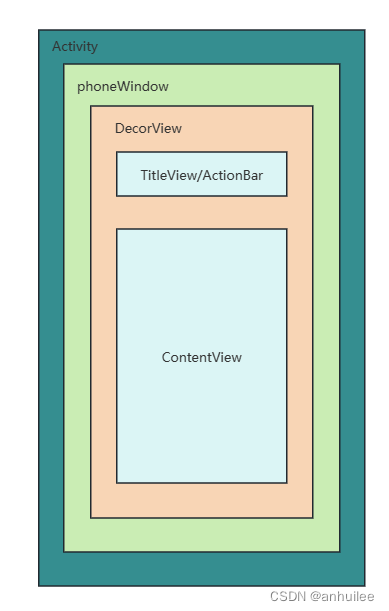
GraphTranslator: 将图模型与大型语言模型对齐,用于开放式任务。
将基于图的结构和信息与大型语言模型的能力整合在一起,以提高在涉及复杂和多样数据的任务中的性能。其目标是利用图模型和大型语言模型的优势,解决需要处理和理解结构化和非结构化数据的各种任务。对齐过程可能涉及调整图结构和基于语言的表示之间的表示和交互,以有效处理各个领域中的开放式任务。
视频地址:https://space.bilibili.com/431850986/channel/series
Git地址:https://datawhalechina.github.io/whale-paper/
目录

背景
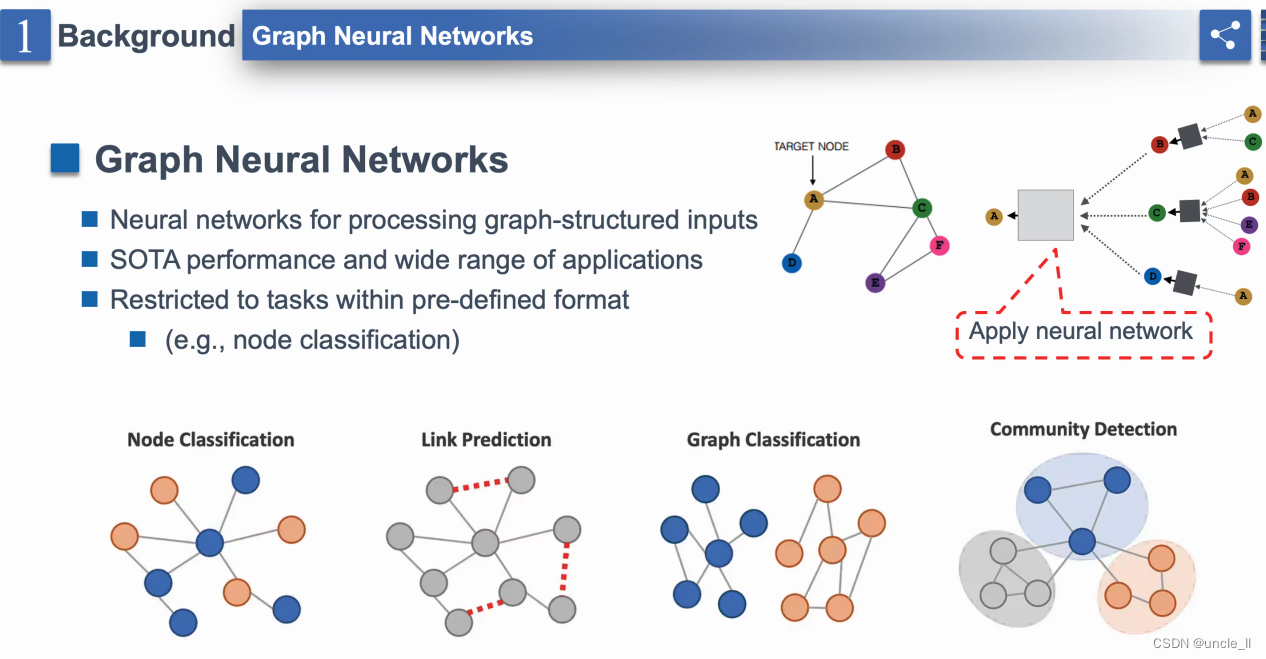
