AB测试面试题

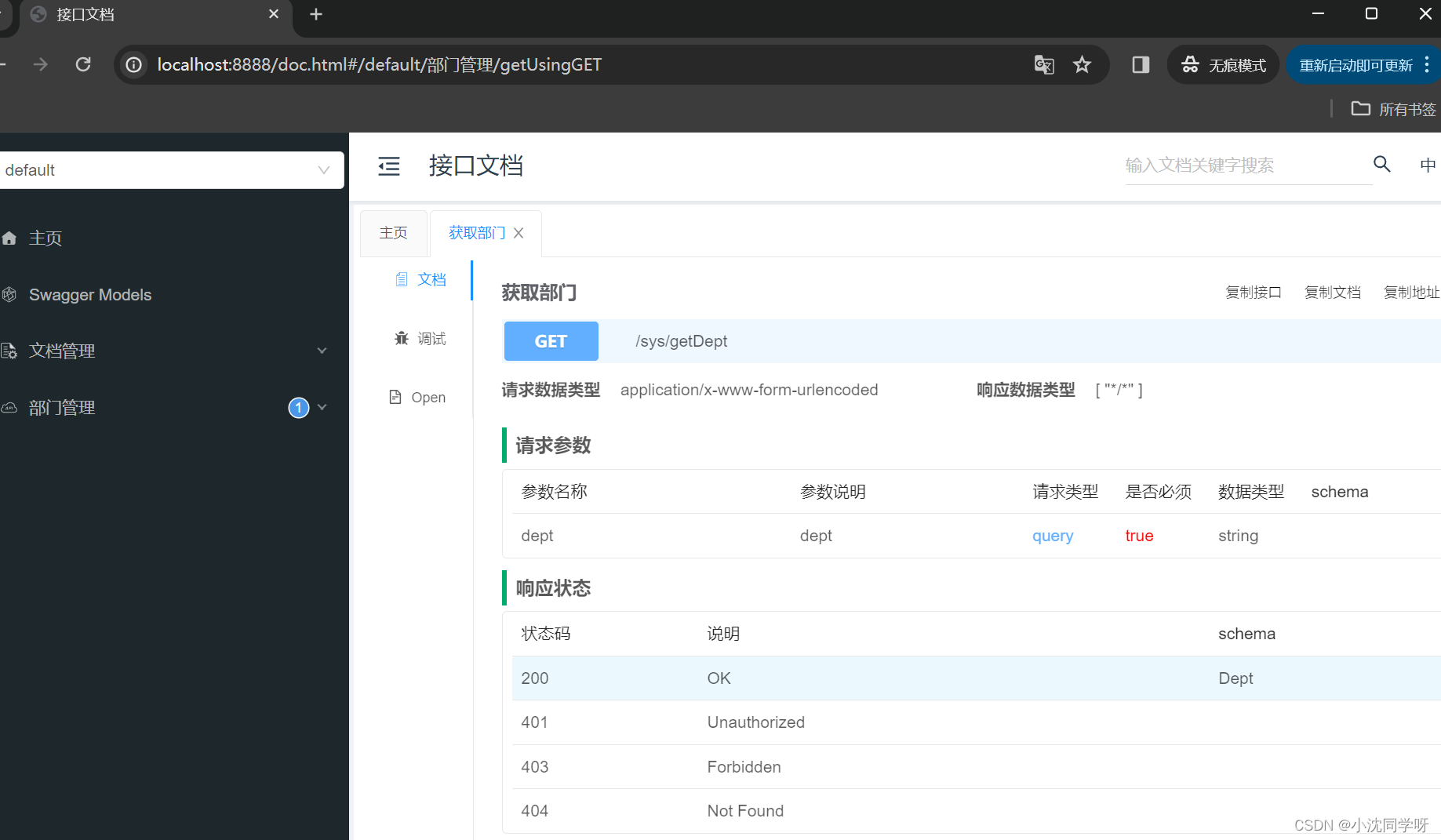
1. 介绍一下ABTest的步骤
ABtest就是为了测试和验证模型/项目的效果,在app/pc端设计出多个版本,在同一时间维度下,分别用组成相同/相似的群组去随机访问这些版本,记录下群组的用户体验数据和业务数据,最后评估出最好的版本给予采用。
步骤:
