B树的一种变种形式,B+树上的叶子结点存储关键字以及相应记录的地址,同等存储空间下比B-Tree存储更多Key。非叶子节点不对关键字记录的指针进行保存,只进行数据索引 , 树的层级会更少 , 所有叶子节点都在同一层, 叶子节点的关键字从小到大有序排列,叶子节点之间用指针连接, 构成有序链表(稠密索引)。
B+树上每个非叶子节点之间是一个双向链表进行链接,而叶子节点中的数据都是使用单向链表链接。
检索特点
当索引部分某个结点的关键字与所查的关键字相等时,并不停止查找,继续沿着关键字的指针向下,每次查询必须到叶子节点才能真正获取到相关数据。B+Tree叶子节点相连接,对树的遍历就是只需要一次线性遍历叶子节点。由于叶子节点的数据是顺序排列,方便区间查找,在B+树完成范围查找、排序查找、分组查找、去重查找比B-Tree效率更高。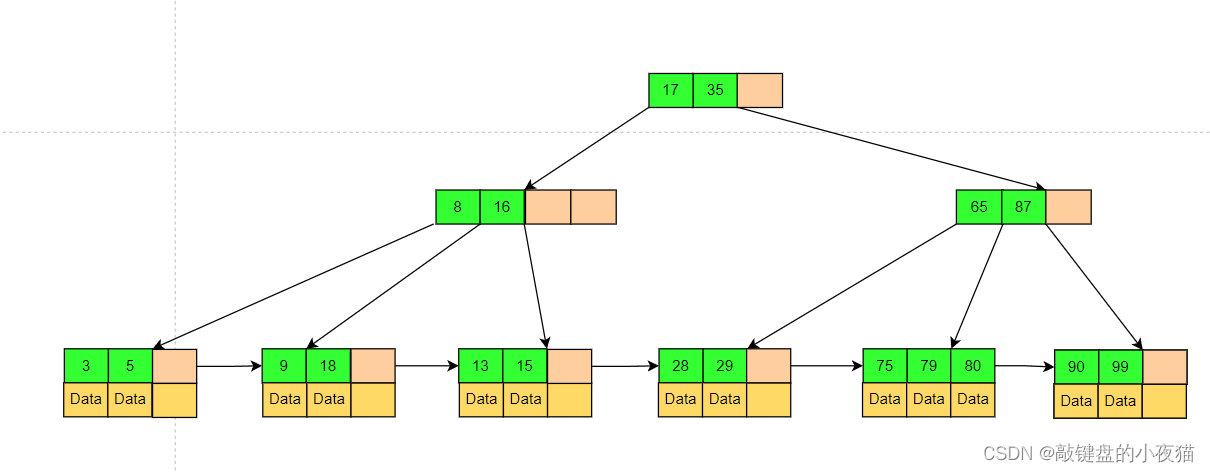
动画演示: B+ Tree Visualization
演示:M=5


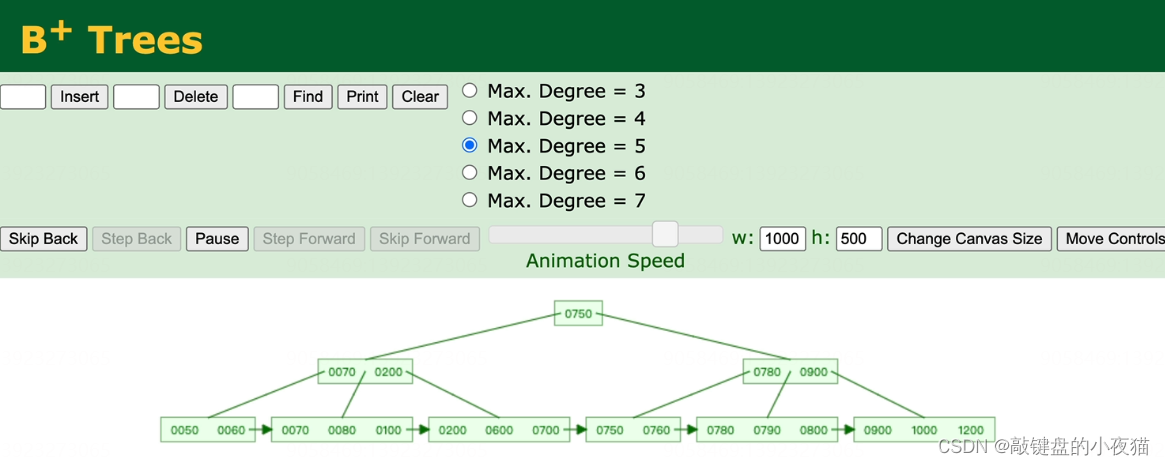
1)插入可以是中文或者是英文,对应会转为ASCII码 ;
2)插入第五个元素时,会将中间的元素往上提,并在中间保留一个元素在叶子节点,叶子节点间用指针相连;
B-Tree和B+树区别
两种树各有优缺点和应用场景:
1)B树和B+树的最大区别在于非叶子节点是否存储数据;
2)B+树非叶子节点只是当索引使用,同等空间下B+树存储更多key;
3)B树,非叶子节点和叶子节点都会存储数据,找到对应节点就有对应的数据;
4)B+树, 只有叶子节点才会存储数据,存储的数据都是在一行上,找到非叶子节点的key,还需要继续找到叶子节点才可以获取数据;
5)B树的节点包括了key-value,所以找到对应的key即可找到对应的value,不用在继续寻找;
Mysql索引底层剖析
在多数数据库的设计里面,会用B-Tree或B+Tree做索引提高查询效率
基于一张数据库的表数据进行查询(类似mysql的user表)
构建索引:id用做key,然后data是数据的存储地址
| 内存地址 | id | phone | name | Age |
|---|---|---|---|---|
| 0xFS | 212 | 13012341234 | 张三 | 34 |
| 0xER | 324 | 15725112361 | 李四 | 46 |
| 0x32 | 461 | 18612695656 | 王五 | 24 |
| 0x93 | 524 | 13109910002 | 赵六 | 29 |
| 0xAP | 689 | 13399811341 | 钱七 | 30 |
| 0xSQ | .... 1千万条数据 |
精确查找 id = 689 的数据
sql:select * from user where id = 689
1)未使用索引:自上而下查找数据,一行行遍历,5次才找到数据;
2)使用索引:ID建立主键索引(B+Tree结构),对应的数据存储数据的地址,2次找到数据,且数据量越多效果越明显;
根节点是常驻内存的,不需要进行IO操作;

