maixpy笔记
Something
- 上下拉。应该就是强制高、低电平,可以避免不确定的状态。
- 模型区没有文件系统,模型之间烧录在指定地址。
- 文件系统可以有效帮助我们管理存储介质,例如磨损均衡。
- 理论上只要单层使用内存不超过 2MB, 整体模型可以无限大,只不过要牺牲一点运算速度。
- SRAM与Flash 。其中SRAM掉电易失,容量小,而速度快。
nnc-0.1算子支持
| layer | parameters |
|---|---|
| Conv2d | kernel={3x3,1x1} stride={1,2} padding=same * |
| DepthwiseConv2d | kernel={3x3,1x1} stride={1,2} padding=same * |
| FullyConnected | 全连接操作。将输入张量拉伸成一个一维向量,然后与权重矩阵进行点积,最后加上偏差向量。 |
| Add | 按位加法操作。将两个输入张量的相应元素相加。 |
| MaxPool2d | 二维最大池化操作。对输入张量的每个子区域执行最大值池化,并返回包含每个子区域的最大值的新张量。 |
| AveragePool2d | 二维平均池化操作。对输入张量的每个子区域执行平均值池化,并返回包含每个子区域的平均值的新张量。 |
| GlobalAveragePool2d | 全局平均池化操作。对输入张量的所有元素求平均值,并返回一个形状为 (1, 1, C) 的张量,其中 C是输入张量的通道数。 |
| BatchNormalization | 批量归一化操作。在训练时,对于输入张量的每个通道计算均值和方差,然后使用这些值对输入进行归一化;在预测时,使用固定的均值和方差对输入进行归一化。 |
| BiasAdd | 将偏差向量加到输入张量上。 |
| Relu | 修正线性单元 (ReLU) 激活函数。将输入张量的所有小于 0 的元素设为 0。 |
| Relu6 | 修正线性单元 (ReLU6) 激活函数。将输入张量的所有小于 0 的元素设为 0,将所有大于 6 的元素设为 6。 |
| LeakyRelu | 带有小正斜率的修正线性单元 (Leaky ReLU) 激活函数。将输入张量的所有小于 0 的元素乘以一个小于 1 的正斜率。 |
| Concatenation | 按给定轴连接多个张量。 |
| L2Normalization | 二范数归一化操作。对输入张量的所有元素求二范数,然后将输入张量的所有元素除以二范数。 |
| Sigmoid | 对输入张量的所有元素应用 Sigmoid 函数。 |
| Softmax | 对输入张量的所有元素应用 Softmax 函数。 |
| Flatten | 展平张量。将输入张量拉伸成一个一维向量。 |
| ResizeNearestNeighbor | 使用最近邻插值法对输入张量进行重新调整大小。 |
可能用到的API
-
image.to_grayscale([copy=False])将图像转换为灰度图像。
Commands
-
os.listdir(),查看当前目录下的文件 -
os.chdir()切换当前目录到文件的目录,比如os.chdir("/flash") -
os.remove(path)删除文件 -
ncc compile mnist_float.tflite mnist_float.kmodel -i tflite -o kmodel -t k210 --inference-type float使用nncase的0.2版本,将.tflite文件转为.kmodel格式
-
ncc -i tflite -o k210model --inference-type float mnist_float.tflite mnist.kmodel使用nncase的0.1版本进行模型格式转换
-
pip show <包名>用pip查看某个已安装包的信息 -
conda search <包名>用conda查看某个包的可安装版本 -
nvidia-smi查看电脑的CUDA版本
Skills
1、使用IDE将文件保存到板子
Tool中使用发送文件保存为同名文件;Tool中使用保存为boot.py,下次板子开机上电时自动执行。
2、执行板子上的文件
例如,板子上有个文件名为hello.py,下面的代码将执行它。
with open("hello.py") as f:exec(f.read())
3、实现开机自启
开机会自动先执行boot.py,然后执行main.py(如果检测到SD卡则执行SD卡里的)。
Problems
-
“对同一个外设或者引脚重复映射”是什么意思?
-
我需要做板级配置吗?
-
很奇怪,为什么只有我手机充电的那根数据线可以连的上板子?
