Netty核心原理剖析与RPC实践11-15
11 另起炉灶:Netty 数据传输载体 ByteBuf 详解
在学习编解码章节的过程中,我们看到 Netty 大量使用了自己实现的 ByteBuf 工具类,ByteBuf 是 Netty 的数据容器,所有网络通信中字节流的传输都是通过 ByteBuf 完成的。然而 JDK NIO 包中已经提供了类似的 ByteBuffer 类,为什么 Netty 还要去重复造轮子呢?本节课我会详细地讲解 ByteBuf。
为什么选择 ByteBuf
我们首先介绍下 JDK NIO 的 ByteBuffer,才能知道 ByteBuffer 有哪些缺陷和痛点。下图展示了 ByteBuffer 的内部结构:

从图中可知,ByteBuffer 包含以下四个基本属性:
- mark:为某个读取过的关键位置做标记,方便回退到该位置;
- position:当前读取的位置;
- limit:buffer 中有效的数据长度大小;
- capacity:初始化时的空间容量。
以上四个基本属性的关系是:mark <= position <= limit <= capacity。结合 ByteBuffer 的基本属性,不难理解它在使用上的一些缺陷。
第一,ByteBuffer 分配的长度是固定的,无法动态扩缩容,所以很难控制需要分配多大的容量。如果分配太大容量,容易造成内存浪费;如果分配太小,存放太大的数据会抛出 BufferOverflowException 异常。在使用 ByteBuffer 时,为了避免容量不足问题,你必须每次在存放数据的时候对容量大小做校验,如果超出 ByteBuffer 最大容量,那么需要重新开辟一个更大容量的 ByteBuffer,将已有的数据迁移过去。整个过程相对烦琐,对开发者而言是非常不友好的。
第二,ByteBuffer 只能通过 position 获取当前可操作的位置,因为读写共用的 position 指针,所以需要频繁调用 flip、rewind 方法切换读写状态,开发者必须很小心处理 ByteBuffer 的数据读写,稍不留意就会出错。
ByteBuffer 作为网络通信中高频使用的数据载体,显然不能够满足 Netty 的需求,Netty 重新实现了一个性能更高、易用性更强的 ByteBuf,相比于 ByteBuffer 它提供了很多非常酷的特性:
- 容量可以按需动态扩展,类似于 StringBuffer;
- 读写采用了不同的指针,读写模式可以随意切换,不需要调用 flip 方法;
- 通过内置的复合缓冲类型可以实现零拷贝;
- 支持引用计数;
- 支持缓存池。
这里我们只是对 ByteBuf 有一个简单的了解,接下来我们就一起看下 ByteBuf 是如何实现的吧。
ByteBuf 内部结构
同样我们看下 ByteBuf 的内部结构,与 ByteBuffer 做一个对比。
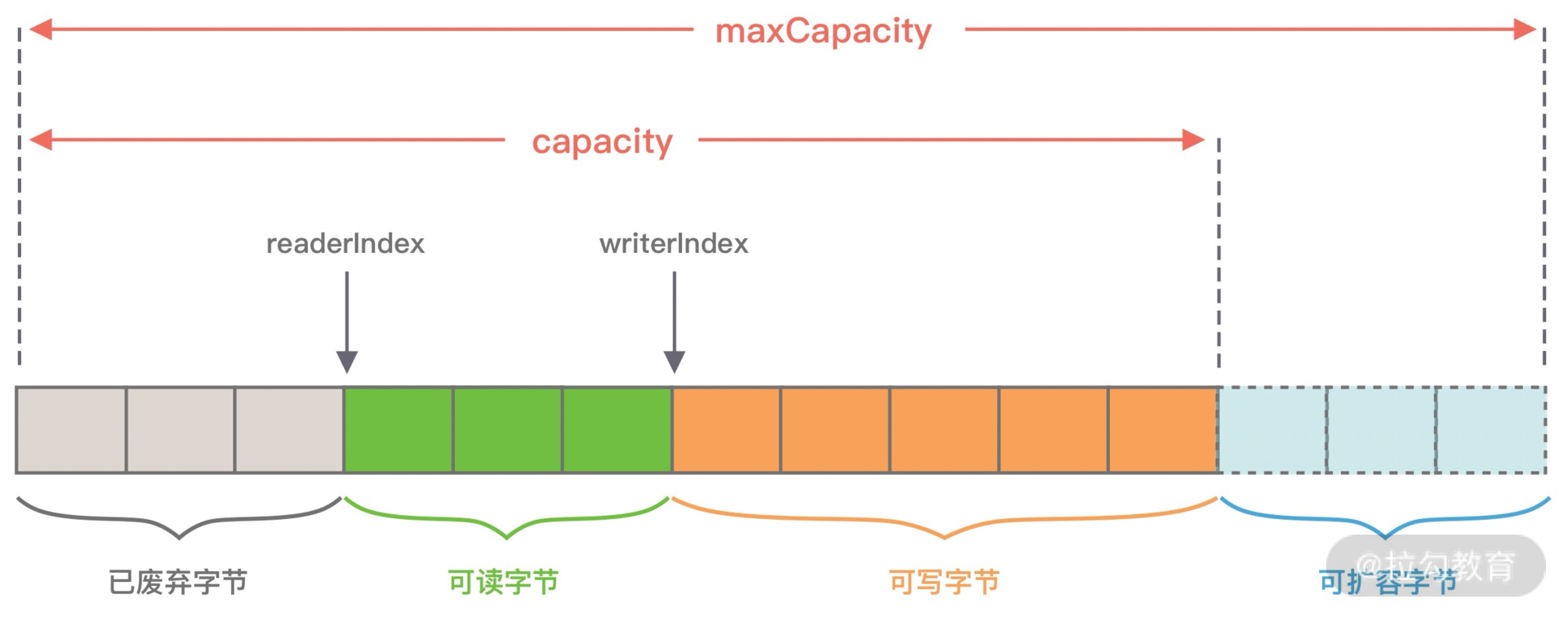
从图中可以看出,ByteBuf 包含三个指针:读指针 readerIndex、写指针 writeIndex、最大容量 maxCapacity,根据指针的位置又可以将 ByteBuf 内部结构可以分为四个部分:
第一部分是废弃字节,表示已经丢弃的无效字节数据。
第二部分是可读字节,表示 ByteBuf 中可以被读取的字节内容,可以通过 writeIndex - readerIndex 计算得出。从 ByteBuf 读取 N 个字节,readerIndex 就会自增 N,readerIndex 不会大于 writeIndex,当 readerIndex == writeIndex 时,表示 ByteBuf 已经不可读。
第三部分是可写字节,向 ByteBuf 中写入数据都会存储到可写字节区域。向 ByteBuf 写入 N 字节数据,writeIndex 就会自增 N,当 writeIndex 超过 capacity,表示 ByteBuf 容量不足,需要扩容。
第四部分是可扩容字节,表示 ByteBuf 最多还可以扩容多少字节,当 writeIndex 超过 capacity 时,会触发 ByteBuf 扩容,最多扩容到 maxCapacity 为止,超过 maxCapacity 再写入就会出错。
由此可见,Netty 重新设计的 ByteBuf 有效地区分了可读、可写以及可扩容数据,解决了 ByteBuffer 无法扩容以及读写模式切换烦琐的缺陷。接下来,我们一起学习下 ByteBuf 的核心 API,你可以把它当作 ByteBuffer 的替代品单独使用。
引用计数
ByteBuf 是基于引用计数设计的,它实现了 ReferenceCounted 接口,ByteBuf 的生命周期是由引用计数所管理。只要引用计数大于 0,表示 ByteBuf 还在被使用;当 ByteBuf 不再被其他对象所引用时,引用计数为 0,那么代表该对象可以被释放。
当新创建一个 ByteBuf 对象时,它的初始引用计数为 1,当 ByteBuf 调用 release() 后,引用计数减 1,所以不要误以为调用了 release() 就会保证 ByteBuf 对象一定会被回收。你可以结合以下的代码示例做验证:
ByteBuf buffer = ctx.alloc().directbuffer();
assert buffer.refCnt() == 1;
buffer.release();
assert buffer.refCnt() == 0;
引用计数对于 Netty 设计缓存池化有非常大的帮助,当引用计数为 0,该 ByteBuf 可以被放入到对象池中,避免每次使用 ByteBuf 都重复创建,对于实现高性能的内存管理有着很大的意义。
此外 Netty 可以利用引用计数的特点实现内存泄漏检测工具。JVM 并不知道 Netty 的引用计数是如何实现的,当 ByteBuf 对象不可达时,一样会被 GC 回收掉,但是如果此时 ByteBuf 的引用计数不为 0,那么该对象就不会释放或者被放入对象池,从而发生了内存泄漏。Netty 会对分配的 ByteBuf 进行抽样分析,检测 ByteBuf 是否已经不可达且引用计数大于 0,判定内存泄漏的位置并输出到日志中,你需要关注日志中 LEAK 关键字。
ByteBuf 分类
ByteBuf 有多种实现类,每种都有不同的特性,下图是 ByteBuf 的家族图谱,可以划分为三个不同的维度:Heap/Direct、Pooled/Unpooled和Unsafe/非 Unsafe,我逐一介绍这三个维度的不同特性。
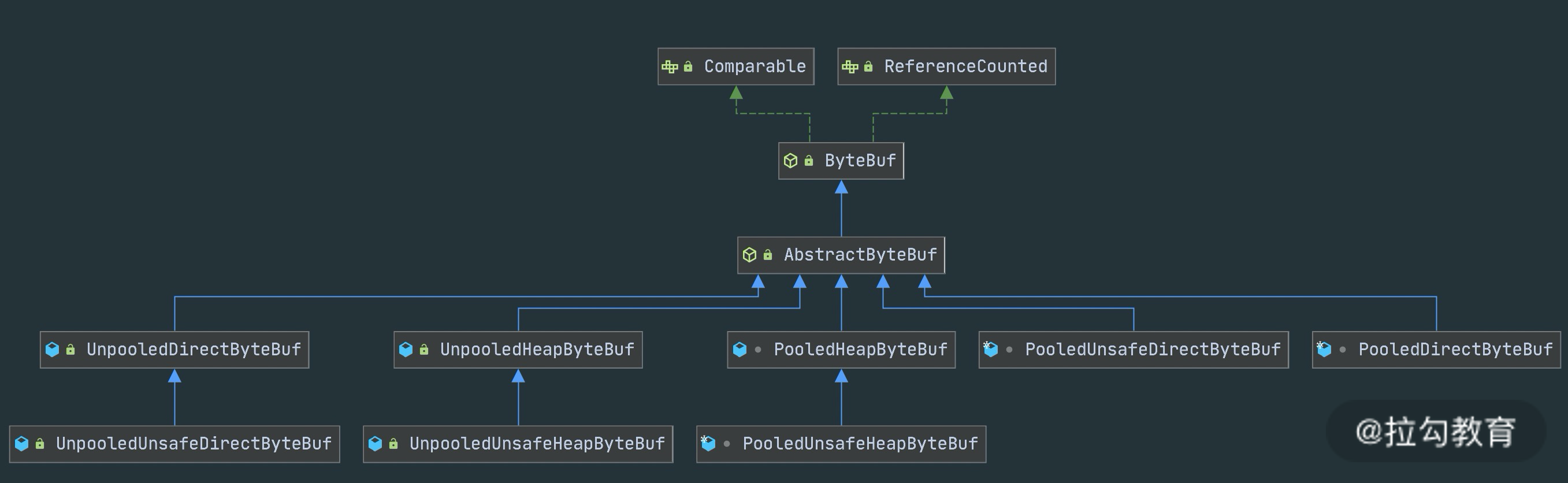
Heap/Direct 就是堆内和堆外内存。Heap 指的是在 JVM 堆内分配,底层依赖的是字节数据;Direct 则是堆外内存,不受 JVM 限制,分配方式依赖 JDK 底层的 ByteBuffer。
Pooled/Unpooled 表示池化还是非池化内存。Pooled 是从预先分配好的内存中取出,使用完可以放回 ByteBuf 内存池,等待下一次分配。而 Unpooled 是直接调用系统 API 去申请内存,确保能够被 JVM GC 管理回收。
Unsafe/非 Unsafe 的区别在于操作方式是否安全。 Unsafe 表示每次调用 JDK 的 Unsafe 对象操作物理内存,依赖 offset + index 的方式操作数据。非 Unsafe 则不需要依赖 JDK 的 Unsafe 对象,直接通过数组下标的方式操作数据。
ByteBuf 核心 API
我会分为指针操作、数据读写和内存管理三个方面介绍 ByteBuf 的核心 API。在开始讲解 API 的使用方法之前,先回顾下之前我们实现的自定义解码器,以便于加深对 ByteBuf API 的理解。
public final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {// 判断 ByteBuf 可读取字节if (in.readableBytes() < 14) { return;}in.markReaderIndex(); // 标记 ByteBuf 读指针位置in.skipBytes(2); // 跳过魔数in.skipBytes(1); // 跳过协议版本号byte serializeType = in.readByte();in.skipBytes(1); // 跳过报文类型in.skipBytes(1); // 跳过状态字段in.skipBytes(4); // 跳过保留字段int dataLength = in.readInt();if (in.readableBytes() < dataLength) {in.resetReaderIndex(); // 重置 ByteBuf 读指针位置return;}byte[] data = new byte[dataLength];in.readBytes(data);SerializeService serializeService = getSerializeServiceByType(serializeType);Object obj = serializeService.deserialize(data);if (obj != null) {out.add(obj);}
}
指针操作 API
- readerIndex() & writeIndex()
readerIndex() 返回的是当前的读指针的 readerIndex 位置,writeIndex() 返回的当前写指针 writeIndex 位置。
- markReaderIndex() & resetReaderIndex()
markReaderIndex() 用于保存 readerIndex 的位置,resetReaderIndex() 则将当前 readerIndex 重置为之前保存的位置。
这对 API 在实现协议解码时最为常用,例如在上述自定义解码器的源码中,在读取协议内容长度字段之前,先使用 markReaderIndex() 保存了 readerIndex 的位置,如果 ByteBuf 中可读字节数小于长度字段的值,则表示 ByteBuf 还没有一个完整的数据包,此时直接使用 resetReaderIndex() 重置 readerIndex 的位置。
此外对应的写指针操作还有 markWriterIndex() 和 resetWriterIndex(),与读指针的操作类似,我就不再一一赘述了。
数据读写 API
- isReadable()
isReadable() 用于判断 ByteBuf 是否可读,如果 writerIndex 大于 readerIndex,那么 ByteBuf 是可读的,否则是不可读状态。
- readableBytes()
readableBytes() 可以获取 ByteBuf 当前可读取的字节数,可以通过 writerIndex - readerIndex 计算得到。
- readBytes(byte[] dst) & writeBytes(byte[] src)
readBytes() 和 writeBytes() 是两个最为常用的方法。readBytes() 是将 ByteBuf 的数据读取相应的字节到字节数组 dst 中,readBytes() 经常结合 readableBytes() 一起使用,dst 字节数组的大小通常等于 readableBytes() 的大小。
- readByte() & writeByte(int value)
readByte() 是从 ByteBuf 中读取一个字节,相应的 readerIndex + 1;同理 writeByte 是向 ByteBuf 写入一个字节,相应的 writerIndex + 1。类似的 Netty 提供了 8 种基础数据类型的读取和写入,例如 readChar()、readShort()、readInt()、readLong()、writeChar()、writeShort()、writeInt()、writeLong() 等,在这里就不详细展开了。
