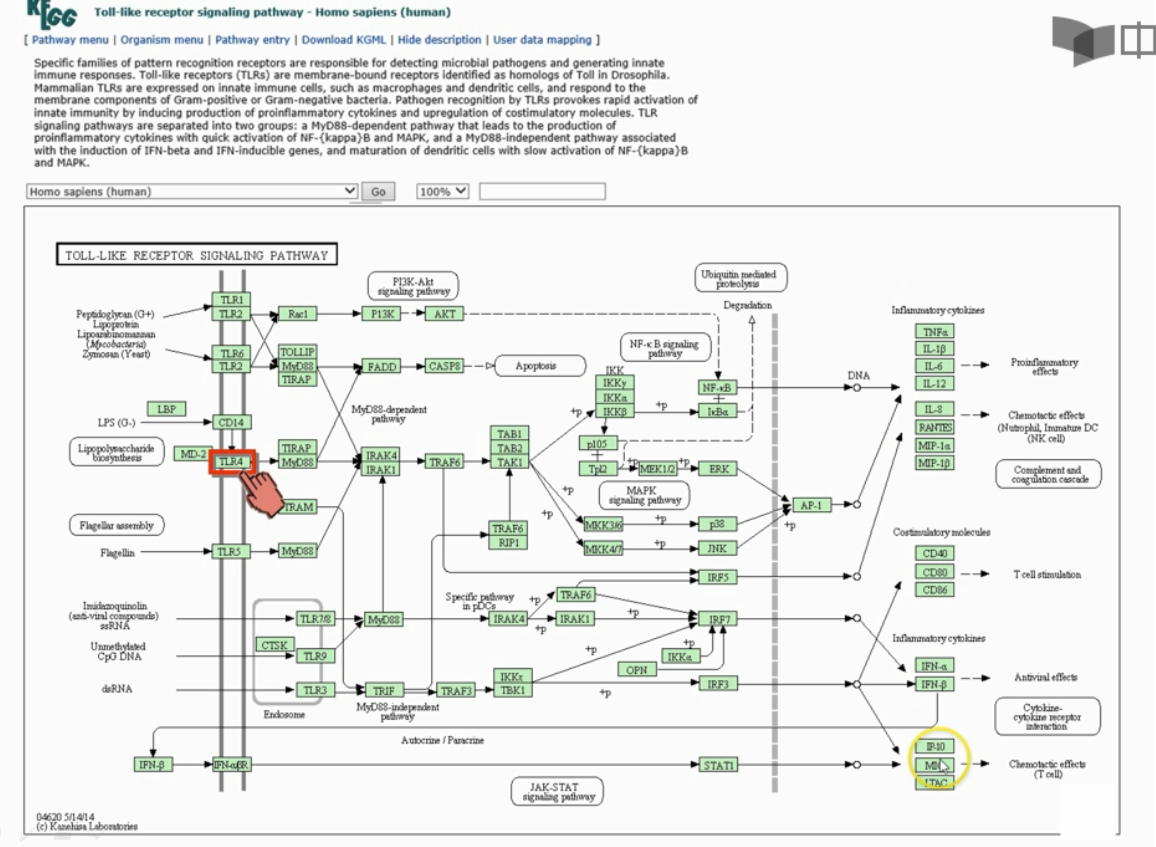
点击pathway之后,选择“5 Organismal Systems”,选择“5.1”里的“Toll-like receptor signaling pathway”
人类的Toll样受体信号通路的简化示意图,用于展示我们的免疫系统如何通过Toll样受体(TLRs)识别病原体。
- TLRs:不同的TLRs(例如TLR1, TLR4, TLR5)识别病原体的特定成分。
- 信号传递:当TLRs识别到病原体后,它们激活信号传递分子,如MyD88,开始一系列的反应。