-
仍然不太清楚“外设”和“引脚”的关系。
-
一个人读文档发现不一致的地方时是真的难受,而且也找不着解释。例如我使用 k f l a s h _ g u i kflash\_gui kflash_gui烧录模型时,就没有设置烧录地址的地方,而文档中第一张图里面有地址,后面的图又没有地址了。
-
用IDE运行官方的人脸识别时,一段时间后就会报错,据说是因为运行内存不够,可以用终端试试。但IDE里的终端我没用明白,我嵌在代码里的print语句正常输出,说明程序确实运行了,但却没有显示画面。而且,为什么会运行一段时间后才显示内存不足呢?是否和脸的数量有关?
-
RGB565是什么?
-
摄像头水平镜像是干什么?
-
import time导入的包和文档中的utime是一样的吗? -
这一段代码是不是不能脱离
try-finally结构?因为前面是while(True)? -
为什么插上板子时,我电脑上会增加两个串口COM5和COM6,但是只有COM5能用?那COM6是什么?
-
如何删除板子上的文件呢?
-
下载
.kmodel在0x300000位置后,就连不上板子了,不知道是不是把固件挤掉了。而重新下载.bin固件时,会下载失败。解决:将开发板设置从“Sipeed Mainxduino"改为“自动选择”后,就好了。但是我记得我之前都是用的“Sipeed Mainxduino"选项。
12-13
试试运行一个maixpy官方提供的模型。
使用MaixHub训练的模型可以在开发板上正常运行,不错不错。在IDE上时只能运行一小会儿就会报错,使用串口终端时又无法显示图像。后来王鹤野建议说打印直接打印结果,我尝试发现确实可以。连串口时板子是在运行的,仅仅是没有图像显示而已。这次尝试的是一个击败K的小模型,训练时验证集精度达到了79.5%,但在尝试中它对盘装菜识别效果较好,其它的尝试识别都失败了。
后续可以进行的尝试:
- 在Maixhub上训练一个更大的模型,看在串口终端连接下它可以支持多大模型的运行。
- 将Paddle的模型转换为
.kmodel的格式。但是Paddle模型保存的时候都是两个文件,一个参数文件一个模型文件,可以转成一个.kmodel文件吗?
12-27
尝试了将 paddle 框架训练的模型使用 paddle2onnx 转换为 onnx 格式,然后使用 nncase 转换为 kmodel 格式。
但是得到的 kmodel 模型无法使用。在载入模型的那一步 kpu.load(model_addr) 就会直接结束,而且连板子和maixpy IDE的连接都会断开。
12-28
仍然是转换出的 kmodel 无法在板子上加载的问题。据我目前了解,可能是它已经停止对 nncase 转换工具的支持了。参考:【K210踩坑】pytorch模型转kmodel,Dock上使用。(最终未实现) 。
真的烦,别人做什么我就只能用什么,为什么我不会自己写一个模型转换工具呢?
12-29
使用nncase v0.2.0转出的模型需要手动设置输出层形状。不知道是不是我使用方法不对,我的部分代码如下:
model_addr = "/flash/iris.kmodel"
task = kpu.load(model_addr)
success = kpu.set_outputs(task, 0, 12, 1, 1)
print('success: ', success)
但它总是显示:
w*h*ch!=12
[MAIXPY]kpu: set_outputs arg value error: w,c,ch size not match output size
success: False
可nncase v0.1.0转出的iris.kmodel的输出就是:
{"fmap": "data"=0x80380e70, "size"=12, "index": 1, "w": 12, "h": 1, "ch": 1, "typecode": f}
不知道出了什么问题,那我干脆就用v0.1.0版本就好了?