- getByte(int index) & setByte(int index, int value)
与 readByte() 和 writeByte() 相对应的还有 getByte() 和 setByte(),get/set 系列方法也提供了 8 种基础类型的读写,那么这两个系列的方法有什么区别呢?read/write 方法在读写时会改变readerIndex 和 writerIndex 指针,而 get/set 方法则不会改变指针位置。
内存管理 API
- release() & retain()
之前已经介绍了引用计数的基本概念,每调用一次 release() 引用计数减 1,每调用一次 retain() 引用计数加 1。
- slice() & duplicate()
slice() 等同于 slice(buffer.readerIndex(), buffer.readableBytes()),默认截取 readerIndex 到 writerIndex 之间的数据,最大容量 maxCapacity 为原始 ByteBuf 的可读取字节数,底层分配的内存、引用计数都与原始的 ByteBuf 共享。
duplicate() 与 slice() 不同的是,duplicate()截取的是整个原始 ByteBuf 信息,底层分配的内存、引用计数也是共享的。如果向 duplicate() 分配出来的 ByteBuf 写入数据,那么都会影响到原始的 ByteBuf 底层数据。
- copy()
copy() 会从原始的 ByteBuf 中拷贝所有信息,所有数据都是独立的,向 copy() 分配的 ByteBuf 中写数据不会影响原始的 ByteBuf。
到底为止,ByteBuf 的核心 API 我们基本已经介绍完了,ByteBuf 读写指针分离的小设计,确实带来了很多实用和便利的功能,在开发的过程中不必再去想着 flip、rewind 这种头疼的操作了。
ByteBuf 实战演练
学习完 ByteBuf 的内部构造以及核心 API 之后,我们下面通过一个简单的示例演示一下 ByteBuf 应该如何使用,代码如下所示。
public class ByteBufTest {public static void main(String[] args) {ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(6, 10);printByteBufInfo("ByteBufAllocator.buffer(5, 10)", buffer);buffer.writeBytes(new byte[]{1, 2});printByteBufInfo("write 2 Bytes", buffer);buffer.writeInt(100);printByteBufInfo("write Int 100", buffer);buffer.writeBytes(new byte[]{3, 4, 5});printByteBufInfo("write 3 Bytes", buffer);byte[] read = new byte[buffer.readableBytes()];buffer.readBytes(read);printByteBufInfo("readBytes(" + buffer.readableBytes() + ")", buffer);printByteBufInfo("BeforeGetAndSet", buffer);System.out.println("getInt(2): " + buffer.getInt(2));buffer.setByte(1, 0);System.out.println("getByte(1): " + buffer.getByte(1));printByteBufInfo("AfterGetAndSet", buffer);}private static void printByteBufInfo(String step, ByteBuf buffer) {System.out.println("------" + step + "-----");System.out.println("readerIndex(): " + buffer.readerIndex());System.out.println("writerIndex(): " + buffer.writerIndex());System.out.println("isReadable(): " + buffer.isReadable());System.out.println("isWritable(): " + buffer.isWritable());System.out.println("readableBytes(): " + buffer.readableBytes());System.out.println("writableBytes(): " + buffer.writableBytes());System.out.println("maxWritableBytes(): " + buffer.maxWritableBytes());System.out.println("capacity(): " + buffer.capacity());System.out.println("maxCapacity(): " + buffer.maxCapacity());}
}
程序的输出结果在此我就不贴出了,建议你可以先尝试思考 readerIndex、writerIndex 是如何改变的,然后再动手跑下上述代码,验证结果是否正确。
结合代码示例,我们总结一下 ByteBuf API 使用时的注意点:
- write 系列方法会改变 writerIndex 位置,当 writerIndex 等于 capacity 的时候,Buffer 置为不可写状态;
- 向不可写 Buffer 写入数据时,Buffer 会尝试扩容,但是扩容后 capacity 最大不能超过 maxCapacity,如果写入的数据超过 maxCapacity,程序会直接抛出异常;
- read 系列方法会改变 readerIndex 位置,get/set 系列方法不会改变 readerIndex/writerIndex 位置。
总结
本节课我们介绍了 Netty 强大的数据容器 ByteBuf,它不仅解决了 JDK NIO 中 ByteBuffer 的缺陷,而且提供了易用性更强的接口。很多开发者已经使用 ByteBuf 代替 ByteBuffer,即便他没有在写一个网络应用,也会单独使用 ByteBuf。ByteBuf 作为 Netty 中最基础的数据结构,你必须熟练掌握它,这是你精通 Netty 的必经之路,接下来的课程我们会围绕 ByteBuf 介绍关于 Netty 内存管理的相关设计。
12 他山之石:高性能内存分配器 jemalloc 基本原理
在上节课,我们介绍了强大的 ByteBuf 工具类,ByteBuf 在 Netty 中随处可见,那么这些 ByteBuf 在 Netty 中是如何被分配和管理的呢?接下来的我们会对 Netty 高性能内存管理进行剖析,这些知识相比前面的章节有些晦涩难懂,你不必过于担心,Netty 内存管理的实现并不是一蹴而就的,它也是参考了 jemalloc 内存分配器。今天我们就先介绍 jemalloc 内存分配器的基本原理,为我们后面的课程打好基础。
背景知识
jemalloc 是由 Jason Evans 在 FreeBSD 项目中引入的新一代内存分配器。它是一个通用的 malloc 实现,侧重于减少内存碎片和提升高并发场景下内存的分配效率,其目标是能够替代 malloc。jemalloc 应用十分广泛,在 Firefox、Redis、Rust、Netty 等出名的产品或者编程语言中都有大量使用。具体细节可以参考 Jason Evans 发表的论文 [《A Scalable Concurrent malloc Implementation for FreeBSD》]
除了 jemalloc 之外,业界还有一些著名的内存分配器实现,例如 ptmalloc 和 tcmalloc。我们对这三种内存分配器做一个简单的对比:
ptmalloc 是基于 glibc 实现的内存分配器,它是一个标准实现,所以兼容性较好。pt 表示 per thread 的意思。当然 ptmalloc 确实在多线程的性能优化上下了很多功夫。由于过于考虑性能问题,多线程之间内存无法实现共享,只能每个线程都独立使用各自的内存,所以在内存开销上是有很大浪费的。
tcmalloc 出身于 Google,全称是 thread-caching malloc,所以 tcmalloc 最大的特点是带有线程缓存,tcmalloc 非常出名,目前在 Chrome、Safari 等知名产品中都有所应有。tcmalloc 为每个线程分配了一个局部缓存,对于小对象的分配,可以直接由线程局部缓存来完成,对于大对象的分配场景,tcmalloc 尝试采用自旋锁来减少多线程的锁竞争问题。
jemalloc 借鉴了 tcmalloc 优秀的设计思路,所以在架构设计方面两者有很多相似之处,同样都包含 thread cache 的特性。但是 jemalloc 在设计上比 ptmalloc 和 tcmalloc 都要复杂,jemalloc 将内存分配粒度划分为 Small、Large、Huge 三个分类,并记录了很多 meta 数据,所以在空间占用上要略多于 tcmalloc,不过在大内存分配的场景,jemalloc 的内存碎片要少于 tcmalloc。tcmalloc 内部采用红黑树管理内存块和分页,Huge 对象通过红黑树查找索引数据可以控制在指数级时间。
由此可见,虽然几个内存分配器的侧重点不同,但是它们的核心目标是一致的:
- 高效的内存分配和回收,提升单线程或者多线程场景下的性能。
- 减少内存碎片,包括内部碎片和外部碎片,提高内存的有效利用率。
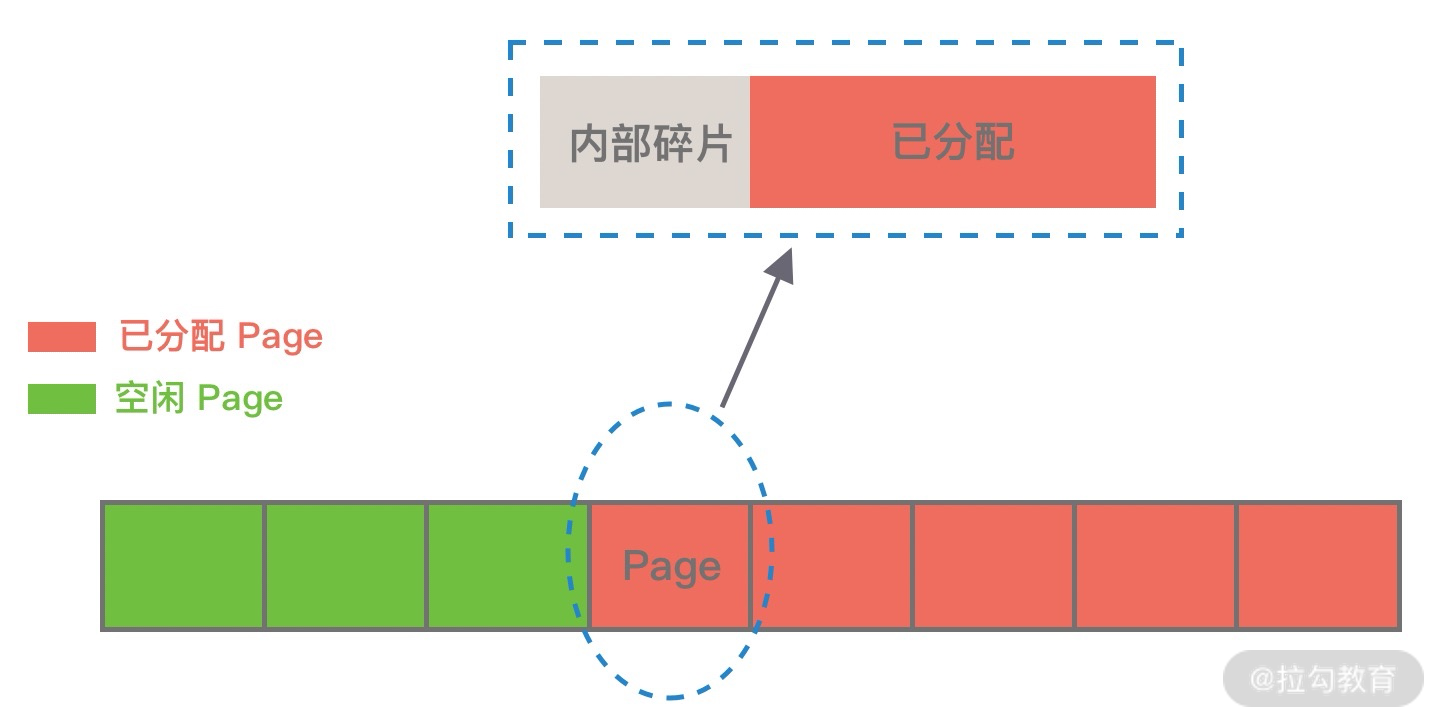
那么这里又涉及一个概念,什么是内存碎片呢?Linux 中物理内存会被划分成若干个 4K 大小的内存页 Page,物理内存的分配和回收都是基于 Page 完成的,Page 内产生的内存碎片称为内部碎片,Page 之间产生的内存碎片称为外部碎片。
首先讲下内部碎片,因为内存是按 Page 进行分配的,即便我们只需要很小的内存,操作系统至少也会分配 4K 大小的 Page,单个 Page 内只有一部分字节都被使用,剩余的字节形成了内部碎片,如下图所示。
外部碎片与内部碎片相反,是在分配较大内存块时产生的。我们试想一下,当需要分配大内存块的时候,操作系统只能通过分配连续的 Page 才能满足要求,在程序不断运行的过程中,这些 Page 被频繁的回收并重新分配,Page 之间就会出现小的空闲内存块,这样就形成了外部碎片,如下图所示。

上述我们介绍了内存分配器的一些背景知识,它们是操作系统以及高性能组件的必备神器,如果你对内存管理有兴趣,jemalloc 和 tcmalloc 都是非常推荐学习的。
常用内存分配器算法
在学习 jemalloc 的实现原理之前,我们先了解下最常用的内存分配器算法:动态内存分配、伙伴算法和Slab 算法,这将对于我们理解 jemalloc 大有裨益。
动态内存分配
动态内存分配(Dynamic memory allocation)又称为堆内存分配,后面简称 DMA,操作系统根据程序运行过程中的需求即时分配内存,且分配的内存大小就是程序需求的大小。在大部分场景下,只有在程序运行的时候才知道所需要分配的内存大小,如果提前分配可能会分配的大小无法把控,分配太大会浪费空间,分配太小会无法使用。
DMA 是从一整块内存中按需分配,对于分配出的内存会记录元数据,同时还会使用空闲分区链维护空闲内存,便于在内存分配时查找可用的空闲分区,常用的有三种查找策略:
第一种是⾸次适应算法(first fit),空闲分区链以地址递增的顺序将空闲分区以双向链表的形式连接在一起,从空闲分区链中找到第一个满足分配条件的空闲分区,然后从空闲分区中划分出一块可用内存给请求进程,剩余的空闲分区仍然保留在空闲分区链中。如下图所示,P1 和 P2 的请求可以在内存块 A 中完成分配。该算法每次都从低地址开始查找,造成低地址部分会不断被分配,同时也会产生很多小的空闲分区。
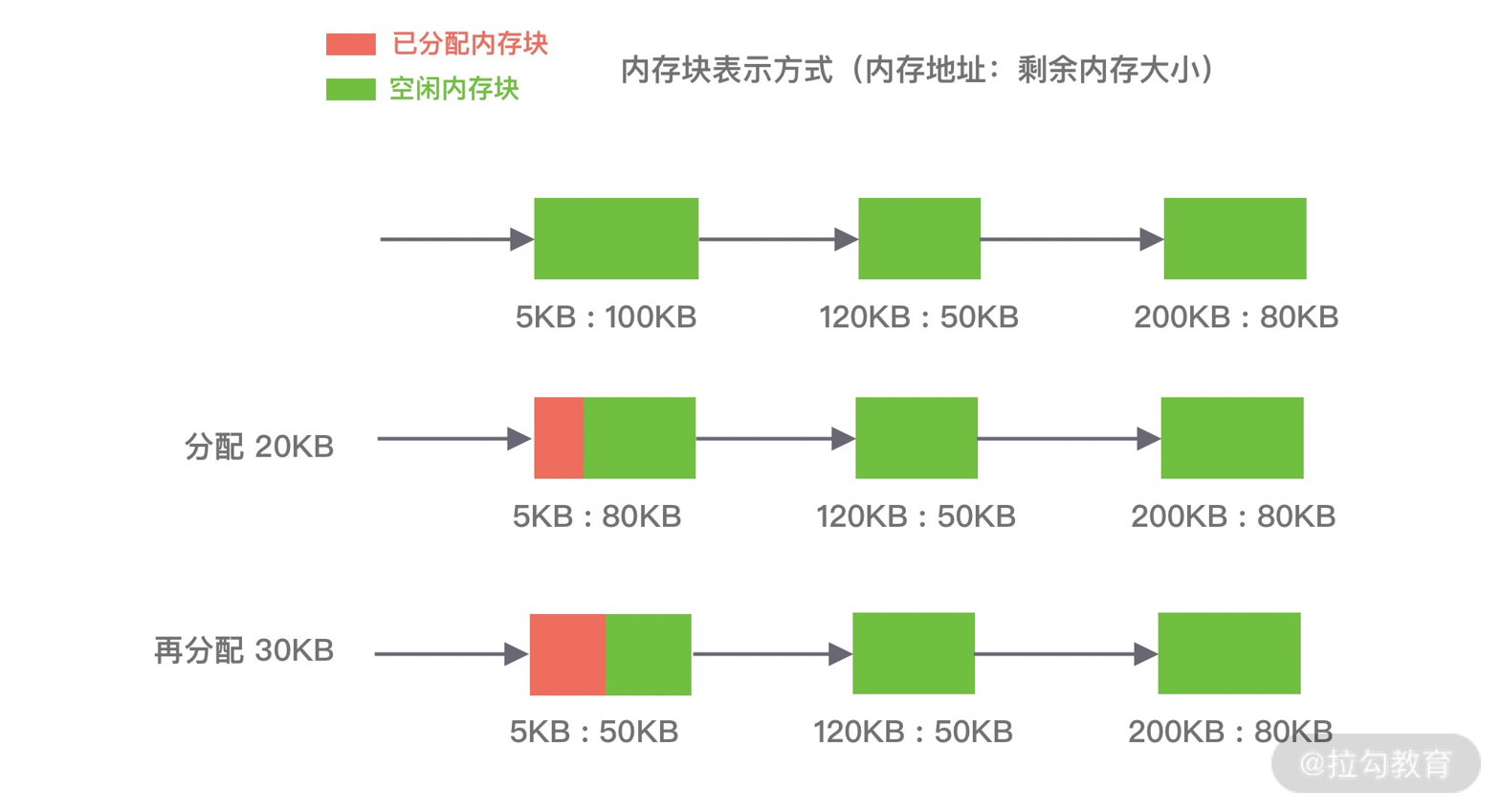
第二种是循环首次适应算法(next fit),该算法是由首次适应算法的变种,循环首次适应算法不再是每次从链表的开始进行查找,而是从上次找到的空闲分区的下⼀个空闲分区开始查找。如下图所示,P1 请求在内存块 A 完成分配,然后再为 P2 分配内存时,是直接继续向下寻找可用分区,最终在 B 内存块中完成分配。该算法相比⾸次适应算法空闲分区的分布更加均匀,而且查找的效率有所提升,但是正因为如此会造成空闲分区链中大的空闲分区会越来越少。
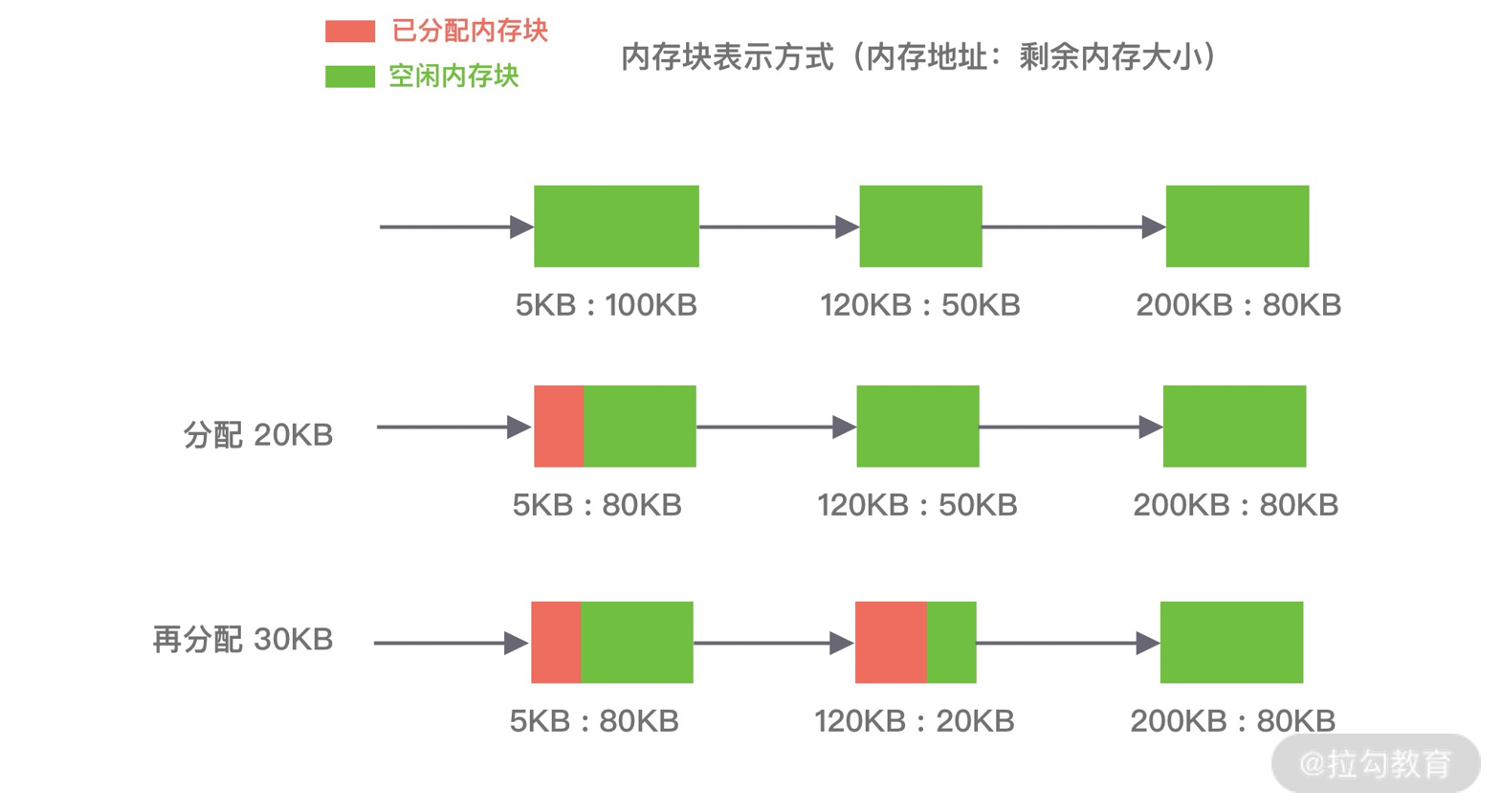
第三种是最佳适应算法(best fit),空闲分区链以空闲分区大小递增的顺序将空闲分区以双向链表的形式连接在一起,每次从空闲分区链的开头进行查找,这样第一个满足分配条件的空间分区就是最优解。如下图所示,在 A 内存块分配完 P1 请求后,空闲分区链重新按分区大小进行排序,再为 P2 请求查找满足条件的空闲分区。该算法的空间利用率更高,但同样也会留下很多较难利用的小空闲分区,由于每次分配完需要重新排序,所以会有造成性能损耗。
伙伴算法
伙伴算法是一种非常经典的内存分配算法,它采用了分离适配的设计思想,将物理内存按照 2 的次幂进行划分,内存分配时也是按照 2 的次幂大小进行按需分配,例如 4KB、 8KB、16KB 等。假设我们请求分配的内存大小为 10KB,那么会按照 16KB 分配。
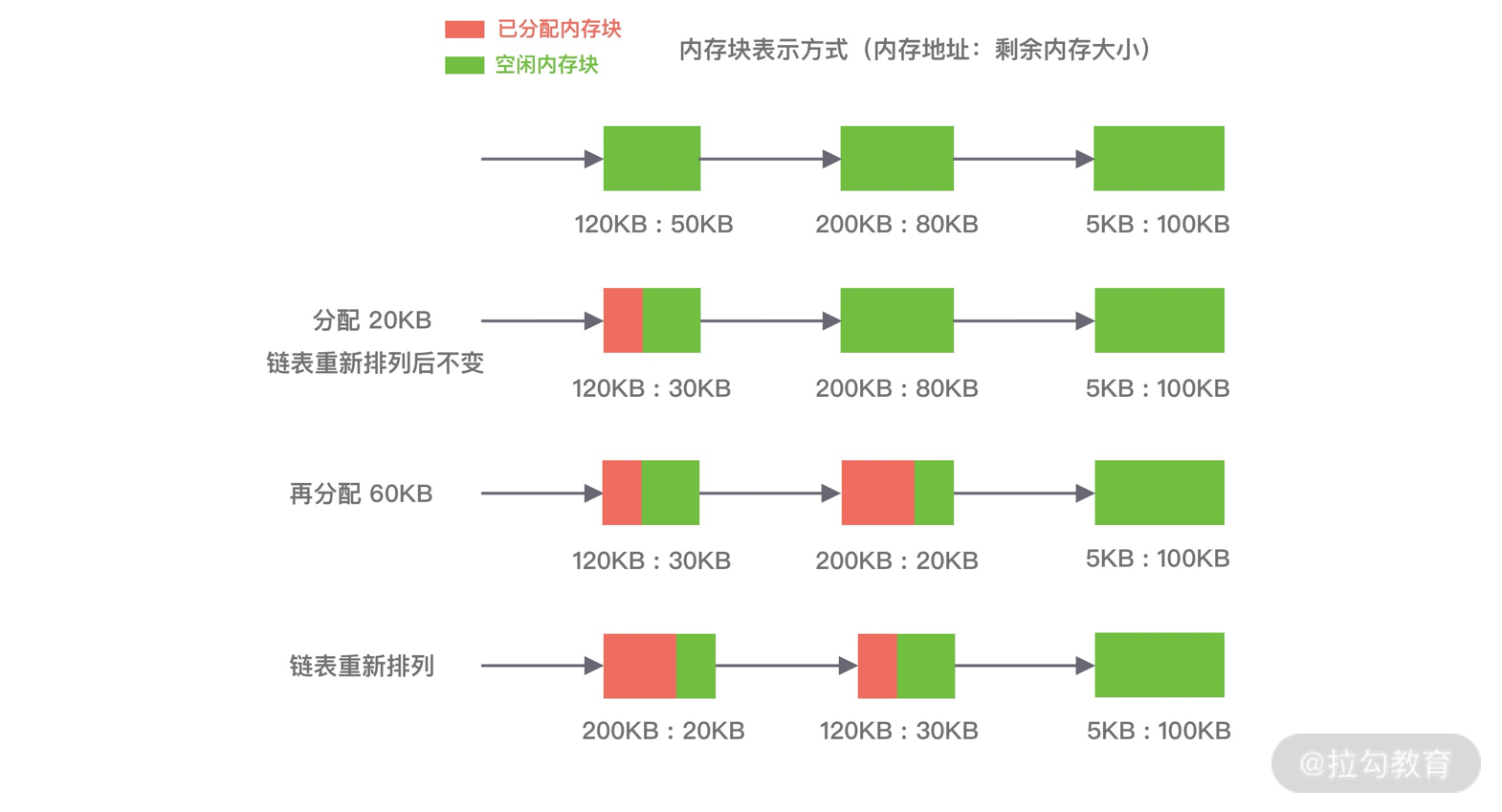
伙伴算法相对比较复杂,我们结合下面这张图来讲解它的分配原理。
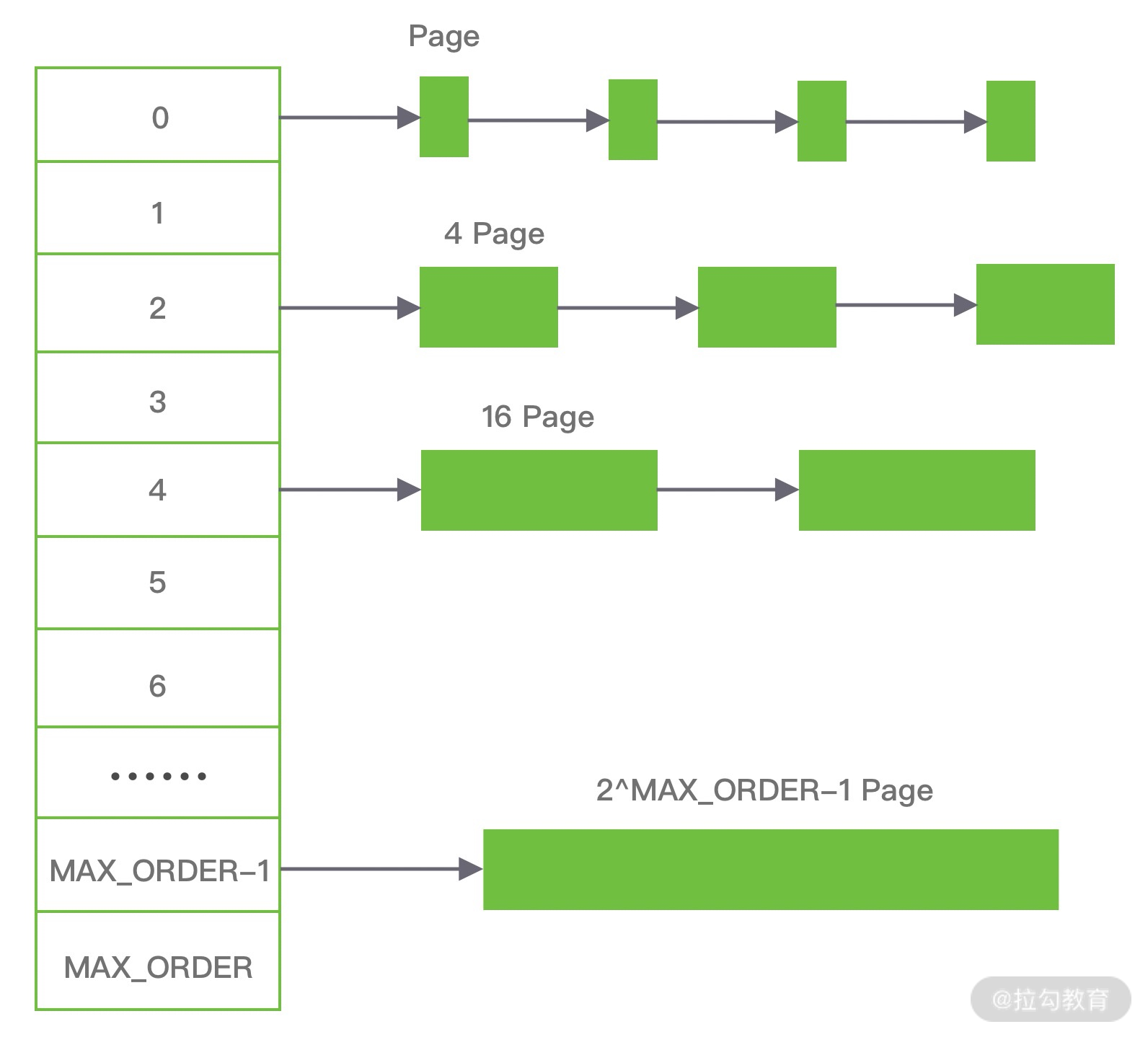
伙伴算法把内存划分为 11 组不同的 2 次幂大小的内存块集合,每组内存块集合都用双向链表连接。链表中每个节点的内存块大小分别为 1、2、4、8、16、32、64、128、256、512 和 1024 个连续的 Page,例如第一组链表的节点为 2^0 个连续 Page,第二组链表的节点为 2^1 个连续 Page,以此类推。
假设我们需要分配 10K 大小的内存块,看下伙伴算法的具体分配过程:
- 首先需要找到存储 2^4 连续 Page 所对应的链表,即数组下标为 4;
- 查找 2^4 链表中是否有空闲的内存块,如果有则分配成功;
- 如果 2^4 链表不存在空闲的内存块,则继续沿数组向上查找,即定位到数组下标为 5 的链表,链表中每个节点存储 2^5 的连续 Page;
- 如果 2^5 链表中存在空闲的内存块,则取出该内存块并将它分割为 2 个 2^4 大小的内存块,其中一块分配给进程使用,剩余的一块链接到 2^4 链表中。
以上是伙伴算法的分配过程,那么释放内存时候伙伴算法又会发生什么行为呢?当进程使用完内存归还时,需要检查其伙伴块的内存是否释放,所谓伙伴块是不仅大小相同,而且两个块的地址是连续的,其中低地址的内存块起始地址必须为 2 的整数次幂。如果伙伴块是空闲的,那么就会将两个内存块合并成更大的块,然后重复执行上述伙伴块的检查机制。直至伙伴块是非空闲状态,那么就会将该内存块按照实际大小归还到对应的链表中。频繁的合并会造成 CPU 浪费,所以并不是每次释放都会触发合并操作,当链表中的内存块个数小于某个阈值时,并不会触发合并操作。
由此可见,伙伴算法有效地减少了外部碎片,但是有可能会造成非常严重的内部碎片,最严重的情况会带来 50% 的内存碎片。
Slab 算法
因为伙伴算法都是以 Page 为最小管理单位,在小内存的分配场景,伙伴算法并不适用,如果每次都分配一个 Page 岂不是非常浪费内存,因此 Slab 算法应运而生了。Slab 算法在伙伴算法的基础上,对小内存的场景专门做了优化,采用了内存池的方案,解决内部碎片问题。
Linux 内核使用的就是 Slab 算法,因为内核需要频繁地分配小内存,所以 Slab 算法提供了一种高速缓存机制,使用缓存存储内核对象,当内核需要分配内存时,基本上可以通过缓存中获取。此外 Slab 算法还可以支持通用对象的初始化操作,避免对象重复初始化的开销。下图是 Slab 算法的结构图,Slab 算法实现起来非常复杂,本文只做一个简单的了解。
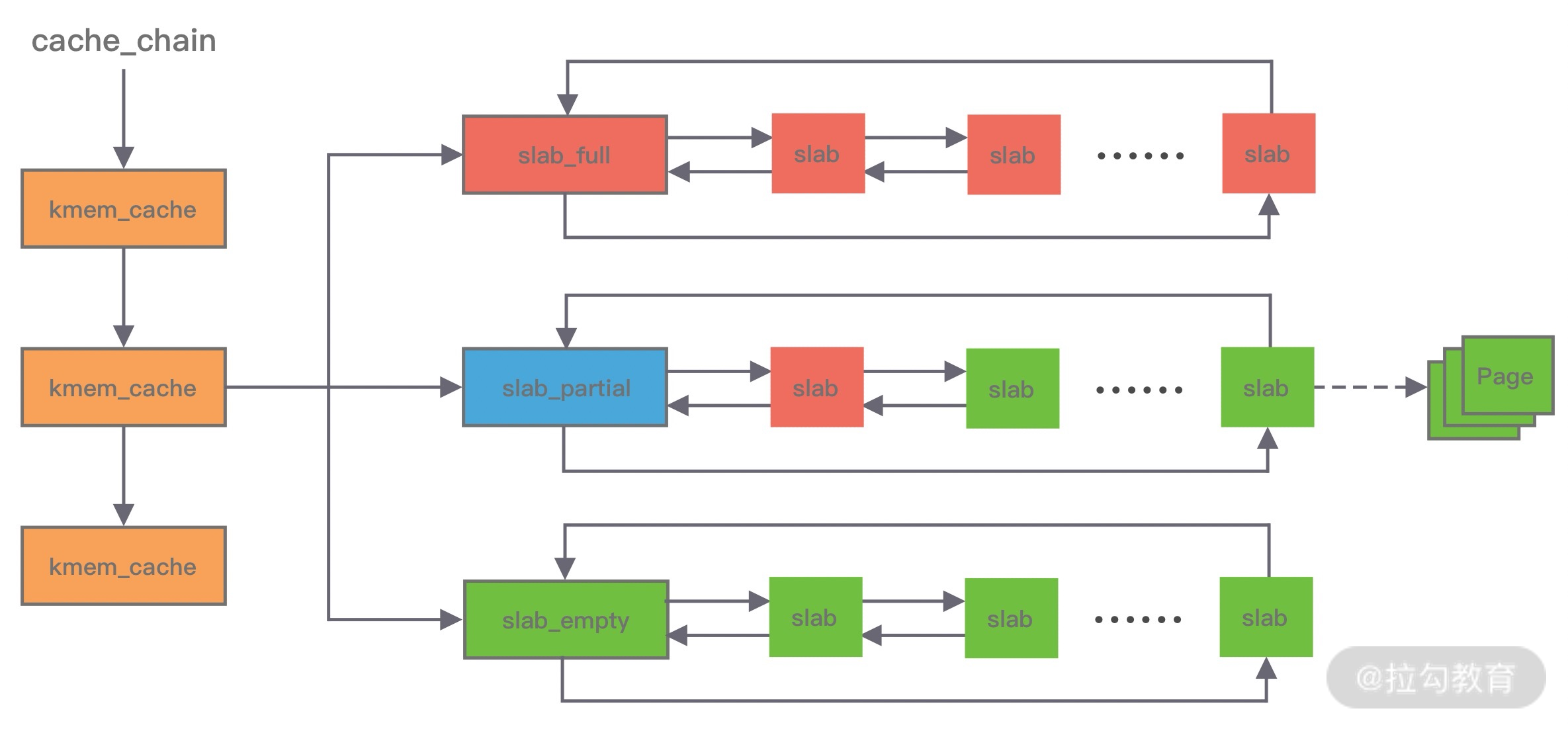
在 Slab 算法中维护着大小不同的 Slab 集合,在最顶层是 cache_chain,cache_chain 中维护着一组 kmem_cache 引用,kmem_cache 负责管理一块固定大小的对象池。通常会提前分配一块内存,然后将这块内存划分为大小相同的 slot,不会对内存块再进行合并,同时使用位图 bitmap 记录每个 slot 的使用情况。
kmem_cache 中包含三个 Slab 链表:完全分配使用 slab_full、部分分配使用 slab_partial和完全空闲 slabs_empty,这三个链表负责内存的分配和释放。每个链表中维护的 Slab 都是一个或多个连续 Page,每个 Slab 被分配多个对象进行存储。Slab 算法是基于对象进行内存管理的,它把相同类型的对象分为一类。当分配内存时,从 Slab 链表中划分相应的内存单元;当释放内存时,Slab 算法并不会丢弃已经分配的对象,而是将它保存在缓存中,当下次再为对象分配内存时,直接会使用最近释放的内存块。
单个 Slab 可以在不同的链表之间移动,例如当一个 Slab 被分配完,就会从 slab_partial 移动到 slabs_full,当一个 Slab 中有对象被释放后,就会从 slab_full 再次回到 slab_partial,所有对象都被释放完的话,就会从 slab_partial 移动到 slab_empty。
至此,三种最常用的内存分配算法已经介绍完了,优秀的内存分配算法都是在性能和内存利用率之间寻找平衡点,我们今天的主角 jemalloc 就是非常典型的例子。
jemalloc 架构设计
在了解了常用的内存分配算法之后,再理解 jemalloc 的架构设计会相对轻松一些。下图是 jemalloc 的架构图,我们一起学习下它的核心设计理念。
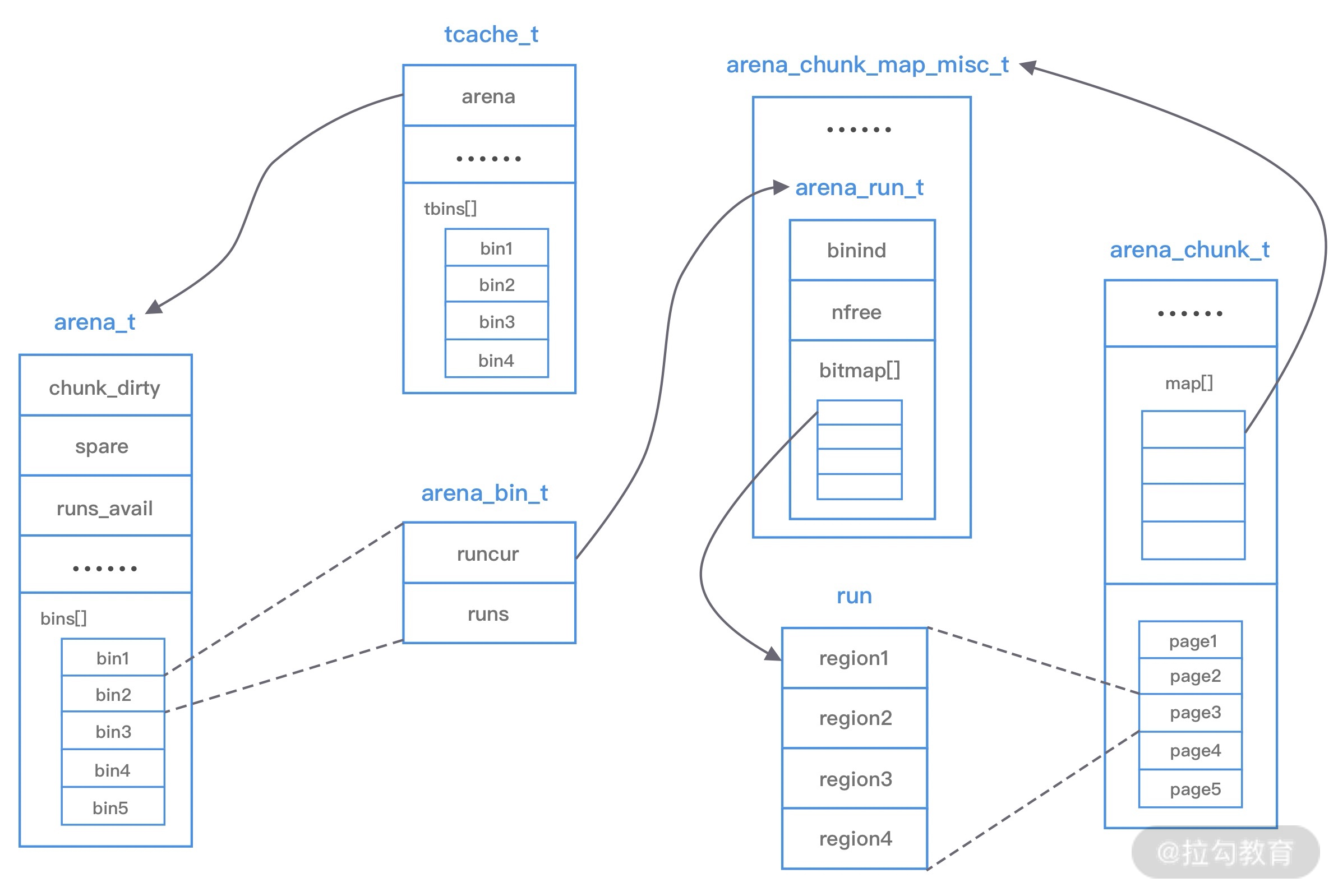
上图中涉及 jemalloc 的几个核心概念,例如 arena、bin、chunk、run、region、tcache 等,我们下面逐一进行介绍。
arena 是 jemalloc 最重要的部分,内存由一定数量的 arenas 负责管理。每个用户线程都会被绑定到一个 arena 上,线程采用 round-robin 轮询的方式选择可用的 arena 进行内存分配,为了减少线程之间的锁竞争,默认每个 CPU 会分配 4 个 arena。
bin 用于管理不同档位的内存单元,每个 bin 管理的内存大小是按分类依次递增。因为 jemalloc 中小内存的分配是基于 Slab 算法完成的,所以会产生不同类别的内存块。
chunk 是负责管理用户内存块的数据结构,chunk 以 Page 为单位管理内存,默认大小是 4M,即 1024 个连续 Page。每个 chunk 可被用于多次小内存的申请,但是在大内存分配的场景下只能分配一次。
run 实际上是 chunk 中的一块内存区域,每个 bin 管理相同类型的 run,最终通过操作 run 完成内存分配。run 结构具体的大小由不同的 bin 决定,例如 8 字节的 bin 对应的 run 只有一个 Page,可以从中选取 8 字节的块进行分配。
region 是每个 run 中的对应的若干个小内存块,每个 run 会将划分为若干个等长的 region,每次内存分配也是按照 region 进行分发。
tcache 是每个线程私有的缓存,用于 small 和 large 场景下的内存分配,每个 tcahe 会对应一个 arena,tcache 本身也会有一个 bin 数组,称为tbin。与 arena 中 bin 不同的是,它不会有 run 的概念。tcache 每次从 arena 申请一批内存,在分配内存时首先在 tcache 查找,从而避免锁竞争,如果分配失败才会通过 run 执行内存分配。
jemalloc 的几个核心的概念介绍完了,我们再重新梳理下它们之间的关系:
- 内存是由一定数量的 arenas 负责管理,线程均匀分布在 arenas 当中;
- 每个 arena 都包含一个 bin 数组,每个 bin 管理不同档位的内存块;
- 每个 arena 被划分为若干个 chunks,每个 chunk 又包含若干个 runs,每个 run 由连续的 Page 组成,run 才是实际分配内存的操作对象;
- 每个 run 会被划分为一定数量的 regions,在小内存的分配场景,region 相当于用户内存;
- 每个 tcache 对应 一个 arena,tcache 中包含多种类型的 bin。
接下来我们分析下 jemalloc 的整体内存分配和释放流程,主要分为 Samll、Large 和 Huge 三种场景。
首先讲下 Samll 场景,如果请求分配内存的大小小于 arena 中的最小的 bin,那么优先从线程中对应的 tcache 中进行分配。首先确定查找对应的 tbin 中是否存在缓存的内存块,如果存在则分配成功,否则找到 tbin 对应的 arena,从 arena 中对应的 bin 中分配 region 保存在 tbin 的 avail 数组中,最终从 availl 数组中选取一个地址进行内存分配,当内存释放时也会将被回收的内存块进行缓存。
Large 场景的内存分配与 Samll 类似,如果请求分配内存的大小大于 arena 中的最小的 bin,但是不大于 tcache 中能够缓存的最大块,依然会通过 tcache 进行分配,但是不同的是此时会分配 chunk 以及所对应的 run,从 chunk 中找到相应的内存空间进行分配。内存释放时也跟 samll 场景类似,会把释放的内存块缓存在 tacache 的 tbin 中。此外还有一种情况,当请求分配内存的大小大于tcache 中能够缓存的最大块,但是不大于 chunk 的大小,那么将不会采用 tcache 机制,直接在 chunk 中进行内存分配。
Huge 场景,如果请求分配内存的大小大于 chunk 的大小,那么直接通过 mmap 进行分配,调用 munmap 进行回收。
到底为止,jemalloc 的基础知识介绍完毕,你需要花点时间消化它,这对于后面学习 Netty 的内存管理很有帮助。
总结
内存管理是每个高阶程序员的必备知识,万变不离其宗,jemalloc 的思想在很多场景都非常适用,在 Redis、Netty 等知名的高性能组件中都有它的原型,你会发现它们的实现思路都是类似的,申请大块内存,避免“细水长流”。趁热打铁吧,下节课我们将继续学习 Netty 是如何设计高性能的内存管理的。
13 举一反三:Netty 高性能内存管理设计(上)
Netty 作为一款高性能的网络框架,需要处理海量的字节数据,而且 Netty 默认提供了池化对象的内存分配,使用完后归还到内存池,所以一套高性能的内存管理机制是 Netty 必不可少的。在上节课中我们介绍了原生 jemalloc 的基本原理,而 Netty 高性能的内存管理也是借鉴 jemalloc 实现的,它同样需要解决两个经典的核心问题:
- 在单线程或者多线程的场景下,如何高效地进行内存分配和回收?
- 如何减少内存碎片,提高内存的有效利用率?
