文章目录
- 摘要
- 1、引言
- 2、 相关工作
- 2.1、用于移动设备的卷积网络
- 2.2、移动设备上的ViT和CNN-ViT混合模型
- 2.3、评估指标
- 3、CNN-ViT 混合模型在低端CPU上的应用
- 3.1、设计原则
- 3.2、SBCFormer的整体设计
- 3.3、SBCFormer块
- 3.4、改进的注意力机制
- 4、实验结果
- 4.1、实验设置
- 4.2、ImageNet-1K
- 4.2.1、训练
- 4.2.2、结果
- 4.2.3、消融测试
- 4.3、检测与分割
- 4.3.1、数据集与实验配置
- 4.3.2、结果
- 5、结论
- 致谢
摘要
https://arxiv.org/ftp/arxiv/papers/2311/2311.03747.pdf
计算机视觉在解决包括智能农业、渔业和畜牧业管理等不同领域的实际问题中变得越来越普遍。这些应用可能不需要每秒处理许多图像帧,因此从业者倾向于使用单板计算机(SBCs)。尽管已经为“移动边缘”设备开发了许多轻量级网络,但它们主要针对具有更强大处理器的智能手机,而不是具有低端CPU的SBCs。本文介绍了一种名为SBCFormer的CNN-ViT混合网络,该网络在低端CPU上实现了高准确性和快速计算。这些CPU的硬件限制使得Transformer的注意力机制比卷积更可取。然而,在低端CPU上使用注意力机制存在挑战:高分辨率的内部特征图需要过多的计算资源,但降低其分辨率会导致丢失局部图像细节。SBCFormer引入了一种架构设计来解决这个问题。因此,SBCFormer在具有ARM-Cortex A72 CPU的Raspberry Pi 4 Model B上实现了精度和速度之间的最高权衡。这是首次在SBC上以1.0帧/秒的速度实现了大约80%的ImageNet-1K top-1准确度。代码可在https://github.com/xyongLu/SBCFormer上找到。
1、引言
深度神经网络已被用于各种计算机视觉任务,这些任务需要在不同的硬件上进行推理。为满足这一需求,已提出了众多针对移动和边缘设备的深度神经网络设计。自MobileNet [27]问世以来,许多研究者提出了用于移动设备的各种卷积神经网络(CNN)架构设计[46, 49, 68]。此外,自视觉转换器(ViT) [12]提出以来,也进行了多次尝试以将ViT适应于移动设备 [4,8,42,65]。当前的趋势是开发CNN-ViT混合模型[20,21,35,50]。得益于这些研究,虽然ViT以前被认为是缓慢的,而轻量级CNN是移动设备的唯一可行选择,但最近针对移动设备的混合模型在计算效率和推理准确度之间的权衡方面已经超越了CNN [14,31,32,44]。
以前的研究主要关注智能手机作为“移动/边缘”设备。尽管智能手机中的处理器不及服务器中的GPU/TPU强大,但它们仍然相当强大,在处理器谱系中属于中端。然而,还存在一些“低端”处理器,如嵌入式系统的CPU/MPU,它们通常的计算能力非常有限。尽管如此,这些处理器已被用于各种实际应用中,如智能农业[41,69]以及渔业和畜牧业管理的AI应用[2,30],在这些应用中,有限的计算资源就足够了。例如,在防止野生动物破坏的物体检测中,可能不需要每秒处理数十帧图像[1]。在许多情况下,每秒处理大约一帧图像是实用的。事实上,像MobileNet和YOLO这样的轻量级模型在此类应用中相当受欢迎,通常使用配备摄像头的单板计算机(SBC)实现。
本研究主要关注低端处理器,这些处理器在轻量级网络的发展中一直被忽视。鉴于它们的限制,我们引入了一种名为SBCFormer的架构设计。指导我们研究的核心问题是卷积或Transformer的注意力机制哪一种更适合SBCs。正如[14]所述,卷积需要复杂的内存访问模式,需要高IO吞吐量以进行有效处理,而注意力则相对简单。此外,两者都转换为矩阵乘法,而注意力通常处理比传统im2col卷积方法更小的矩阵维度。