- 激活核因子:信号传递激活了如NF-κB这样的转录因子。
- 产生细胞因子:激活的转录因子调控炎症反应相关的基因,引导细胞因子(如TNF-α, IL-1β, IFN-α/β)的产生。
- 产生效应:细胞因子促进炎症反应,吸引免疫细胞到感染部位,并激活抗病毒防御机制。
- 随便点开一个toll样受体,比如TLR4,可以看到它的详细信息
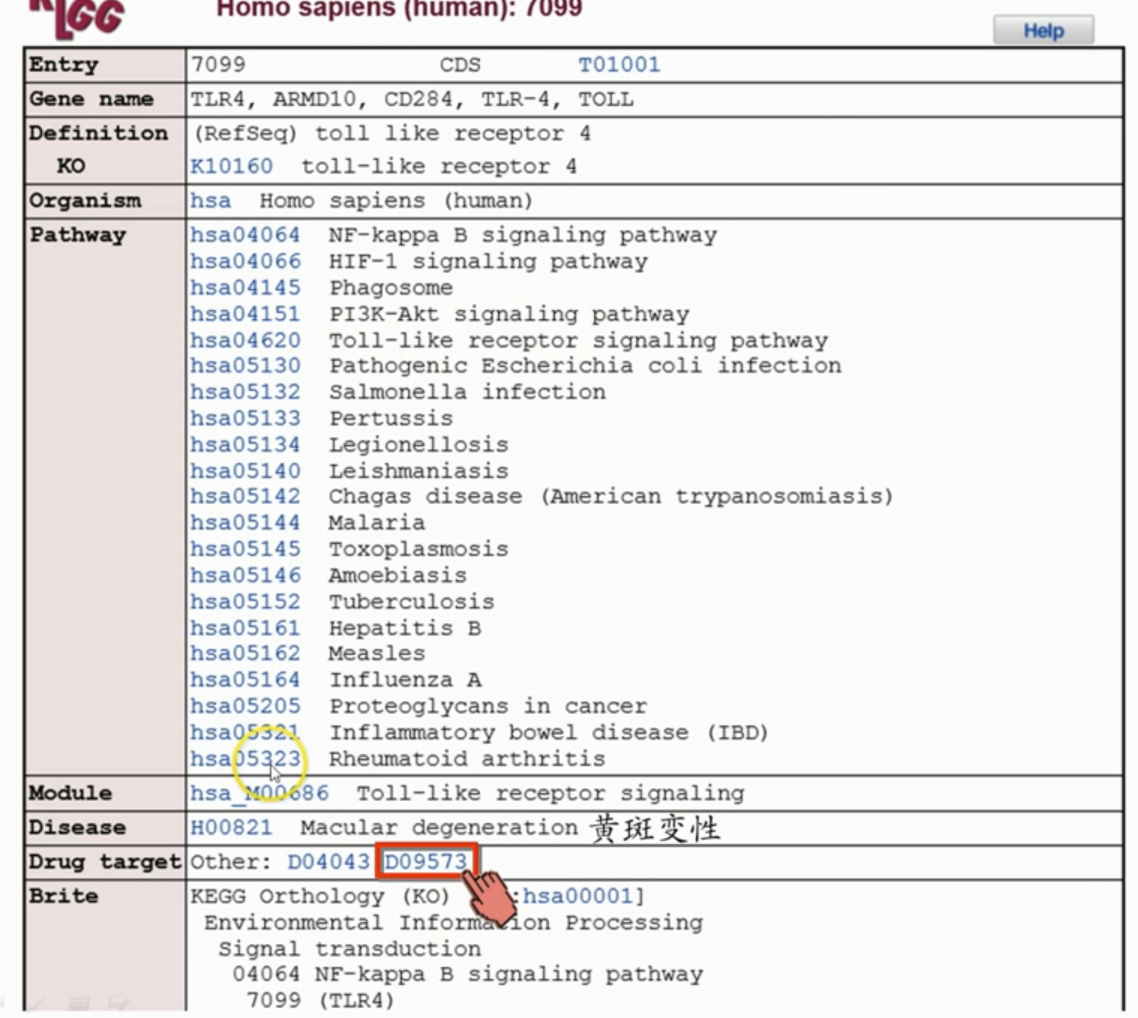
可以提供很多信息,比如这里提供了药物靶点,就是针对这个TLR4设计的药
2 OMIM
搜索阿尔兹海默症AD,找到了相关的基因