我们同样带着这两个经典问题开始 Netty 内存管理的课程学习。
内存规格介绍
Netty 保留了内存规格分类的设计理念,不同大小的内存块采用的分配策略是不同的,具体内存规格的分类情况如下图所示。

上图中 Tiny 代表 0 ~ 512B 之间的内存块,Samll 代表 512B ~ 8K 之间的内存块,Normal 代表 8K ~ 16M 的内存块,Huge 代表大于 16M 的内存块。在 Netty 中定义了一个 SizeClass 类型的枚举,用于描述上图中的内存规格类型,分别为 Tiny、Small 和 Normal。但是图中 Huge 并未在代码中定义,当分配大于 16M 时,可以归类为 Huge 场景,Netty 会直接使用非池化的方式进行内存分配。
Netty 在每个区域内又定义了更细粒度的内存分配单位,分别为 Chunk、Page、Subpage,我们将逐一对其进行介绍。
Chunk 是 Netty 向操作系统申请内存的单位,所有的内存分配操作也是基于 Chunk 完成的,Chunk 可以理解为 Page 的集合,每个 Chunk 默认大小为 16M。
Page 是 Chunk 用于管理内存的单位,Netty 中的 Page 的大小为 8K,不要与 Linux 中的内存页 Page 相混淆了。假如我们需要分配 64K 的内存,需要在 Chunk 中选取 8 个 Page 进行分配。
Subpage 负责 Page 内的内存分配,假如我们分配的内存大小远小于 Page,直接分配一个 Page 会造成严重的内存浪费,所以需要将 Page 划分为多个相同的子块进行分配,这里的子块就相当于 Subpage。按照 Tiny 和 Small 两种内存规格,SubPage 的大小也会分为两种情况。在 Tiny 场景下,最小的划分单位为 16B,按 16B 依次递增,16B、32B、48B … 496B;在 Small 场景下,总共可以划分为 512B、1024B、2048B、4096B 四种情况。Subpage 没有固定的大小,需要根据用户分配的缓冲区大小决定,例如分配 1K 的内存时,Netty 会把一个 Page 等分为 8 个 1K 的 Subpage。
了解了 Netty 不同粒度的内存的分配单位后,我们接下来看看 Netty 中的 jemalloc 是如何实现的。
Netty 内存池架构设计
Netty 中的内存池可以看作一个 Java 版本的 jemalloc 实现,并结合 JVM 的诸多特性做了部分优化。如下图所示,我们首先从全局视角看下 Netty 内存池的整体布局,对它有一个宏观的认识。
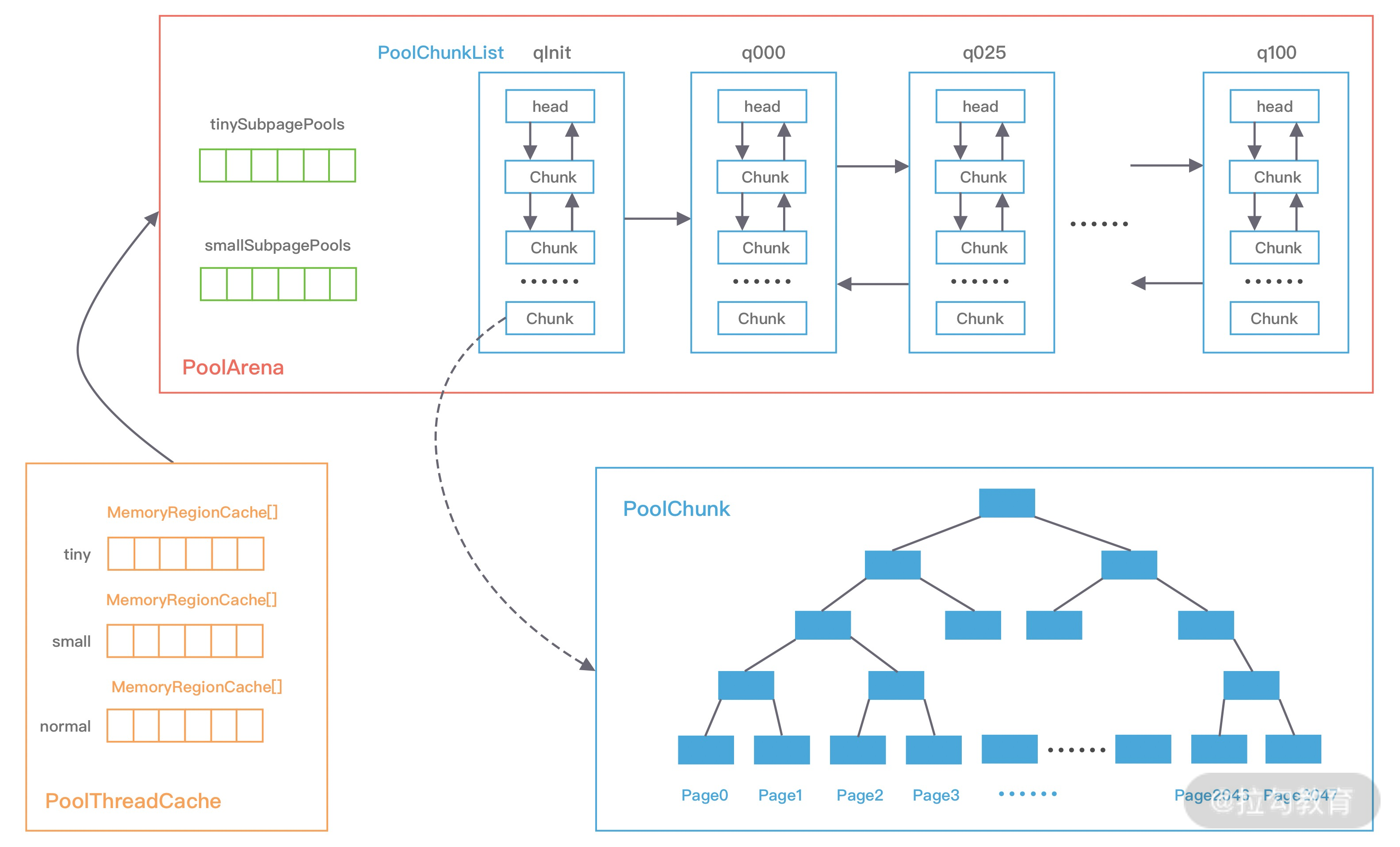
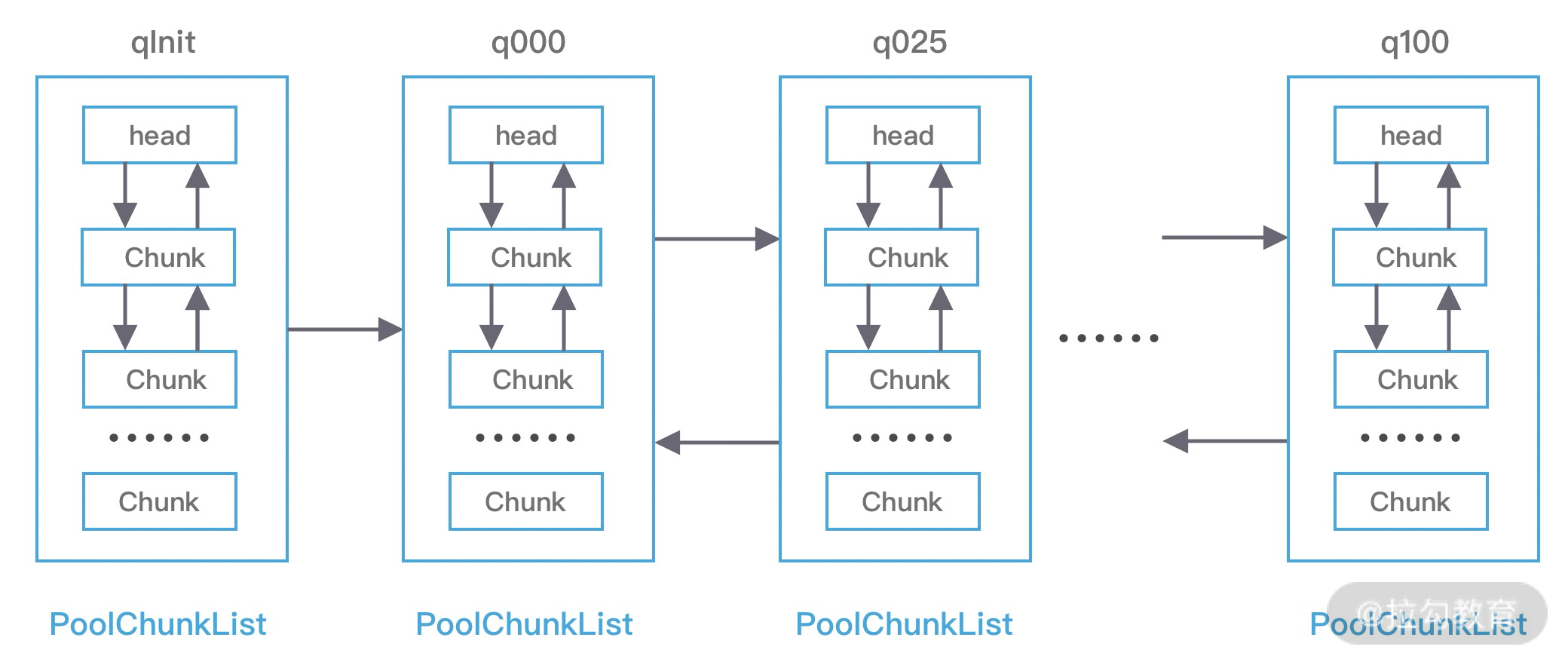
基于上图的内存池模型,Netty 抽象出一些核心组件,如 PoolArena、PoolChunk、PoolChunkList、PoolSubpage、PoolThreadCache、MemoryRegionCache 等,可以看出与 jemalloc 中的核心概念有些是类似的,接下来我们逐一进行介绍。
PoolArena
Netty 借鉴了 jemalloc 中 Arena 的设计思想,采用固定数量的多个 Arena 进行内存分配,Arena 的默认数量与 CPU 核数有关,通过创建多个 Arena 来缓解资源竞争问题,从而提高内存分配效率。线程在首次申请分配内存时,会通过 round-robin 的方式轮询 Arena 数组,选择一个固定的 Arena,在线程的生命周期内只与该 Arena 打交道,所以每个线程都保存了 Arena 信息,从而提高访问效率。
根据分配内存的类型,ByteBuf 可以分为 Heap 和 Direct,同样 PoolArena 抽象类提供了 HeapArena 和 DirectArena 两个子类。首先看下 PoolArena 的数据结构,如下图所示。
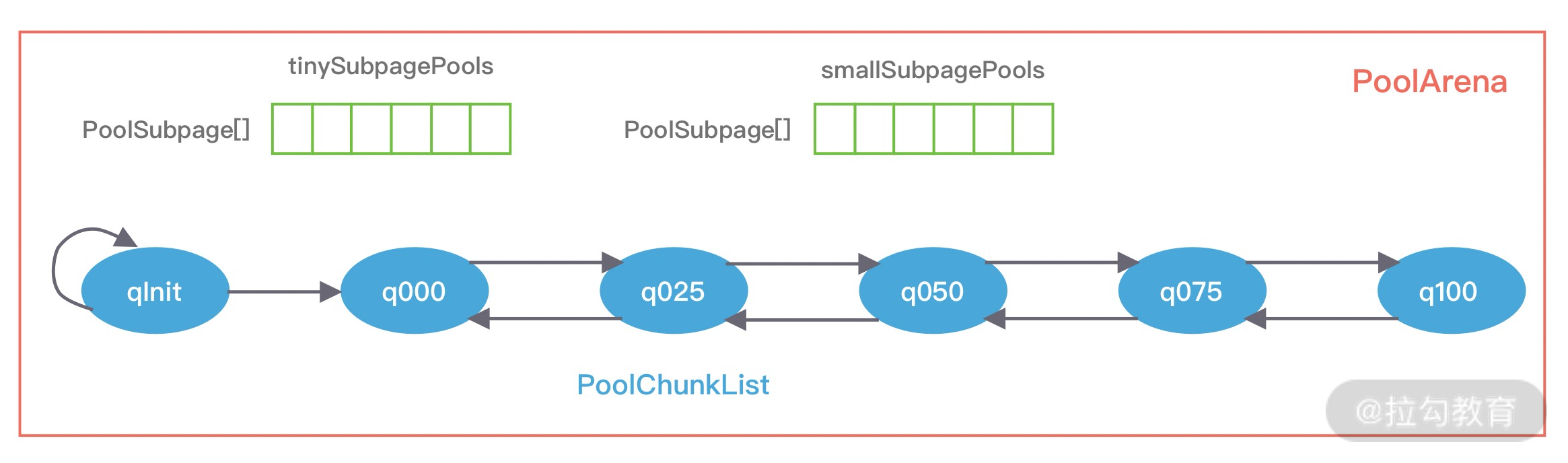
PoolArena 的数据结构包含两个 PoolSubpage 数组和六个 PoolChunkList,两个 PoolSubpage 数组分别存放 Tiny 和 Small 类型的内存块,六个 PoolChunkList 分别存储不同利用率的 Chunk,构成一个双向循环链表。
之前我们介绍了 Netty 内存规格的分类,PoolArena 对应实现了 Subpage 和 Chunk 中的内存分配,其 中 PoolSubpage 用于分配小于 8K 的内存,PoolChunkList 用于分配大于 8K 的内存。
PoolSubpage 也是按照 Tiny 和 Small 两种内存规格,设计了tinySubpagePools 和 smallSubpagePools 两个数组,根据关于 Subpage 的介绍,我们知道 Tiny 场景下,内存单位最小为 16B,按 16B 依次递增,共 32 种情况,Small 场景下共分为 512B、1024B、2048B、4096B 四种情况,分别对应两个数组的长度大小,每种粒度的内存单位都由一个 PoolSubpage 进行管理。假如我们分配 20B 大小的内存空间,也会向上取整找到 32B 的 PoolSubpage 节点进行分配。
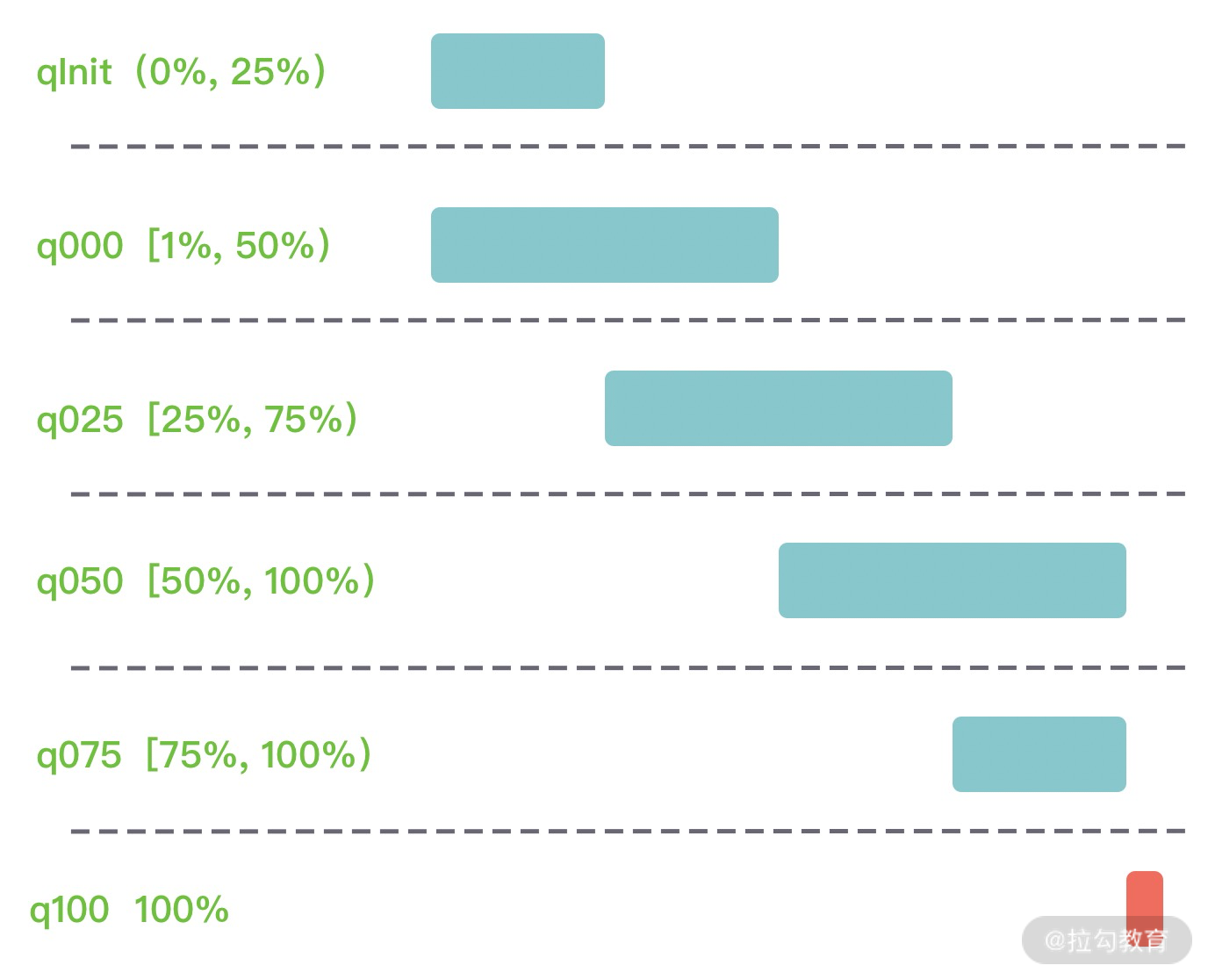
PoolChunkList 用于 Chunk 场景下的内存分配,PoolArena 中初始化了六个 PoolChunkList,分别为 qInit、q000、q025、q050、q075、q100,这与 jemalloc 中 run 队列思路是一致的,它们分别代表不同的内存使用率,如下所示:
- qInit,内存使用率为 0 ~ 25% 的 Chunk。
- q000,内存使用率为 1 ~ 50% 的 Chunk。
- q025,内存使用率为 25% ~ 75% 的 Chunk。
- q050,内存使用率为 50% ~ 100% 的 Chunk。
- q075,内存使用率为 75% ~ 100% 的 Chunk。
- q100,内存使用率为 100% 的 Chunk。
六种类型的 PoolChunkList 除了 qInit,它们之间都形成了双向链表,如下图所示。

随着 Chunk 内存使用率的变化,Netty 会重新检查内存的使用率并放入对应的 PoolChunkList,所以 PoolChunk 会在不同的 PoolChunkList 移动。
我在刚开始学习 PoolChunkList 的时候的一个疑问就是,qInit 和 q000 为什么需要设计成两个,是否可以合并成一个?其实它们各有用处。
qInit 用于存储初始分配的 PoolChunk,因为在第一次内存分配时,PoolChunkList 中并没有可用的 PoolChunk,所以需要新创建一个 PoolChunk 并添加到 qInit 列表中。qInit 中的 PoolChunk 即使内存被完全释放也不会被回收,避免 PoolChunk 的重复初始化工作。
q000 则用于存放内存使用率为 1 ~ 50% 的 PoolChunk,q000 中的 PoolChunk 内存被完全释放后,PoolChunk 从链表中移除,对应分配的内存也会被回收。
还有一点需要注意的是,在分配大于 8K 的内存时,其链表的访问顺序是 q050->q025->q000->qInit->q075,遍历检查 PoolChunkList 中是否有 PoolChunk 可以用于内存分配,源码如下:
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||q075.allocate(buf, reqCapacity, normCapacity)) {return;}PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);boolean success = c.allocate(buf, reqCapacity, normCapacity);assert success;qInit.add(c);
}
这里你或许有了疑问,为什么会优先选择 q050,而不是从 q000 开始呢?
