数据库设计中有一项至关重要的技术难点,那就是给定特定条件进行查询时,我们需要保证速度尽可能快。假设我们有一个 STUDENT 表,表中包含学生名字,年龄,专业等字段,当我们要查询给定年龄数值的记录,如果我们能把所有记录以年龄字段排序,那么通过二分查找,我们就能快速定位满足条件的记录。如果表中包含N=1,000,000 条记录,通过二分查找就能通过大概 logN = 20 次即可,但是要遍历所有记录来找,就得查询一百万次。
但根据某个字段来排序记录,当查询以另外字段查询时就无法得到相应加速。因此如何通过合适算法,让数据进行相应组织,使得查询根据不同字段进行时都能得到相应加速是数据库设计的核心难题。
在不改变表结构的情况下,要能根据不同字段加快查询速度,就需要索引制度。索引本质是一个文件,其中的数据是对给定表的记录分布进行描述和说明。索引文件中的数据以一条条记录的方式存在,一条记录包含两个字段,一个字段叫 datarid,它是一个指针,指向某条特定数据所在的位置,另一个字段叫 dataval,它可以是建立索引的字段的值,如果我们要想针对两个字段 age, name 进行索引,那么索引文件钟就包含两种记录,一种记录的 dataval 对应 age 的值,另一种记录的 dataval 存储 name 的值,然后记录根据 dataval 的值排序,于是我们要根据 age 查询时,我们先通过折半查找在第一种记录钟查询到 VALUE 为给定查询值的记录,然后通过 datarid 字段获取给定记录在硬盘的位置,另外需要注意的是,索引信息也是存储在文件中,获取索引信息也需要访问磁盘,因此我们需要使用好的所有算法尽可能减少在查询索引信息时对磁盘区块的读取。
使用索引文件创建索引数据来记录每条记录的位置还有一个问题,那就是记录会删除和修改,一旦相关记录删除和修改后,索引中的数据就需要进行相应变动,这里我们就需要 B 树,B+树等相关算法的支持。
还需要注意的是,一旦能快速定位所需记录的位置,我们就能定位记录所在的区块从而大大减少对硬盘的访问次数。但也有例外的情况,当建立索引的字段取值重复性很小时,索引的效率就好,如果索引字段取值的重复性很高,那么效率反而有可能会降低。
我们把索引建立的基本流程展示如下:
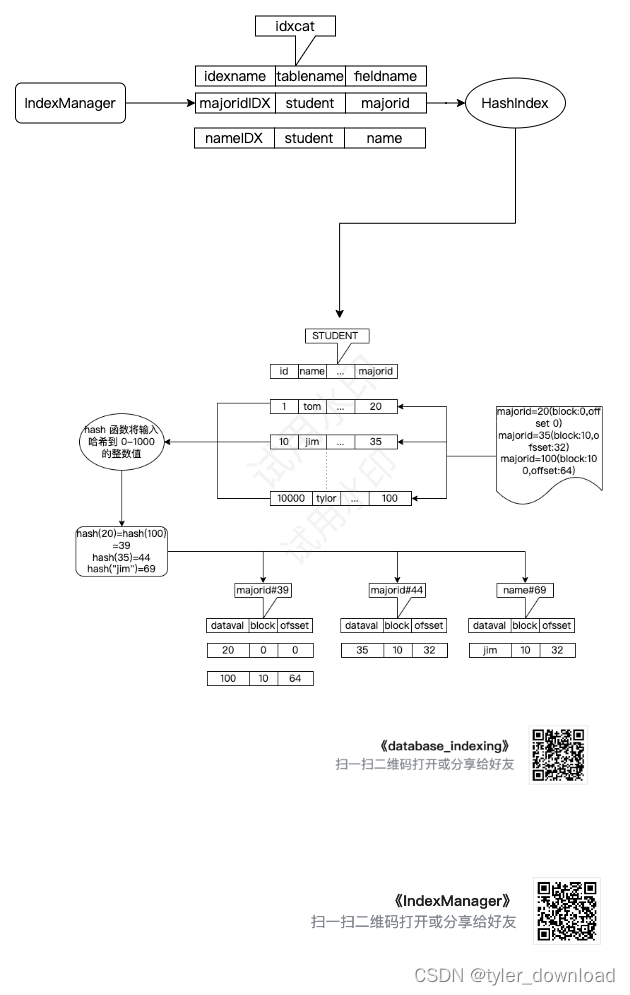
1,当解释执行索引建立的 SQL 语句时,例如 create majoridIDX on student (majorid),
create nameIDX on student (name), 启动索引建立流程
2,索引流程首先创建专门存储索引信息的表 idxcat,其字段为 indexname, tablename, fildname,这些字段分别用于存储索引的名称,建立索引的表名和字段名称。
3,选择索引算法,这里我们先使用前面说的哈希索引。我们使用一个哈希函数hash,假设他能将输入的数据哈希到 0-1000 这范围内的整数值, 假设字段 majorid 的取值 20和 100 经过该函数后输出结果相同为 39,那么代码将创建一个名为 majoroid#39 的记录表来存储这两条记录的访问信息(blockid 和 offset),上图,该表的字段为 dataval,block, id 分别用于存储记录对应索引字段的值,记录所在的 blockid 和 offset 也就是偏移。
在上面例子中由于 majorid 为 20 和 100 的记录都哈希到数值 39,因此他们这两条记录的存储信息都存储在表 majorid#39 这个表中,记录中字段为 name="jim"的记录,由于"jim"哈希的结果为 69,因此该记录的存储信息放置在表 name#69 中。
哈希索引的效率取决于所寻求哈希函数的取值范围,假设函数哈希结果取值范围为 0-N,那么对于一个包含 M 条记录的的表,他对应记录的存储信息将放置在 M/N 个哈希记录表中。哈希索引法在理论上能将记录的查询时间从 M 优化到 M/N。
4,在执行 select 语句进行记录查询时,首先在索引表 idxcat 中查询给定表和对应字段是否已经建立了索引,如果建立了,那么直接从对应的查询记录表中获得记录的存储信息,然后直接从硬盘读取记录数据。
我们看对应代码实现,索引管理器的实现依然放在 metadata_manager 路径下,创建一个名为index_manager.go 的文件,增加代码如下:
package metadata_manager//索引管理器需要使用到后面才讲到的SQL查询和索引算法知识,所以先放一放
import ("query"rm "record_manager""tx"
)type IndexManager struct {layout *rm.LayouttblMgr *TableManagerstatMgr *StatManager
}func NewIndexManager(isNew bool, tblMgr *TableManager, statMgr *StatManager, tx *tx.Transation) *IndexManager {if isNew {//索引元数据表包含三个字段,索引名,对应的表名,被索引的字段名sch := rm.NewSchema()sch.AddStringField("indexname", MAX_NAME)sch.AddStringField("tablename", MAX_NAME)sch.AddStringField("fieldname", MAX_NAME)tblMgr.CreateTable("idxcat", sch, tx)}idxMgr := &IndexManager{tblMgr: tblMgr,statMgr: statMgr,layout: tblMgr.GetLayout("idxcat", tx),}return idxMgr