12-31
在尝试使用nncase的0.1和0.2对kmodel进行转换时都失败了,它们都不支持SHAPE操作。总体0.2版本的算子支持比0.1版本要丰富许多,比如0.2可以支持Reshape操作。
删除含有SHAPE操作的层后,转换又失败了。
- 0.1版猜测是不支持我在tensorflow lite中量化后的得到的unit8参数格式。
- 0.2版则显示
Fatal: Invalid tensor type,可以参考Cannot compile .tflite model (Fatal: Invalid tensor type) · Issue #420 · kendryte/nncase (github.com) 。
当我取消tensorflow lite中的量化后,
-
0.1版仍然失败,据chatGPT所说,是因为转换器无法理解模型文件中的某些内容,我没有继续探究这个问题。
1-4对比文档发现,应该是不支持Reshape算子导致。
-
0.2版成功得到了
.kmodel的模型。
现在,让我们尝试将刚刚得到的模型载入板子。
好家伙,使用IDE传文件又传不进去了,一直显示发送并保存中,请等待... 。此时IDE就一直卡在传送那里,无法断开与板子的连接,却可以打开串口终端;将IDE关闭后,依然有程序在后台运行。
好像是特定文件传不进去,我尝试传另一个 .kmodel 文件时成功了。模型文件从Colab训练后下载后得到,Build a handwritten digit classifier app with TensorFlow Lite 。
- 改用kflash_gui可以成功烧录进板子。
终于成了!一个手写数字识别的模型成功在板子上被加载,并正常产生了输出。
-
关于报错
kpu:check img format err!,看很多帖子都说分辨率不正确。在串口终端运行文件时多了一条报错[MAIXPY]kpu: pix_ai is NULL,查了帖子后发现是内存中图像的修改与kpu中图像的修改不会自动同步的问题,需要每次修改图像后手动同步:<img>.pix_to_ai(),记得将<img>替换为自己图像变量的变量名。参考:why pix_to_ai still return none? · Issue #264 · sipeed/MaixPy (github.com) 。
-
关于
kpu.set_outputs()总是失败。是啊,是要设置outputs,我总莫名想象成了inputs,制度第n次看到w*h*ch!=40之类的报错提示与输入的形状风牛马不相及(输入是分辨率为28*28的图像),我才突然恍然大悟。
1-1
关于模型部署,MaixPy文档的这一部分中可能有些有用的参考:部署模型到 Maix-I(M1) K210 系列开发板 - Sipeed Wiki 。
- 实际用数字图片进行测试时,手写数字识别的模型无法产生正确的输出。
猜测:输入需要进行预处理。训练时使用了img = img / 255.0 ,但是在Maixpy中我不知道如何达成这一步操作。
我尝试了 image.div() 接口,但发现 /255 时就相当于数学中 /1 ,/125 就相当于数学中 /0.5 这种。也就是说,我无法使用这个接口让图像中的像素值变小。
接着我使用了如下代码进行测试:
code:10图测试
import sensor, lcd, image
import KPU as kpu# 测试图像列表
img_names = ['num0', 'num1', 'num2', 'num3', 'num4', 'num5', 'num6', 'num7', 'num8', 'num9']# 载入模型
model_addr = 0x300000
task = kpu.load(model_addr)# 批量测试
for i in range(10):img = image.Image("/flash/" + img_names[i] + ".jpg")img = img.resize(28, 28)img = img.to_grayscale(copy=False)img.pix_to_ai()success = kpu.set_outputs(task, 0, 1, 1, 10)fmap = kpu.forward(task, img)plist=fmap[:]pmax=max(plist)max_index=plist.index(pmax)print('\ni = ', i)print(plist)print(max_index)
对于用于测试的10张图片,输出的 plist 都是:
(3.402823e+38, -3.402823e+38, 3.402823e+38, -3.402823e+38, 3.402823e+38, 3.402823e+38, -3.402823e+38, 3.402823e+38, 3.402823e+38, 3.402823e+38)
很容易发现它只有两个值:3.402823e+38 和 -3.402823e+38,看起来像是溢出了。是不是没有预处理的原因呢?
-
想对image对象进行
/255的预处理,结果发现它没有小数,可以使用image.morph()对每个像素进行除法操作,但是得到的结果只能是0~255。 -
发现列表和元组都支持小数和除法操作。
有没有什么方便的办法将图像转换为列表或元组呢?运行模型的时候是否支持使用列表或元组作为输入?转换速度如何?
-
发现
fmap = kpu.forward(task, img)中 img 可以是一维的列表。 -
测试10张手写数字的图片,模型都正确预测。哦耶!