考虑到SBCs在并行计算资源和内存带宽方面不如GPU,注意力成为SBCs的首选基础构建块。然而,注意力计算的复杂度与令牌数量的平方成正比。因此,确保计算效率和降低延迟的关键在于在特征图中保持低空间分辨率。(请注意,空间分辨率为H × W的特征图对应于HW个令牌。)
使用ViT架构会导致所有层的特征图保持一致的分辨率,但由于特征图较粗糙,会丢失输入图像的局部细节。为此,最近旨在提高计算效率的模型,特别是CNN-ViT混合模型[32, 40, 42, 54],采用了更类似于CNN的基础结构。在这些模型中,特征图通过从输入到输出的下采样来降低其空间分辨率。由于对所有层应用注意力会大大增加计算成本,特别是在具有高空间分辨率的层中,这些模型仅在顶层使用注意力机制。这种设计利用了Transformer的注意力机制在图像特征的全局交互方面的优势,同时保留了特征图中的局部细节。然而,对于SBCs来说,低层的卷积可能会成为问题,导致更长的计算时间。
为了在保留局部信息的同时优化注意力计算,我们的SBCFormer采用了一种双流块结构。第一流缩小输入特征图,对减少的令牌数量应用注意力,然后将地图恢复到其初始大小,以确保高效的注意力计算。认识到缩小尺寸可能导致的局部信息损失,第二流作为“直通”通道来保留输入特征图中的局部信息。这两条流汇聚在一起,生成一个融合了局部和全局信息的特征图,为下一层做好准备。此外,我们改进了Transformer的注意力机制,以弥补专注于较小特征图时可能导致的表示能力下降。
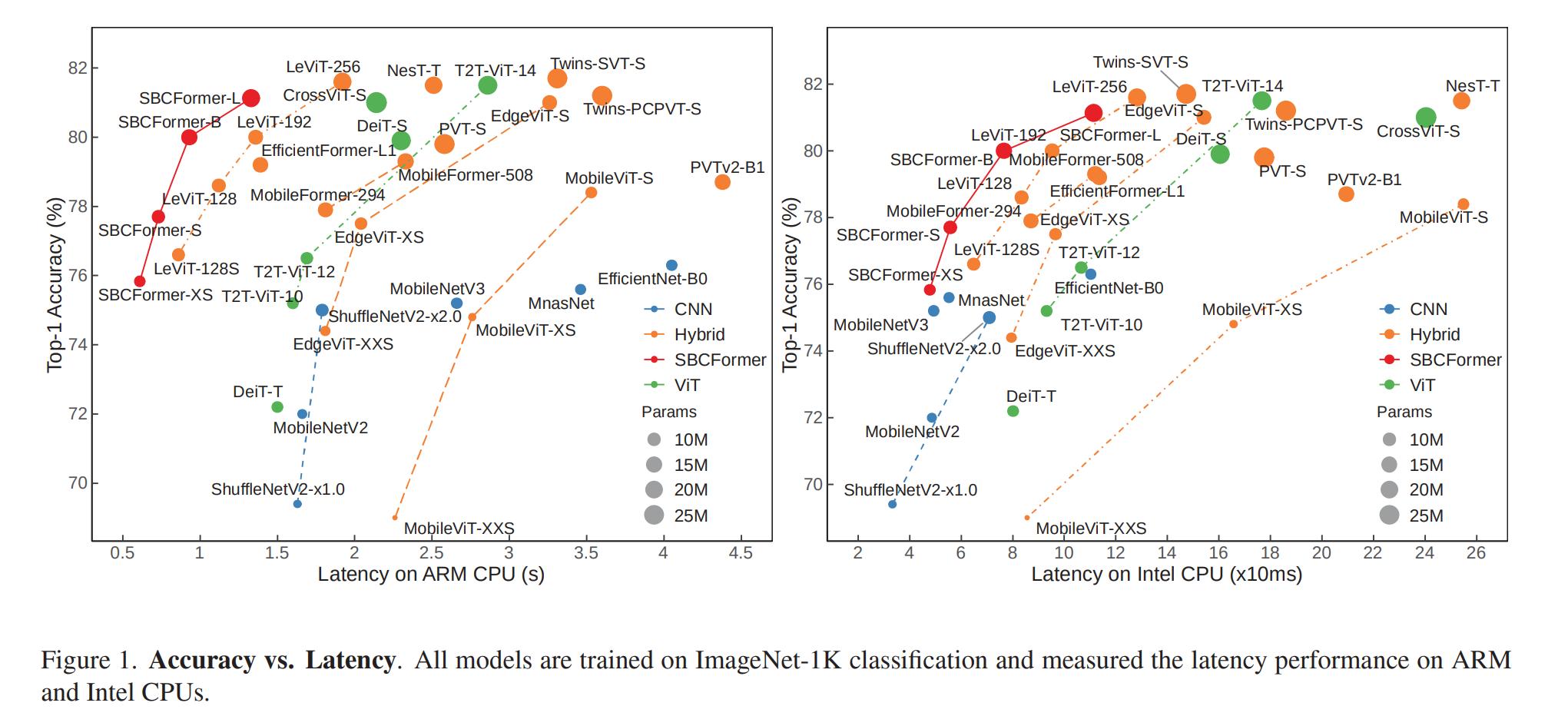
我们的实验证明了SBCFormer的有效性,如图1所示。由于上述进步,SBCFormer在广泛使用的单板计算机(SBC)上,即配备ARM Cortex-A72 CPU的Raspberry Pi 4 Model B上,实现了最高的准确度和速度之间的权衡。事实上,SBCFormer在SBC上以每秒1.0帧的速度实现了接近80.0%的ImageNet 1K top-1准确度,这是首次达到这一性能水平。
2、 相关工作
2.1、用于移动设备的卷积网络
近年来,随着视觉应用在不同领域的深入发展,对深度神经网络的需求日益增长,这促使研究人员关注高效神经网络的设计。一种方法是通过使卷积计算更高效来实现,如SqueezeNet[28]等作品所示。MobileNet[27]引入了深度可分离卷积来降低标准卷积层的昂贵计算成本,以满足边缘设备的资源限制。MobileNetV2[46]改进了设计,引入了倒残差块。我们提出的SBCFormer将倒残差块作为卷积操作的主要构建块。
另一种方法旨在设计高效的卷积神经网络(CNN)架构,如Inception[47]和MnasNet[48]等工作所示。其他研究还提出了轻量级模型,包括ShuffleNetv1[68]、ESPNetv2[43]、GhostNet[17]、MobileNeXt[71]、EfficientNet[49]和TinyNet[18]等。
值得注意的是,包括上述提到的CNN在内,它们只能在每一层捕获图像中的局部空间相关性,而无法考虑全局交互。另一个需要考虑的重要点是,对于CPU来说,对标准大小的图像进行卷积计算可能是昂贵的,因为它需要大矩阵乘法。在这些方面,视觉转换器(ViT)具有优势[12]。
2.2、移动设备上的ViT和CNN-ViT混合模型
得益于自注意力机制[56]和大规模图像数据集,视觉转换器(ViT)[12]和相关基于ViT的架构[3, 6, 29, 52, 72]在各种视觉识别任务中达到了最先进的推理精度[16, 67]。然而,为了充分发挥其潜力,基于ViT的模型通常需要大量的计算和内存资源,这限制了它们在资源受限的边缘设备上的部署。随后,一系列研究致力于从各个角度提高ViT的效率。受卷积架构中层次设计的启发,一些工作为ViT开发了新架构[24, 58, 62, 66]。神经架构搜索方法也被用于优化基于ViT的架构[7, 13]。此外,为了降低ViT的计算复杂性,一些研究人员提出了高效的自注意力机制[5, 15, 25, 57],而另一些则专注于利用新的参数效率策略[23, 51]。