}func (i *IndexManager) CreateIndex(idxName string, tblName string, fldName string, tx *tx.Transation) {//创建索引时就为其在idxcat索引元数据表中加入一条记录ts := query.NewTableScan(tx, "idxcat", i.layout)ts.BeforeFirst()ts.Insert()ts.SetString("indexname", idxName)ts.SetString("tablename", tblName)ts.SetString("fieldname", fldName)ts.Close()
}func (i *IndexManager) GetIndexInfo(tblName string, tx *tx.Transation) map[string]*IndexInfo {result := make(map[string]*IndexInfo)ts := query.NewTableScan(tx, "idxcat", i.layout)ts.BeforeFirst()for ts.Next() {if ts.GetString("tablename") == tblName {idxName := ts.GetString("indexname")fldName := ts.GetString("fieldname")tblLayout := i.tblMgr.GetLayout(tblName, tx)tblSi := i.statMgr.GetStatInfo(tblName, tblLayout, tx)schema, ok := (tblLayout.Schema()).(*rm.Schema)if ok != true {panic("convert schema interface error")}ii := NewIndexInfo(idxName, fldName, schema, tx, tblSi)result[fldName] = ii}}ts.Close()return result
}IndexManager 的作用是创建索引记录表 idxcat,该表记录有哪些索引建立在哪些表上,idxcat 表包含三个字段,分别是 indexname, tablename 和 fildname。由于为了支持能够灵活的选取不同的索引算法,在代码上我们增加了一个中间件叫 IndexInfo,由它来负责创建所需要的索引算法对象。由于我们可能对不同的字段采取不同的索引算法,因此 GetIndexInfo 返回了一个 map 对象,该字典的 key 对应索引字段的名称,value 对应 IndexInfo 对象,我们看看后者的实现:
package metadata_managerimport (rm "record_manager""tx"
)type IndexInfo struct {idxName stringfldName stringtblSchema *rm.Schematx *tx.TransationidxLayout *rm.Layoutsi *StatInfo
}func NewIndexInfo(idxName string, fldName string, tblSchema *rm.Schema,tx *tx.Transation, si *StatInfo) *IndexInfo {idxInfo := &IndexInfo{idxName: idxName,fldName: fldName,tx: tx,tblSchema: tblSchema,si: si,idxLayout: nil,}idxInfo.idxLayout = idxInfo.CreateIdxLayout()return idxInfo
}func (i *IndexInfo) Open() Index {//在这里 构建不同的哈希算法对象 sreturn NewHashIndex(i.tx, i.idxName, i.idxLayout)
}func (i *IndexInfo) BlocksAccessed() int {rpb := int(i.tx.BlockSize()) / i.idxLayout.SlotSize()numBlocks := i.si.RecordsOutput() / rpbreturn HashIndexSearchCost(numBlocks, rpb)
}func (i *IndexInfo) RecordsOutput() int {return i.si.RecordsOutput() / i.si.DistinctValues(i.fldName)
}func (i *IndexInfo) DistinctValues(fldName string) int {if i.fldName == fldName {return 1}return i.si.DistinctValues(fldName)