下面的代码实现了对手写数字图片文件的预测:
code:正确预测
import sensor, image, time
import KPU as kpudef to_list_1(img):return [x/255 for x in img[:]]# 载入图片
img = image.Image("/flash/num0.jpg")
img = img.resize(28, 28)
img = img.to_grayscale(copy=False)
print()
print(img)
img = to_list_1(img)
print(img[:10])# 载入模型
model_addr = 0x300000
task = kpu.load(model_addr)# 推理
success = kpu.set_outputs(task, 0, 1, 1, 10)
print(success)
fmap = kpu.forward(task, img)
print(fmap)# 处理模型输出
plist=fmap[:]
pmax=max(plist)
max_index=plist.index(pmax)
print(plist)
print(max_index)print()
-
通过板子摄像头识别的效果要稍差一些,但是通常还是可以产生正确的输出;使用的是mnist测试集中的图片。
-
对于自己手写的数字,效果比较糟糕。
-
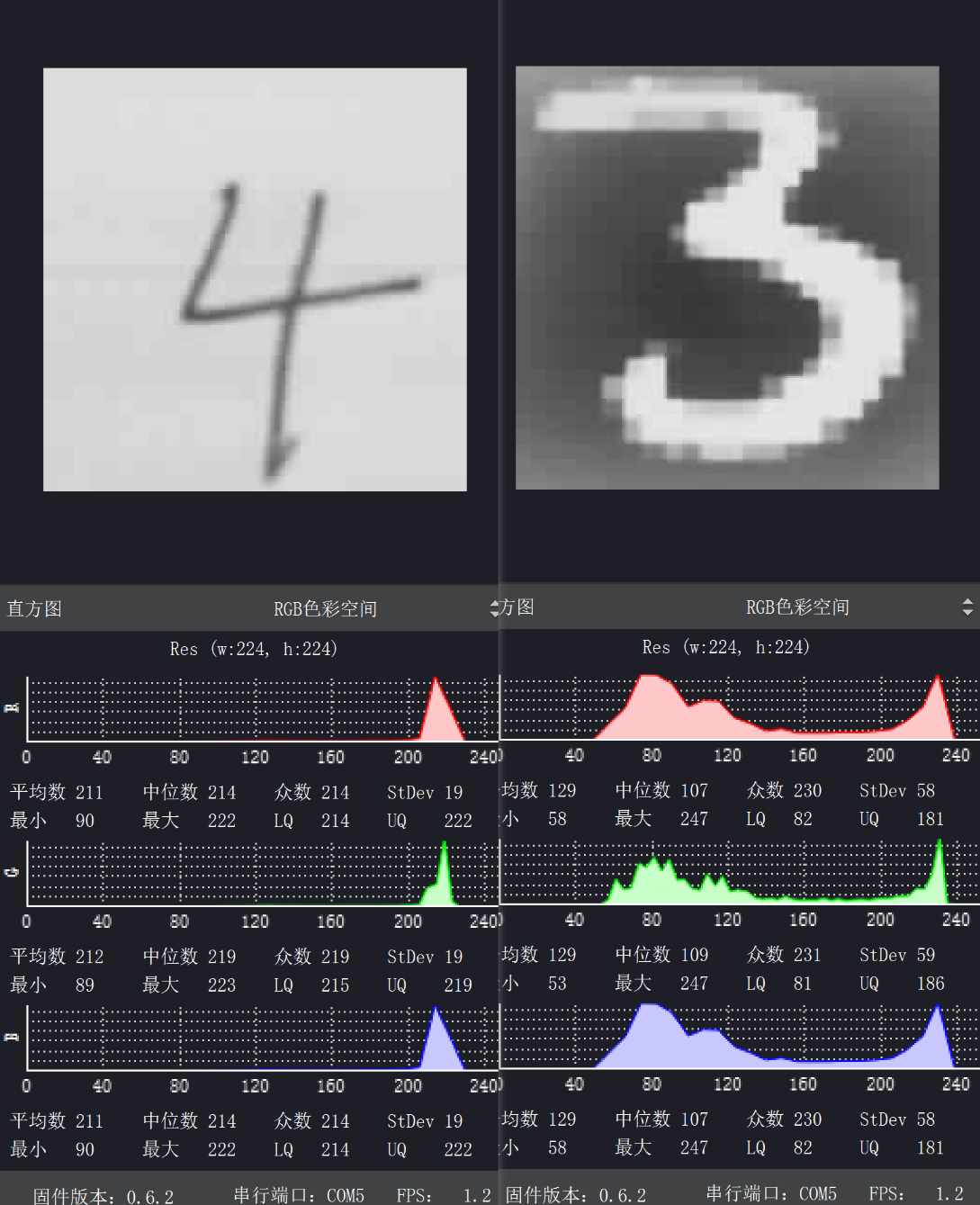
拖动、缩放图片,可能导致预测结果变化。
猜测:训练集中的数据场景比较单一,又没有经过数据增强。
可以发现两种情况下直方图的差异较大,左为自己手写,右为mnist数据集中的图片。
目前问题:对一张图片的预测时间太长,例如在手写数字识别的例子中为0.7秒。
1-3
尝试将float参数类型的mnist分类模型使用nncase-0.2量化为uint8类型,成功。
目的:提升推理速度。nncase文档中提到使用uint8可以获得k210的kpu加速。
效果:模型推理时间从700ms左右减为40ms左右;从摄像头获得输入,可以获得正确的预测结果。
疑惑:为什么量化需要输入数据集作为参数呢?