随后的研究表明,在Transformer块中融入卷积操作可以提高基于ViT的模型的性能和效率。例如,LeViT[14]在网络开始处重新引入了一个卷积茎,以学习低分辨率特征,而不是使用ViT[12]中的补丁茎。EdgeViT[44]引入了局部-全局-局部块,以更好地整合自注意力和卷积,使模型能够捕获具有不同范围的空间标记并在它们之间交换信息。MobileFormer[8]并行化MobileNet和Transformer以编码局部和全局特征,并通过双向桥接融合这两个分支。MobileViT[42]将Transformer块视为卷积,并开发了一个MobileViT块来有效地学习局部和全局信息。最后,EfficientFormer[32]采用了一种混合方法,结合了卷积层和自注意力层,以实现准确性和效率之间的平衡。
尽管在开发移动设备混合模型方面进行了积极的研究,但仍有一些问题需要解决。首先,许多研究并没有将延迟(即推理时间)作为评估效率的主要指标,这将在后面进行讨论。其次,这些研究往往忽略了低端CPU,目标最多仅限于智能手机的CPU/NPU和Intel CPU。例如,LeViT是在ARM CPU上评估的,具体来说是针对云服务器设计的ARM Graviton 2。
2.3、评估指标
评估计算效率的指标有很多,包括模型参数数量、操作数(即浮点运算次数FLOPs)、推理时间或延迟,以及内存使用量。尽管所有这些指标都很重要,但在本研究中,延迟尤其受到关注。值得注意的是,Dehghani等人[10]和Vasu等人[55]的研究表明,延迟方面的效率与浮点运算次数和参数数量之间的相关性并不强。
如前所述,一些研究已经专注于开发轻量级且高效的卷积神经网络(CNN)。然而,只有少数研究,如MNASNet[48]、MobileNetv3[26]和ShuffleNetv2[39],直接针对延迟进行了优化。CNN-ViT混合网络的研究也是如此,其中一些研究主要是为了移动设备而设计的[8,42];大多数这些研究并没有将延迟作为目标进行优先考虑,而是专注于像浮点运算次数(FLOPs)这样的指标[8]。
这些研究中经常避免讨论延迟,这是有充分理由的。这是因为每个处理器的指令集和与之一起使用的编译器对延迟的影响很大。因此,为了获得实际的评估结果,需要选择特定的处理器,但这会牺牲一般性讨论。在本文中,我们选择用于单板计算机的CPU,如树莓派,作为我们的主要目标,它在各个领域被广泛用于边缘应用。它配备了专为移动平台设计的微处理器ARM Cortex-A72,属于ARM Cortex-A系列。
3、CNN-ViT 混合模型在低端CPU上的应用
我们的目标是开发一个CPU友好的ViT-CNN混合网络,在测试时延迟和推理准确性之间实现更好的权衡。
3.1、设计原则
我们采用了最近CNN-ViT混合模型中常用的基础架构。网络的初始阶段包含一组标准的卷积层,这些卷积层擅长将输入图像转换为特征图,而不是像ViT中那样从图像块到令牌的线性映射。网络的主要部分被分为多个阶段,连续阶段之间的特征图尺寸会减小。这导致了一个特征图金字塔结构,其维度为 H / 8 × W / 8, H / 16 × W / 16, H / 32 × W / 32 等。
Transformer的注意力机制的计算复杂度与令牌数量(即输入特征图的大小 h × w)呈二次方增长。因此,具有较大尺寸特征图的较低阶段需要更多的计算成本。一些研究通过仅对特征图的子区域/令牌应用注意力来解决这个问题。针对移动设备的研究通常只在高层使用注意力机制。虽然这避免了计算成本的增加,但导致了次优的推理准确性,因为它放弃了ViT中最重要的属性之一,即聚合图像中的全局信息。
考虑到这些因素,我们提出了一种方法,即缩小输入特征图的大小,对缩小后的特征图应用注意力,然后将得到的特征图放大。在我们的实验中,无论阶段如何,对于大小为 224 × 224 的输入图像,我们都将特征图缩小到 7 × 7。这种沙漏设计允许我们聚合整个图像的全局信息,同时最小化计算成本。