}func (i *IndexInfo) CreateIdxLayout() *rm.Layout {sch := rm.NewSchema()sch.AddIntField("block")sch.AddIntField("id")if i.tblSchema.Type(i.fldName) == rm.INTEGER {sch.AddIntField("dataval")} else {fldLen := i.tblSchema.Length(i.fldName)sch.AddStringField("dataval", fldLen)}return rm.NewLayoutWithSchema(sch)
}我们注意看 IndexInfo 的实现中有一个接口例如 DistincValues 等跟我们以前实现的 StateInfo 一样,他负责返回当前索引算法效率的相关信息,对于哈希索引而言,很多效率指标都是固定的,搜索的效率就是 M/N,其中 M 是表中记录的条数,N 就是索引函数取值的范围。下面我们看哈希索引的实现,新建 hash_index.go 文件,输入代码如下:
package metadata_managerimport ("fmt""query"rm "record_manager""tx"
)const (NUM_BUCKETS = 100
)type HashIndex struct {tx *tx.TransationidxName stringlayout *rm.LayoutsearchKey *query.Constantts *query.TableScan
}func NewHashIndex(tx *tx.Transation, idxName string, layout *rm.Layout) *HashIndex {return &HashIndex{tx: tx,idxName: idxName,layout: layout,ts: nil,}
}func (h *HashIndex) BeforeFirst(searchKey *query.Constant) {h.Close()h.searchKey = searchKeybucket := searchKey.HashCode() % NUM_BUCKETS//构造索引记录对应的表名称tblName := fmt.Sprintf("%s#%d", h.idxName, bucket)h.ts = query.NewTableScan(h.tx, tblName, h.layout)
}func (h *HashIndex) Next() bool {for h.ts.Next() {if h.ts.GetVal("dataval").Equals(h.searchKey) {return true}}return false
}func (h *HashIndex) GetDataRID() *rm.RID {//返回记录所在的区块信息blkNum := h.ts.GetInt("block")id := h.ts.GetInt("id")return rm.NewRID(blkNum, id)
}func (h *HashIndex) Insert(val *query.Constant, rid *rm.RID) {h.BeforeFirst(val)h.ts.Insert()h.ts.SetInt("block", rid.BlockNumber())h.ts.SetInt("id", rid.Slot())h.ts.SetVal("dataval", val)
}func (h *HashIndex) Delete(val *query.Constant, rid *rm.RID) {h.BeforeFirst(val)for h.Next() {if h.GetDataRID().Equals(rid) {h.ts.Delete()return}}
}func (h *HashIndex) Close() {if h.ts != nil {h.ts.Close()}
}func HashIndexSearchCost(numBlocks int, rpb int) int {return numBlocks / NUM_BUCKETS
}HashIndex 对象会根据索引字段的名称和哈希计算结果来新建一个存储被索引记录区块信息的表,如果索引字段为 majorid,记录对应 majorid 字段的取值为 20,哈希计算结果为 39,他就会创建名为 majorid#39 的表,表中包含三个字段分别是 dataval, block, id,dataval 存储哈希字段的取值,block 对应记录所在的区块号,id 对应偏移,当我们想要读取给定记录时,只要从该表中拿出 block 和 id 的值,就能直接读取磁盘上给定位置的数据。
在MetaDataManager 的实现中,我们需要在他的实现中增加索引管理器的创建,对应代码如下:
package metadata_managerimport ("query"rm "record_manager""tx"
)type MetaDataManager struct {tblMgr *TableManagerviewMgr *ViewManagerstatMgr *StatManagerconstant *query.Constant//索引管理器以后再处理idxMgr *IndexManager