可以说这是一个折中的选择,在频繁分配内存的场景下,如果从 q000 开始,会有大部分的 PoolChunk 面临频繁的创建和销毁,造成内存分配的性能降低。如果从 q050 开始,会使 PoolChunk 的使用率范围保持在中间水平,降低了 PoolChunk 被回收的概率,从而兼顾了性能。
PoolArena 是 Netty 内存分配中非常重要的部分,我们花了较多篇幅进行讲解,对之后理解内存分配的实现原理会有所帮助。
PoolChunkList
PoolChunkList 负责管理多个 PoolChunk 的生命周期,同一个 PoolChunkList 中存放内存使用率相近的 PoolChunk,这些 PoolChunk 同样以双向链表的形式连接在一起,PoolChunkList 的结构如下图所示。因为 PoolChunk 经常要从 PoolChunkList 中删除,并且需要在不同的 PoolChunkList 中移动,所以双向链表是管理 PoolChunk 时间复杂度较低的数据结构。
每个 PoolChunkList 都有内存使用率的上下限:minUsage 和 maxUsage,当 PoolChunk 进行内存分配后,如果使用率超过 maxUsage,那么 PoolChunk 会从当前 PoolChunkList 移除,并移动到下一个 PoolChunkList。同理,PoolChunk 中的内存发生释放后,如果使用率小于 minUsage,那么 PoolChunk 会从当前 PoolChunkList 移除,并移动到前一个 PoolChunkList。
回过头再看下 Netty 初始化的六个 PoolChunkList,每个 PoolChunkList 的上下限都有交叉重叠的部分,如下图所示。因为 PoolChunk 需要在 PoolChunkList 不断移动,如果每个 PoolChunkList 的内存使用率的临界值都是恰好衔接的,例如 1 ~ 50%、50% ~ 75%,那么如果 PoolChunk 的使用率一直处于 50% 的临界值,会导致 PoolChunk 在两个 PoolChunkList 不断移动,造成性能损耗。
PoolChunk
Netty 内存的分配和回收都是基于 PoolChunk 完成的,PoolChunk 是真正存储内存数据的地方,每个 PoolChunk 的默认大小为 16M,首先我们看下 PoolChunk 数据结构的定义:
final class PoolChunk<T> implements PoolChunkMetric {final PoolArena<T> arena;final T memory; // 存储的数据private final byte[] memoryMap; // 满二叉树中的节点是否被分配,数组大小为 4096private final byte[] depthMap; // 满二叉树中的节点高度,数组大小为 4096private final PoolSubpage<T>[] subpages; // PoolChunk 中管理的 2048 个 8K 内存块private int freeBytes; // 剩余的内存大小PoolChunkList<T> parent;PoolChunk<T> prev;PoolChunk<T> next; // 省略其他代码
}
PoolChunk 可以理解为 Page 的集合,Page 只是一种抽象的概念,实际在 Netty 中 Page 所指的是 PoolChunk 所管理的子内存块,每个子内存块采用 PoolSubpage 表示。Netty 会使用伙伴算法将 PoolChunk 分配成 2048 个 Page,最终形成一颗满二叉树,二叉树中所有子节点的内存都属于其父节点管理,如下图所示。
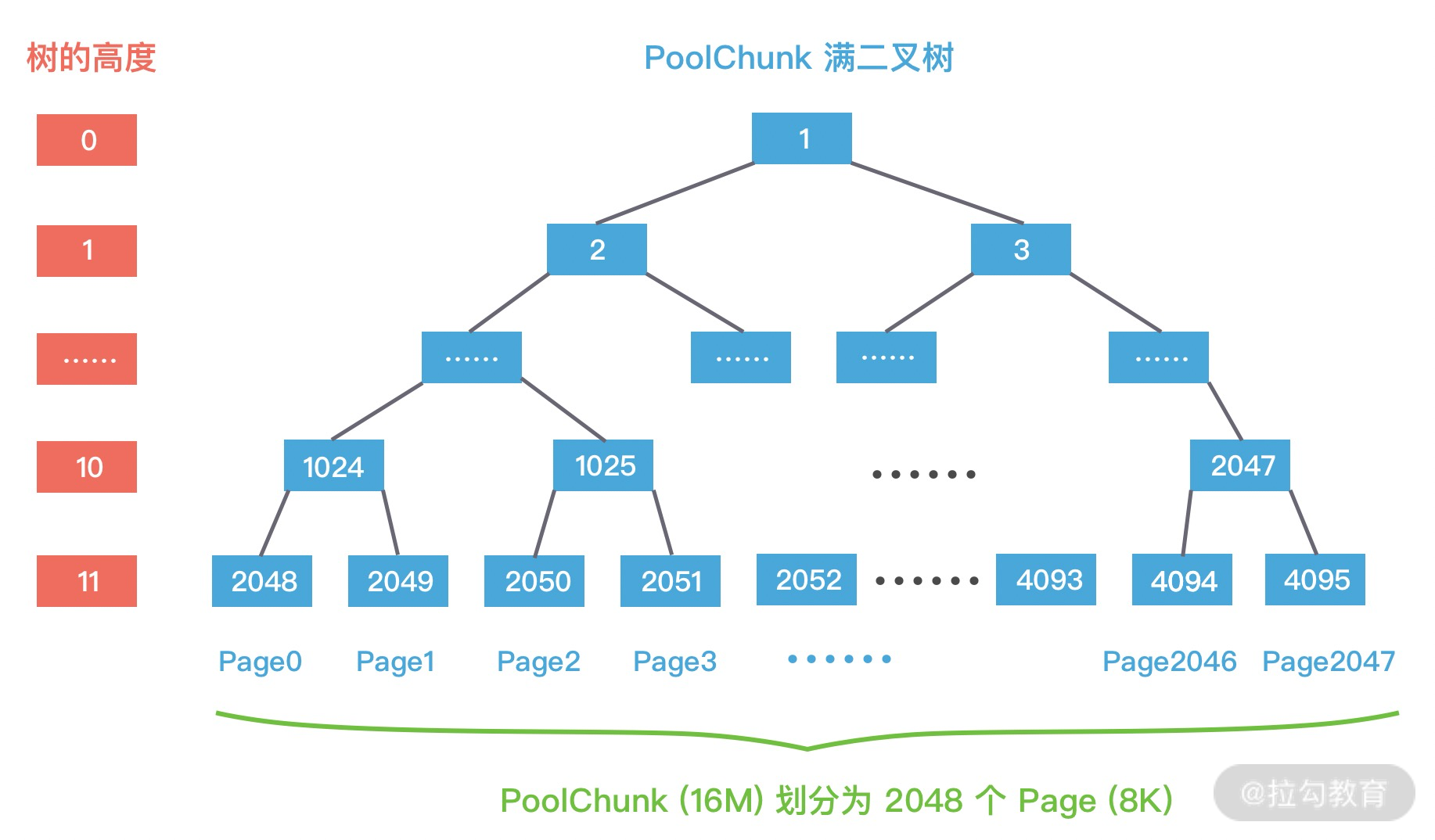
结合 PoolChunk 的结构图,我们介绍一下 PoolChunk 中几个重要的属性:
depthMap 用于存放节点所对应的高度。例如第 2048 个节点 depthMap[1025] = 10。
memoryMap 用于记录二叉树节点的分配信息,memoryMap 初始值与 depthMap 是一样的,随着节点被分配,不仅节点的值会改变,而且会递归遍历更新其父节点的值,父节点的值取两个子节点中最小的值。
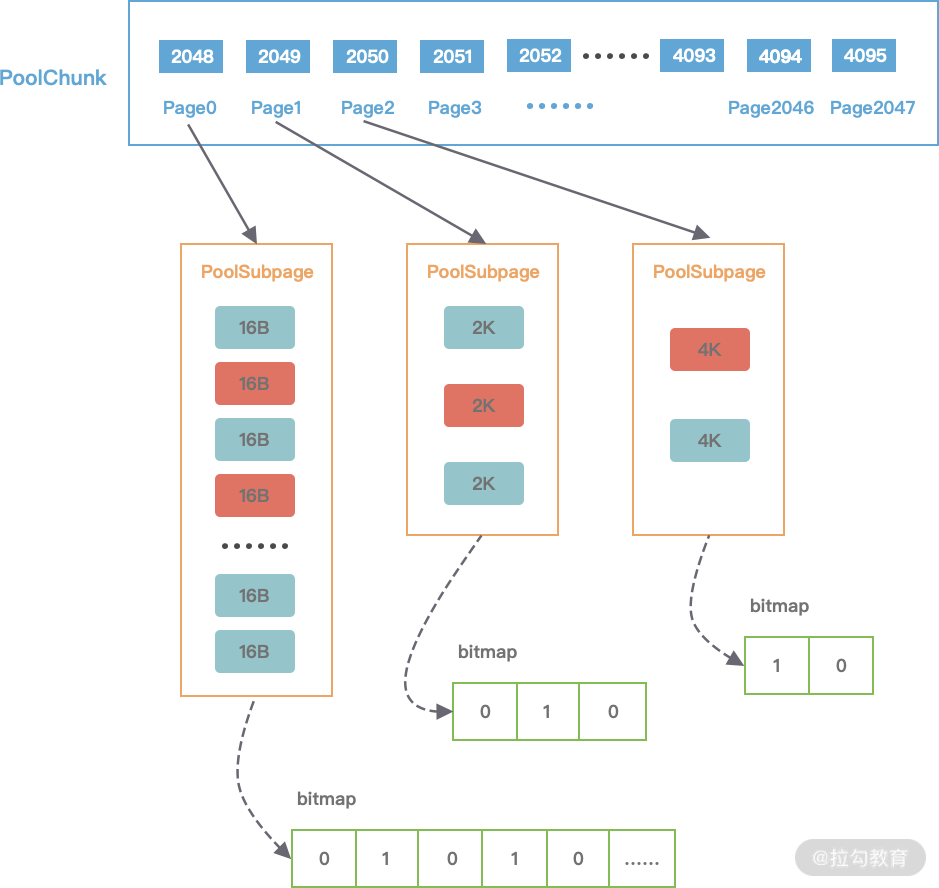
subpages 对应上图中 PoolChunk 内部的 Page0、Page1、Page2 … Page2047,Netty 中并没有 Page 的定义,直接使用 PoolSubpage 表示。当分配的内存小于 8K 时,PoolChunk 中的每个 Page 节点会被划分成为更小粒度的内存块进行管理,小内存块同样以 PoolSubpage 管理。从图中可以看出,小内存的分配场景下,会首先找到对应的 PoolArena ,然后根据计算出对应的 tinySubpagePools 或者 smallSubpagePools 数组对应的下标,如果对应数组元素所包含的 PoolSubpage 链表不存在任何节点,那么将创建新的 PoolSubpage 加入链表中。
PoolSubpage
目前大家对 PoolSubpage 应该有了一些认识,在小内存分配的场景下,即分配的内存大小小于一个 Page 8K,会使用 PoolSubpage 进行管理。首先看下 PoolSubpage 的定义:
final class PoolSubpage<T> implements PoolSubpageMetric {final PoolChunk<T> chunk;private final int memoryMapIdx; // 对应满二叉树节点的下标private final int runOffset; // PoolSubpage 在 PoolChunk 中 memory 的偏移量private final long[] bitmap; // 记录每个小内存块的状态// 与 PoolArena 中 tinySubpagePools 或 smallSubpagePools 中元素连接成双向链表PoolSubpage<T> prev;PoolSubpage<T> next;int elemSize; // 每个小内存块的大小private int maxNumElems; // 最多可以存放多少小内存块:8K/elemSizeprivate int numAvail; // 可用于分配的内存块个数 // 省略其他代码
}
PoolSubpage 中每个属性的含义都比较清晰易懂,我都以注释的形式标出,在这里就不一一赘述了,只指出其中比较重点的两个知识点:
第一个就是 PoolSubpage 是如何记录内存块的使用状态的呢?PoolSubpage 通过位图 bitmap 记录子内存是否已经被使用,bit 的取值为 0 或者 1,如下图所示。
第二个就是 PoolSubpage 和 PoolArena 之间是如何联系起来的?
通过之前的介绍,我们知道 PoolArena 在创建是会初始化 tinySubpagePools 和 smallSubpagePools 两个 PoolSubpage 数组,数组的大小分别为 32 和 4。
假如我们现在需要分配 20B 大小的内存,会向上取整为 32B,从满二叉树的第 11 层找到一个 PoolSubpage 节点,并把它等分为 8KB/32B = 256B 个小内存块,然后找到这个 PoolSubpage 节点对应的 PoolArena,将 PoolSubpage 节点与 tinySubpagePools[1] 对应的 head 节点连接成双向链表,形成下图所示的结构。
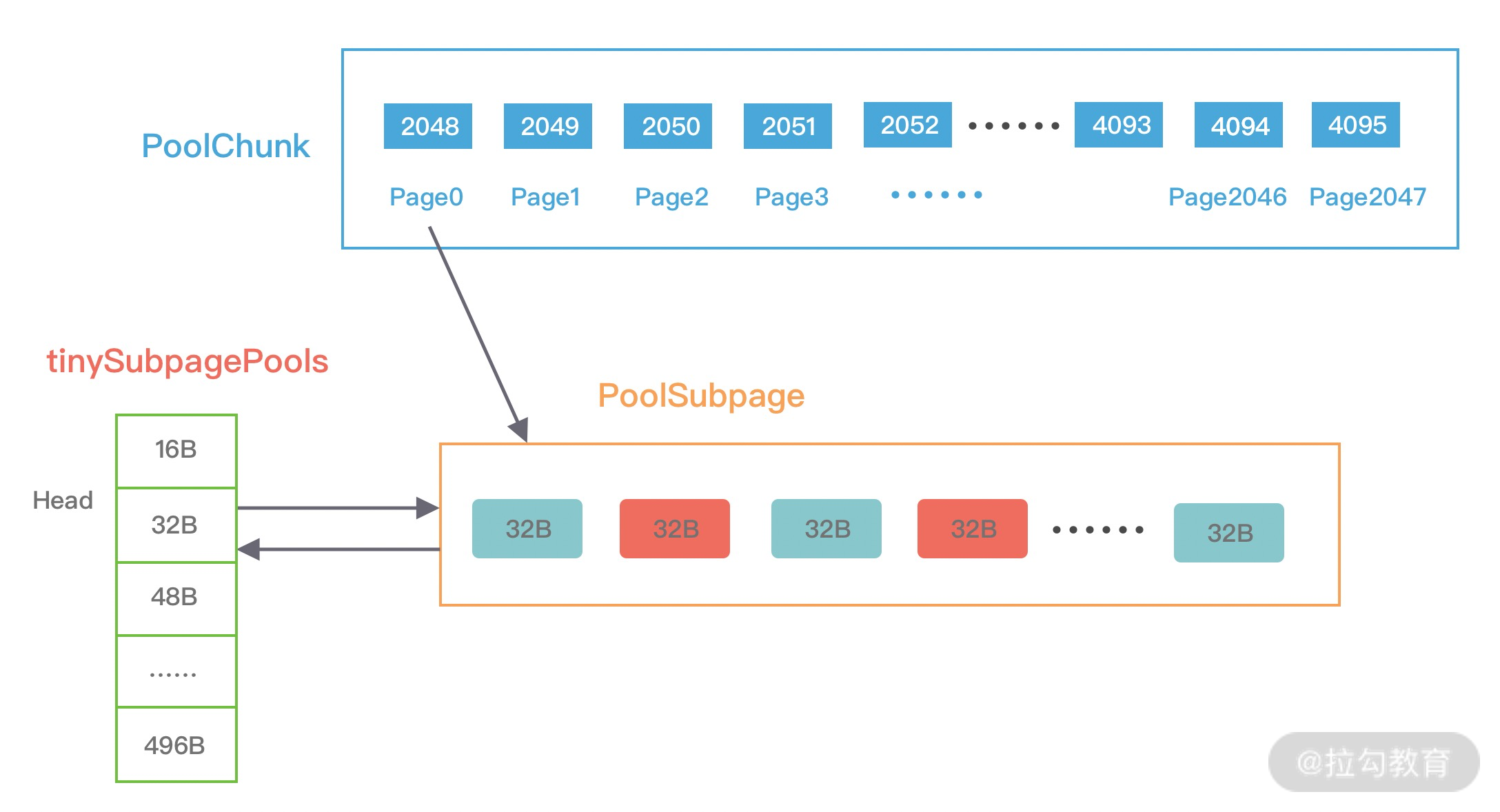
下次再有 32B 规格的内存分配时,会直接查找 PoolArena 中 tinySubpagePools[1] 元素的 next 节点是否存在可用的 PoolSubpage,如果存在将直接使用该 PoolSubpage 执行内存分配,从而提高了内存分配效率,其他内存规格的分配原理类似。
PoolThreadCache & MemoryRegionCache
PoolThreadCache 顾名思义,对应的是 jemalloc 中本地线程缓存的意思。那么 PoolThreadCache 是如何被使用的呢?它可以缓存哪些类型的数据呢?
当内存释放时,与 jemalloc 一样,Netty 并没有将缓存归还给 PoolChunk,而是使用 PoolThreadCache 缓存起来,当下次有同样规格的内存分配时,直接从 PoolThreadCache 取出使用即可。PoolThreadCache 缓存 Tiny、Small、Normal 三种类型的数据,而且根据堆内和堆外内存的类型进行了区分,如 PoolThreadCache 的源码定义所示:
final class PoolThreadCache {final PoolArena<byte[]> heapArena;final PoolArena<ByteBuffer> directArena;private final MemoryRegionCache<byte[]>[] tinySubPageHeapCaches;private final MemoryRegionCache<byte[]>[] smallSubPageHeapCaches;private final MemoryRegionCache<ByteBuffer>[] tinySubPageDirectCaches;private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches;private final MemoryRegionCache<byte[]>[] normalHeapCaches;private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches; // 省略其他代码
}
PoolThreadCache 中有一个重要的数据结构:MemoryRegionCache。MemoryRegionCache 有三个重要的属性,分别为 queue,sizeClass 和 size,下图是不同内存规格所对应的 MemoryRegionCache 属性取值范围。
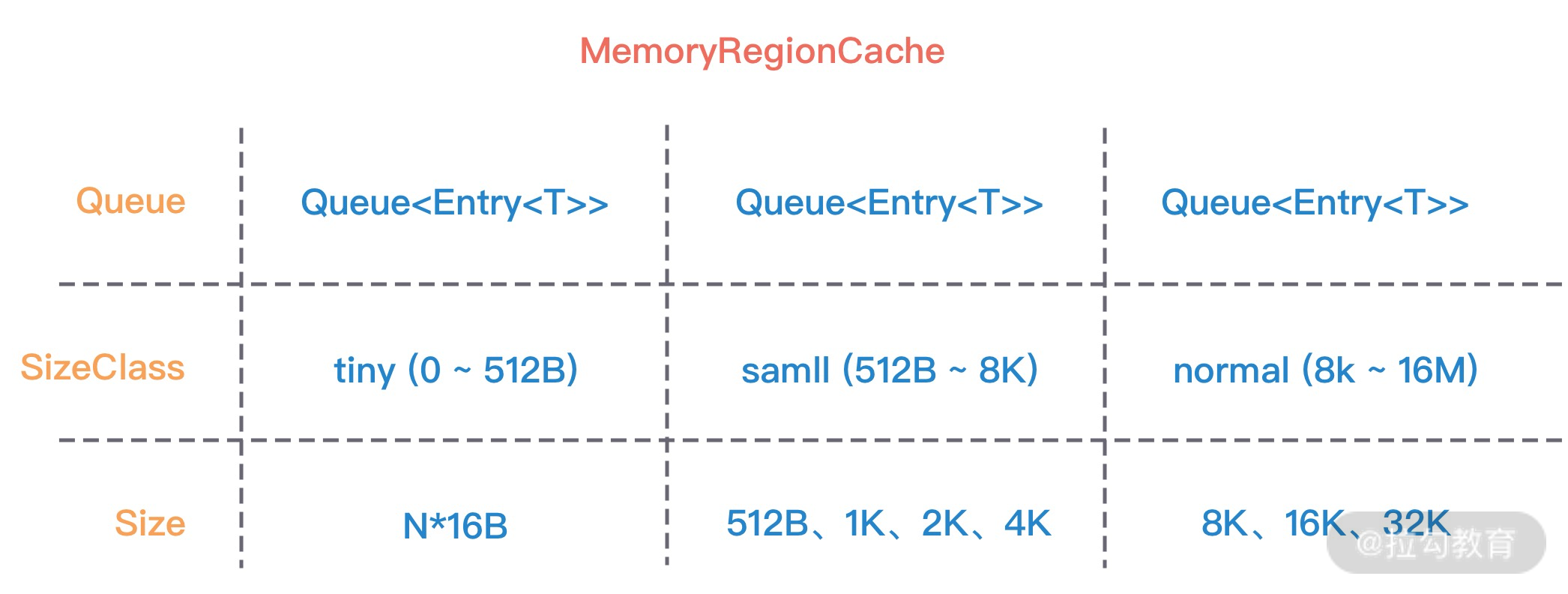
MemoryRegionCache 实际就是一个队列,当内存释放时,将内存块加入队列当中,下次再分配同样规格的内存时,直接从队列中取出空闲的内存块。
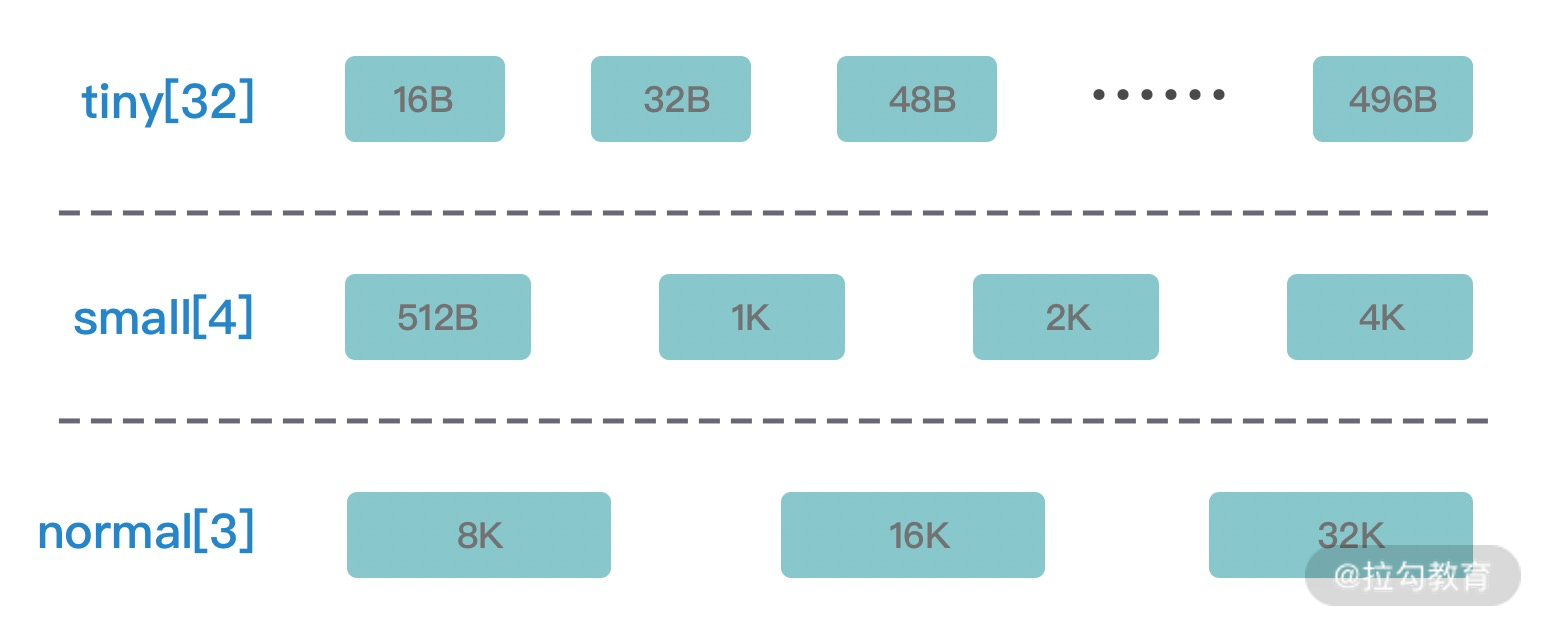
PoolThreadCache 将不同规格大小的内存都使用单独的 MemoryRegionCache 维护,如下图所示,图中的每个节点都对应一个 MemoryRegionCache,例如 Tiny 场景下对应的 32 种内存规格会使用 32 个 MemoryRegionCache 维护,所以 PoolThreadCache 源码中 Tiny、Small、Normal 类型的 MemoryRegionCache 数组长度分别为 32、4、3。
到此为止,Netty 中内存管理所涉及的核心组件都介绍完毕,推荐你回头再梳理一遍 jemalloc 的核心概念,与 Netty 做一个简单的对比,思路会更加清晰。
总结
知识都是殊途同归的,当你理解 jemalloc 之后,Netty 的内存管理也就不是那么难了,其中大部分的思路与 jemalloc 是保持一致的,所以打好基础非常重要。下节课我们继续看下 Netty 内存分配与回收的实现原理。
14 举一反三:Netty 高性能内存管理设计(下)
在上一节课,我们学习了 Netty 的内存规格分类以及内存管理的核心组件,今天这节课我们继续介绍 Netty 内存分配与回收的实现原理。有了上节课的基础,相信接下来的学习过程会事半功倍。
本节课会侧重于详细分析不同场景下 Netty 内存分配和回收的实现过程,让你对 Netty 内存池的整体设计有一个更加清晰的认识。
内存分配实现原理
Netty 中负责线程分配的组件有两个:PoolArena和PoolThreadCache。PoolArena 是多个线程共享的,每个线程会固定绑定一个 PoolArena,PoolThreadCache 是每个线程私有的缓存空间,如下图所示。
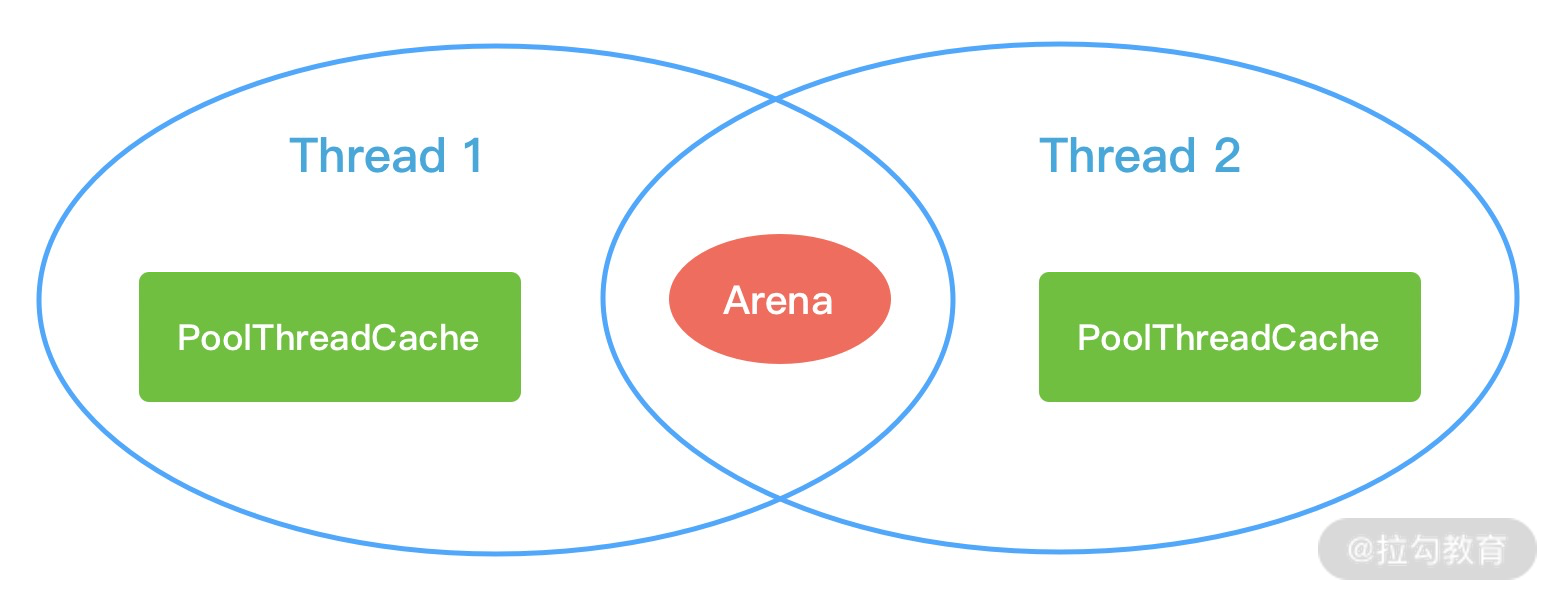
在上节课中,我们介绍了 PoolChunk、PoolSubpage、PoolChunkList,它们都是 PoolArena 中所用到的概念。PoolArena 中管理的内存单位为 PoolChunk,每个 PoolChunk 会被划分为 2048 个 8K 的 Page。在申请的内存大于 8K 时,PoolChunk 会以 Page 为单位进行内存分配。当申请的内存大小小于 8K 时,会由 PoolSubpage 管理更小粒度的内存分配。
PoolArena 分配的内存被释放后,不会立即会还给 PoolChunk,而且会缓存在本地私有缓存 PoolThreadCache 中,在下一次进行内存分配时,会优先从 PoolThreadCache 中查找匹配的内存块。
由此可见,Netty 中不同的内存规格采用的分配策略是不同的,我们主要分为以下三个场景逐一进行分析。
- 分配内存大于 8K 时,PoolChunk 中采用的 Page 级别的内存分配策略。
- 分配内存小于 8K 时,由 PoolSubpage 负责管理的内存分配策略。
- 分配内存小于 8K 时,为了提高内存分配效率,由 PoolThreadCache 本地线程缓存提供的内存分配。
PoolChunk 中 Page 级别的内存分配
每个 PoolChunk 默认大小为 16M,PoolChunk 是通过伙伴算法管理多个 Page,每个 PoolChunk 被划分为 2048 个 Page,最终通过一颗满二叉树实现,我们再一起回顾下 PoolChunk 的二叉树结构,如下图所示。
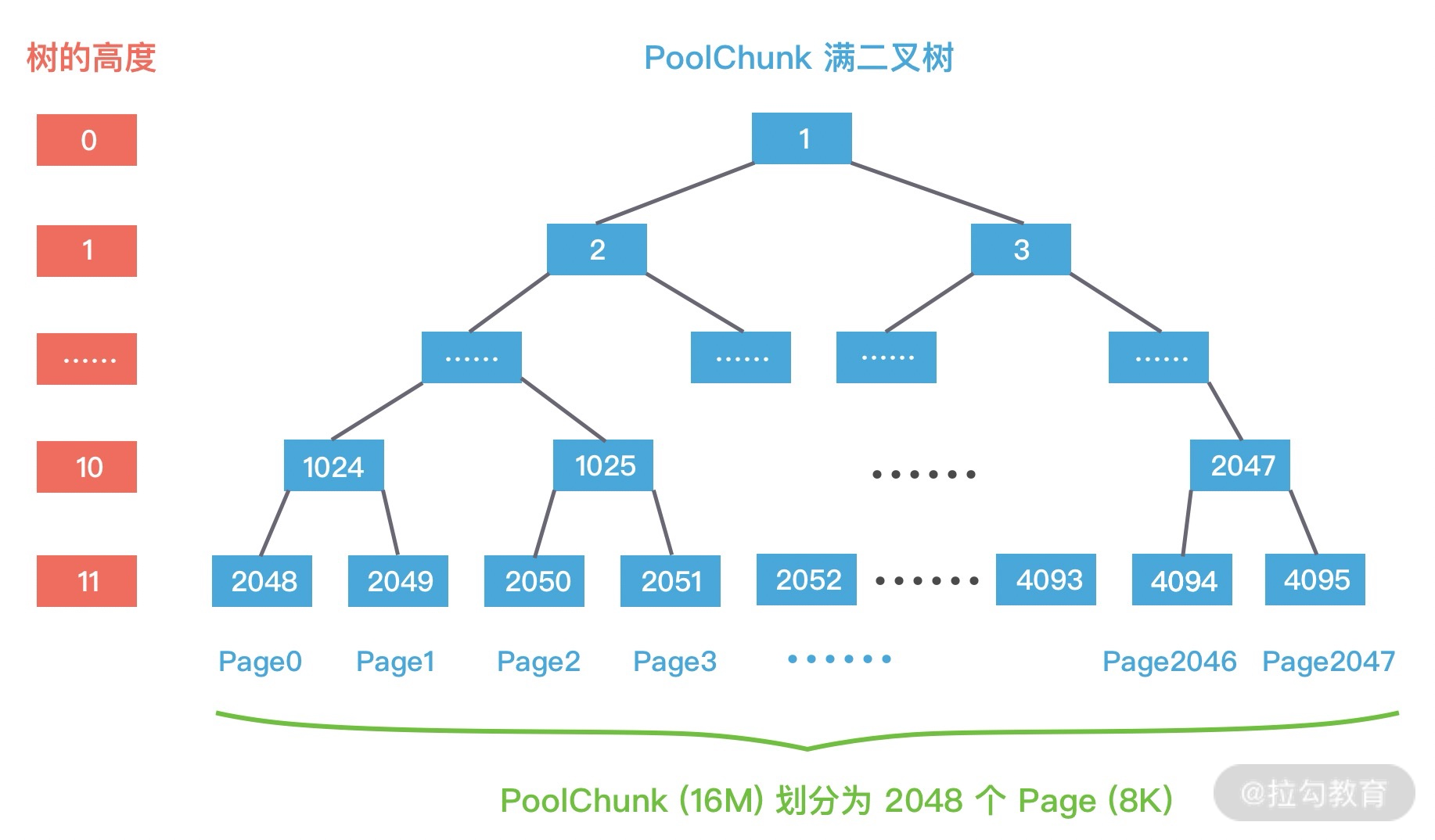
假如用户需要依次申请 8K、16K、8K 的内存,通过这里例子我们详细描述下 PoolChunk 如何分配 Page 级别的内存,方便大家理解伙伴算法的原理。
首先看下分配逻辑 allocateRun 的源码,如下所示。PoolChunk 分配 Page 主要分为三步:首先根据分配内存大小计算二叉树所在节点的高度,然后查找对应高度中是否存在可用节点,如果分配成功则减去已分配的内存大小得到剩余可用空间。
private long allocateRun(int normCapacity) {// 根据分配内存大小计算二叉树对应的节点高度int d = maxOrder - (log2(normCapacity) - pageShifts);// 查找对应高度中是否存在可用节点int id = allocateNode(d);if (id < 0) {return id;}// 减去已分配的内存大小freeBytes -= runLength(id);return id;
}
结合 PoolChunk 的二叉树结构以及 allocateRun 源码我们开始分析模拟的示例:
第一次分配 8K 大小的内存时,通过 d = maxOrder - (log2(normCapacity) - pageShifts) 计算得到二叉树所在节点高度为 11,其中 maxOrder 为二叉树的最大高度,normCapacity 为 8K,pageShifts 默认值为 13,因为只有当申请内存大小大于 2^13 = 8K 时才会使用 allocateRun 分配内存。然后从第 11 层查找可用的 Page,下标为 2048 的节点可以被用于分配内存,即 Page[0] 被分配使用,此时赋值 memoryMap[2048] = 12,表示该节点已经不可用,然后递归更新父节点的值,父节点的值取两个子节点的最小值,memoryMap[1024] = 11,memoryMap[512] = 10,以此类推直至 memoryMap[1] = 1,更新后的二叉树分配结果如下图所示。