使用的编译参数为
ncc compile mnist_float.tflite mnist_float.kmodel -i tflite -o kmodel -t k210 --inference-type uint8 --dataset ./dataset_mnist --input-std 1 --input-mean 0
ncc compile mobilenet_v2.tflite mobilenet_v2.kmodel -i tflite -o kmodel -t k210 --inference-type uint8 --dataset ./dataset_garbage --input-std 1 --input-mean 0 --dump-weights-range --weights-quantize-threshold 64.000000
不进行量化(建议量化,因为摄像头输入本身是uint8):
ncc compile cifar10.tflite cifar10.kmodel -i tflite -o kmodel -t k210 --inference-type float
1-4
以moblienet-v2网络在mnist上训练了一个模型,然后转为tflite,分析了网络使用算子的支持情况。
mobilenet-v2网络代码来源:MobileNet V2 网络结构的原理与 Tensorflow2.0 实现 。
下表为mobilenet-v2中的算子支持情况:
| 算子 | 支持 |
|---|---|
| Conv2D | ✅ |
| Relu6 | ✅ |
| DepthwiseConv2D | ✅ |
| Add | ✅ |
| Mean | ✅ |
| Shape | ❌ |
| StridedSlice | ✅ |
| Pack | ❌ |
| Reshape | ✅ |
| Softmax | ✅ |
修改网络后,开始尝试tflite转kmodel。
bug:
Fatal: Invalid dataset, should contain one file at least,但文件夹明明非空啊。发现:文件夹的名字打错了,修正后得到了kmodel。
问题:转换过程中显示
WARN: Conv2D_19 Fallback to float conv2d due to weights divergence,暂时不知有什么影响。
连接板子运行时,加载模型失败。
bug:ValueError: [MAIXPY]kpu: load error:2003, ERR_KMODEL_FORMAT: layer_header.body_size <= 0
参考:Fallback to float conv2d due to weight divergence · Issue #164 · kendryte/nncase (github.com) 。
bug2:使用Netron查看网络结构时显示Error loading kmodel. Unsupported version ‘4’ layer ‘strided_slice’.
