图解:
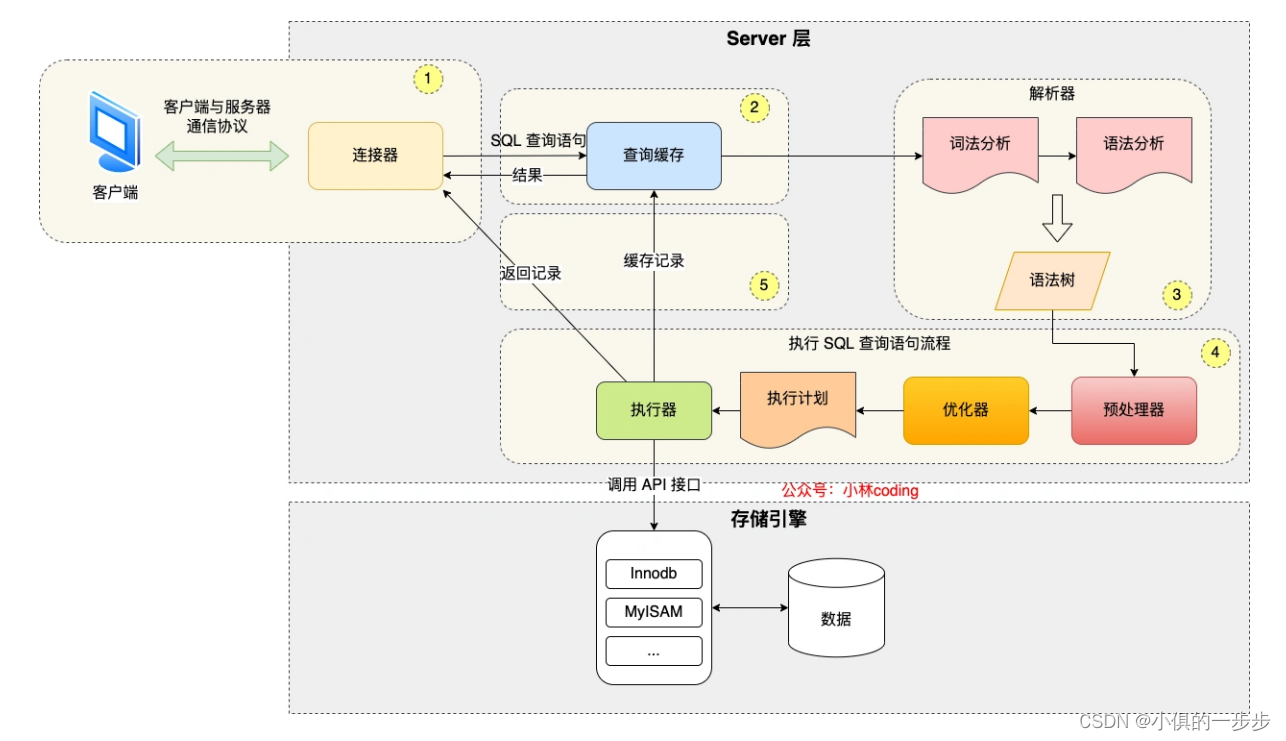
第⼀步:连接器
过程
1. 建⽴连接:与客户端进⾏ TCP 三次握⼿建⽴连接;
2. 校验密码:校验客户端的⽤户名和密码,如果⽤户名或密码不对,则会报错;3. 权限判断:如果⽤户名和密码都对了,会读取该⽤户的权限,然后后⾯的权限逻辑判断都基于此时读取到的权限;
注意点:
1.如何查看 MySQL 服务被多少个客户端连接了?
mysql> show processlist;
2.空闲连接会⼀直占⽤着吗?
空闲连接的最⼤空闲时⻓,由 wait_timeout 参数控制的
查询命令
mysql> show variables like 'wait_timeout';
⼿动断开
mysql> kill connection +6;
3.MySQL 的连接数有限制吗?
MySQL 服务⽀持的最⼤连接数由 max_connections 参数控制。
MySQL 的连接也跟 HTTP ⼀样,有短连接和⻓连接的概念。
4.怎么解决⻓连接占⽤内存的问题?
定期断开⻓连接
客户端主动重置连接
第⼆步:查询缓存
过程
解析出 SQL 语句的第⼀个字段,看看是什么类型的语句。
如果 SQL 是查询语句(select 语句),MySQL 就会先去查询缓存( Query Cache )⾥查找缓存数据。 如果查询的语句命中查询缓存,那么就会直接返回 value 给客户端。
如果查询的语句没有命中查询缓存中,那么就要往下继续执⾏,等执⾏完后,查询的结果就会被存⼊查询缓存中。
缺点
更新⽐较频繁的表,查询缓存的命中率很低
版本变动
MySQL 8.0 版本直接将查询缓存删掉了,也就是说 MySQL 8.0 开始,执⾏⼀条 SQL 查询语句,不会再⾛到查 询缓存这个阶段了。 对于 MySQL 8.0 之前的版本,如果想关闭查询缓存,我们可以通过将参数 query_cache_type 设置成 DEMAND。这⾥说的查询缓存是 server 层的,也就是 MySQL 8.0 版本移除的是 server 层的查询缓存,并不是 Innodb 存储引 擎中的 buffer pool。
第三步:解析 SQL
过程
1. 词法分析
2. 语法分析
3. 语法不对,解析器就会给报错
注意:表不存在或者字段不存在,并不是在解析器⾥做的,解析器只负责构建语法树和检查语法,但是不会去查表 或者字段存不存在。
第四步:执⾏ SQL
过程
1. prepare 阶段,也就是预处理阶段;
2. optimize 阶段,也就是优化阶段;
3. execute 阶段,也就是执⾏阶段;
1 预处理器
检查 SQL 查询语句中的表或者字段是否存在;
将 select * 中的 * 符号,扩展为表上的所有列;
2 优化器
优化器主要负责将 SQL 查询语句的执⾏⽅案确定下来 ⽐如在表⾥⾯有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使⽤哪个索引。
要想知道优化器选择了哪个索引,我们可以在查询语句最前⾯加个 explain 命令
3 执⾏器
执⾏器就会和存储引擎交互了,交互是以记录为单位的。
三种⽅式执⾏过程
- 主键索引查询
- 全表扫描
- 索引下推(MySQL 5.6 推出的查询优化策略)
特点
- 执⾏器查询的过程是⼀个 while 循环
- Server 层每从存储引擎读到⼀条记录就会发送给客户端,之所以客户端显示的时候是直接显示所有记录的, 是因为客户端是等查询语句查询完成后,才会显示出所有的记录
总结
执⾏⼀条 SQL 查询语句,期间发⽣了什么?
1.连接器:建⽴连接,管理连接、校验⽤户身份;
2.查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执⾏。MySQL 8.0 已删除该模块;
3.解析 SQL,通过解析器对 SQL 查询语句进⾏词法分析、语法分析,然后构建语法树,⽅便后续模块读取表 名、字段、语句类型;
4.执⾏ SQL:执⾏ SQL 共有三个阶段:
- 预处理阶段:检查表或字段是否存在;将 select * 中的 * 符号扩展为表上的所有列。
- 优化阶段:基于查询成本的考虑,选择查询成本最⼩的执⾏计划;
- 执⾏阶段:根据执⾏计划执⾏ SQL 查询语句,从存储引擎读取记录,返回给客户端