- “神经处理结构化输入” - 表明图神经网络(GNNs)旨在处理以图形式结构化的数据。
- “SOTA性能和广泛应用范围” - SOTA可能代表“最新技术”,表明GNN在各种应用中取得领先性能。
- “受限于预定义格式内的任务” - 后面跟着一个括号中的示例:“(例如,节点分类)”。
常见任务: - “节点分类” - 显示了一个小图,有节点(圆圈)和连接节点的边(线)。一个节点被突出显示,表示分类的目标节点。
- “图分类” - 描绘了两个不同结构的图,暗示了对整个图进行分类的任务,而不是对单个节点进行分类。
- “社区检测” - 显示了一个较大的图,节点被聚类,并用不同颜色标记。一个虚线红色框围绕着一个社区,表示在图中检测到一个社区。

- 基础模型
- 下游任务适配
- 在开域领域表现好
- 在特定领域不一定有小模型好,幻觉问题
- 大型语言模型的特点:
- “当参数数量达到一定规模时,模型参与度大”
- “展示出对开放式任务的强大能力”
- “由于产生幻觉和成本高昂,无法适应纯定义任务的真实自然语言指令”
动机
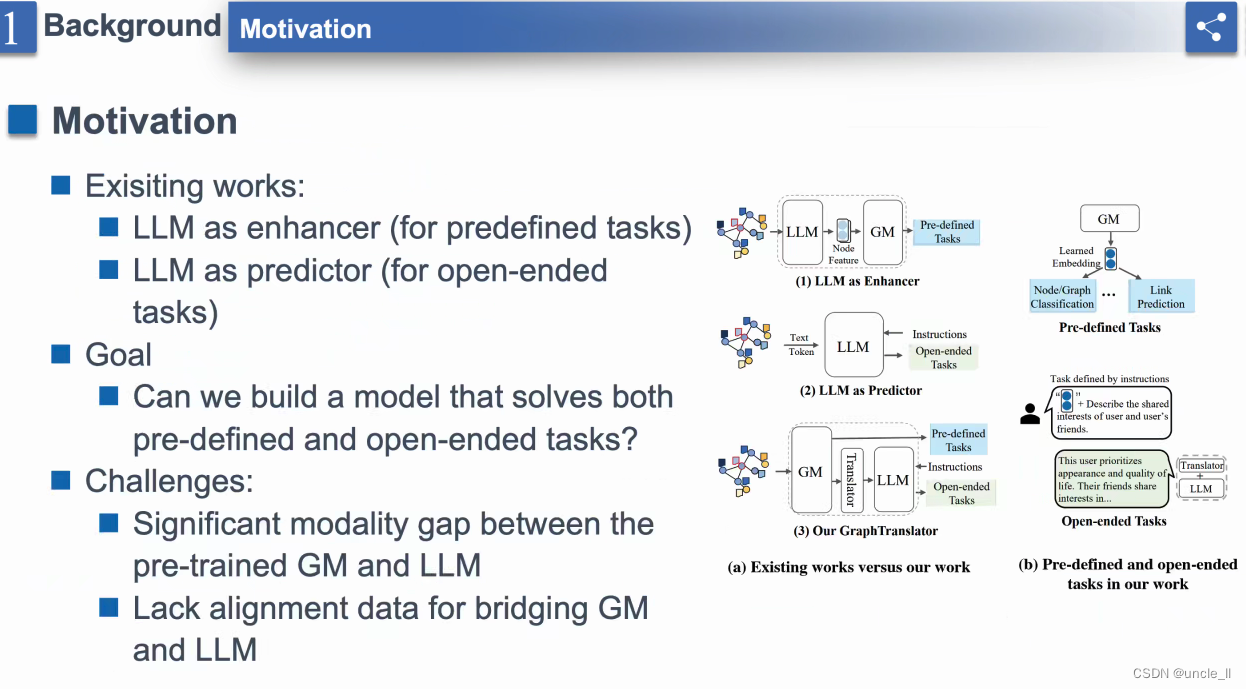
- 图数据送给大模型,是生成节点的embedding
- 现有工作:LLM作为增强器,LLM作为预测器
- “Goals”:建立一个既能解决预定义任务又能处理开放式任务的模型的目标。有一个文本框强调了创造具有这种双重能力的模型的愿望。
- “Challenges”:“预训练GM和LLM之间的显著模态差距”和“缺乏用于连接GM和LLM的对齐数据”。这表明由于模态之间的差异以及缺乏有效对齐数据,整合图形模型和语言模型存在困难。
model
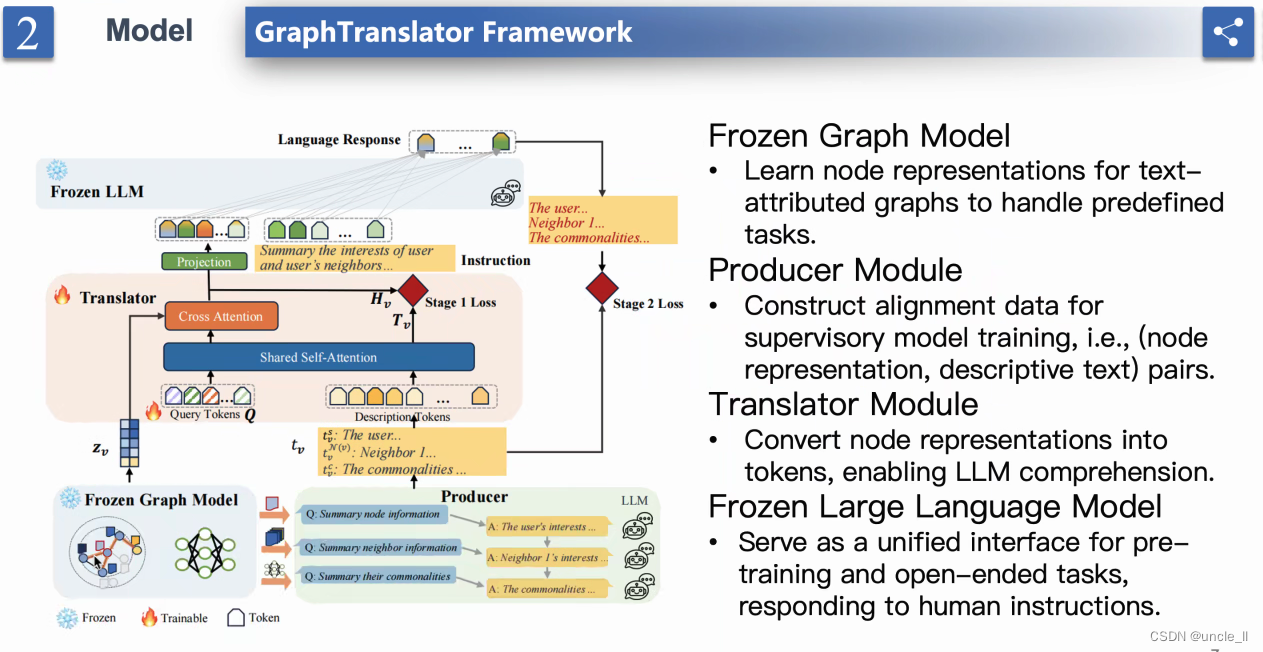
- 四个模块