发现:若不进行量化,可以在Netron正常查看结构,但仍加载时仍然有ValueError。
猜测:是否网络中单层体积太大?记得maixpy文档中说单层不能超过2MB(不知道是指参数量、输出特征图,还是什么)。使用
model.summary()查看网络各层,最大的一层Param为410880。不知道每个参数占多大的空间,我们先假定为8字节,于是这层占用内存为 410880 ∗ 8 / 102 4 2 = 3.13 M B 410880*8/1024^2=3.13MB 410880∗8/10242=3.13MB 。但这样就有一个矛盾,.tflite模型文件的实际大小为8.47MB,如果我按上面的计算方法,将所有层参数的参数大小加起来,会远超这个数值。疑惑:卷积层的参数量是怎么计算的?前一层输出尺寸为(None, 1, 1, 320),本身输出为(None, 1, 1, 1280)。于是 ( 320 + 1 ) ∗ 1280 = 410880 (320 + 1) * 1280 = 410880 (320+1)∗1280=410880 。但这不应该是全连接层的计算方法吗?我理解中卷积层应该 P a r a m = f i l t e r ∗ k e r n e l Param = filter * kernel Param=filter∗kernel 。
1-5
对比Params与模型文件实际体积。
结果:模型实际大小与Params大小是可以对上的,参数应该是以float32存储。我把“字节”与“位”搞混了,应该是一个字节为8位。
疑惑:为什么nncase量化后,模型文件体积还是没有显著减小?例如tfilte文件大小为436KB,量化后的kmodel大小仍有380KB。但从float32到uint8,大小理应变为四分之一。
看tensorflow的视频,卷积层参数量如何计算。
结果: P a r a m = C o u t ∗ ( W ∗ H ∗ C i n + 1 ) Param=C_{out} * (W * H * C_{in} + 1) Param=Cout∗(W∗H∗Cin+1) 。输出特征图的通道数决定过滤器的个数,输入特征图的通道数决定每个过滤器的通道数。
重新训练mobilenet_v2。
发现:使用batch_size=128和使用batch_size=32时每个step的耗时差不多,于是整体使用batch_size=128时准确率上升更快。然而训练准确率达到92%时,测试准确率却只有70%。
使用batch_size=32时,也出现了过拟合。训练5个epoch时准确率从78%到了81%,但是测试准确率却突然从73%掉到了58%。再训练5个epoch后训练准确率为84%,测试准确率又回到了74%。
问题:过拟合真的是噩梦。
发现2:转换为kmodel后的体积发生了变化。tflite是8.47MB没有变,上次kmodel是8.44MB,这次kmodel是6.31MB。使用Netron依然打不开模型,板子上也依然加载不了。
问题2:据chatGPT和mainxpy群里的“小老鼠”所说,转换模型时的
WARN: Conv2D_19 Fallback to float conv2d due to weights divergence没有关系。那导致加载模型时ValueError的原因是什么呢?发现3:因为使用的cifar10数据集,图片分辨率为(32, 32),所以网络中出现了(1, 1)分辨率的图片被(3, 3)卷积核卷积的情况,可能是它导致了问题。
改用图片分辨率为(224, 224)的数据集训练mobilenet_v2 。
进度:卡在了调整数据集中图片大小这一步,找了个猫狗数据集,数据集中图片的分辨率是不固定的。虽然opencv的resize操作可以调整图片大小,但是我不知道怎么把这个操作插入到tensorflow训练模型的流水线中去。
贪图一些API的方便,却又不熟悉这些API的使用。
解决方案:继续学习tensorflow课程视频,了解对自己数据集的处理流程。
1-8
miblenet_v2在horse-or-human数据集上训练失败。
发现:层
tf.keras.layers.BatchNormalization()似乎会导致问题,多次使用该层容易导致像是过拟合的现象。下面是五层卷积的简单模型,插入了三层BatchNormalization,产生的训练数据:
Epoch 1/5 16/16 [=====] - 7s 345ms/step - loss: 2.6593 - acc: 0.7812 - val_loss: 0.6854 - val_acc: 0.7617 Epoch 2/5 16/16 [=====] - 5s 305ms/step - loss: 0.0719 - acc: 0.9793 - val_loss: 0.7076 - val_acc: 0.4570 Epoch 3/5 16/16 [=====] - 5s 320ms/step - loss: 0.3488 - acc: 0.8887 - val_loss: 0.6957 - val_acc: 0.4688 Epoch 4/5 16/16 [=====] - 5s 321ms/step - loss: 0.0114 - acc: 0.9980 - val_loss: 0.6909 - val_acc: 0.5000 Epoch 5/5 16/16 [=====] - 6s 373ms/step - loss: 0.2425 - acc: 0.9503 - val_loss: 0.8048 - val_acc: 0.5000使用mobilenet_v2时,现象类似,train_acc可以在90%以上,val_acc恒为50%整。
令人不解的是,当我使用训练集数据进行评估,acc是在50%附近浮动,那为何训练时会显示那么高的准确率?