}func NewMetaDataManager(isNew bool, tx *tx.Transation) *MetaDataManager {metaDataMgr := &MetaDataManager{tblMgr: NewTableManager(isNew, tx),constant: nil,}metaDataMgr.viewMgr = NewViewManager(isNew, metaDataMgr.tblMgr, tx)metaDataMgr.statMgr = NewStatManager(metaDataMgr.tblMgr, tx)metaDataMgr.idxMgr = NewIndexManager(isNew, metaDataMgr.tblMgr,metaDataMgr.statMgr, tx)return metaDataMgr
}func (m *MetaDataManager) CreateTable(tblName string, sch *rm.Schema, tx *tx.Transation) {m.tblMgr.CreateTable(tblName, sch, tx)
}func (m *MetaDataManager) CreateView(viewName string, viewDef string, tx *tx.Transation) {m.viewMgr.CreateView(viewName, viewDef, tx)
}func (m *MetaDataManager) GetLayout(tblName string, tx *tx.Transation) *rm.Layout {return m.tblMgr.GetLayout(tblName, tx)
}func (m *MetaDataManager) GetViewDef(viewName string, tx *tx.Transation) string {return m.viewMgr.GetViewDef(viewName, tx)
}func (m *MetaDataManager) GetStatInfo(tblName string, layout *rm.Layout, tx *tx.Transation) *StatInfo {return m.statMgr.GetStatInfo(tblName, layout, tx)
}func (m *MetaDataManager) CreateIndex(idxName string, tblName string, fldName string, tx *tx.Transation) {m.idxMgr.CreateIndex(idxName, tblName, fldName, tx)
}func (m *MetaDataManager) GetIndexInfo(tblName string, tx *tx.Transation) map[string]*IndexInfo {return m.idxMgr.GetIndexInfo(tblName, tx)
}最后我们在 main.go 中将上面代码调用起来看看运行效果:
package mainimport (bmg "buffer_manager"fm "file_manager""fmt"lm "log_manager"metadata_manager "metadata_management""parser""planner""query""tx"
)
func PrintStudentTable(tx *tx.Transation, mdm *metadata_manager.MetaDataManager) {queryStr := "select name, majorid, gradyear from STUDENT"p := parser.NewSQLParser(queryStr)queryData := p.Query()test_planner := planner.CreateBasicQueryPlanner(mdm)test_plan := test_planner.CreatePlan(queryData, tx)test_interface := (test_plan.Open())test_scan, _ := test_interface.(query.Scan)for test_scan.Next() {fmt.Printf("name: %s, majorid: %d, gradyear: %d\n",test_scan.GetString("name"), test_scan.GetInt("majorid"),test_scan.GetInt("gradyear"))}
}
func TestIndex() {file_manager, _ := fm.NewFileManager("student", 4096)log_manager, _ := lm.NewLogManager(file_manager, "logfile.log")buffer_manager := bmg.NewBufferManager(file_manager, log_manager, 3)tx := tx.NewTransation(file_manager, log_manager, buffer_manager)fmt.Printf("file manager is new: %v\n", file_manager.IsNew())mdm := metadata_manager.NewMetaDataManager(file_manager.IsNew(), tx)//创建 student 表,并插入一些记录updatePlanner := planner.NewBasicUpdatePlanner(mdm)createTableSql := "create table STUDENT (name varchar(16), majorid int, gradyear int)"p := parser.NewSQLParser(createTableSql)tableData := p.UpdateCmd().