- 学习文本属性图模型的节点表示
- 使用GraphTranslator处理预定义任务
- 构建、对齐、连接(节点表示、描述性文本)对。
- 作为预定义、后续和开放式任务的统一接口,根据人类指令进行训练。

- “Frozen Graph Model”(冻结图模型)
- “Text-Attributed Graph”(文本属性图),后面跟着一个关于图G的数学符号描述,TAG G = (V, A, {S_0}uSEV)。BoW代表词袋模型
- 一个节点的特征向量与其邻居的特征向量进行聚合,然后通过函数sigma和权重矩阵W进行转换

- 生产者模块”(Construct Model: Producer Module)
- 节点对齐数据:描述了节点对齐数据包括节点特征、邻居信息以及它们与时间戳的组合
- 使用“思维链(CoT)引导 GPT 逐步生成高质量描述”
- 流程图,包含三个主要组件标记为 A、B 和 C。每个组件之间通过箭头连接,表示信息流或处理步骤。这些组件描述如下:
A. 源节点信息
B. 摘要邻居信息
C. 聚合器
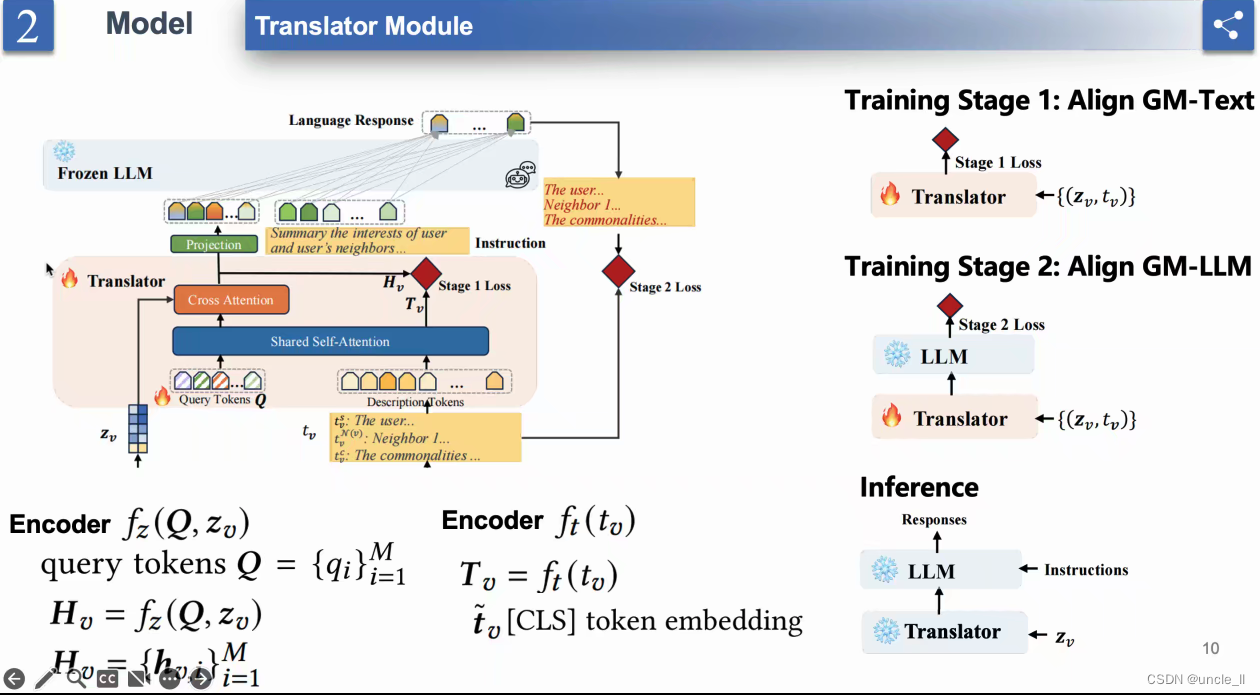
- “翻译模块”(Translator Module)的模型
- 分两个阶段
- 翻译模块的架构,分为两个训练阶段:
- 训练阶段1:对齐 GM-Text
- 训练阶段2:对齐 GM-LM
- 共享自注意力: 用于在两个编码器之间对齐或相关信息的机制
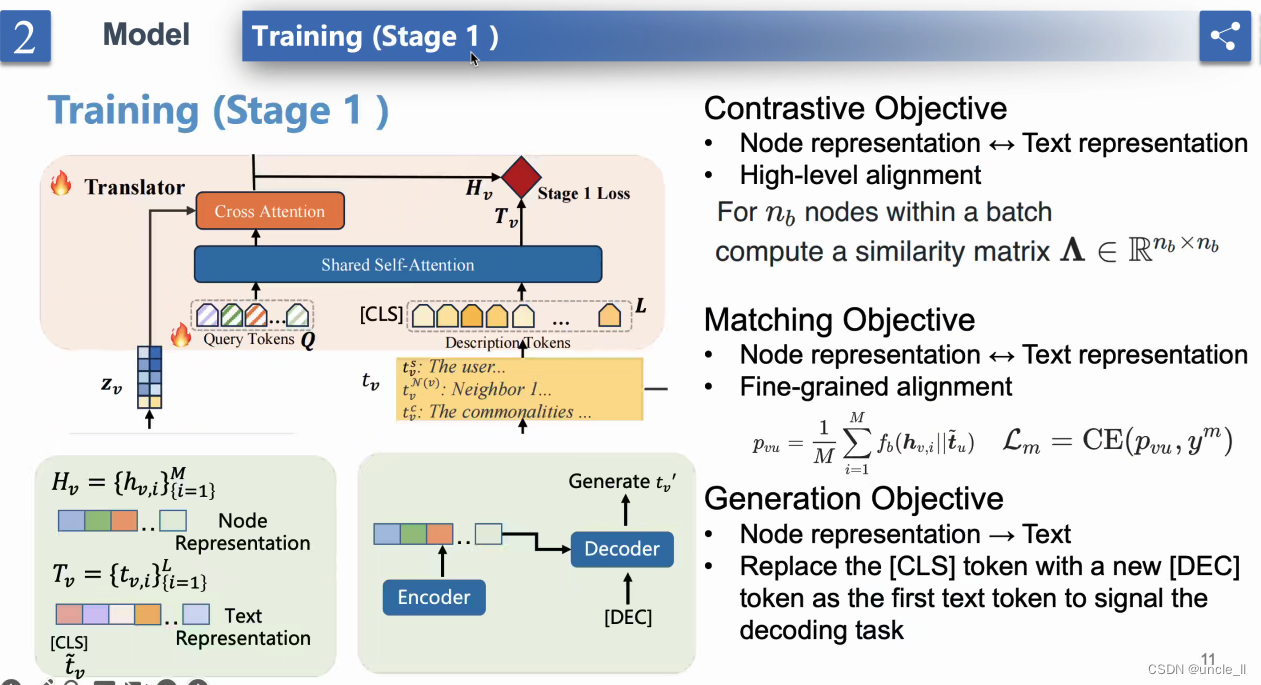
- 阶段1:对比学习loss
- 翻译器(Translator)
共享注意力(Shared Attention) - 查询标记(Query Tokens)和描述性标记(Descriptive Tokens)
