一、插入排序
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了,因为只要打过扑克牌的人都应该能够秒懂。插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
1.实现思路:
1.将第一待排序序列第一个元素看做一个有序序列。
2.把第二个元素到最后一个元素当成是未排序序列。
3.从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
动图演示:
动图来源:1.3 插入排序 | 菜鸟教程 (runoob.com)
代码实现:
void InsertSort(int* a, int n)
{for (int i = 0; i < n-1; i++){// [0, end] end+1int end = i;int tmp = a[end + 1];while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end];--end;}else{break;}}a[end + 1] = tmp;}
}二、希尔排序
1.来源:
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因DL.Shell于1959年提出而得名。希尔排序是记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
————《百度文库》
2.基本思想:
先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。
因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率上比前两种方法有较大提高。
3.实现方式:
① 先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。
② 所有距离为d1的倍数的记录放在同一个组中,在各组内进行直接插入排序。
③ 取第二个增量d2小于d1重复上述的分组和排序,直至所取的增量dt=1(dt小于dt-l小于…小于d2小于d1),即所有记录放在同一组中进行直接插入排序为止。
4.希尔排序的特性总结:
1. 希尔排序是对直接插入排序的优化。2. 当 gap > 1 时都是预排序,目的是让数组更接近于有序。当 gap == 1 时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。3. 希尔排序的时间复杂度不好计算,因为 gap 的取值方法很多,导致很难去计算,因此在好些树中给出的希尔排序的时间复杂度都不固定:《数据结构 (C 语言版 ) 》 --- 严蔚敏
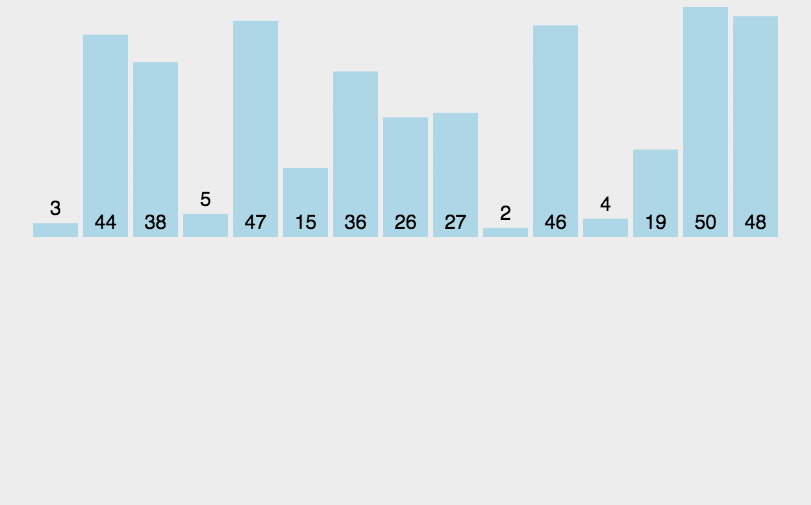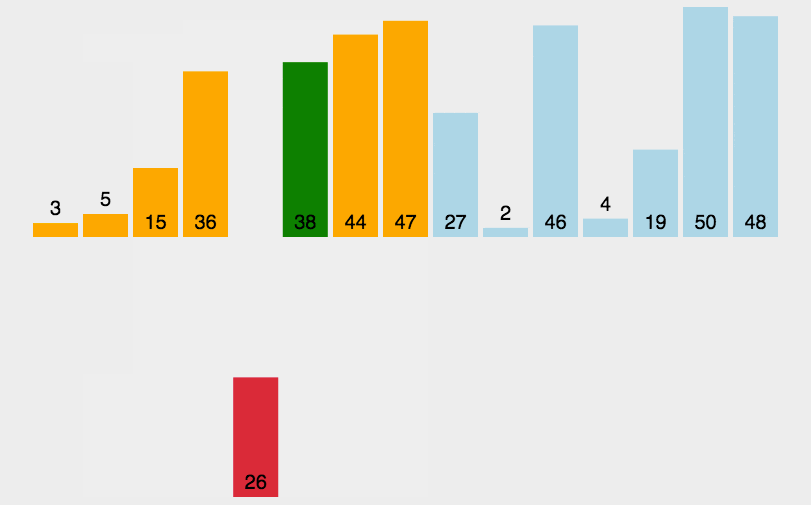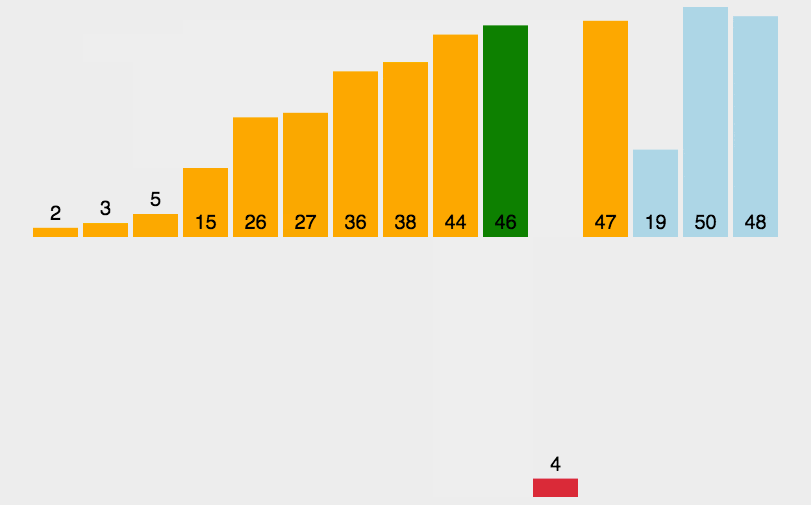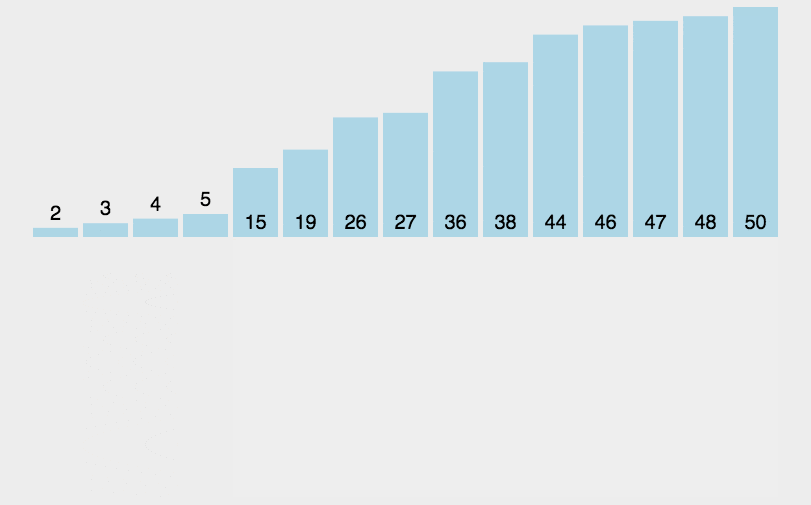
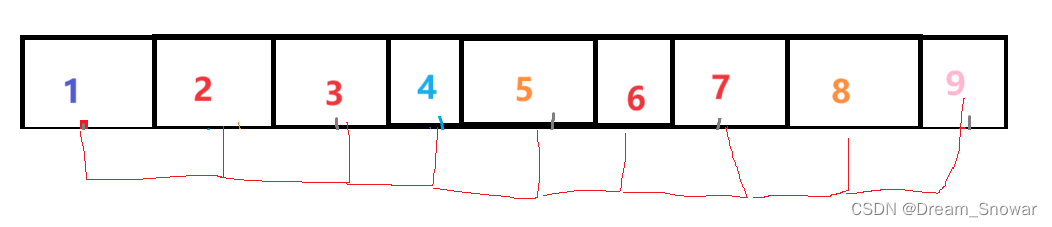
由于动图没找到,这里我就画图描述一下吧,.
现在我们有如下数据:

我们先选
gap=8;
第一趟排序:

然后
gap=gap/3+1--->gap=3
第二趟排序:

接着
gap=gap/3+1--->gap=2
第三趟排序:

最后
gap=gap/3+1--->gap=1
代码实现:
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap/3 + 1;for (int i = 0; i < n - gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}