model.evaluate(train_generator) 129/129 [==============================] - 10s 77ms/step - loss: 0.8571 - acc: 0.4869删除mobilenet_v2中的所有BatchNormalization层,模型却无法收敛了,train_acc在50%附件徘徊。
使用的mobilenet_v2模型代码来自MobileNet V2 网络结构的原理与 Tensorflow2.0 实现 。
想法:换个数据集会不会不一样?毕竟mobilenet_v2之前在mnist数据集上是可以正常训练的。
猜测:1、我的mobilenet_v2代码有问题,与官方的不同;2、数据集不合适。
方案:1、调用
model.summary()查看keras中官方mobienet_v2的模型结构,与它对齐;2、改用自己的4分类垃圾数据集训练。
1-9
对齐mobilenet_v2模型结构 。
步骤1:先试试keras中的mobilenet_v2能不能正常训练;
结果:train_acc正常上升。(补充:这步疏忽了,没有测试val_acc,后面发现是有问题)
步骤2:对比两个模型的结构,以及训练时准确率;
发现:相对官方模型的train_acc随epoch稳定上升,我的模型train_acc显得不稳定。仔细对比模型结构,发现我模型尾部多了个卷积层。
# 例 - 调用keras官方mobilenet_v2 tf.keras.applications.mobilenet_v2.MobileNetV2(input_shape=(224,224,3), weights=None, classes=4)在原来CSDN找到的代码中,该卷积层与Reshape层搭配,发挥全连接层的作用。因为nncase-v0.2.0不支持Reshape层(Reshape算子是支持的,但是Reshape层会产生不被支持的Shape算子),我就把Reshape删了,补了全连接层Dense,但是我没有把那个卷积层删掉。于是,相当于多了一层。
# 原代码中的用法 x = tf.keras.layers.GlobalAveragePooling2D()(x) x = tf.keras.layers.Reshape((1,1,1280))(x) x = tf.keras.layers.Conv2D(classes, (1,1), padding='same')(x) x = tf.keras.layers.Reshape((classes,))(x) x = tf.keras.layers.Activation('softmax')(x)# 正确修改方式 x = tf.keras.layers.GlobalAveragePooling2D(keepdims=True)(x) x = tf.keras.layers.Flatten()(x) x = tf.keras.layers.Dense(classes)(x) x = tf.keras.layers.Activation('softmax')(x)改成上述“正确修改方式“后,训练效果与官方模型接近。
进一步训练mobilenet_v2模型,尝试转换和上板 。
突发:Colab的GPU限额了,正在摸索阿里的天池实验室。
原来的代码与天池实验室默认环境不兼容,但此时发现我的Colab解封了,哈哈。
问题:发现官方的模型也不能正常训练;训练时train_acc可以上升,但我将训练集作为验证集得到的val_acc在25%左右。
Epoch 1/2 64/64 - 53s 820ms/step - loss: 1.5922 - acc: 0.3819 - val_loss: 1.4714 - val_acc: 0.2489 Epoch 2/2 64/64 - 53s 834ms/step - loss: 1.5034 - acc: 0.3931 - val_loss: 1.4462 - val_acc: 0.2489分析:是模型的问题,还是训练过程的问题?
- 要说模型,但之前mobilenet_v2模型在mnist和cifar-10数据集上都可以正常预测;
- 要说训练过程,但之前该流程在horse-or-human上训练也可以正常预测。
怎么组合起来就不行了呢?
发现:只要换成下面注释调的那几行代码,模型训练就由 ”正常“ 变为 ”val_acc恒为50%“。
from tensorflow.keras.optimizers import RMSprop# model = tf.keras.applications.mobilenet_v2.MobileNetV2(input_shape=(150,150,3), weights=None, classes=2)model.compile(loss='binary_crossentropy',# loss='categorical_crossentropy',optimizer=RMSprop(lr=0.001),metrics=['acc'])from tensorflow.keras.preprocessing.image import ImageDataGeneratortrain_datagen = ImageDataGenerator(rescale=1/255) train_generator = train_datagen.flow_from_directory('horse-or-human',target_size=(150,150),batch_size=32,class_mode='binary'# class_mode='categorical' )validation_datagen = ImageDataGenerator(rescale=1/255) validation_generator = validation_datagen.flow_from_directory('validation-horse-or-human',target_size=(150,150),batch_size=32,class_mode='binary'# class_mode='categorical' )history = model.fit(train_generator,steps_per_epoch=16, # 控制单个epoch的大小,以batch为单位。epochs=5,verbose=1,validation_data=validation_generator )发现2:令人疑惑的情况越来越多了,在tensorflow官方手写数字识别的例子(数据集已被我换成cifar-10)中,换上我的mobilenet_v2时val_acc正常,调用的官方mobilenet_v2模型却val_acc=10%。