然而,将特征图缩小到这么小的尺寸可能会导致局部信息的丢失。为了解决这个问题,我们设计了一个包含两个并行流的块:一个用于局部特征,另一个用于全局特征。具体来说,我们保持局部流的原始特征图大小,并不执行注意力操作。对于全局流,我们采用上述沙漏式的注意力设计,即首先缩小特征图,应用注意力,然后将其放大到原始大小。两个流的输出被合并并传递到下一个块。更多细节见第3.3节。此外,为了弥补沙漏设计导致的表示能力损失,我们提出了一种改进的注意力机制。见第3.4节。
3.2、SBCFormer的整体设计
图2展示了我们所提出的SBCFormer的整体架构。网络以初始部分(图中标记为“Stem”)开始,该部分包含三个卷积层,每个卷积层使用 3 × 3 3 \times 3 3×3的卷积核和步长为2,用于将输入图像转换为特征图。主体部分包含三个阶段,每个阶段通过单个卷积层(图中标记为“Embedding”)连接到下一个阶段。该层使用步长为2的 3 × 3 3 \times 3 3×3卷积将输入特征图的大小减半。至于输出部分,我们采用全局平均池化,后跟一个全连接线性层,作为网络的最后一层,特别是用于图像分类任务。
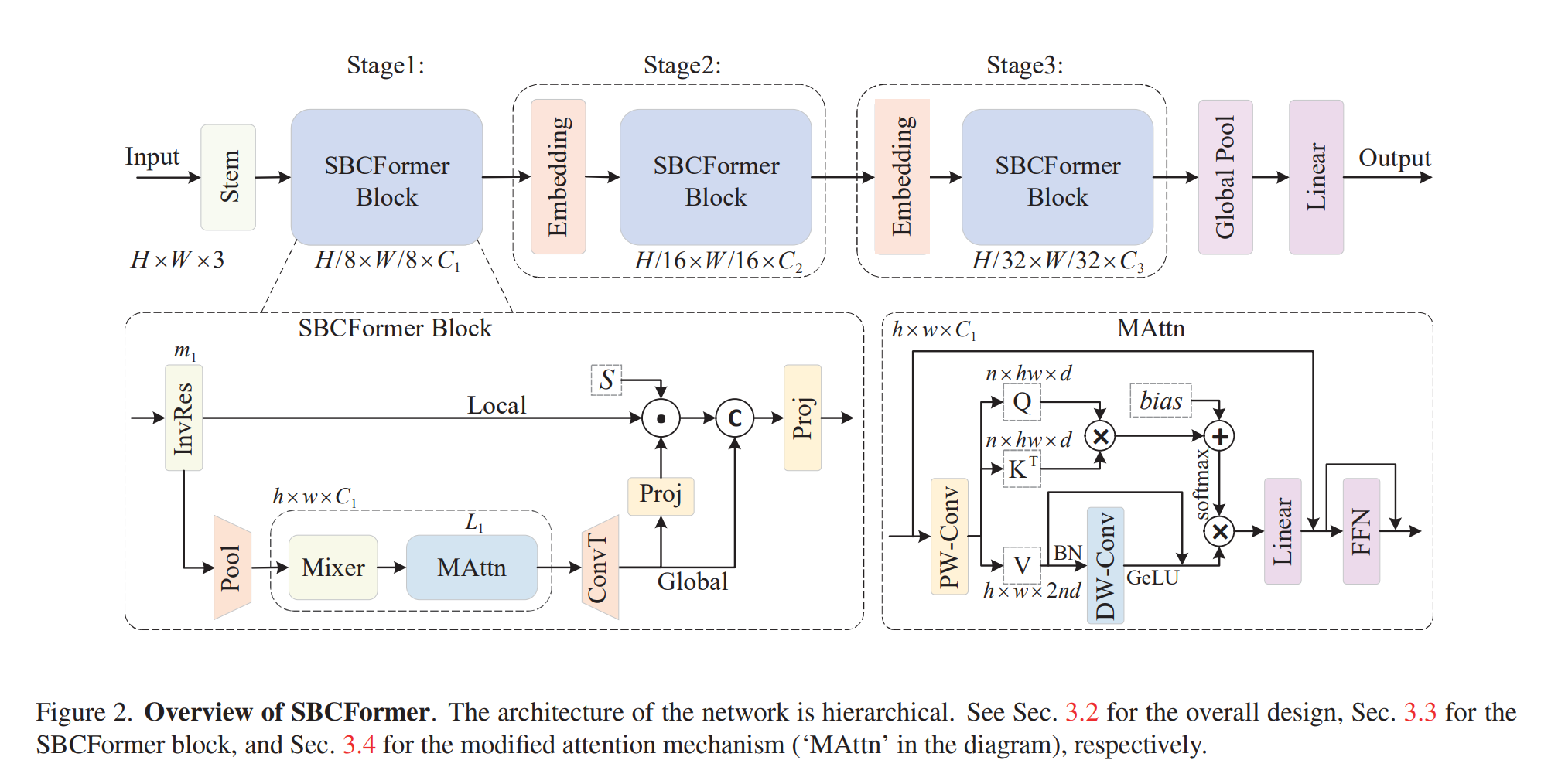
3.3、SBCFormer块
我们用 X i ∈ R ( H / 2 i + 2 ) × ( W / 2 i + 2 ) × C i \mathbf{X}_{i} \in \mathbb{R}^{\left(H / 2^{i+2}\right) \times\left(W / 2^{i+2}\right) \times C_{i}} Xi∈R(H/2i+2)×(W/2i+2)×Ci 表示第 i i i阶段的块输入特征图。
为了开始一个块,我们在开头放置了 m i m_{i} mi个连续的倒置残差块[46],这种块最初在MobileNetV2[46]中使用。我们使用的是带有GeLU激活函数的变体,该变体包含一个逐点卷积、一个GeLU激活函数和一个带有 3 × 3 3 \times 3 3×3滤波器的深度卷积。我们后续将其称为InvRes。这些块将输入图 X i \mathbf{X}_{i} Xi转换为 X i l \mathbf{X}_{i}^{l} Xil,如下所示:
X i l = F InvRes m i ( X i ) , \mathbf{X}_{i}^{l}=\mathcal{F}_{\text {InvRes }}^{m_{i}}\left(\mathbf{X}_{i}\right), Xil=FInvRes mi(Xi),
其中 F m i ( ⋅ ) \mathcal{F}^{m_{i}}(\cdot) Fmi(⋅)表示将 m i m_{i} mi个连续的InvRes块应用于输入。
如图2所示,更新后的特征 X i l \mathbf{X}_{i}^{l} Xil被传送到两个不同的分支,即局部流和全局流。对于局部流, X i l \mathbf{X}_{i}^{l} Xil直接传递到块的末端部分。对于全局流, X i l \mathbf{X}_{i}^{l} Xil首先通过一个平均池化层缩小到 h × w h \times w h×w的大小,在图2中标记为“Pool”。在我们的实验中,我们将其设置为 7 × 7 7 \times 7 7×7,无论处于哪个阶段。缩小后的特征图随后被传入一个包含两个连续InvRes块的块,在图中标记为“Mixer”,旁边是一堆名为“MAttn”的注意力块。输出特征图随后被放大,并经过卷积,这在图中表示为“ConvT”。这些操作提供了特征图 X i g ∈ R ( H / 2 i + 2 ) × ( W / 2 i + 2 ) × C i \mathbf{X}_{i}^{g} \in \mathbb{R}^{\left(H / 2^{i+2}\right) \times\left(W / 2^{i+2}\right) \times C_{i}} Xig∈R(H/2i+2)×(W/2i+2)×Ci,具体为:
X i g = ConvT [ F MAttn [ Mixer [ Pool ( X i l ) ] ] L i ] , \mathbf{X}_{i}^{g}=\operatorname{ConvT}\left[\mathcal{F}_{\text {MAttn }\left[\operatorname{Mixer}\left[\operatorname{Pool}\left(\mathbf{X}_{i}^{l}\right)\right]\right]}^{L_{i}}\right], Xig=ConvT[FMAttn [Mixer[Pool(Xil)]]Li],
其中 F MAttn L i ( ⋅ ) \mathcal{F}_{\text {MAttn }}^{L_{i}}(\cdot) FMAttn Li(⋅)表示将 L i L_{i} Li个连续的MAttn块应用于输入。
在块的最后一部分,局部流特征 X i l \mathbf{X}_{i}^{l} Xil和全局流特征 X i g \mathbf{X}_{i}^{g} Xig被融合以得到一个新的特征图,如图2所示。为了融合这两个特征,我们首先使用从 X i g \mathbf{X}_{i}^{g} Xig生成的权重图来调制 X i l \mathbf{X}_{i}^{l} Xil。具体来说,我们计算 W i g ∈ R ( H / 2 i + 2 ) × ( W / 2 i + 2 ) × C i \mathbf{W}_{i}^{g} \in \mathbb{R}^{\left(H / 2^{i+2}\right) \times\left(W / 2^{i+2}\right) \times C_{i}} Wig∈R(H/2i+2)×(W/2i+2)×Ci,其计算方式为:
W i g = Sigmoid [ Proj ( X i g ) ] , \mathbf{W}_{i}^{g}=\operatorname{Sigmoid}\left[\operatorname{Proj}\left(\mathbf{X}_{i}^{g}\right)\right], Wig=Sigmoid[Proj(Xig)],
其中Proj表示逐点卷积后接批量归一化。然后,我们将它乘以 X i l \mathbf{X}_{i}^{l} Xil,并将结果图与 X i g \mathbf{X}_{i}^{g} Xig在通道维度上进行拼接,得到:
X i u = [ X i l ⊙ W i g , X i g ] \mathbf{X}_{i}^{u}=\left[\mathbf{X}_{i}^{l} \odot \mathbf{W}_{i}^{g}, \mathbf{X}_{i}^{g}\right] Xiu=[Xil⊙Wig,Xig]
其中 ⊙ \odot ⊙表示哈达玛乘积。最后,融合后的特征 X i u \mathbf{X}_{i}^{u} Xiu通过另一个投影块来减半通道数,从而得到该块的输出。
3.4、改进的注意力机制
上述的双流设计将弥补所提出的沙漏形注意力计算导致的局部信息损失。然而,由于注意力操作是在非常低分辨率(或等价于小尺寸)的特征图上进行的,注意力计算本身必然会丧失其表征能力。为了弥补这一损失,我们对Transformer的注意力机制进行了一些修改;请参见图2中的“MAttn”。
主要概念是利用CNN的标准计算元组作为注意力的输入,特别是使用 3 × 3 3 \times 3 3×3(深度可分离)卷积、GeLU激活函数和批量归一化。注意力的输入由查询(query)、键(key)和值(value)组成,我们将元组应用于值,因为它构成了注意力输出的基础。我们的目标是通过促进输入特征图中空间信息的聚合来增强表征能力,同时降低训练难度。为了抵消计算成本的增加,我们取消了应用于查询和键的独立线性变换,而是对所有三个组件应用相同的逐点卷积。
