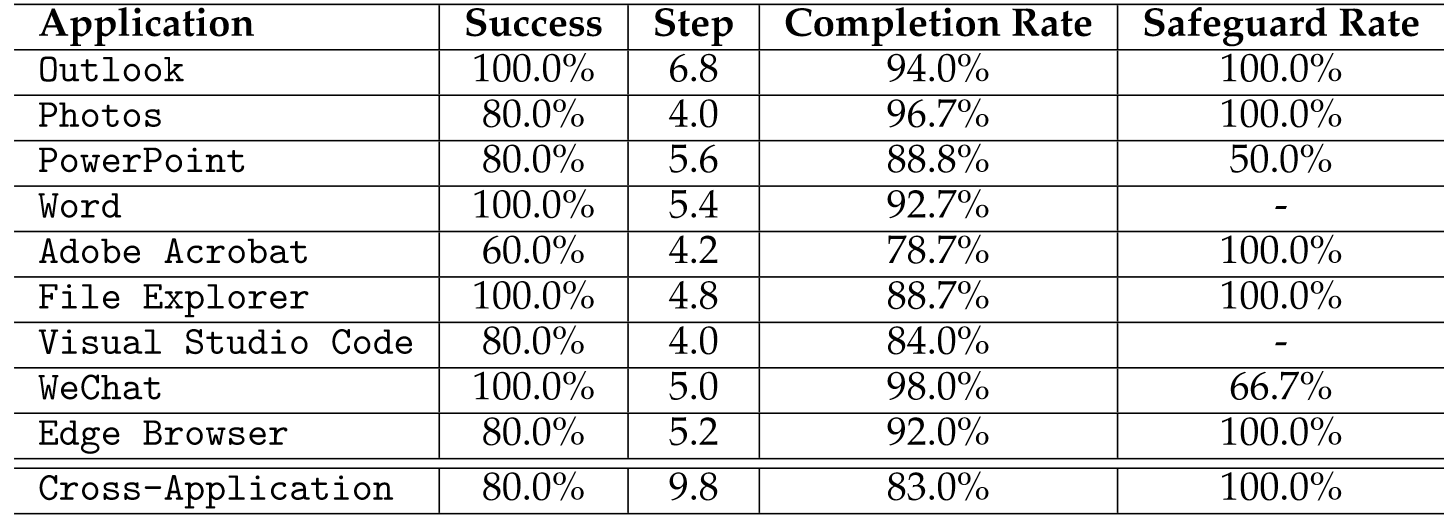
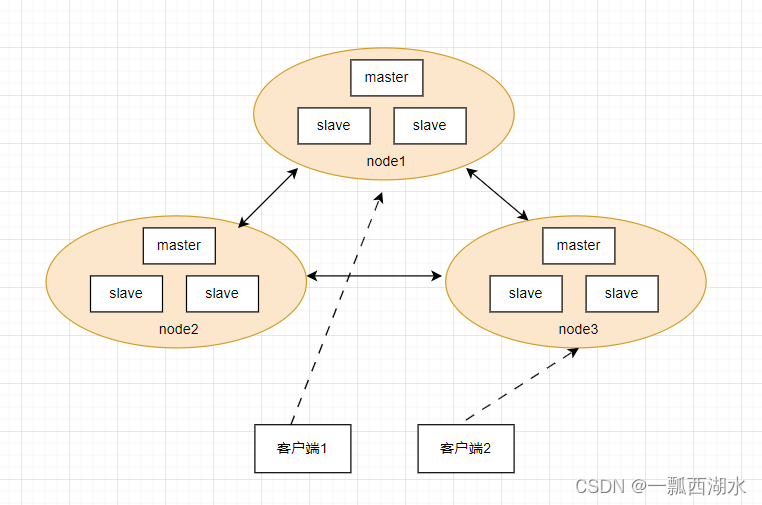
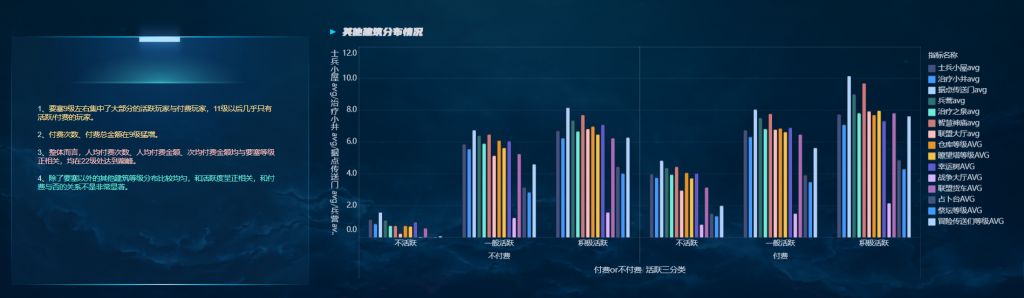
Hadoop分布式文件系统支持NameNode节点的高可用性,本文主要描述Secondary NameNode数据备份版本的安装部署。