(*parser.CreateTableData)updatePlanner.ExecuteCreateTable(tableData, tx)insertSQL := "insert into STUDENT (name, majorid, gradyear) values(\"tylor\", 30, 2020)"p = parser.NewSQLParser(insertSQL)insertData := p.UpdateCmd().(*parser.InsertData)updatePlanner.ExecuteInsert(insertData, tx)insertSQL = "insert into STUDENT (name, majorid, gradyear) values(\"tom\", 35, 2023)"p = parser.NewSQLParser(insertSQL)insertData = p.UpdateCmd().(*parser.InsertData)updatePlanner.ExecuteInsert(insertData, tx)fmt.Println("table after insert:")PrintStudentTable(tx, mdm)//在 student 表的 majorid 字段建立索引mdm.CreateIndex("majoridIdx", "STUDENT", "majorid", tx)//查询建立在 student 表上的索引并根据索引输出对应的记录信息studetPlan := planner.NewTablePlan(tx, "STUDENT", mdm)updateScan := studetPlan.Open().(*query.TableScan)//先获取每个字段对应的索引对象,这里我们只有 majorid 建立了索引对象indexes := mdm.GetIndexInfo("STUDENT", tx)//获取 majorid 对应的索引对象majoridIdxInfo := indexes["majorid"]//将改rid 加入到索引表majorIdx := majoridIdxInfo.Open()updateScan.BeforeFirst()for updateScan.Next() {//返回当前记录的 riddataRID := updateScan.GetRid()dataVal := updateScan.GetVal("majorid")majorIdx.Insert(dataVal, dataRID)}//通过索引表获得给定字段内容的记录majorid := 35majorIdx.BeforeFirst(query.NewConstantWithInt(&majorid))for majorIdx.Next() {datarid := majorIdx.GetDataRID()updateScan.MoveToRid(datarid)fmt.Printf("student name :%s, id: %d\n", updateScan.GetScan().GetString("name"),updateScan.GetScan().GetInt("majorid"))}majorIdx.Close()updateScan.GetScan().Close()tx.Commit()}func main() {TestIndex()
}在代码中我们先创建 STUDENT表,插入两条记录,然后创建一个名为 majoridIdx 的索引,该索引对应的字段就是 majorid,然后代码通过 IndexInfo 创建 HashIndex 对象,接着代码遍历 STUDENT 表中的每条记录,获取这些记录对应的 blockid 和偏移 offset,HashIndex 将对应记录的字段值进行哈希后创建对应的索引记录表,然后将每条记录的 block id 和 offset 插入记录表中。
最后代码遍历创建的索引记录表,从中找到索引值为 35 的记录,然后取出记录对应的 block id 和 offset,通过这两个信息直接从磁盘上将记录信息读取并显示出来,上面代码运行后结果如下:
file manager is new: true
table after insert:
name: tylor, majorid: 30, gradyear: 2020
name: tom, majorid: 35, gradyear: 2023
student name :tom, id: 35
transation 1 committed
从输出我们可以看到,代码能直接通过索引记录表的记录信息直接查找想要的记录,不用向我们前面做的那样,在查询想要的记录时,将整个表的每条记录都搜索一遍,由此我们就能有效的提升查询效率。代码下载:
https://github.com/wycl16514/database_hashindex
更多内容和视频讲解演示请在 b 站搜索 coding迪尼斯