改进的注意力计算的细节如下。设 X ∈ R h × w × C i \mathbf{X} \in \mathbb{R}^{h \times w \times C_{i}} X∈Rh×w×Ci为注意力机制的输入,输出 X ′ ′ ∈ R h × w × C i \mathbf{X}^{\prime \prime} \in \mathbb{R}^{h \times w \times C_{i}} X′′∈Rh×w×Ci的计算方式为:
X ′ ′ = FFN ( X ′ ) + X ′ , \mathbf{X}^{\prime \prime}=\operatorname{FFN}\left(\mathbf{X}^{\prime}\right)+\mathbf{X}^{\prime}, X′′=FFN(X′)+X′,
其中FFN代表ViT中的前馈网络[12,51],而 X ′ \mathbf{X}^{\prime} X′定义为:
X ′ = Linear ( MHSA ( P W − Conv ( X ) ) ) + X , \mathbf{X}^{\prime}=\operatorname{Linear}(\operatorname{MHSA}(\mathrm{PW}-\operatorname{Conv}(\mathbf{X})))+\mathbf{X}, X′=Linear(MHSA(PW−Conv(X)))+X,
其中Linear是具有可学习权重的线性层, P W − C o n v \mathrm{PW}-Conv PW−Conv表示逐点卷积;MHSA定义为:
MHSA ( Y ) = Softmax ( Y ⋅ Y ⊤ d + b ⋅ 1 ⊤ ) ⋅ Y ′ \operatorname{MHSA}(\mathbf{Y})=\operatorname{Softmax}\left(\frac{\mathbf{Y} \cdot \mathbf{Y}^{\top}}{\sqrt{d}}+\mathbf{b} \cdot \mathbf{1}^{\top}\right) \cdot \mathbf{Y}^{\prime} MHSA(Y)=Softmax(dY⋅Y⊤+b⋅1⊤)⋅Y′
其中 d d d是查询和键中每个头的通道数; b ∈ R h w \mathbf{b} \in \mathbb{R}^{h w} b∈Rhw是一个可学习的偏置,用作位置编码[14,32]; 1 ∈ R h w \mathbf{1} \in \mathbb{R}^{h w} 1∈Rhw是一个全一向量; Y ′ \mathbf{Y}^{\prime} Y′定义为:
Y ′ = D W − Conv G ( B N ( Y ) ) + Y , \mathbf{Y}^{\prime}=\mathrm{DW}-\operatorname{Conv}_{\mathrm{G}}(\mathrm{BN}(\mathbf{Y}))+\mathbf{Y}, Y′=DW−ConvG(BN(Y))+Y,
其中DW-Conv G {}_{\mathrm{G}} G表示深度可分离卷积后接GeLU激活函数,BN表示与CNN中相同的批量归一化。
4、实验结果
我们进行了实验来评估SBCFormer的性能,并将其与在ImageNet1K[11]图像分类任务和COCO数据集[34]物体检测任务上的现有网络进行了比较。
4.1、实验设置
SBCFormer主要针对在单板计算机中常用的低端CPU进行优化。此外,我们还在边缘设备中常见的Intel CPU以及桌面PC中使用的GPU上评估了其性能。我们在实验中使用了以下三个处理器和平台。
-
一款在单板计算机Raspberry PI 4 model B上以1.5 GHz运行的ARM Cortex-A72处理器。尽管它被归类为低端处理器,但ARM Cortex-A72是一款四核64位处理器,支持ARM Neon指令集。我们使用32位的Raspberry Pi OS和PyTorch 1.6.0版本来运行网络。
-
