想象一下,如果把世界上所有的图片都找来,给它们放到一块巨大的空地上,其中内容相似的图片放得近一些,内容不相似的图片放得远一些(类比向量嵌入)。然后,我随机地向这片空地撒一把豆子,那么这把豆子怎么才能尽量撒得均匀?
在真实世界收集数据集的过程就像是在撒豆子,把被撒到豆子的图片收集起来。简单来说,豆子撒不匀,数据集就有偏置。
论文标题:
A Decade’s Battle on Dataset Bias: Are We There Yet?文章链接:
https://arxiv.org/pdf/2403.08632.pdf
数据集偏置之战,最初在2011年由知名学者Antonio Torralba和Alyosha Efros提出——Alyosha Efros正是Sora两位一作博士小哥(Tim Brooks和William Peebles)的博士导师,而Antonio Torralba也在本科期间指导过Peebles。
如今13年过去,这场旷日持久的战争仍在继续,CV大牛何恺明团队再次深度解析这个问题,模型表现好是源于能力提升还是捕获数据集偏置?
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
什么是数据集偏置?
数据集偏置(Dataset Bias)是指在数据收集、选择或处理过程中引入的系统性偏差,导致数据集不能公平、全面地代表整个问题空间或现实世界的各个方面,而是较为集中地代表其中某些方面。这种偏差会影响数据集的代表性,进而影响训练模型的鲁棒性、泛化能力和公平性。
计算机视觉任务中,察觉数据集的偏置对人类来说是十分困难的,下面的15张图片分别来自3个数据集,每个数据集5张,你能发现哪5张图片来自同一数据集吗?

揭晓答案: 1, 4, 7, 10, 13来自同一数据集,名为YFCC 2, 5, 8, 11, 14来自同一数据集,名为CC 3, 6, 9, 12, 15来自同一数据集,名为DataComp
尽管对人类来说十分困难,但神经网络却可以轻易地发现数据集中存在的潜在偏置,分类准确率达到84.7%。即使是自监督分类也能达到惊人的78%
数据集偏置的来源(为什么豆子撒不匀?)
1、选择偏置(Selection Bias):数据收集过程中对特定样本的偏好选择。例如,在进行人脸识别研究时,数据集中的大多数人脸来自特定的种族或性别。
2、采样偏置(Sampling Bias):数据集的采样方法未能准确反映目标。
3、标签偏置(Label Bias):在监督学习中,数据标签可能受到客观或主观因素影响,导致某些类别被过度表示或错误标注。
4、社会文化偏置(Sociocultural Bias):数据集可能反映了特定社会、文化的偏见和刻板印象,这些偏见被模型学习后可能在预测时被放大,引发道德和社会问题。