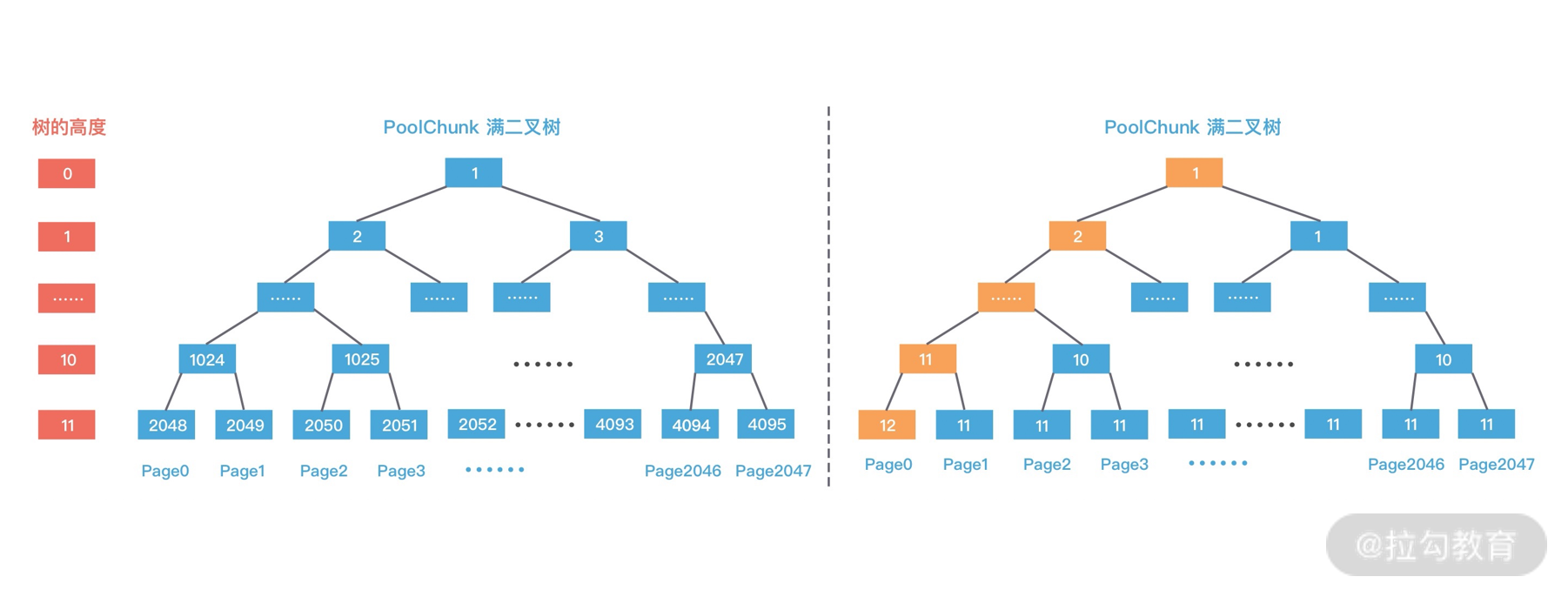
第二次分配 16K 大小内存时,计算得到所需节点的高度为 10。此时 1024 节点已经分配了一个 8K 内存,不再满足条件,继续寻找到 1025 节点。1025 节点并未使用过,满足分配条件,于是将 1025 节点的两个子节点 2050 和 2051 全部分配出去,并赋值 memoryMap[2050] = 12,memoryMap[2051] = 12,再次递归更新父节点的值,更新后的二叉树分配结果如下图所示。
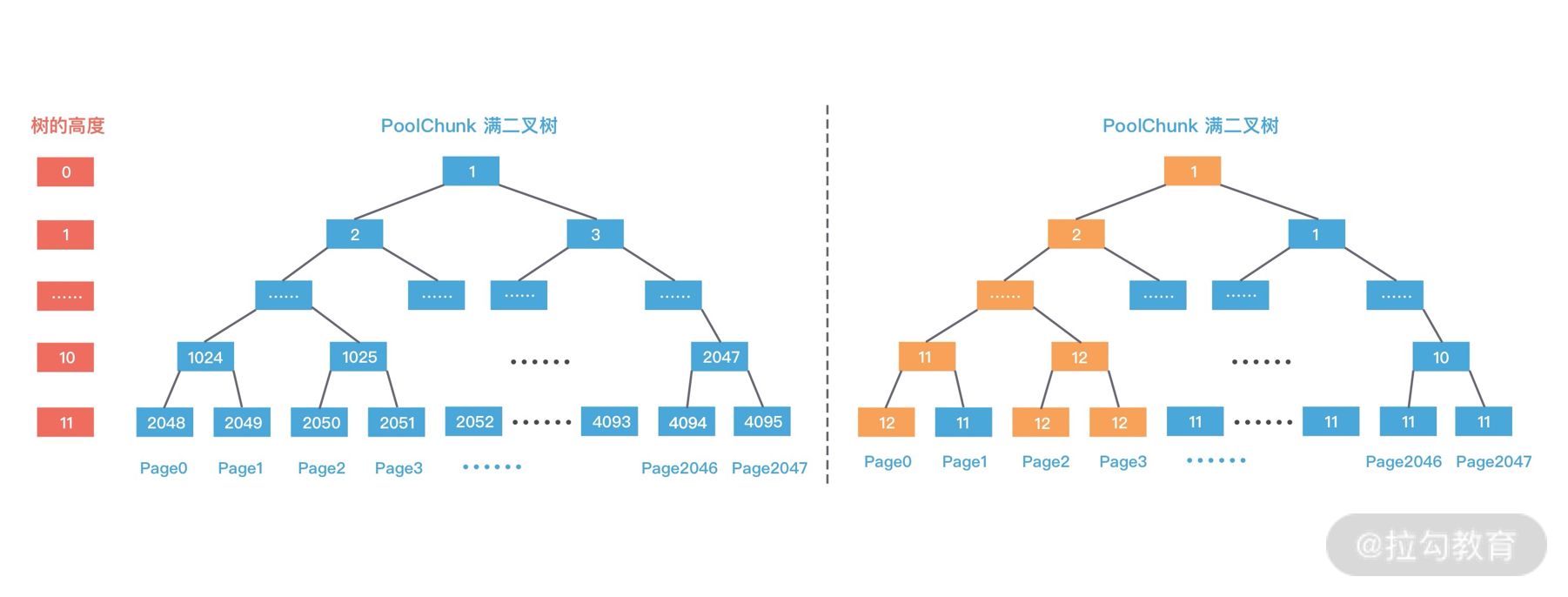
第三次再次分配 8K 大小的内存时,依然从二叉树第 11 层开始查找,2048 已经被使用,2049 可以被分配,赋值 memoryMap[2049] = 12,并递归更新父节点值,memoryMap[1024] = 12,memoryMap[512] = 12,以此类推直至 memoryMap[1] = 1,最终的二叉树分配结果如下图所示。
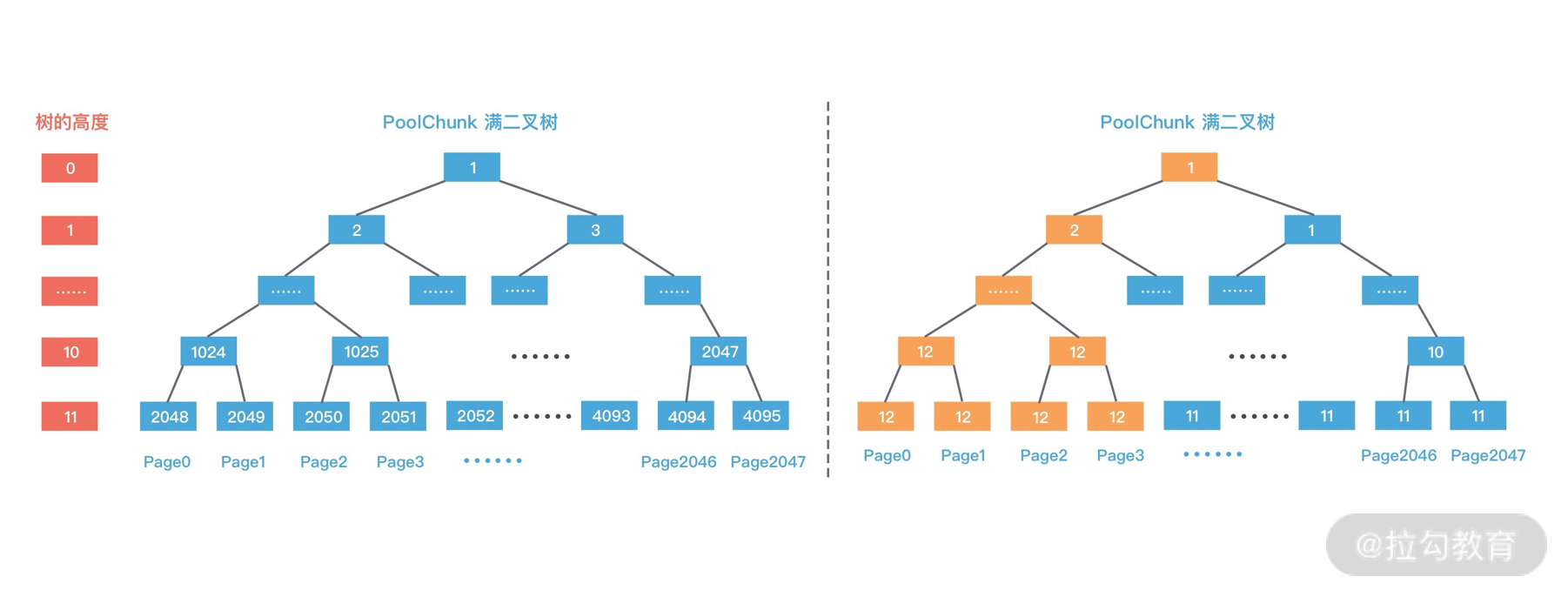
至此,PoolChunk 中 Page 级别的内存分配已经介绍完了,可以看出伙伴算法尽可能保证了分配内存地址的连续性,有效地降低了内存碎片。
Subpage 级别的内存分配
为了提高内存分配的利用率,在分配小于 8K 的内存时,PoolChunk 不在分配单独的 Page,而是将 Page 划分为更小的内存块,由 PoolSubpage 进行管理。
首先我们看下 PoolSubpage 的创建过程,由于分配的内存小于 8K,所以走到了 allocateSubpage 源码中:
private long allocateSubpage(int normCapacity) {// 根据内存大小找到 PoolArena 中 subpage 数组对应的头结点PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity);int d = maxOrder; // 因为分配内存小于 8K,所以从满二叉树最底层开始查找synchronized (head) {int id = allocateNode(d); // 在满二叉树中找到一个可用的节点if (id < 0) {return id;}final PoolSubpage<T>[] subpages = this.subpages; // 记录哪些 Page 被转化为 Subpagefinal int pageSize = this.pageSize; freeBytes -= pageSize;int subpageIdx = subpageIdx(id); // pageId 到 subpageId 的转化,例如 pageId=2048 对应的 subpageId=0PoolSubpage<T> subpage = subpages[subpageIdx];if (subpage == null) {// 创建 PoolSubpage,并切分为相同大小的子内存块,然后加入 PoolArena 对应的双向链表中subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity);subpages[subpageIdx] = subpage;} else {subpage.init(head, normCapacity);}return subpage.allocate(); // 执行内存分配并返回内存地址}
}
假如我们需要分配 20B 大小的内存,一起分析下上述源码的执行过程:
- 因为 20B 小于 512B,属于 Tiny 场景,按照内存规格的分类 20B 需要向上取整到 32B。
- 根据内存规格的大小找到 PoolArena 中 tinySubpagePools 数组对应的头结点,32B 对应的 tinySubpagePools[1]。
- 在满二叉树中寻找可用的节点用于内存分配,因为我们分配的内存小于 8K,所以直接从二叉树的最底层开始查找。假如 2049 节点是可用的,那么返回的 id = 2049。
- 找到可用节点后,因为 pageIdx 是从叶子节点 2048 开始记录索引,而 subpageIdx 需要从 0 开始的,所以需要将 pageIdx 转化为 subpageIdx,例如 2048 对应的 subpageIdx = 0,2049 对应的 subpageIdx = 1,以此类推。
- 如果 PoolChunk 中 subpages 数组的 subpageIdx 下标对应的 PoolSubpage 不存在,那么将创建一个新的 PoolSubpage,并将 PoolSubpage 切分为相同大小的子内存块,示例对应的子内存块大小为 32B,最后将新创建的 PoolSubpage 节点与 tinySubpagePools[1] 对应的 head 节点连接成双向链表。
- 最后 PoolSubpage 执行内存分配并返回内存地址。
接下来我们跟进一下 subpage.allocate() 源码,看下 PoolSubpage 是如何执行内存分配的,源码如下:
long allocate() {if (elemSize == 0) {return toHandle(0);}if (numAvail == 0 || !doNotDestroy) {return -1;}final int bitmapIdx = getNextAvail(); // 在 bitmap 中找到第一个索引段,然后将该 bit 置为 1int q = bitmapIdx >>> 6; // 定位到 bitmap 的数组下标int r = bitmapIdx & 63; // 取到节点对应一个 long 类型中的二进制位assert (bitmap[q] >>> r & 1) == 0;bitmap[q] |= 1L << r;if (-- numAvail == 0) {removeFromPool(); // 如果 PoolSubpage 没有可分配的内存块,从 PoolArena 双向链表中删除}return toHandle(bitmapIdx);
}
PoolSubpage 通过位图 bitmap 记录每个内存块是否已经被使用。在上述的示例中,8K/32B = 256,因为每个 long 有 64 位,所以需要 256/64 = 4 个 long 类型的即可描述全部的内存块分配状态,因此 bitmap 数组的长度为 4,从 bitmap[0] 开始记录,每分配一个内存块,就会移动到 bitmap[0] 中的下一个二进制位,直至 bitmap[0] 的所有二进制位都赋值为 1,然后继续分配 bitmap[1],以此类推。当我们使用 2049 节点进行内存分配时,bitmap[0] 中的二进制位如下图所示:
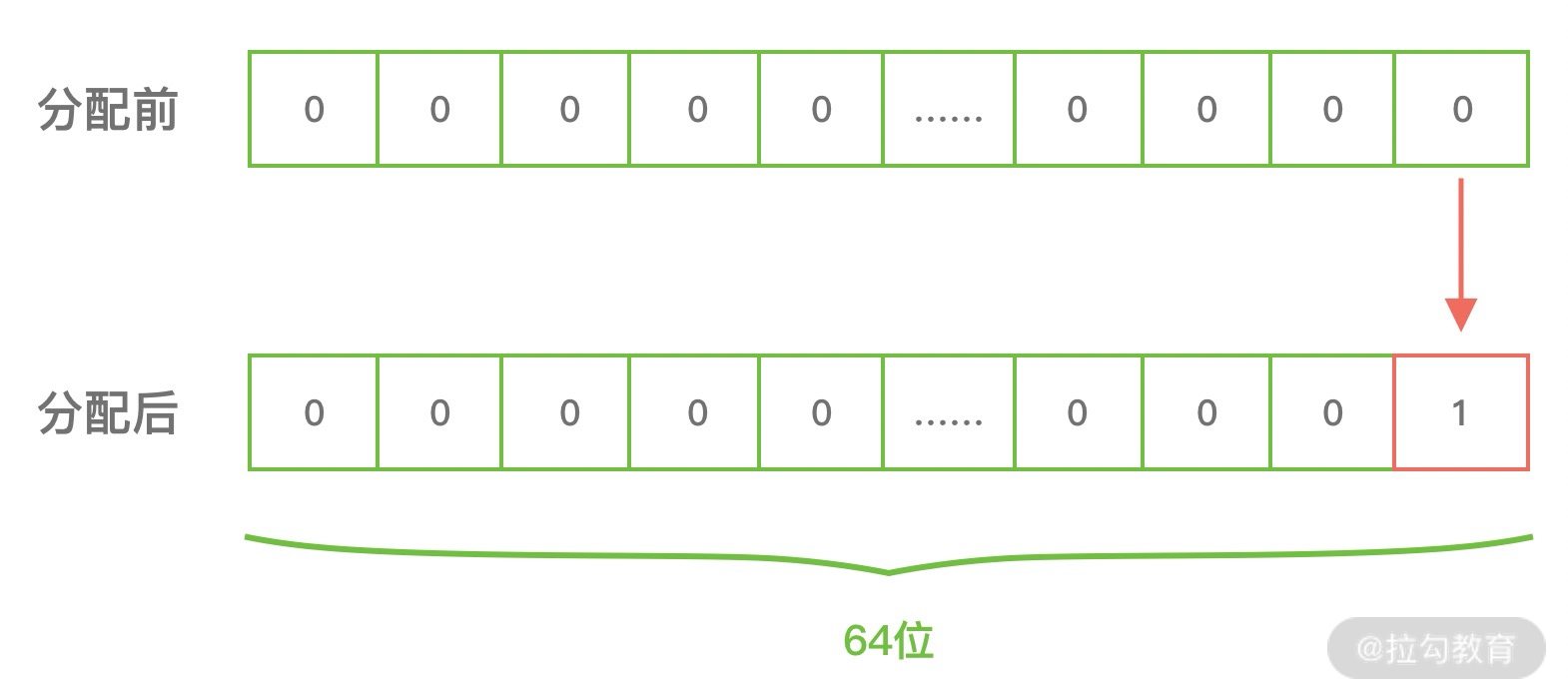
当 bitmap 分成成功后,PoolSubpage 会将可用节点的个数 numAvail 减 1,当 numAvail 降为 0 时,表示 PoolSubpage 已经没有可分配的内存块,此时需要从 PoolArena 中 tinySubpagePools[1] 的双向链表中删除。
至此,整个 PoolChunk 中 Subpage 的内存分配过程已经完成了,可见 PoolChunk 的伙伴算法几乎贯穿了整个流程,位图 bitmap 的设计也是非常巧妙的,不仅节省了内存空间,而且加快了定位内存块的速度。
PoolThreadCache 的内存分配
上节课已经介绍了 PoolThreadCache 的基本概念,我们知道 PoolArena 分配的内存被释放时,Netty 并没有将缓存归还给 PoolChunk,而是使用 PoolThreadCache 缓存起来,当下次有同样规格的内存分配时,直接从 PoolThreadCache 取出使用即可。所以下面我们从 PoolArena#allocate() 的源码中看下 PoolThreadCache 是如何使用的。
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {final int normCapacity = normalizeCapacity(reqCapacity);if (isTinyOrSmall(normCapacity)) { // capacity < pageSizeint tableIdx;PoolSubpage<T>[] table;boolean tiny = isTiny(normCapacity);if (tiny) { // < 512if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {return;}tableIdx = tinyIdx(normCapacity);table = tinySubpagePools;} else {if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {return;}tableIdx = smallIdx(normCapacity);table = smallSubpagePools;} // 省略其他代码}if (normCapacity <= chunkSize) {if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {return;}synchronized (this) {allocateNormal(buf, reqCapacity, normCapacity);++allocationsNormal;}} else {allocateHuge(buf, reqCapacity);}
}
从源码中可以看出在分配 Tiny、Small 和 Normal 类型的内存时,都会尝试先从 PoolThreadCache 中进行分配,源码结构比较清晰,我们整体梳理一遍流程:
- 对申请的内存大小做向上取整,例如 20B 的内存大小会取整为 32B。
- 当申请的内存大小小于 8K 时,分为 Tiny 和 Small 两种情况,分别都会优先尝试从 PoolThreadCache 分配内存,如果 PoolThreadCache 分配失败,才会走 PoolArena 的分配流程。
- 当申请的内存大小大于 8K,但是小于 Chunk 的默认大小 16M,属于 Normal 的内存分配,也会优先尝试从 PoolThreadCache 分配内存,如果 PoolThreadCache 分配失败,才会走 PoolArena 的分配流程。
- 当申请的内存大小大于 Chunk 的 16M,则不会经过 PoolThreadCache,直接进行分配。
PoolThreadCache 具体分配内存的过程使用到了一个重要的数据结构 MemoryRegionCache,关于 MemoryRegionCache 的概念你可以回顾下上节课的内容,在这里我就不再赘述了。假如我们现在需要分配 32B 大小的堆外内存,会从 MemoryRegionCache 数组 tinySubPageDirectCaches[1] 中取出对应的 MemoryRegionCache 节点,尝试从 MemoryRegionCache 的队列中取出可用的内存块。
内存回收实现原理
通过之前的介绍我们知道,当用户线程释放内存时会将内存块缓存到本地线程的私有缓存 PoolThreadCache 中,这样在下次分配内存时会提高分配效率,但是当内存块被用完一次后,再没有分配需求,那么一直驻留在内存中又会造成浪费。接下来我们就看下 Netty 是如何实现内存释放的呢?直接跟进下 PoolThreadCache 的源码。
private boolean allocate(MemoryRegionCache<?> cache, PooledByteBuf buf, int reqCapacity) {if (cache == null) {return false;}// 默认每执行 8192 次 allocate(),就会调用一次 trim() 进行内存整理boolean allocated = cache.allocate(buf, reqCapacity);if (++ allocations >= freeSweepAllocationThreshold) {allocations = 0;trim();}return allocated;
}
void trim() {trim(tinySubPageDirectCaches);trim(smallSubPageDirectCaches);trim(normalDirectCaches);trim(tinySubPageHeapCaches);trim(smallSubPageHeapCaches);trim(normalHeapCaches);
}
从源码中可以看出,Netty 记录了 allocate() 的执行次数,默认每执行 8192 次,就会触发 PoolThreadCache 调用一次 trim() 进行内存整理,会对 PoolThreadCache 中维护的六个 MemoryRegionCache 数组分别进行整理。我们继续跟进 trim 的源码,定位到核心逻辑。
public final void trim() {int free = size - allocations;allocations = 0;// We not even allocated all the number that areif (free > 0) {free(free, false);}
}
private int free(int max, boolean finalizer) {int numFreed = 0;for (; numFreed < max; numFreed++) {Entry<T> entry = queue.poll();if (entry != null) {freeEntry(entry, finalizer);} else {// all clearedreturn numFreed;}}return numFreed;
}
通过 size - allocations 衡量内存分配执行的频繁程度,其中 size 为该 MemoryRegionCache 对应的内存规格大小,size 为固定值,例如 Tiny 类型默认为 512。allocations 表示 MemoryRegionCache 距离上一次内存整理已经发生了多少次 allocate 调用,当调用次数小于 size 时,表示 MemoryRegionCache 中缓存的内存块并不常用,从队列中取出内存块依次释放。
此外 Netty 在线程退出的时候还会回收该线程的所有内存,PoolThreadCache 重载了 finalize() 方法,在销毁前执行缓存回收的逻辑,对应源码如下:
@Override
protected void finalize() throws Throwable {try {super.finalize();} finally {free(true);}
}