一款在笔记本电脑和平板电脑等移动设备中常见的Intel Core i7-3520M处理器,运行频率为2.9 GHz。它是一款双核处理器,支持多种指令集,包括为向量和矩阵运算提供高性能支持的Intel高级向量扩展(AVX)和AVX2。我们使用Ubuntu 18.04.5 LTS和PyTorch 1.10.1版本来运行网络。
-
一款在配备Intel Xeon CPU E5-1650 v3的桌面PC上的GeForce RTX 2080Ti GPU。我们使用Ubuntu 18.04.6 LTS和PyTorch 1.10.1版本来运行网络。
我们使用PyTorch框架(版本1.10)和Timm库[61]来实现和测试所有网络。对于每个我们进行比较的现有网络,我们采用了作者提供的官方代码,但少数网络除外。我们遵循之前的研究[32,44]来测量处理单个输入图像所需的推理时间(即延迟)。具体来说,我们将批量大小设置为1,并记录每个平台上的时钟时间。为确保准确性,我们进行了300次推理,并报告了平均延迟时间(以秒为单位)。在测量过程中,我们终止了任何可能干扰结果的无关应用程序。所有计算均使用32位浮点数。由于我们的重点是推理速度而不是训练,因此我们在配备八个Nvidia 2080Ti GPU的GPU服务器上训练了所有网络,然后在每个平台上评估了它们的推理时间。
4.2、ImageNet-1K
我们首先在最标准的任务——ImageNet-1K的图像分类任务上评估了这些网络。
4.2.1、训练
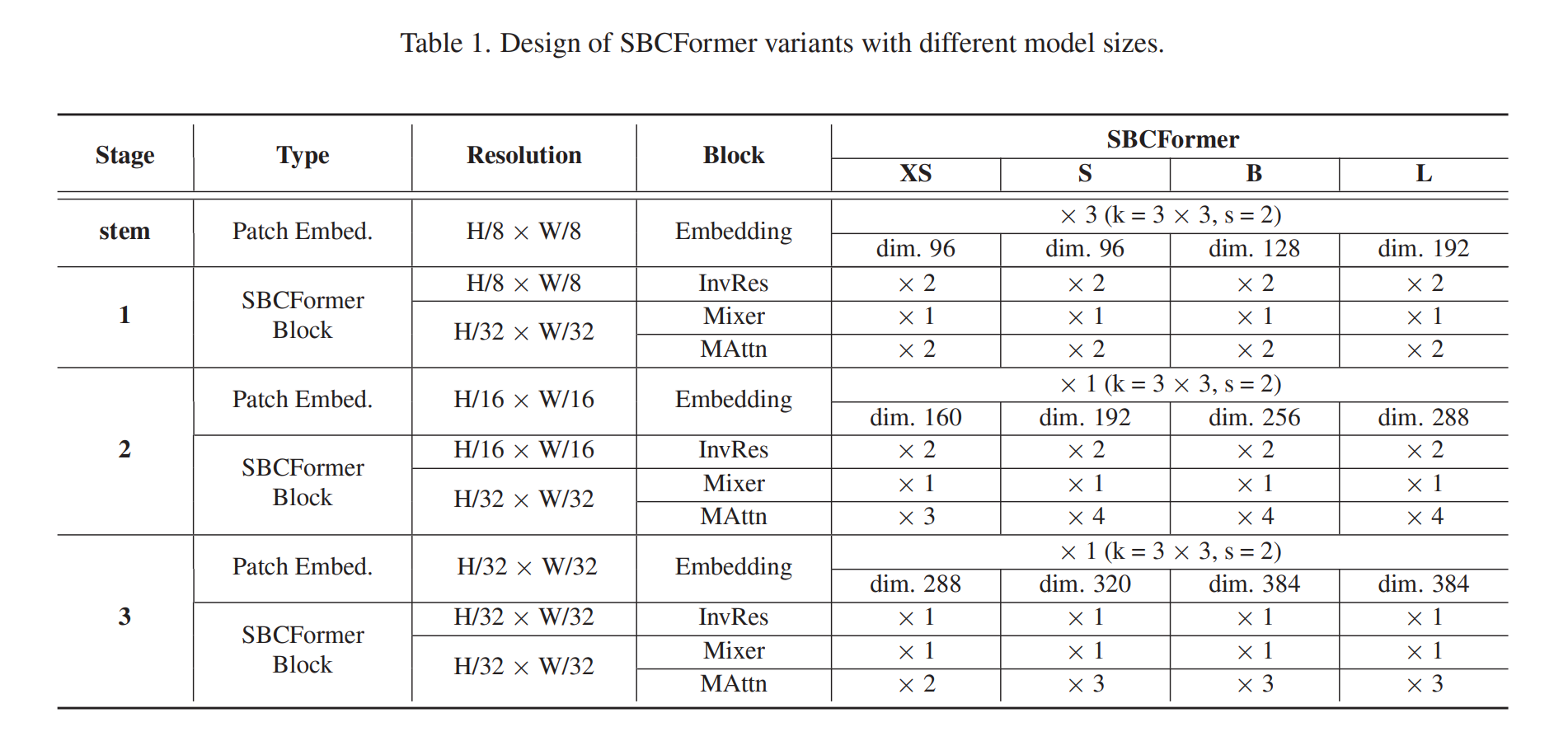
我们在ImageNet-1K数据集的训练集上从头开始训练SBCFormer和现有网络,共训练300个周期。该训练集包含1,000个类别共128万张图像。我们考虑了四种不同模型大小的变体,即SBCFormer-XS、-S、-B和-L,如表1所示。所有模型均以标准分辨率224×224进行训练和测试。
我们遵循原始作者的代码来训练现有网络。对于SBCFormer的训练,我们采用了DeiT[51]中的训练策略,总结如下。我们使用了带有余弦学习率调度[37]的AdamW优化器[38],并在前五个周期应用了线性预热。初始学习率设置为2.5×10⁻⁴,最小值设置为10⁻⁵。权重衰减和动量分别设置为5×10⁻²和0.9,批量大小为200。在训练过程中,我们采用了数据增强技术,包括随机裁剪、随机水平翻转、mixup、随机擦除和标签平滑,这些技术遵循了[44,51]中的做法。在训练过程中,我们对输入图像进行随机裁剪以获得224×224像素的图像大小,而在测试过程中则使用相同大小的单个中心裁剪。
4.2.2、结果
表2展示了不同模型大小的SBCFormer变体以及目前针对移动/边缘设备的轻量级网络(包括CNN、ViT变体以及CNN-ViT混合模型)的最新成果。
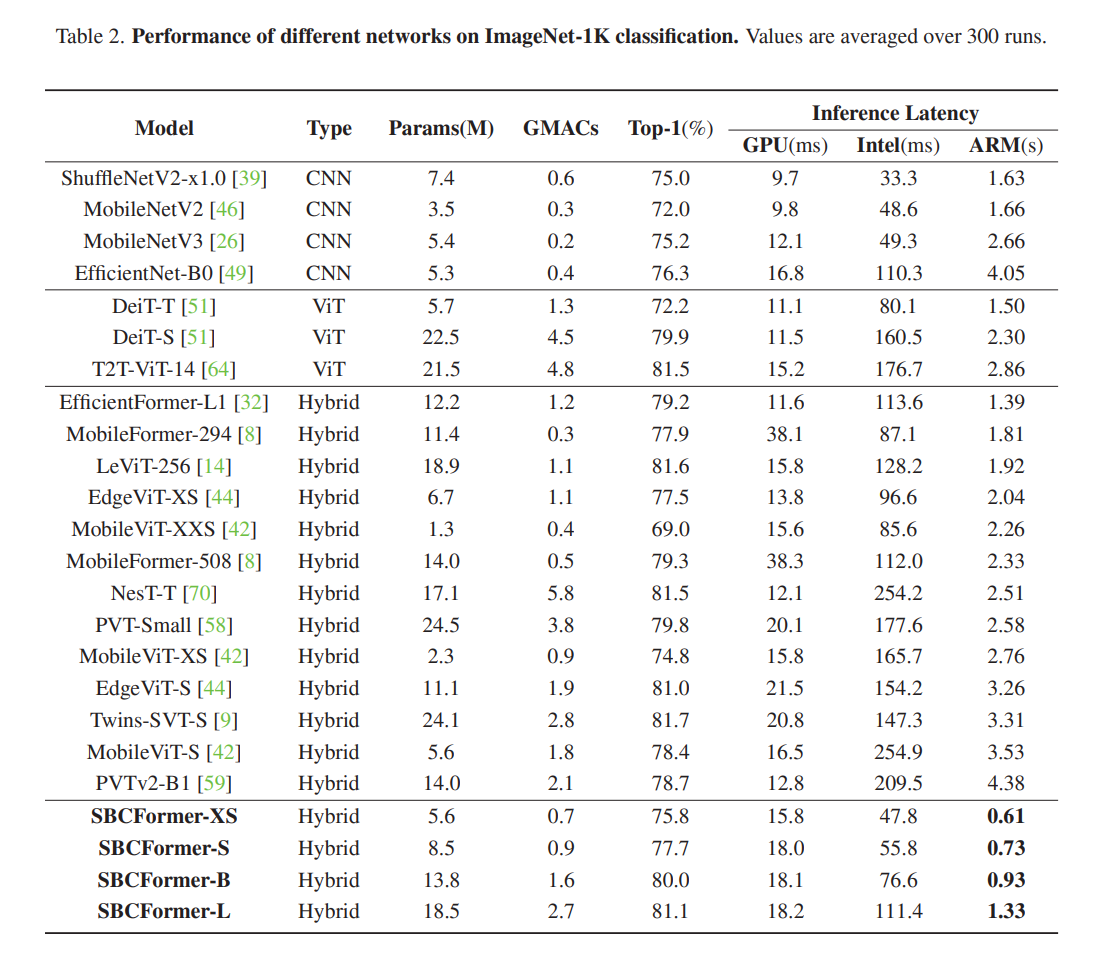
观察到,具有不同模型大小的SBCFormer变体在CPU上实现了更高的准确率和延迟之间的权衡;也请参见图1。SBCFormer与其他模型之间的性能差距在ARM CPU上比在Intel CPU上更为显著。值得注意的是,SBCFormer在GPU上仅实现了中等或较差的权衡。这些结果与我们的设计目标相一致,因为SBCFormer针对具有有限计算资源的CPU进行了优化,以实现更快的运行速度。
从图1中展示的CPU结果还可以得出以下额外观察。首先,流行的轻量级CNN,如MobileNetV2/V3 [26,46]、ShuffleNetV2 [39]和EfficientNet [49],在推理准确性方面往往不足。与最近的混合模型相比,它们以相同的速度水平获得了相对较低的准确性。这充分说明了在CPU上采用卷积的难度。
此外,一些为移动应用开发的ViT-CNN混合模型比具有相似推理准确性的CNN更慢。这样的混合模型包括MobileViT和EdgeViT。这有多种原因。首先,这些混合模型中的一些使用FLOPs和/或参数大小作为效率指标,这些指标并不一定对应于较低的延迟。其次,一些混合模型旨在用于最新款的智能手机,这些手机具有比我们实验中使用的更强大的CPU/NPU。这可能导致与先前研究相比看似不一致的发现。