1. 基于现状和期望,分析并提出假设
2. 设定目标制定方案
3. 设计与开发
4. 分配流量进行测试
5. 埋点采集数据
6. 实验后分析数据
7. 发布新版本/改进设计方案/调整流量继续测试
2. ABtest背后的理论支撑是什么?
中心极限定理:在样本量足够大的时候,可以认为样本的均值近似服从正态分布。
假设检验:假设检验是研究如何根据抽样后获得的样本来检查抽样前所作假设是否合理,A/B Test 从本质上来说是一个基于统计的假设检验过程,它首先对实验组和对照组的关系提出了某种假设,然后计算这两组数据的差异和确定该差异是否存在统计上的显著性,最后根据上述结果对假设做出判断。
假设检验的核心是证伪,所以原假设是统计者想要拒绝的假设,无显著差异我们也可以理解为:实验组和对照组的统计差异是由抽样误差引起的(误差服从正态分布)。
3. 如何分组才能更好地避免混淆呢?
- 利用用户的唯一标识的尾号或者其他标识进行分类,如按照尾号的奇数或者偶数将其分为两组。
- 用一个hash函数将用户的唯一标识进行hash取模,分桶。可以将用户均匀地分到若干个桶中,如分到100个或者1000个桶中,这样的好处就是可以进一步将用户打散,提高分组的效果。
当然,如果有多个分组并行进行的情况的话,要考虑独占域和分享域问题。(不同域之间的用户相互独立,交集为空)对于共享域,我们要进行分层。但是在分层中,下一层要将上一层的用户打散,确保下一层用户的随机性。
4. 样本量大小如何?
理论上,我们想要样本量越多的越好,因为这样可以避免第二类错误。随着样本量增加,power=1-β也在增大,一般到80%,这里我们可以算出一个最小样本量,但理论上样本量还是越大越好。
实际上,样本量越少越好,这是因为
-
流量有限:小公司就这么点流量,还要精打细算做各种测试,开发各种产品。在保证样本分组不重叠的基础上,产品开发速度会大大降低。
-
试错成本大:如果拿50%的用户做实验,一周以后发现总收入下降了20%,这样一周时间的实验给公司造成了10%的损失,这样损失未免有点大。
5. 两类错误是什么?
-
弃真:实验组和对照组没有显著差异,但我们接受了方案推了全量。减少这种错误的方法就是提高显著性水平,比如 p 值小于 0.05 才算显著,而不是小于 0.1,显著性水平是人为给定的犯一类错误的可以接受的上限( p p p值为犯 I 类错误的概率 α \alpha α )。
-
存伪:实验组和对照组有显著差异,但我们没有接受方案。
II 类错误和统计功效 (power) 有关,统计功效可以简单理解为真理能被发现的可能性。统计功效 为: 1 − β 1-\beta 1−β ,而 β \beta β为犯第二类错误的概率。影响统计功效的因素有很多,主要的有三个:统计量、样本量和 I 类错误的概率 α \alpha α 。
6. 埋点&暗中观察
当我们确定了需要分析的具体指标之后,就需要我们进行埋点设计,把相关的用户行为收集起来,供后续的流程进行数据分析,从而得出实验结论。
对于 ABTest我们需要知道当前用户是处于对照组还是实验组,所以埋点中这些参数必须要有。埋点完了就是收集实验数据了(暗中观察),主要看以下两个方面:
-
观察样本量是否符合预期,比如实验组和对照组分流的流量是否均匀,正常情况下,分流的数据不会相差太大,如果相差太大,就要分析哪里出现了问题。
-
观察用户的行为埋点是否埋的正确,很多次实验之后,我们发现埋点埋错了。
7. 如果一个人有多个账号,分别做不同用途,abtest的时候怎么分组才最合理呢?
我们对这类人的分类是,看的不是他是谁,而是他做了什么。按照我们对行业的分类,行为不同的话就是两类人,和身份证是不是同一个无关。我们要聚合的是有相同行为特征的账户,而不是人。