如上所示,NameNode主节点同步数据到NameNode备份节点,当NameNode主节点发生故障变得不可用时, NameNode主节点重新启动,则从Secondary NameNode备份节点中恢复数据,备份节点的数据是存放在内存中,当集群的数据量大的时候,NameNode主节点可以直接从Secondary NameNode备份节点的内存中快速读取备份数据,大幅度降低NameNode主节点失败恢复的时间
| NameNode1 | 192.168.0.136 |
| DataNode 1 Secondary NameNode | 192.168.0.137 |
| DataNode 2 | 192.168.0.138 |
如上所示,增加一个Secondary NameNode节点
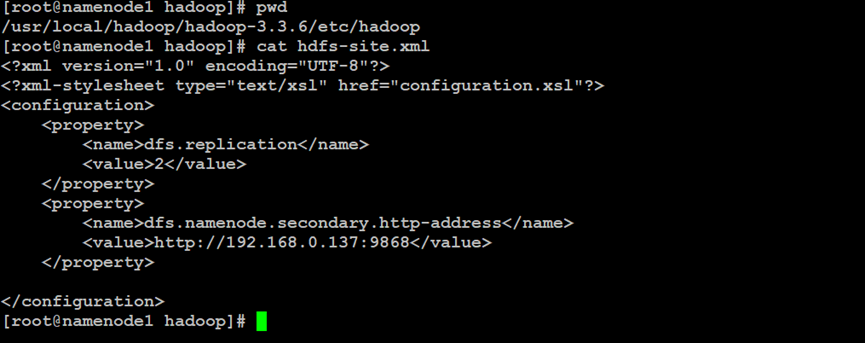
如上所示,在Hadoop分布式文件系统的NameNode索引节点中,设置Secondary NameNode备份节点的网络地址信息
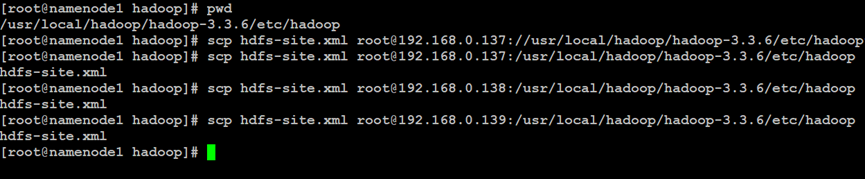
如上所示,在Hadoop分布式文件系统的NameNode索引节点中,同步分布式文件系统的属性配置文件到集群的其他节点

如上所示,在Hadoop分布式文件系统的NameNode索引节点中,刷新配置文件

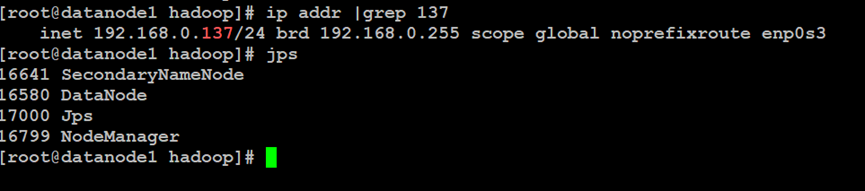
如上所示,主节点NameNode以及备份节点Secondary NameNode已经正常启动