void free(boolean finalizer) {if (freed.compareAndSet(false, true)) {int numFreed = free(tinySubPageDirectCaches, finalizer) +free(smallSubPageDirectCaches, finalizer) +free(normalDirectCaches, finalizer) +free(tinySubPageHeapCaches, finalizer) +free(smallSubPageHeapCaches, finalizer) +free(normalHeapCaches, finalizer);if (numFreed > 0 && logger.isDebugEnabled()) {logger.debug("Freed {} thread-local buffer(s) from thread: {}", numFreed,Thread.currentThread().getName());}if (directArena != null) {directArena.numThreadCaches.getAndDecrement();}if (heapArena != null) {heapArena.numThreadCaches.getAndDecrement();}}
}
线程销毁时 PoolThreadCache 会依次释放所有 MemoryRegionCache 中的内存数据,其中 free 方法的核心逻辑与之前内存整理 trim 中释放内存的过程是一致的,有兴趣的同学可以自行翻阅源码。
到此为止,整个 Netty 内存池的分配和释放原理我们已经分析完了,其中巧妙的设计思路以及源码细节的实现,都是非常值得我们学习的宝贵资源。
总结
最后,我们对 Netty 内存池的设计思想做一个知识点总结:
- 分四种内存规格管理内存,分别为 Tiny、Samll、Normal、Huge,PoolChunk 负责管理 8K 以上的内存分配,PoolSubpage 用于管理 8K 以下的内存分配。当申请内存大于 16M 时,不会经过内存池,直接分配。
- 设计了本地线程缓存机制 PoolThreadCache,用于提升内存分配时的并发性能。用于申请 Tiny、Samll、Normal 三种类型的内存时,会优先尝试从 PoolThreadCache 中分配。
- PoolChunk 使用伙伴算法管理 Page,以二叉树的数据结构实现,是整个内存池分配的核心所在。
- 每调用 PoolThreadCache 的 allocate() 方法到一定次数,会触发检查 PoolThreadCache 中缓存的使用频率,使用频率较低的内存块会被释放。
- 线程退出时,Netty 会回收该线程对应的所有内存。
Netty 中引入类似 jemalloc 的内存池管理技术可以说是一大突破,将 Netty 的性能又提升了一个台阶,而这种思想不仅可以用于 Netty,在很对缓存的场景下都可以借鉴学习,希望这些优秀的设计思想能够对你有所帮助,在实际工作中学以致用。
15 轻量级对象回收站:Recycler 对象池技术解析
前面两节课,我们学习了 Netty 内存池的高性能设计原理,这节课会介绍 Netty 的另一种池化技术:Recycler 对象池。在刚接触到 Netty 对象池这个概念时,你是不是也会有类似的疑问:
- 对象池和内存池有什么区别?它们有什么联系吗?
- 实现对象池的方法有很多,Netty 也是自己实现的吗?是如何实现的?
- 对象池在实践中我们应该怎么使用?
带着这些问题,我们进入今天课程的学习吧。
Recycler 快速上手
我们通过一个例子直观感受下 Recycler 如何使用,假设我们有一个 User 类,需要实现 User 对象的复用,具体实现代码如下:
public class UserCache {private static final Recycler<User> userRecycler = new Recycler<User>() {@Overrideprotected User newObject(Handle<User> handle) {return new User(handle);}};static final class User {private String name;private Recycler.Handle<User> handle;public void setName(String name) {this.name = name;}public String getName() {return name;}public User(Recycler.Handle<User> handle) {this.handle = handle;}public void recycle() {handle.recycle(this);}}public static void main(String[] args) {User user1 = userRecycler.get(); // 1、从对象池获取 User 对象user1.setName("hello"); // 2、设置 User 对象的属性user1.recycle(); // 3、回收对象到对象池User user2 = userRecycler.get(); // 4、从对象池获取对象System.out.println(user2.getName());System.out.println(user1 == user2);}
}
控制台的输出结果如下:
hello
true
代码示例中定义了对象池实例 userRecycler,其中实现了 newObject() 方法,如果对象池没有可用的对象,会调用该方法新建对象。此外需要创建 Recycler.Handle 对象与 User 对象进行绑定,这样我们就可以通过 userRecycler.get() 从对象池中获取 User 对象,如果对象不再使用,通过调用 User 类实现的 recycle() 方法即可完成回收对象到对象池。
Recycler 的使用方式是不是特别简单,我们可以单独把它当作工具类在项目中使用。
Recycler 的设计理念
对象池与内存池的都是为了提高 Netty 的并发处理能力,我们知道 Java 中频繁地创建和销毁对象的开销是很大的,所以很多人会将一些通用对象缓存起来,当需要某个对象时,优先从对象池中获取对象实例。通过重用对象,不仅避免频繁地创建和销毁所带来的性能损耗,而且对 JVM GC 是友好的,这就是对象池的作用。
Recycler 是 Netty 提供的自定义实现的轻量级对象回收站,借助 Recycler 可以完成对象的获取和回收。既然 Recycler 是 Netty 自己实现的对象池,那么它是如何设计的呢?首先看下 Recycler 的内部结构,如下图所示:
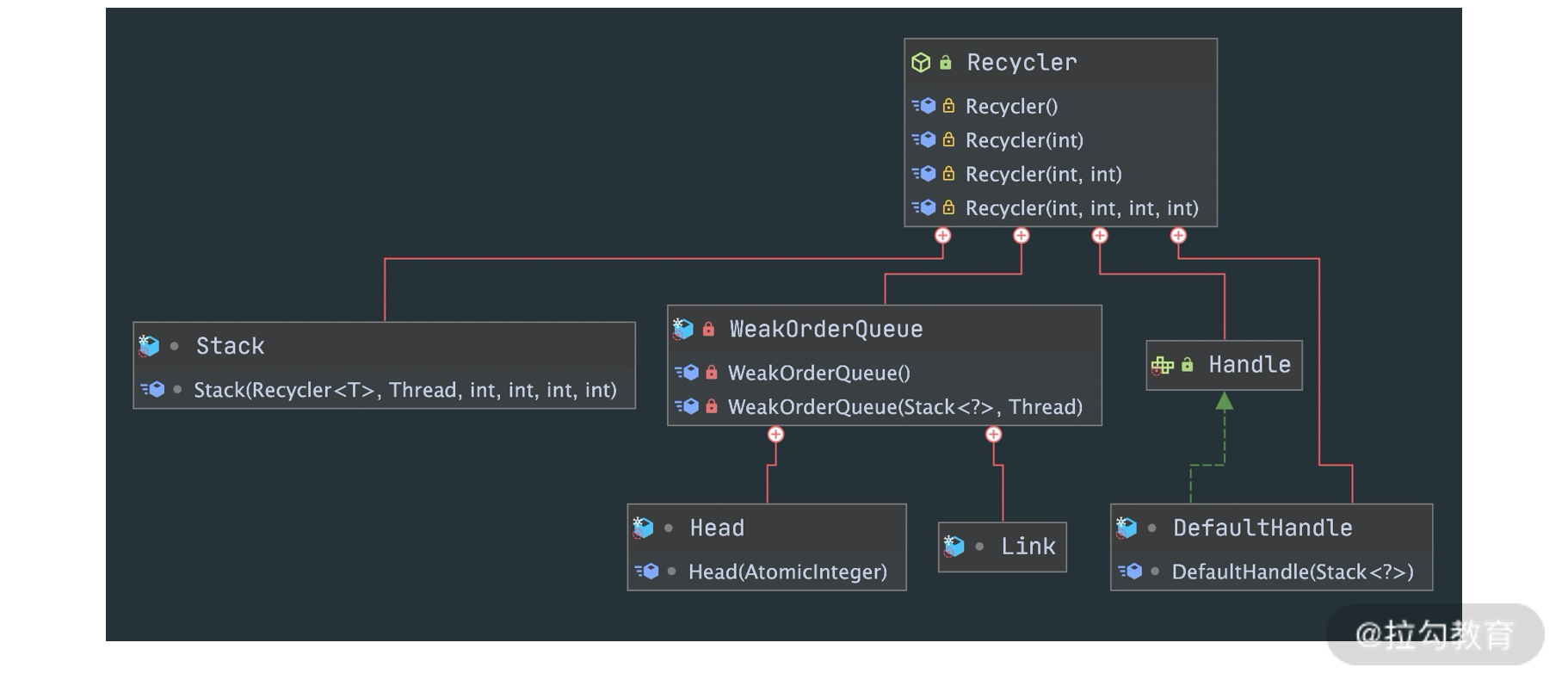
通过 Recycler 的 UML 图可以看出,一共包含四个核心组件:Stack、WeakOrderQueue、Link、DefaultHandle,接下来我们逐一进行介绍。
首先我们先看下整个 Recycler 的内部结构中各个组件的关系,可以通过下面这幅图进行描述。
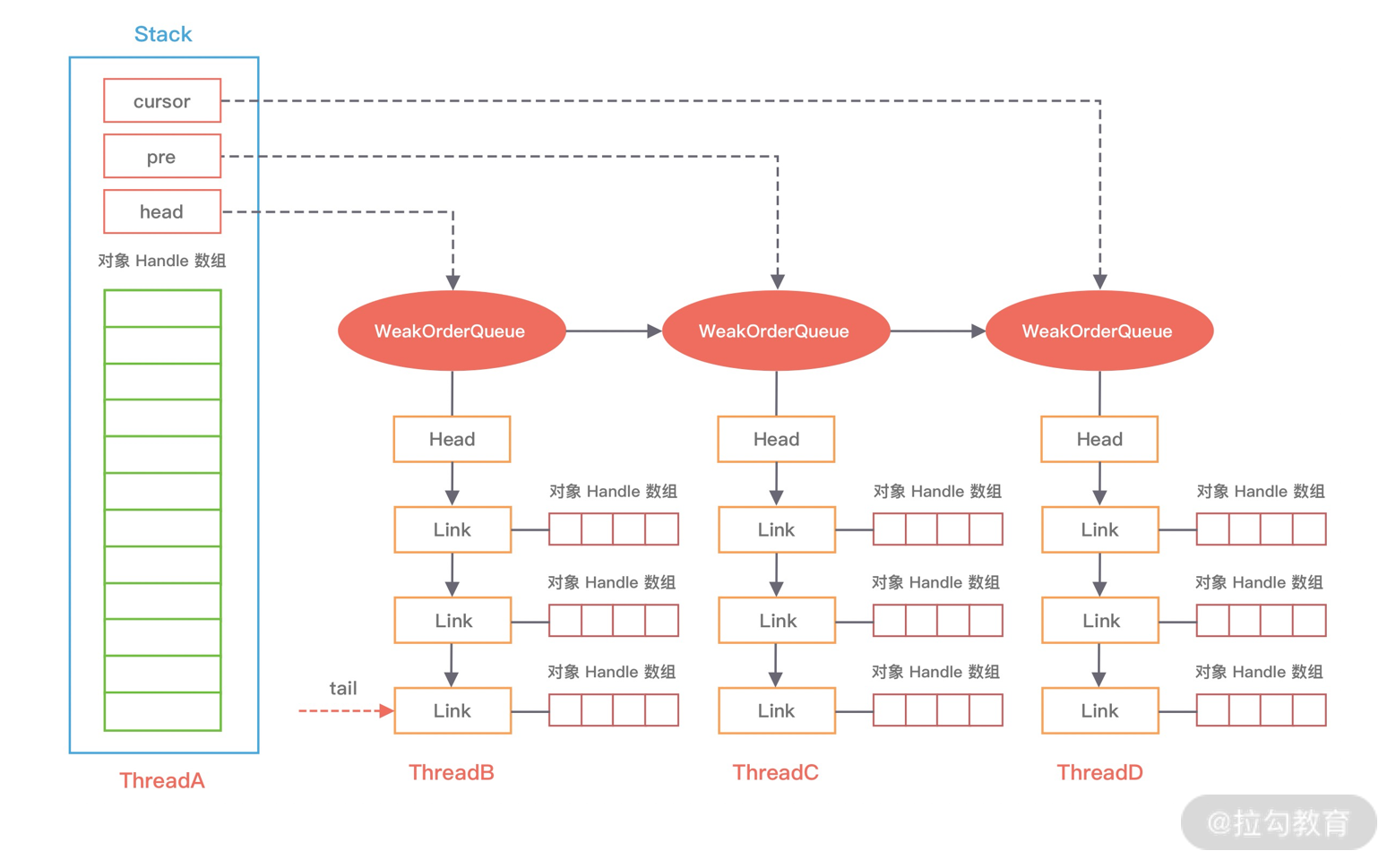
第一个核心组件是 Stack,Stack 是整个对象池的顶层数据结构,描述了整个对象池的构造,用于存储当前本线程回收的对象。在多线程的场景下,Netty 为了避免锁竞争问题,每个线程都会持有各自的对象池,内部通过 FastThreadLocal 来实现每个线程的私有化。FastThreadLocal 你可以理解为 Java 里的 ThreadLocal,后续会有专门的课程介绍它。
我们有必要先学习下 Stack 的数据结构,先看下 Stack 的源码定义:
static final class Stack<T> {final Recycler<T> parent; // 所属的 Recyclerfinal WeakReference<Thread> threadRef; // 所属线程的弱引用 final AtomicInteger availableSharedCapacity; // 异线程回收对象时,其他线程能保存的被回收对象的最大个数final int maxDelayedQueues; // WeakOrderQueue最大个数private final int maxCapacity; // 对象池的最大大小,默认最大为 4kprivate final int ratioMask; // 控制对象的回收比率,默认只回收 1/8 的对象private DefaultHandle<?>[] elements; // 存储缓存数据的数组private int size; // 缓存的 DefaultHandle 对象个数private int handleRecycleCount = -1; // WeakOrderQueue 链表的三个重要节点private WeakOrderQueue cursor, prev;private volatile WeakOrderQueue head; // 省略其他代码
}
对应上面 Recycler 的内部结构图,Stack 包用于存储缓存数据的 DefaultHandle 数组,以及维护了 WeakOrderQueue 链表中的三个重要节点,关于 WeakOrderQueue 相关概念我们之后再详细介绍。除此之外,Stack 其他的重要属性我在源码中已经全部以注释的形式标出,大部分已经都非常清楚,其中 availableSharedCapacity 是比较难理解的,每个 Stack 会维护一个 WeakOrderQueue 的链表,每个 WeakOrderQueue 节点会保存非当前线程的其他线程所释放的对象,例如图中 ThreadA 表示当前线程,WeakOrderQueue 的链表存储着 ThreadB、ThreadC 等其他线程释放的对象。availableSharedCapacity 的初始化方式为 new AtomicInteger(max(maxCapacity / maxSharedCapacityFactor, LINK_CAPACITY)),默认大小为 16K,其他线程在回收对象时,最多可以回收 ThreadA 创建的对象个数不能超过 availableSharedCapacity。还有一个疑问就是既然 Stack 是每个线程私有的,为什么 availableSharedCapacity 还需要用 AtomicInteger 呢?因为 ThreadB、ThreadC 等多个线程可能都会创建 ThreadA 的 WeakOrderQueue,存在同时操作 availableSharedCapacity 的情况。
第二个要介绍的组件是 WeakOrderQueue,WeakOrderQueue 用于存储其他线程回收到当前线程所分配的对象,并且在合适的时机,Stack 会从异线程的 WeakOrderQueue 中收割对象。如上图所示,ThreadB 回收到 ThreadA 所分配的内存时,就会被放到 ThreadA 的 WeakOrderQueue 当中。
第三个组件是 Link,每个 WeakOrderQueue 中都包含一个 Link 链表,回收对象都会被存在 Link 链表中的节点上,每个 Link 节点默认存储 16 个对象,当每个 Link 节点存储满了会创建新的 Link 节点放入链表尾部。
第四个组件是 DefaultHandle,DefaultHandle 实例中保存了实际回收的对象,Stack 和 WeakOrderQueue 都使用 DefaultHandle 存储回收的对象。在 Stack 中包含一个 elements 数组,该数组保存的是 DefaultHandle 实例。DefaultHandle 中每个 Link 节点所存储的 16 个对象也是使用 DefaultHandle 表示的。
到此为止,我们已经介绍完 Recycler 的内存结构,对 Recycler 有了初步的认识。Recycler 作为一个高性能的对象池,在多线程的场景下,Netty 是如何保证 Recycler 高效地分配和回收对象的呢?接下来我们一起看下 Recycler 对象获取和回收的原理。
从 Recycler 中获取对象
前面我们介绍了 Recycler 如何使用,从代码示例中可以看出,从对象池中获取对象的入口是在 Recycler#get() 方法,直接定位到源码:
public final T get() {if (maxCapacityPerThread == 0) {return newObject((Handle<T>) NOOP_HANDLE);}Stack<T> stack = threadLocal.get(); // 获取当前线程缓存的 StackDefaultHandle<T> handle = stack.pop(); // 从 Stack 中弹出一个 DefaultHandle 对象if (handle == null) {handle = stack.newHandle();handle.value = newObject(handle); // 创建的对象并保存到 DefaultHandle}return (T) handle.value;
}
Recycler#get() 方法的逻辑非常清晰,首先通过 FastThreadLocal 获取当前线程的唯一栈缓存 Stack,然后尝试从栈顶弹出 DefaultHandle 对象实例,如果 Stack 中没有可用的 DefaultHandle 对象实例,那么会调用 newObject 生成一个新的对象,完成 handle 与用户对象和 Stack 的绑定。
那么 Stack 是如何从 elements 数组中弹出 DefaultHandle 对象实例的呢?只是从 elements 数组中取出一个实例吗?我们一起跟进下 stack.pop() 的源码:
DefaultHandle<T> pop() {int size = this.size;if (size == 0) {// 就尝试从其他线程回收的对象中转移一些到 elements 数组当中if (!scavenge()) {return null;}size = this.size;}size --;DefaultHandle ret = elements[size]; // 将实例从栈顶弹出elements[size] = null;if (ret.lastRecycledId != ret.recycleId) {throw new IllegalStateException("recycled multiple times");}ret.recycleId = 0;ret.lastRecycledId = 0;this.size = size;return ret;
}
如果 Stack 的 elements 数组中有可用的对象实例,直接将对象实例弹出;如果 elements 数组中没有可用的对象实例,会调用 scavenge 方法,scavenge 的作用是从其他线程回收的对象实例中转移一些到 elements 数组当中,也就是说,它会想办法从 WeakOrderQueue 链表中迁移部分对象实例。每个 Stack 会有一个 WeakOrderQueue 链表,每个 WeakOrderQueue 节点都维持了相应异线程回收的对象,那么以什么样的策略从 WeakOrderQueue 链表中迁移对象实例呢?继续跟进 scavenge 的源码:
boolean scavenge() {// 尝试从 WeakOrderQueue 中转移对象实例到 Stack 中if (scavengeSome()) {return true;}// 如果迁移失败,就会重置 cursor 指针到 head 节点prev = null;cursor = head;return false;
}