论文的主要实验
论文通过一系列实验,说明了数据集的偏置问题,仍广泛存在于当今的计算机视觉研究中。
作者选定了六个数据集来进行数据集分类任务,用ConvNeXt-T模型来判断图片来自于哪个数据集,结果如下图所示,左边是选择了哪些数据集,右边是分类的准确率指标,作者共进行了24组实验。
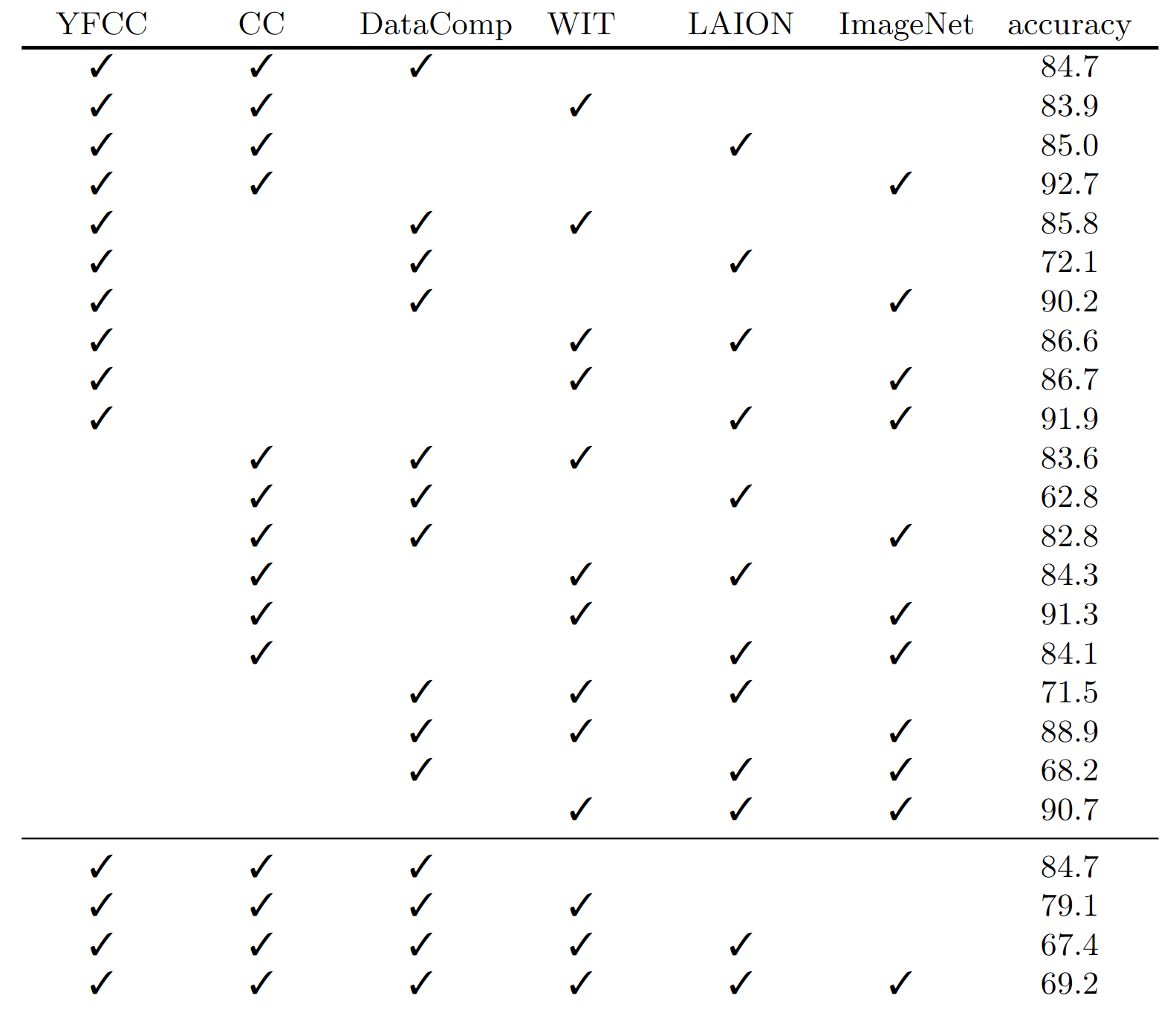
即使换用不同的模型,偏置效果依然显著

▲表为YFCC,CC,DataComp的分类结果
但是,进行伪数据集分类实验(把同一个数据集随机分成3类并打上不同的类别标签),准确率就会接近33%,这证明了实验任务的合理性。
CV数据集的偏置,是什么样的?
是低阶特征吗?
分别对原始数据集进行颜色抖动、加噪、模糊和降采样操作,如下图所示