4.2.3、消融测试
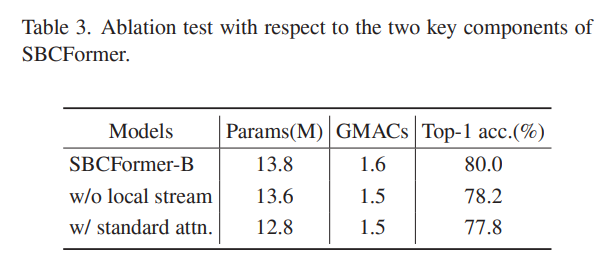
SBCFormer引入了两个新颖组件,即具有全局和局部流的块设计(第3.3节)和修改后的注意力机制(第3.4节)。为了评估它们的有效性,我们进行了消融测试。具体来说,我们选择了SBCFormer-B,并创建了两个消融模型。第一个是从所有SBCFormer块中移除局部流的SBCFormer,第二个是将修改后的注意力机制替换为标准Transformer注意力机制的模型。我们对所有模型进行了300个周期的训练。表3展示了结果,证实了这两个引入组件的有效性。
4.3、检测与分割
除了图像分类外,目标检测是最受欢迎的应用之一。因此,我们测试了SBCFormer在目标检测上的性能。具体来说,我们按照标准方法,将SBCFormer用作主干网络,并在其顶部放置特定于任务的架构来构建模型。
4.3.1、数据集与实验配置
我们使用COCO 2017数据集[34]进行评估。该数据集包含118,000张图像的训练集和5,000张图像的验证集。
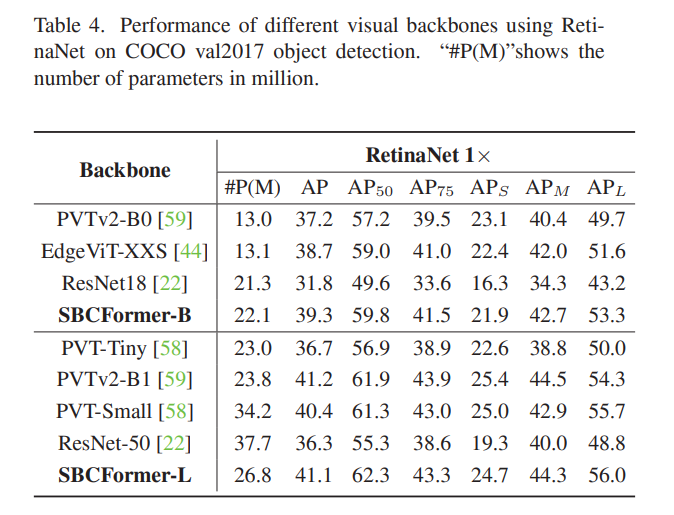
我们选择了目标检测的基本网络,即RetinaNet[33]。我们将几个主干网络集成到RetinaNet中。我们选择了SBC-Former-B和-L,并选择了一些具有大致相同模型大小的基线模型,这些基线模型来自PVT[58]、PVTv2[59]和ResNet18[22]。
我们在ImageNet-1K数据集上训练这些主干网络。对于使用不同主干网络的RetinaNet的训练,我们采用标准协议[9,44,59]。我们将图像调整为较短边为800像素,同时确保较长边小于1333像素。我们使用AdamW优化器[38],初始学习率为1×10⁻⁴,批量大小为16,训练模型12个周期。在测试时,我们将图像大小重新缩放为800×800。
4.3.2、结果
表4展示了结果。可以看出,使用SBCFormer作为主干网络的模型与基线模型相比,表现出相当或更好的性能。如图1和表2所示,PVT、PVTv2和ResNet18在推理速度上明显较慢,这可能会成为使用它们作为主干网络的检测器的瓶颈。
5、结论
我们提出了一种新的深度网络设计,称为SBCFormer,它在低端CPU上使用时,在推理准确性和计算速度之间实现了有利的平衡,这些CPU通常存在于单板计算机(SBCs)中。这些CPU执行大型矩阵乘法时效率不高,使得Transformer的注意力机制比CNN更具吸引力。然而,当应用于大型特征图时,注意力机制的计算成本很高。SBCFormer通过首先减小输入特征图的大小,对较小的特征图应用注意力,然后将其恢复到原始大小来减轻这种成本。但是,这种方法具有副作用,如局部图像信息的丢失和小尺寸注意力表示能力的限制。为了解决这些问题,我们引入了两个新颖的设计。首先,我们在注意力计算中添加了一个并行流,该流通过输入特征图,从而保留局部图像信息。其次,我们通过整合标准的CNN组件来增强注意力机制。我们的实验表明,SBCFormer在流行的SBC(配备ARM-Cortex A72 CPU的Raspberry-PI 4 Model B)上实现了准确性和速度之间的良好权衡。
局限性:在我们的实验中,我们选择了特定的处理器,即两款CPU和一款GPU,并在每个处理器上测量了延迟。尽管这些处理器在其类别中具有代表性,但使用其他处理器可能会得到不同的结果。此外,我们的主要指标是推理延迟。它可能因多种因素而异,包括代码优化、编译器、深度学习框架、操作系统等。因此,我们的实验结果可能无法在不同的环境中重现。
致谢
本研究得到了JSPS KAKENHI资助项目(编号:23H00482和20H05952)的部分支持。












![[中级]软考_软件设计_计算机组成与体系结构_03_CPU的组成(运算器与控制器)](https://img-blog.csdnimg.cn/direct/cbae4f56200b49f792a68194375dedb1.png)