- 交叉注意力(Cross Attention)
- 模型训练(阶段1)构建: 右侧包括三个项目符号,每个描述一个不同的目标:
- 对比目标(Contrastive Objective): 包括节点表示对齐和在批次内计算相似性。
- 节点匹配目标(Node Matching Objective): 包括将标记与文本表示匹配和对齐。
- 节点表示目标(Node Representation Objective): 包括生成,特别是用特殊标记替换第一个标记作为解码器解决的任务。
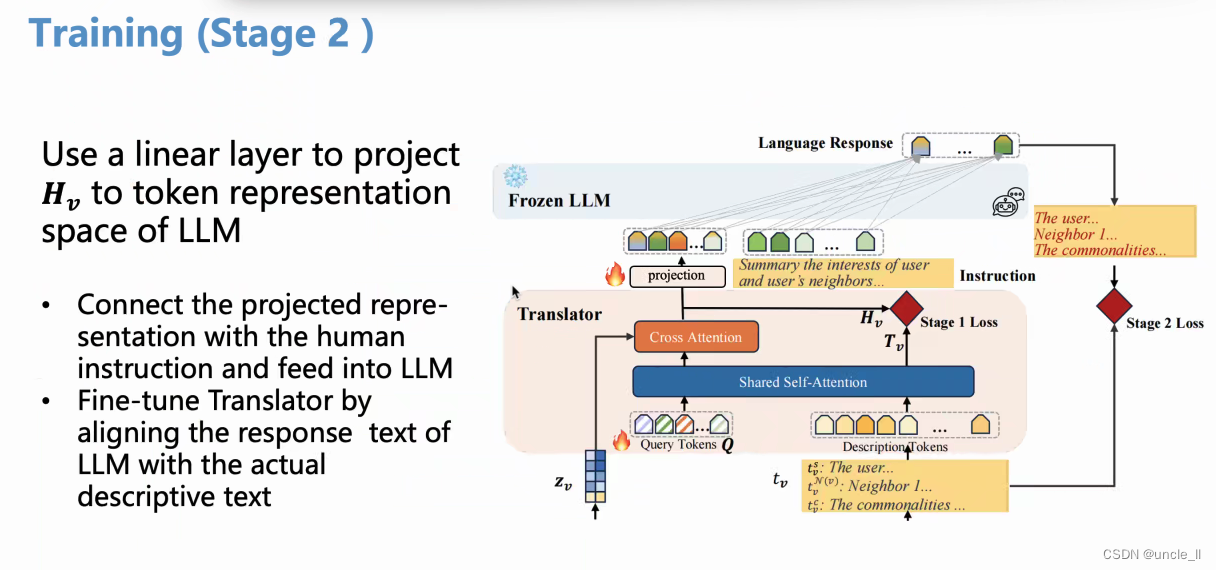
- 阶段2:过一个投影层,总结用户和邻接节点的信息去生成response
- 图表展示了一个机器学习模型的架构,包括以下组件和步骤:
- H_stage1: 这个组件代表第一阶段训练的输出。