发现对数据集的分类性能影响并不大
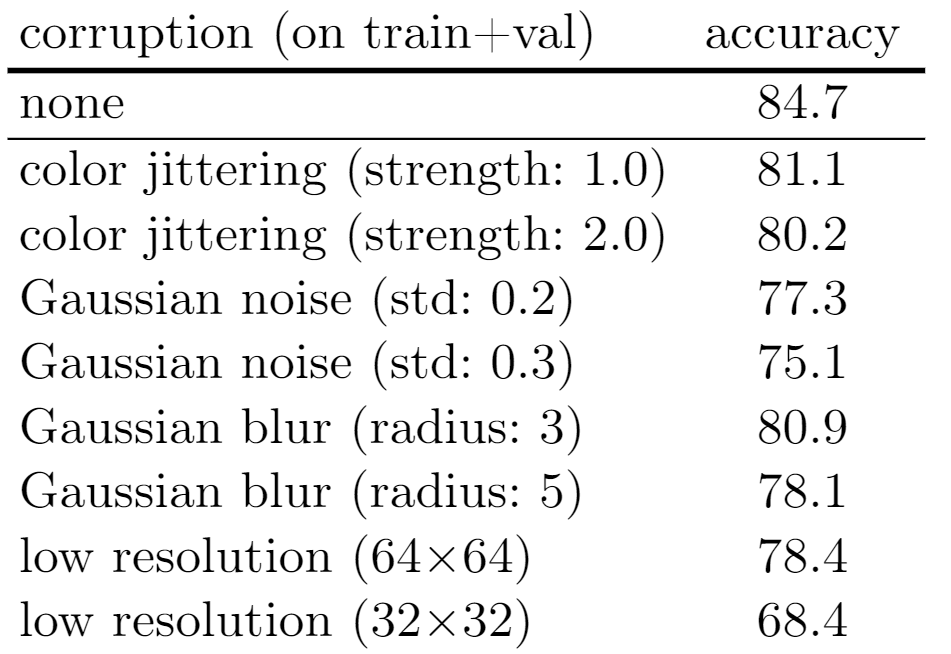
▲表为YFCC,CC,DataComp的分类结果
所以,低阶特征对数据集分类有点影响,但影响不大,低阶特征只能看作是数据集偏置的很小一部分。
更多的实际上是语义特征
文章进行了线性探测实验(linear probing),用于判断两个任务(任务a和任务b)的相似性。
具体来说,步骤是这样的: 1、任务a作为预训练任务,训练模型A 2、冻结模型A的所有参数,然后在A的顶层添加一个简单的线性分类器,我们称为模型B(冻结了参数的A+线性分类器) 3、在任务b上训练模型B
这样我们把模型A作为特征提取器,看看这个特征提取器对任务b的增益。
论文将数据集分类任务作为任务a,然后把ImageNet图片分类任务作为任务b,评估这些通过数据集分类学习到的特征在图像分类任务上的表现,结果如下

▲Y,C,D等对应前面6个数据集的首字母
结果显示,相比于随机初始化的权重,这些特征可以提升ImageNet分类任务的性能,尽管这种提升并不如直接在ImageNet上预训练的模型那样显著。
这证明了数据集分类任务所提取到的特征明显有益于图像分类任务,而图像分类任务需要的是语义特征。
讨论
CV数据集的偏置很可能以语义特征为主,而低阶特征通过干扰语义特征来影响偏置。
对于人类来说,NLP数据集的偏置更容易被察觉,比如文风,语义等等。相比之下,CV数据集的偏置就难以察觉,所以更值得研究。
判断数据集偏置(如何判断豆子到底撒的匀不匀?)
除了论文提到的数据集分类方法,还有一些其他工作提出的方法。
1、交叉数据集验证:在一个数据集上训练模型,然后在另一个数据集上测试它的性能。
2、分析数据集构成:统计分析数据集中的类别分布、样本多样性(如种族、性别、年龄等属性在人脸数据集中的分布),以及图像的获取和处理方式(例如拍摄角度、光照条件等)。
3、用户研究:让人类参与者尝试识别图像的数据集来源或评估图像的多样性。
4、平等机会:对于给定的正确标签,所有群体(通常是受保护的群体,如不同的种族、性别等)都应该有相同的真阳性率。
5、平均奇异值差异:比较两个数据集或两组模型特征的奇异值,以此来衡量它们在统计属性或信息含量上的差异。
用模型对抗数据集偏置(既然豆子撒不匀,有没有弥补的方法?)
这里我们介绍两篇先前的工作,他们试图通过改变模型的训练方式,来减少已有数据集偏置造成的影响。
对抗性学习:通过引入对抗性示例来增强模型鲁棒性,使其无法区分不同群体或类别的数据,从而减少模型对这些特征的依赖。
领域独立训练:使模型能够在多个不同的领域或数据分布中都表现良好。
所以到底怎么撒豆子?
回到我们文章开头的那个问题,我们如何把豆子撒的均匀呢?这篇论文也没有给出答案,自从2011年提出这个问题,它就一直伴随着整个深度学习革命,在今天这仍然是一个值得研究的方向。
总地来说,过去十年里,尽管在减少数据集偏差方面取得了一定进展,但现代神经网络的能力使得它们能够轻易地识别出数据集中的偏置,这提示我们在建立数据集时应当更加小心。