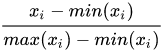KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路非常简单直观:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别 。
该方法的不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最邻近点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。另外还有一种 Reverse KNN法,它能降低KNN算法的计算复杂度,提高分类的效率 。
KNN算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分 。
——百度百科
一、算法思想:
已经有的样本,均有n个特征值,可以用n个坐标轴表示出这个样本点的位置。
而测试集中的元素,也均有n个特征值,也可以用n个坐标轴表示出这个样本点的位置。
对于每个测试集中的元素,找到距离其最近的k个点(距离可使用欧氏距离),在这k个点中选出数量最多的一个种类,将这个种类作为其结果。
需要注意的是,由于每个坐标的相对大小不同, 需要将数值做归一化处理。
二、代码
思想不难,代码:
import csv
import math
import operatorfrom matplotlib import pyplot as pltdef guiyihua(train, input):maxval1 = 0minval1 = 101maxval2 = 0minval2 = 101for i in range( len(train) ):train[i][0] = float(train[i][0])train[i][1] = float(train[i][1])maxval1 = max(maxval1, train[i][0])minval1 = min(minval1, train[i][0])maxval2 = max(maxval2, train[i][1])minval2 = min(minval2, train[i][1])for i in range( len(input) ):input[i][0] = float(input[i][0])input[i][1] = float(input[i][1])maxval1 = max(maxval1, input[i][0])minval1 = min(minval1, input[i][0])maxval2 = max(maxval2, input[i][1])minval2 = min(minval2, input[i][1])for i in range( len(train)):train[i][0] = (train[i][0]-minval1)/(maxval1-minval1)train[i][1] = (train[i][1]-minval2)/(maxval2-minval2)for i in range( len(input) ):input[i][0] = (input[i][0]-minval1)/(maxval1-minval1)input[i][1] = (input[i][1]-minval2)/(maxval2-minval2)def load(fname):with open(fname, 'rt') as csvfile:lists = csv.reader(csvfile)data = list(lists)return datadef euclideanDistance(atrain, ainput, needcal):re2 = 0for i in range(needcal):re2 += (atrain[i] - ainput[i])**2return math.sqrt(re2)def jg(train, ainput, k):alldis = []needcal = len(ainput)-1 #需要计算的维度for i in range(len(train)):nowdis = euclideanDistance(train[i], ainput, needcal)alldis.append((train[i], nowdis))alldis.sort(key=operator.itemgetter(1))vote = {}for i in range(k):type = alldis[i][0][-1]if type in vote:vote[type] += 1else:vote[type] = 1sortvote = sorted(vote.items(), key=operator.itemgetter(1), reverse=True)#items()将字典转为列表,这样可以对第二个值进行排序return sortvote[0][0]def showright(train, input):plt.subplot(2, 5, 1)plt.title("right")for i in range(len(train)):if train[i][-1] == "第一种" : plt.scatter(train[i][0], train[i][1], c = '#0066FF', s = 10, label = "第一种")else :plt.scatter(train[i][0], train[i][1], c = '#CC0000', s = 10, label = "第二种")for i in range(len(input)):if input[i][-1] == "第一种" :plt.scatter(input[i][0], input[i][1], c = '#0066FF', s = 50, label = "cs第一种")#plt.scatter(input[i][0], input[i][1], c = '#FF3333', s = 30, label = "cs第一种")else :plt.scatter(input[i][0], input[i][1], c = '#CC0000', s = 50, label = "cs第一种")#plt.scatter(input[i][0], input[i][1], c = '#FF33FF', s = 30, label = "cs第二种")def showtest(train, input, re, ki, cnt):plt.subplot(2, 5, ki+1)plt.title("k = "+ repr(ki)+" acc: "+repr(1.0*cnt/(1.0*len(input))*100 )+ '%')for i in range(len(train)):if train[i][-1] == "第一种" :plt.scatter(train[i][0], train[i][1], c = '#0066FF', s = 10, label = "第一种")else :plt.scatter(train[i][0], train[i][1], c = '#CC0000', s = 10, label = "第二种")for i in range(len(input)):if re[i] == "第一种" :plt.scatter(input[i][0], input[i][1], c = '#0066FF', s = 50, label = "cs第一种")#plt.scatter(input[i][0], input[i][1], c = '#00FF33', s = 30, label = "cs第一种")else :plt.scatter(input[i][0], input[i][1], c = '#CC0000', s = 50, label = "cs第二种")#plt.scatter(input[i][0], input[i][1], c = '#00FFFF', s = 30, label = "cs第二种")
def main():train = load("C:\\Users\\T.HLQ12\\Desktop\\wdnmd\\python\\jiqixuexi\\train.csv")input = load("C:\\Users\\T.HLQ12\\Desktop\\wdnmd\\python\\jiqixuexi\\test.csv")guiyihua(train, input)# print(train)# print(input)showright(train, input)for ki in range (1, 10):re = []k = kicnt = 0for i in range(len(input)):type = jg(train, input[i], k)if(type == input[i][-1]):cnt += 1re.append(type)print("预测:" + type + ",实际上: " + input[i][-1])print("准确率: " + repr(1.0*cnt/(1.0*len(input))*100) + '%')showtest(train, input, re, ki, cnt)plt.show()
main()逐个解释一下:
guiyihua:
不会归一化的英文,就写拼音了,从训练集和测试集中找出一个最大值和最小值。然后把训练集和测试集的数据都减去最小值,再除以最大值减最小值即可。
load:
使用with open可以不用人为关闭文件。其中csv.reader会返回一个迭代器,配合list将data赋值为二维数组。
euclideanDistance:
欧式距离,就是把所有维度平方下相加,然后再返回开根号的值。
jg:
这个是judge的缩写,判断输入的测试集中的一个元素的种类。函数的参数有训练集,一个输入的值和一个k。遍历训练集中的所有元素,算出距离测试点的欧式距离,然后添加到alldis数组里。最后对数组进行排序(参数中意味按照元组中第一个值排序,默认从大到小)。然后创建一个vote字典。这个字点的第一个值是种类,第二个值是种类的个数。循环遍历距离数组,每次碰到一个种类,就把这个种类的数量加一。循环结束后,对这个字典的第二个值进行排序(排序中参数:第一个item:将字典vote转换为一个包含键值对的列表, 第二个:对下标1进行排序,第三个:从大到小排序),选出最大数量的种类作为这个测试元素的结果。
shoright 与showtest:
这两个函数是用于绘制散点图的。Subplot中第一个参数是行数,第二个参数是列数。第三个参数是第几个部分。Title中可以设置这张图的标题。训练集中每个种类的颜色都不一样,点是使用scatter打上去的,其中第一个参数是这个点在第一条坐标轴上对应的值。第二个点是第二个坐标轴上对应的值,c是颜色。S是点的大小。 label是这个点的标签。循环遍历训练集和测试的每个点,就可以绘制出一张散点图。
三、实际问题
一、

如图所示,这个报错是因为vote中不存在vote括号中的值,修改为:

即可。
二、

这个问题不知道发生的原因是什么,查询资料本来以为是scatter可以使用切分,但是实际上没有办法使用,最后就替换成了循环遍历每个点来绘制散点图的方式。
四、实验结论
结果:(第一张图为对的。对于每张图,大的是测试集,小的是训练集,颜色相同的是一个种类)


数据:

从结果分析上来看,K在1~9范围内,不能很好的确定最优值,需要多次取值,反复确认才能锁定k值。
尽管有着计算量大,维度灾难等缺点,但是可以不用训练,容易理解,对于新手来说很友好。
(纯手打,求老师轻点批改)