- Projector: 一个线性层,用于将H_stage1投影到LLM(大型语言模型)的标记表示空间。
- Cross Attention和Shared Self-Attention: 这两个组件接收投影输出,并可能涉及在模型中对不同部分进行关注和交互。
- Language Response和Descriptive Actions: 这些组件可能与模型的输出和相应的描述性动作或指令有关。
- 使用线性层将H_stage1投影到LLM的标记表示空间。
- 将投影表示与人类指令连接,并通过对齐描述性文本的翻译器,将其输入到微调响应文本中。
实验
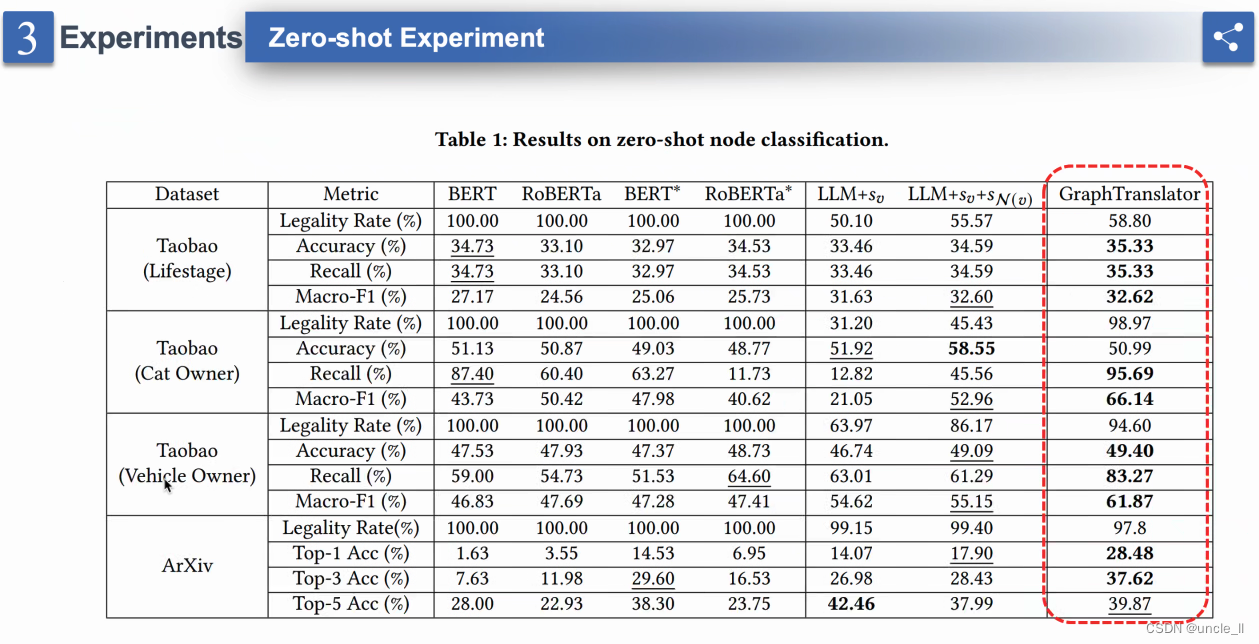
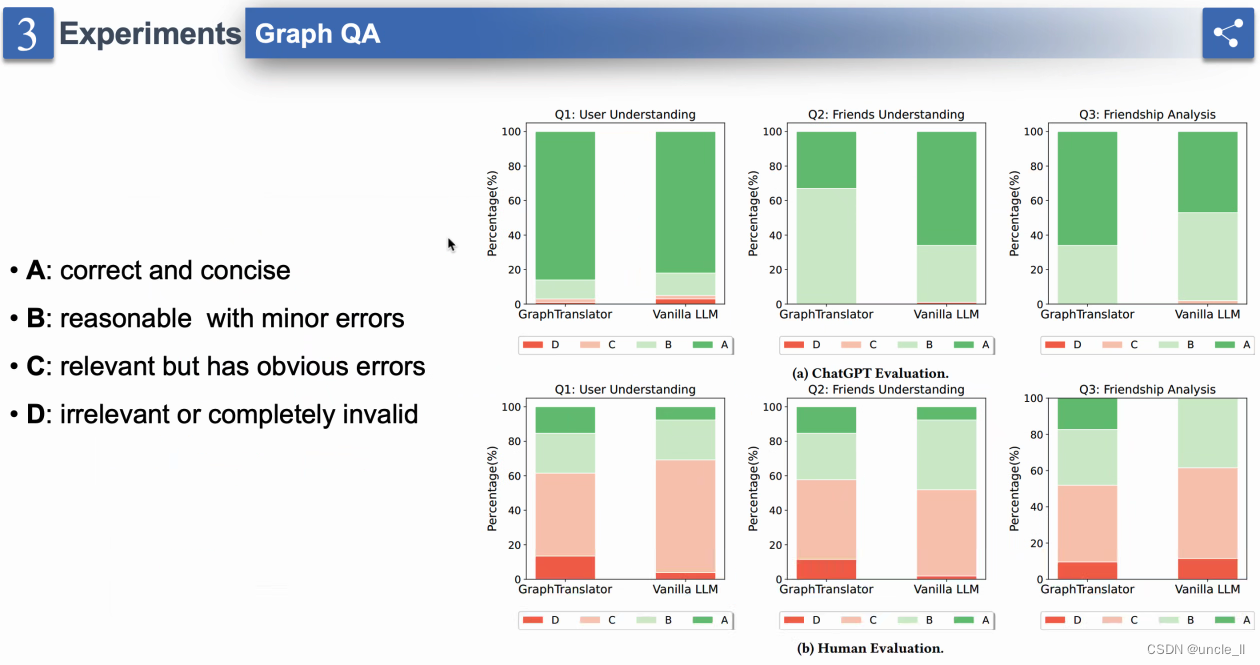
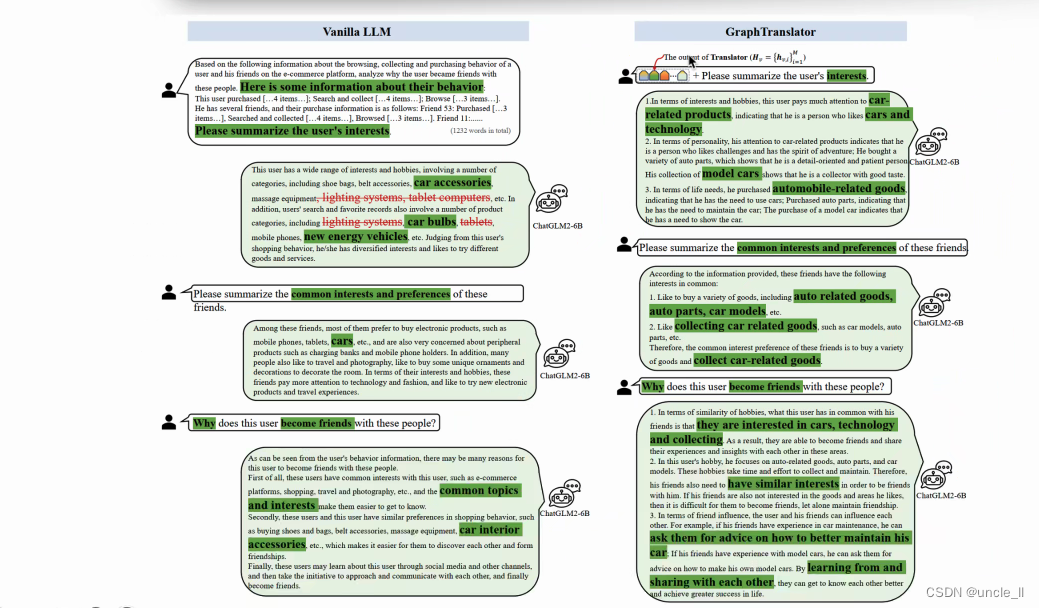