参见我的notebook:mobilenet_v2尝试-mnist 。
感觉Colab的环境不太稳定,容易突然卡住或者变慢;而且有时会提示配额上限。
也许我还是需要在自己的电脑上搭建个tensorflow环境。
1-10
给我的电脑安装tensorflow的GPU环境 。
(不用)查看某个已安装包的信息
pip show <包名>查看电脑的CUDA版本,在命令行输入
nvidia-smitensorflow-gpu需要搭配cuda和cudnn使用。
我的CUDA版本:11.7
官方链接:tensorflow-gpu的版本关系
计划版本搭配:
python3.7,tensorflow_gpu-2.6.0,cudnn8.2.1,对应的CUDA应该是11.2。包管理工具:使用
conda install结果:安装成功,很顺利。
解决
conda install时CondaSSLError的问题。参考:[报错解决]CondaSSLError
在参考博客的评论区看到说环境变量的问题,我想起来我以前为了在命令行窗口运行非anaconda的python,把一些环境变量删掉了,后来忘记补上。一股脑补上一些环境变量后,重启终端窗口,就好了。
D:\anaconda D:\anaconda\Scripts D:\anaconda\Library\bin D:\anaconda\Library\mingw-w64\bin
将cifar-10数据集用ImageDataGenerator加载,训练mobilenet_v2 。
怀疑:ImageDataGenerator的使用流程可能存在导致问题;
理由:
我之前直接用API调cifar-10数据集,是可以正常训练mobilenet_v2模型的。
换到ImageDataGenerator从文件夹加载图片后,就出现 “训练时train_acc上涨,val_acc不变;在训练集上的评估acc像没训练” 的情况。
下一步:何必用ImageDataGenerator?我可以自己写代码从文件夹读图片,读成images+labels的形式,与正确训练的条件对齐。
重写数据加载部分代码,训练mobilenet_v2 。
结果:在cifar-10上训练成功,在horse-or-human和我的GarbageForMaixHub上训练失败。
越来越疑惑,是谁的问题?模型?数据集?
1-11
尝试mobilenet_v2模型从训练到板上推理的流程能否走通,暂不考虑模型准确性 。
问题:转kmodel时报错:
Fatal: KPU allocator cannot allocate more memory.;搜索问题发现,可能是KPU限制特征图大小不能超过2MB。但我最大的一层特征图尺寸为(1, 112, 112, 96),大小是 1 , 204 , 224 1,204,224 1,204,224 ,1MB多一点而已。尝试:将训练时输入尺寸减半,从(224,224)到(112,112)
结果:转换得到了kmodel,大小为2.25MB
问题:
E (4139792902) SYSCALL: Out of memory。烧录后,加载模型会卡住没反应,打开串口终端就报这个错误。可能方案:换更小的固件,参见:使用mind+运行口罩识别模型显示内存不足(已解决)
分析:应该是板子是的main.py文件里有加载模型的操作,加载我刚刚烧录的模型,就会导致Out of memory
查看内存大小,参见:内存管理 - Sipeed Wiki
import gc print(gc.mem_free() / 1024) # stack mem import Maix print(Maix.utils.heap_free() / 1024) # heap mem ''' 我的 502.9687 2532.0 官方示例 352.0937 4640.0 '''内存好像是偏小,可以换个小固件、或者减小模型输入图片尺寸试试。
换固件:maixpy_v0.6.2_84_g8fcd84a58_openmv_kmodel_v4_with_ide_support.bin,再查看内存大小为[502.9687, 3912.0]
再减小模型输入尺寸 :从(112, 112)到(96, 96)。96应该是当前模型结构能用的最小输入尺寸了,再小就会出现(2, 2)的特征图被(3, 3)的卷积核处理的情况,这在k210上会导致加载失败(上次mobilenet_v2在cifar-10上训练的模型就是加载时报错)。
结果:模型加载成功。
import sensor, lcd, image import KPU as kpu# 测试板子是否响应 print('\nboard start...') # 载入模型 model_addr = 0x300000 print('load model...') task = kpu.load(model_addr) print('hello, world')''' 终端输出 board start... load model... hello, world '''下一步:测试模型能否产生预测输出