查询ID=689时 ,IO从461才开始发生第一次IO,随之时524、689
范围查找 id>212和 id < 524的用户
sql:select * from user where id > 212 and id < 524
1)未使用索引:自上而下查找数据,一行行遍历;
2)使用索引:id建立主键索引(B+Tree结构),由于本身是有序链表,所以顺序查找即可;
举一反三
如果把相关数据都放到B+Tree叶子节点上,拿查询的时候直接一次性就可以把数据获取了。
以这个为例,我们展开讲讲Mysql中的InnoDB中的索引结构与MyISAM的索引结构区别
InnoDB引擎
表数据文件按B+Tree组织的,叶节点data域保存完整行数据, 树上的key就是主键, 以主键构建的B+树索引。
这种索引叫做聚集索引(聚簇索引 clustered index),聚簇索引一般为主键索引,而主键一个表中只能有一个,所以聚集索引一个表只能有一个聚簇索引叶子节点存储的是行数据,而非聚簇索引叶子节点存储的是聚簇索引(通常是主键 ID)

MyISAM引擎
索引文件和数据文件是分开的,索引结构的叶子节点放的是指向数据的主键(或者是地址)构建的B+树索引。
这种索引叫做非聚集索引、二级索引、辅助索引(非聚簇索引 nonclustered index),非聚集索引一个表可以存在多个。
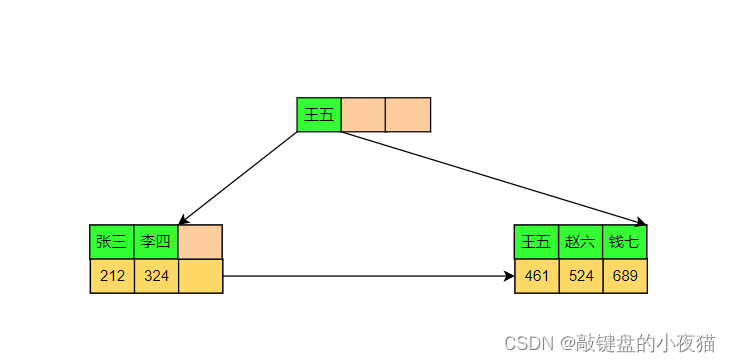
叶子节点中保存的不是实际数据,而是主键,获得主键值后去聚簇索引中获得数据行。
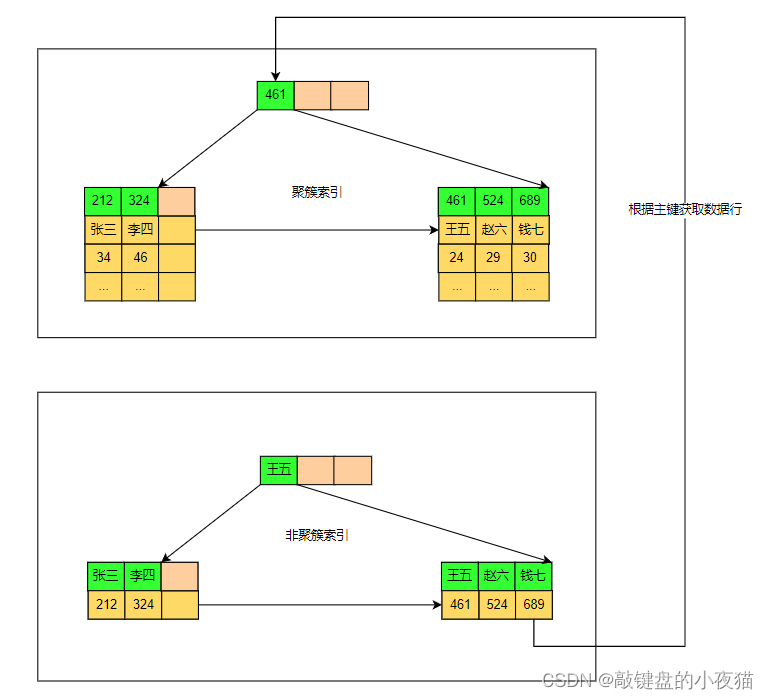
非聚簇索引的叶子节点上存储的并不是真正的行数据,而是主键 ID或记录的地址。当使用非聚簇索引进行查询时,会得到一个主键 ID,再使用主键 ID 去聚簇索引上找真正的行数据,把这个过程称之为回表查询,所以聚簇索引查询效率更高,而非聚簇索引需要进行回表查询,性能不如聚簇索引。







![Linux repo基本用法: 搭建自己的repo仓库[服务端]](https://img-blog.csdnimg.cn/direct/4ff0eb8bf537489dbb519f8e33bb06bb.png#pic_center)