1、Accelerating Diffusion Sampling with Optimized Time Steps

扩散概率模型(DPMs)在高分辨率图像生成方面显示出显著性能,但由于通常需要大量采样步骤,其采样效率仍有待提高。高阶ODE求解在DPMs中的应用的最新进展使得能够以更少的采样步骤生成高质量图像。然而,大多数采样方法仍使用均匀的时间步长,在使用少量步骤时并不是最优的。
为解决这个问题,提出一个通用框架来设计一个优化问题,该优化问题寻求特定数值ODE求解器在DPMs中更合适的时间步长。该优化问题的目标是将基本解和相应的数值解之间的距离最小化。高效解决这个优化问题,所需时间不超过15秒。
在像素空间和潜空间DPMs上进行大量实验,无条件采样和有条件采样,结果表明,与用均匀时间步长相比,当与最先进的采样方法UniPC相结合时,对于CIFAR-10和ImageNet等数据集,以FID分数来衡量,优化时间步长显著提高图像生成性能。
2、DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models

用扩散模型生成高分辨率图像巨大计算成本,导致交互式应用的延迟不可接受。提出DistriFusion来解决这个问题,通过利用多个GPU之间的并行性。方法将模型输入分成多个patch,并每个分配给一个GPU。然而,简单地实现这种算法会破坏patch之间的交互并丢失保真度,而考虑这种交互将导致巨大的通信开销。
为解决这个困境,观察到相邻扩散步骤的输入之间具有很高的相似性,并提出位移patch并行性,它利用扩散过程的顺序性质,通过重复使用前一时间步的预计算特征图为当前步骤提供上下文。因此,方法支持异步通信,可以通过计算进行流水线处理。大量实验证明,方法可以应用于最近的Stable Diffusion XL,而不会降低质量,并且相对于一个NVIDIA A100设备,可以实现高达6.1倍的加速。已开源在:https://github.com/mit-han-lab/distrifuser
3、Balancing Act: Distribution-Guided Debiasing in Diffusion Models
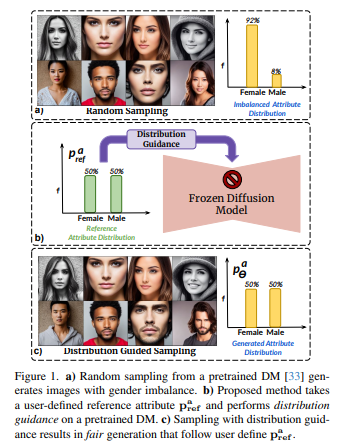
扩散模型(DMs)会反映训练数据集中存在的偏差。在人脸情况下尤为令人担忧,DM更偏爱某个人口群体而不是其他人口群体(例如女性比男性)。这项工作提出一种在不依赖于额外数据或模型重新训练的情况下对DMs进行去偏置的方法。
具体而言,提出分布引导(Distribution Guidance)方法,该方法强制生成的图像遵循指定的属性分布。为实现这一点,建立在去噪UNet(denoising UNet)的潜在特征上具有丰富的人口群体语义,并且可以利用这些特征来引导去偏置生成。训练属性分布预测器(ADP),一个将潜在特征映射到属性分布的小型多层感知机。ADP是使用现有属性分类器生成的伪标签进行训练的。引入的Distribution Guidance与ADP能进行公平生成。
方法减少了单个/多个属性上的偏差,并且在无条件和文本条件下的扩散模型方面的基线效果明显优于过去的方法。此外,提出通过生成数据对训练集进行再平衡来训练公平属性分类器的下游任务。
4、Few-shot Learner Parameterization by Diffusion Time-steps
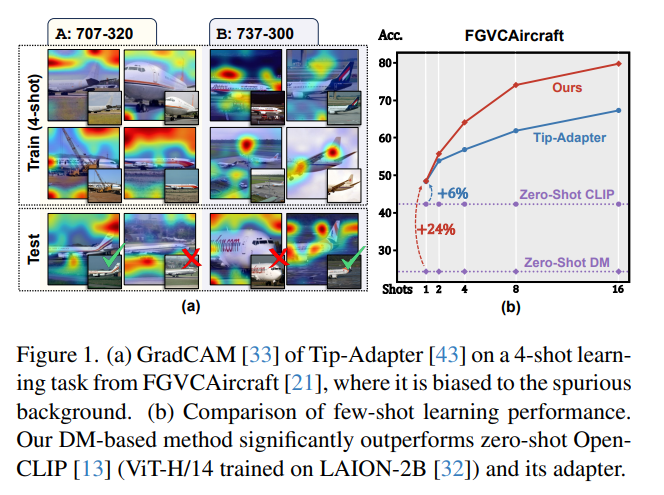
即使用大型多模态基础模型,少样本学习仍具有挑战性。如果没有适当的归纳偏差,很难保留微妙的类属性,同时删除与类标签啡不相关的显著视觉属性。
发现扩散模型(DM)的时间步骤可以隔离微妙的类属性,即随着前向扩散在每个时间步骤向图像添加噪声,微妙的属性通常在比显著属性更早的时间步骤丢失。基于此,提出了时间步骤少样本(TiF)学习器。为文本条件下的DM训练了类别特定的低秩适配器,以弥补丢失的属性,从而在给定提示的情况下可以准确地从噪声图像重建出原始图像。因此,在较小的时间步骤中,适配器和提示本质上是仅含有微妙的类属性的参数化。对于一个测试图像,可以使用这个参数化来仅提取具有微妙的类属性进行分类。在各种细粒度和定制的少样本学习任务上,TiF学习器在性能上明显优于OpenCLIP及其适配器。
5、Structure-Guided Adversarial Training of Diffusion Models