结论

综述文章

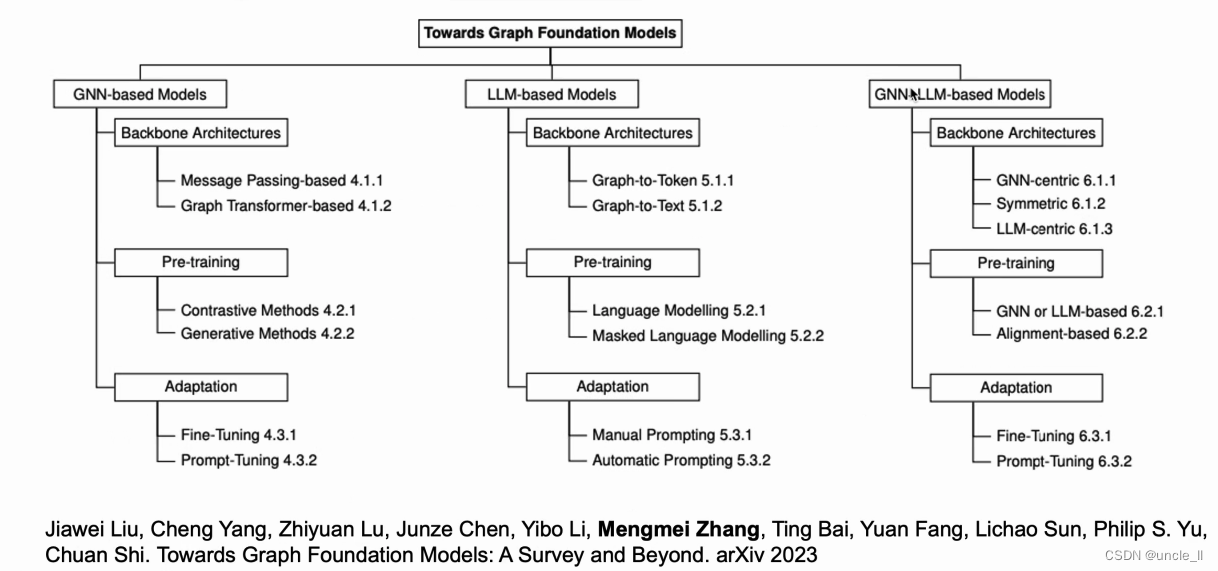
“Towards Graph Foundation Models: A Survey and Beyond(走向图基础模型:调查与未来)”摘要讨论了基础模型在各个领域的重要性,特别是在自然语言处理和其他人工智能应用中。它提到这些模型由于其迁移学习能力在多个领域取得了显著成功。该论文旨在探索图基础模型的潜力以及它们在各种下游任务中的适应性。它还讨论了图学习范式同质化能力的挑战,以及需要多样化和去中心化方法的必要性。
作者提出了通过大数据和学习方法上的预训练图进行转变性转变。摘要指出,该论文将对现有关于图基础模型的工作进行系统回顾,包括它们的分类、使用的技术和框架,以及对该领域未来的影响。它还提到该论文将讨论开放挑战、新方向以及在这一领域跨学科研究的重要性。