boolean scavengeSome() {WeakOrderQueue prev;WeakOrderQueue cursor = this.cursor; // cursor 指针指向当前 WeakorderQueueu 链表的读取位置// 如果 cursor 指针为 null, 则是第一次从 WeakorderQueueu 链表中获取对象if (cursor == null) {prev = null;cursor = head;if (cursor == null) {return false;}} else {prev = this.prev;}boolean success = false;// 不断循环从 WeakOrderQueue 链表中找到一个可用的对象实例do {// 尝试迁移 WeakOrderQueue 中部分对象实例到 Stack 中if (cursor.transfer(this)) {success = true;break;}WeakOrderQueue next = cursor.next;if (cursor.owner.get() == null) {// 如果已退出的线程还有数据if (cursor.hasFinalData()) {for (;;) {if (cursor.transfer(this)) {success = true;} else {break;}}}// 将已退出的线程从 WeakOrderQueue 链表中移除if (prev != null) {prev.setNext(next);}} else {prev = cursor;}// 将 cursor 指针指向下一个 WeakOrderQueuecursor = next;} while (cursor != null && !success);this.prev = prev;this.cursor = cursor;return success;
}
scavenge 的源码中首先会从 cursor 指针指向的 WeakOrderQueue 节点回收部分对象到 Stack 的 elements 数组中,如果没有回收到数据就会将 cursor 指针移到下一个 WeakOrderQueue,重复执行以上过程直至回到到对象实例为止。具体的流程可以结合下图来理解。
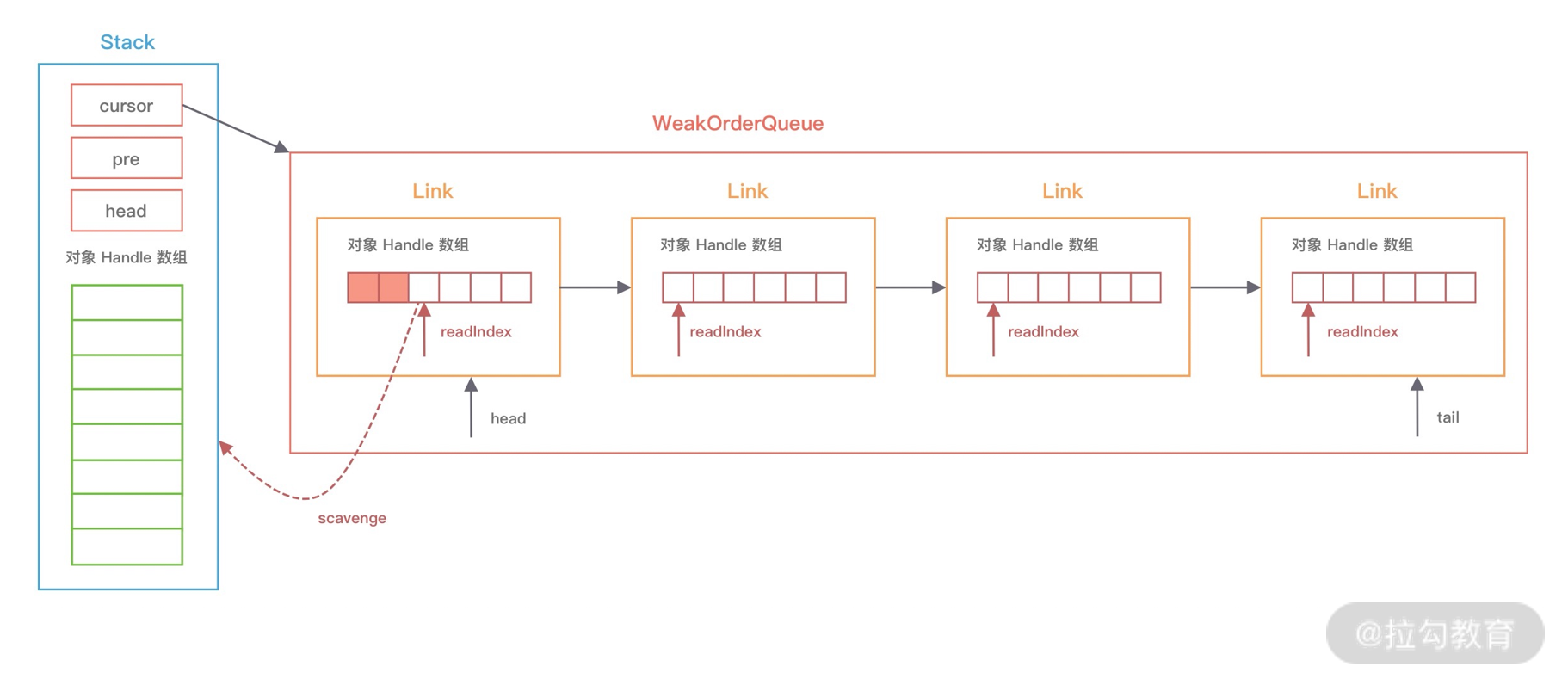
此外,每次移动 cursor 时,都会检查 WeakOrderQueue 对应的线程是否已经退出了,如果线程已经退出,那么线程中的对象实例都会被回收,然后将 WeakOrderQueue 节点从链表中移除。
还有一个问题,每次 Stack 从 WeakOrderQueue 链表会回收多少数据呢?我们依然结合上图讲解,每个 WeakOrderQueue 中都包含一个 Link 链表,Netty 每次会回收其中的一个 Link 节点所存储的对象。从图中可以看出,Link 内部会包含一个读指针 readIndex,每个 Link 节点默认存储 16 个对象,读指针到链表尾部就是可以用于回收的对象实例,每次回收对象时,readIndex 都会从上一次记录的位置开始回收。
在回收对象实例之前,Netty 会计算出可回收对象的数量,加上 Stack 中已有的对象数量后,如果超过 Stack 的当前容量且小于 Stack 的最大容量,会对 Stack 进行扩容。为了防止回收对象太多导致 Stack 的容量激增,在每次回收时 Netty 会调用 dropHandle 方法控制回收频率,具体源码如下:
boolean dropHandle(DefaultHandle<?> handle) {if (!handle.hasBeenRecycled) {if ((++handleRecycleCount & ratioMask) != 0) {// Drop the object.return true;}handle.hasBeenRecycled = true;}return false;
}
dropHandle 方法中主要靠 hasBeenRecycled 和 handleRecycleCount 两个变量控制回收的频率,会从每 8 个未被收回的对象中选取一个进行回收,其他的都被丢弃掉。
到此为止,从 Recycler 中获取对象的主流程已经讲完了,简单总结为两点:
- 当 Stack 中 elements 有数据时,直接从栈顶弹出。
- 当 Stack 中 elements 没有数据时,尝试从 WeakOrderQueue 中回收一个 Link 包含的对象实例到 Stack 中,然后从栈顶弹出。
Recycler 对象回收原理
理解了如何从 Recycler 获取对象之后,再学习 Recycler 对象回收的原理就会清晰很多了,同样上文代码示例中定位到对象回收的源码入口 DefaultHandle#recycle()。
// DefaultHandle#recycle
public void recycle(Object object) {if (object != value) {throw new IllegalArgumentException("object does not belong to handle");}Stack<?> stack = this.stack;if (lastRecycledId != recycleId || stack == null) {throw new IllegalStateException("recycled already");}stack.push(this);
}
// Stack#push
void push(DefaultHandle<?> item) {Thread currentThread = Thread.currentThread();if (threadRef.get() == currentThread) {pushNow(item);} else {pushLater(item, currentThread);}
}
从源码中可以看出,在回收对象时,会向 Stack 中 push 对象,push 会分为同线程回收和异线程回收两种情况,分别对应 pushNow 和 pushLater 两个方法,我们逐一进行分析。
同线程对象回收
如果是当前线程回收自己分配的对象时,会调用 pushNow 方法:
private void pushNow(DefaultHandle<?> item) {if ((item.recycleId | item.lastRecycledId) != 0) { // 防止被多次回收throw new IllegalStateException("recycled already");}item.recycleId = item.lastRecycledId = OWN_THREAD_ID;int size = this.size;// 1. 超出最大容量 2. 控制回收速率if (size >= maxCapacity || dropHandle(item)) {return;}if (size == elements.length) {elements = Arrays.copyOf(elements, min(size << 1, maxCapacity));}elements[size] = item;this.size = size + 1;
}
同线程回收对象的逻辑非常简单,就是直接向 Stack 的 elements 数组中添加数据,对象会被存放在栈顶指针指向的位置。如果超过了 Stack 的最大容量,那么对象会被直接丢弃,同样这里使用了 dropHandle 方法控制对象的回收速率,每 8 个对象会有一个被回收到 Stack 中。
异线程对象回收
接下来我们分析异线程对象回收的场景,想必你已经猜到,异线程回收对象时,并不会添加到 Stack 中,而是会与 WeakOrderQueue 直接打交道,先看下 pushLater 的源码:
private void pushLater(DefaultHandle<?> item, Thread thread) {Map<Stack<?>, WeakOrderQueue> delayedRecycled = DELAYED_RECYCLED.get(); // 当前线程帮助其他线程回收对象的缓存WeakOrderQueue queue = delayedRecycled.get(this); // 取出对象绑定的 Stack 对应的 WeakOrderQueueif (queue == null) {// 最多帮助 2*CPU 核数的线程回收线程if (delayedRecycled.size() >= maxDelayedQueues) {delayedRecycled.put(this, WeakOrderQueue.DUMMY); // WeakOrderQueue.DUMMY 表示当前线程无法再帮助该 Stack 回收对象return;}// 新建 WeakOrderQueueif ((queue = WeakOrderQueue.allocate(this, thread)) == null) {// drop objectreturn;}delayedRecycled.put(this, queue);} else if (queue == WeakOrderQueue.DUMMY) {// drop objectreturn;}queue.add(item); // 添加对象到 WeakOrderQueue 的 Link 链表中
}
pushLater 的实现过程可以总结为两个步骤:获取 WeakOrderQueue,添加对象到 WeakOrderQueue 中。
首先看下如何获取 WeakOrderQueue 对象。通过 FastThreadLocal 取出当前对象的 DELAYED_RECYCLED 缓存,DELAYED_RECYCLED 存放着当前线程帮助其他线程回收对象的映射关系。假如 item 是 ThreadA 分配的对象,当前线程是 ThreadB,此时 ThreadB 帮助 ThreadA 回收 item,那么 DELAYED_RECYCLED 放入的 key 是 StackA。然后从 delayedRecycled 中取出 StackA 对应的 WeakOrderQueue,如果 WeakOrderQueue 不存在,那么为 StackA 新创建一个 WeakOrderQueue,并将其加入 DELAYED_RECYCLED 缓存。WeakOrderQueue.allocate() 会检查帮助 StackA 回收的对象总数是否超过 2K 个,如果没有超过 2K,会将 StackA 的 head 指针指向新创建的 WeakOrderQueue,否则不再为 StackA 回收对象。
当然 ThreadB 不会只帮助 ThreadA 回收对象,它可以帮助其他多个线程回收,所以 DELAYED_RECYCLED 使用的 Map 结构,为了防止 DELAYED_RECYCLED 内存膨胀,Netty 也采取了保护措施,从 delayedRecycled.size() >= maxDelayedQueues 可以看出,每个线程最多帮助 2 倍 CPU 核数的线程回收线程,如果超过了该阈值,假设当前对象绑定的为 StackX,那么将在 Map 中为 StackX 放入一种特殊的 WeakOrderQueue.DUMMY,表示当前线程无法帮助 StackX 回收对象。
接下来我们继续分析对象是如何被添加到 WeakOrderQueue 的,直接跟进 queue.add(item) 的源码:
void add(DefaultHandle<?> handle) {handle.lastRecycledId = id;Link tail = this.tail;int writeIndex;// 如果链表尾部的 Link 已经写满,那么再新建一个 Link 追加到链表尾部if ((writeIndex = tail.get()) == LINK_CAPACITY) {// 检查是否超过对应 Stack 可以存放的其他线程帮助回收的最大对象数if (!head.reserveSpace(LINK_CAPACITY)) {// Drop it.return;}this.tail = tail = tail.next = new Link();writeIndex = tail.get();}tail.elements[writeIndex] = handle; // 添加对象到 Link 尾部handle.stack = null; // handle 的 stack 属性赋值为 nulltail.lazySet(writeIndex + 1);
}
在向 WeakOrderQueue 写入对象之前,会先判断 Link 链表的 tail 节点是否还有空间存放对象。如果还有空间,直接向 tail Link 尾部写入数据,否则直接丢弃对象。如果 tail Link 已经没有空间,会新建一个 Link 之后再存放对象,新建 Link 之前会检查异线程帮助回收的对象总数超过了 Stack 设置的阈值,如果超过了阈值,那么对象也会被丢弃掉。
对象被添加到 Link 之后,handle 的 stack 属性被赋值为 null,而在取出对象的时候,handle 的 stack 属性又再次被赋值回来,为什么这么做呢,岂不是很麻烦?如果 Stack 不再使用,期望被 GC 回收,发现 handle 中还持有 Stack 的引用,那么就无法被 GC 回收,从而造成内存泄漏。
到此为止,Recycler 如何回收对象的实现原理就全部分析完了,在多线程的场景下,Netty 考虑的还是非常细致的,Recycler 回收对象时向 WeakOrderQueue 中存放对象,从 Recycler 获取对象时,WeakOrderQueue 中的对象会作为 Stack 的储备,而且有效地解决了跨线程回收的问题,是一个挺新颖别致的设计。
Recycler 在 Netty 中的应用
Recycler 在 Netty 里面使用也是非常频繁的,我们直接看下 Netty 源码中 newObject 相关的引用,如下图所示。
其中比较常用的有 PooledHeapByteBuf 和 PooledDirectByteBuf,分别对应的堆内存和堆外内存的池化实现。例如我们在使用 PooledDirectByteBuf 的时候,并不是每次都去创建新的对象实例,而是从对象池中获取预先分配好的对象实例,不再使用 PooledDirectByteBuf 时,被回收归还到对象池中。
此外,可以看到内存池的 MemoryRegionCache 也有使用到对象池,MemoryRegionCache 中保存着一个队列,队列中每个 Entry 节点用于保存内存块,Entry 节点在 Netty 中就是以对象池的形式进行分配和释放,在这里我就不展开了,建议你翻阅下源码,学习下 Entry 节点是何时被分配和释放的,从而加深下对 Recycler 对象池的理解。
总结
最后,简单总结下对象池几个重要的知识点:
- 对象池有两个重要的组成部分:Stack 和 WeakOrderQueue。
- 从 Recycler 获取对象时,优先从 Stack 中查找,如果 Stack 没有可用对象,会尝试从 WeakOrderQueue 迁移部分对象到 Stack 中。
- Recycler 回收对象时,分为同线程对象回收和异线程对象回收两种情况,同线程回收直接向 Stack 中添加对象,异线程回收向 WeakOrderQueue 中的 Link 添加对象。
- 对象回收都会控制回收速率,每 8 个对象会回收一个,其他的全部丢弃。
学完内存池、对象池的设计之后,相信你已经有很大的收获,同时也感受到学好数据结构是多么重要。为了避免依赖,Netty 并没有借助第三方库实现对象池,而是采用了独特的思路自己实现了一个轻量级的对象池,其中优秀的设计思路在开发中是非常值得借鉴的。如果你已经理解了 Recycler,你可以直接在项目中当成工具类使用它,在一些高并发的场景下能够较好地提升应用的性能。