在各种生成应用中,扩散模型展示了卓越的有效性。现有模型主要侧重于通过加权损失最小化来对数据分布进行建模,但它们的训练主要强调实例级的优化,忽视了每个小批量数据内有价值的结构信息。
为解决这个限制,引入结构引导的扩散模型对抗训练(Structure-guided Adversarial training of Diffusion Models, SADM)方法。迫使模型在每个训练批次中学习样本之间的流形结构。为确保模型捕捉到数据分布中真实的流形结构,提出一种新的结构判别器,通过对抗训练与扩散生成器进行游戏,区分真实的流形结构和生成的流形结构。
SADM显著改进了现有的扩散transformer,在图像生成和跨域微调任务中的12个数据集上性能优于现有方法,对于256×256和512×512分辨率下的类条件图像生成,新FID记录分别为1.58和2.11。
6、Tackling the Singularities at the Endpoints of Time Intervals in Diffusion Models

大多数扩散模型假设反向过程服从高斯分布,然而,这种近似在奇异点处(t=0和t=1)尤其在奇异点singularities处尚未得到严格验证。不当处理这些点会导致应用中的平均亮度问题,并限制生成具有极端亮度或深暗度的图像。
本文从理论和实践的角度解决。首先,建立了反向过程逼近的误差界限,并展示了在奇异时间步骤时它的高斯特征。基于这个理论认识,确认t=1的奇异点是有条件可消除的,而t=0时是固有的属性。基于这些重要的结论,提出一种新的即插即用方法SingDiffusion来处理初始奇异时间步骤的采样,它不仅可以在没有额外训练的情况下有效解决平均亮度问题,而且还可以提高它们的生成能力,从而实现显著较低的FID得分。https://github.com/PangzeCheung/SingDiffusion
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
不是一杯奶茶喝不起,而是我T M直接用来跟进 AIGC+CV视觉 前沿技术,它不香?!
ICCV 2023 | 最全AIGC梳理,5w字30个diffusion扩散模型方向,近百篇论文!
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
经典GAN不得不读:StyleGAN
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
最新最全100篇汇总!生成扩散模型Diffusion Models
ECCV2022 | 生成对抗网络GAN部分论文汇总
CVPR 2022 | 25+方向、最新50篇GAN论文
ICCV 2021 | 35个主题GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击跟进 AIGC+CV视觉 前沿技术,真香!,加入 AI生成创作与计算机视觉 知识星球!


![[羊城杯 2020]EasySer](https://img-blog.csdnimg.cn/img_convert/931c7d1850ae2ea841ff11e3510eec26.png)